



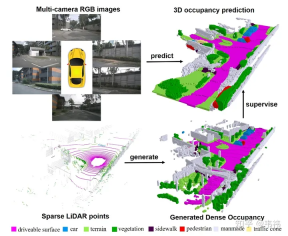
この作業では、マルチフレーム点群を通じて高密度の占有ラスター データセットを構築し、トランスフォーマーの 2D-3D Unet 構造に基づいて 3 次元占有ラスター ネットワークを設計しました。私たちの記事が ICCV 2023 に掲載されていることを光栄に思います。プロジェクト コードは現在オープンソースであり、誰でも試すことができます。

arXiv: https://arxiv.org/pdf/2303.09551.pdf
コード: https://github.com/weiyithu/SurroundOcc
ホームページ リンク: https://weiyithu.github.io/SurroundOcc/
最近、狂ったように仕事を探していて、書く時間がありません。最近、カメラ準備完了の提出物を提出したところです。社会人として、結局は志胡のまとめを書いた方が良いのではないかと思いました。実際、記事の導入部分はすでにさまざまな公開アカウントによってよく書かれており、その宣伝のおかげで、自動運転の心臓部である nuScenes SOTA! を直接参照することができます。 SurroundOcc: 自動運転用の純粋なビジュアル 3D 占有予測ネットワーク (清華およびTianda)。一般に、貢献は 2 つの部分に分かれており、1 つはマルチフレーム LIDAR 点群を使用して高密度の占有データ セットを構築する方法、もう 1 つは占有予測用のネットワークを設計する方法です。実際、どちらの部分も比較的単純で理解しやすい内容になっており、わからないことがあればいつでも質問していただけます。そこでこの記事では、理論以外のことについてお話したいと思います。1 つは、現在のソリューションをどのように改善して導入しやすくするか、もう 1 つは将来の開発の方向性です。
展開
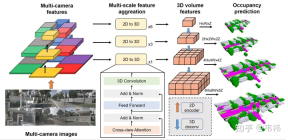
ネットワークの展開が簡単かどうかは、主にネットワークが適切かどうかによって決まります。オペレータはボード側に実装されますが、SurroundOcc メソッドの 2 つのより困難なオペレータは、トランス層と 3D コンボリューションです。
トランスフォーマーの主な機能は、2D 特徴を 3D 空間に変換することです。実際、この部分は LSS、ホモグラフィー、さらには mlp を使用して実装することもできるため、ネットワークのこの部分は、実装されたソリューション。ただし、私の知る限り、変圧器ソリューションはキャリブレーションの影響を受けにくく、いくつかのソリューションの中でパフォーマンスが優れているため、変圧器の展開を実装する能力がある人は、元のソリューションを使用することをお勧めします。
3D コンボリューションの場合は、2D コンボリューションに置き換えることができます。ここでは、(C、H、W、Z) の元の 3D 特徴を (C* Z、H、W) 2D 特徴に再形成する必要があります。その後、特徴抽出に 2D 畳み込みを使用でき、最後の占有予測ステップでは、(C、H、W、Z) に再整形され、監視されます。一方、スキップ接続は解像度が高いため、より多くのビデオ メモリを消費しますが、展開時に削除して、最小解像度のレイヤーのみを残すことができます。私たちの実験では、3D コンボリューションのこれら 2 つの操作には nuscene でいくつかのドロップ ポイントがあることがわかりましたが、業界のデータ セットの規模は nuscene よりもはるかに大きいため、場合によってはいくつかの結論が変更され、ドロップ ポイントは少なくなるか、まったくなくなるはずです。
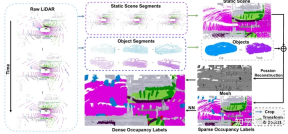
データセットの構築に関して、最も時間のかかるステップはポアソン再構成です。収集には 32 ライン LIDAR を使用する nuscenes データ セットを使用します。マルチフレーム ステッチング技術を使用した場合でも、ステッチされた点群には依然として多くの穴が存在することがわかりました。したがって、これらの穴を埋めるためにポアソン再構成を採用しました。ただし、現在業界で使用されている LIDAR 点群の多くは、M1、RS128 など比較的密度が高くなります。したがって、この場合、データセットの構築を高速化するためにポアソン再構成ステップを省略できます。
一方、SurroundOcc は、nuscenes でマークされた 3 次元ターゲット検出フレームを使用して、静的シーンを結合します。と動的オブジェクトが分離されます。ただし、実際のアプリケーションでは、大規模な 3 次元ターゲット検出および追跡モデルであるオートラベルを使用して、シーケンス全体の各オブジェクトの検出フレームを取得できます。手動で注釈を付けたラベルと比較すると、大規模なモデルを使用して生成された結果には間違いなくエラーが含まれます。最も直接的に現れるのは、オブジェクトの複数のフレームを結合した後のゴースト現象です。しかし実際には、職業では物体の形状に対する要求はそれほど高くなく、検出枠の位置が比較的正確であれば要求を満たすことができます。
将来の方向
現在の方法は依然としてライダーを利用して乗員監視信号を提供していますが、多くの車、特に一部の低レベル運転支援車にはライダーが搭載されていません。シャドウモードでは大量のRGBデータが返せるので、今後の方向性としては自己教師あり学習のみにRGBを使えるかどうかです。自然な解決策は、監視に NeRF を使用することです。具体的には、フロント バックボーン部分は変更せずに占有予測を取得し、ボクセル レンダリングを使用して各カメラの視点から RGB を取得し、損失は真の値 RGB で行われます。トレーニング セット監視信号を作成します。しかし、この単純な方法が実際に試してみたところ、あまりうまく機能しなかったのが残念です。考えられる理由としては、屋外シーンの範囲が広すぎてナーフが保持できない可能性もありますが、可能性もあります。正しく調整されていないことがわかります。もう一度試してください。
もう 1 つの方向は、タイミングと占有フローです。実際、占有フローは、単一フレームの占有よりも下流のタスクにとってはるかに便利です。 ICCV の期間中は、占有フローのデータセットを編集する時間がなく、論文を発表するときに多くのフロー ベースラインを比較する必要があったため、その時点では作業しませんでした。タイミング ネットワークについては、比較的シンプルで効果的な BEVFormer および BEVDet4D のソリューションを参照できます。難しい部分はやはりフロー データ セットです。一般的なオブジェクトはシーケンスの 3 次元ターゲット検出フレームを使用して計算できますが、小動物のビニール袋などの特殊な形状のオブジェクトには、シーン フロー手法を使用してアノテーションを付ける必要がある場合があります。

書き直す必要がある内容は次のとおりです: 元のリンク: https://mp.weixin.qq.com/s/_crun60B_lOz6_maR0Wyug
以上がSurroundOcc: サラウンド 3D 占有グリッドの新しい SOTA!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 外挿の包括的なガイドApr 15, 2025 am 11:38 AM
外挿の包括的なガイドApr 15, 2025 am 11:38 AM導入 数週間で作物の進行を毎日観察する農民がいるとします。彼は成長率を見て、さらに数週間で彼の植物がどれほど背が高くなるかについて熟考し始めます。 thから
 ソフトAIの台頭とそれが今日のビジネスにとって何を意味するかApr 15, 2025 am 11:36 AM
ソフトAIの台頭とそれが今日のビジネスにとって何を意味するかApr 15, 2025 am 11:36 AMソフトAIは、おおよその推論、パターン認識、柔軟な意思決定を使用して特定の狭いタスクを実行するように設計されたAIシステムとして定義されていますが、曖昧さを受け入れることにより、人間のような思考を模倣しようとします。 しかし、これはBusineにとって何を意味しますか
 AIフロンティア向けの進化するセキュリティフレームワークApr 15, 2025 am 11:34 AM
AIフロンティア向けの進化するセキュリティフレームワークApr 15, 2025 am 11:34 AM答えは明確です。クラウドコンピューティングには、クラウドネイティブセキュリティツールへの移行が必要であるため、AIはAIの独自のニーズに特化した新しい種類のセキュリティソリューションを要求します。 クラウドコンピューティングとセキュリティレッスンの台頭 で
 3つの方法生成AIは起業家を増幅します:平均に注意してください!Apr 15, 2025 am 11:33 AM
3つの方法生成AIは起業家を増幅します:平均に注意してください!Apr 15, 2025 am 11:33 AM起業家とAIと生成AIを使用して、ビジネスを改善します。同時に、すべてのテクノロジーと同様に、生成的AIが増幅器であることを覚えておくことが重要です。厳密な2024年の研究o
 Andrew Ngによる埋め込みモデルに関する新しいショートコースApr 15, 2025 am 11:32 AM
Andrew Ngによる埋め込みモデルに関する新しいショートコースApr 15, 2025 am 11:32 AM埋め込みモデルのパワーのロックを解除する:Andrew Ngの新しいコースに深く飛び込む マシンがあなたの質問を完全に正確に理解し、応答する未来を想像してください。 これはサイエンスフィクションではありません。 AIの進歩のおかげで、それはRになりつつあります
 大規模な言語モデル(LLMS)の幻覚は避けられませんか?Apr 15, 2025 am 11:31 AM
大規模な言語モデル(LLMS)の幻覚は避けられませんか?Apr 15, 2025 am 11:31 AM大規模な言語モデル(LLM)と幻覚の避けられない問題 ChatGpt、Claude、GeminiなどのAIモデルを使用した可能性があります。 これらはすべて、大規模なテキストデータセットでトレーニングされた大規模な言語モデル(LLMS)、強力なAIシステムの例です。
 60%の問題 - AI検索がトラフィックを排出する方法Apr 15, 2025 am 11:28 AM
60%の問題 - AI検索がトラフィックを排出する方法Apr 15, 2025 am 11:28 AM最近の研究では、AIの概要により、産業と検索の種類に基づいて、オーガニックトラフィックがなんと15〜64%減少する可能性があることが示されています。この根本的な変化により、マーケティング担当者はデジタルの可視性に関する戦略全体を再考することになっています。 新しい
 AI R&Dの中心に人間が繁栄するようにするMITメディアラボApr 15, 2025 am 11:26 AM
AI R&Dの中心に人間が繁栄するようにするMITメディアラボApr 15, 2025 am 11:26 AMElon UniversityがDigital Future Centerを想像している最近のレポートは、300人近くのグローバルテクノロジーの専門家を調査しました。結果のレポート「2035年に人間である」は、ほとんどがTを超えるAIシステムの採用を深めることを懸念していると結論付けました。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SublimeText3 中国語版
中国語版、とても使いやすい

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

