
ホームページ >テクノロジー周辺機器 >AI >UniOcc: 視覚中心の占有予測を幾何学的およびセマンティック レンダリングと統合します。
UniOcc: 視覚中心の占有予測を幾何学的およびセマンティック レンダリングと統合します。

- 王林転載
- 2023-09-16 20:29:10876ブラウズ
原題: UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering
論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/pdf/2306.09117.pdf

ペーパーアイデア:
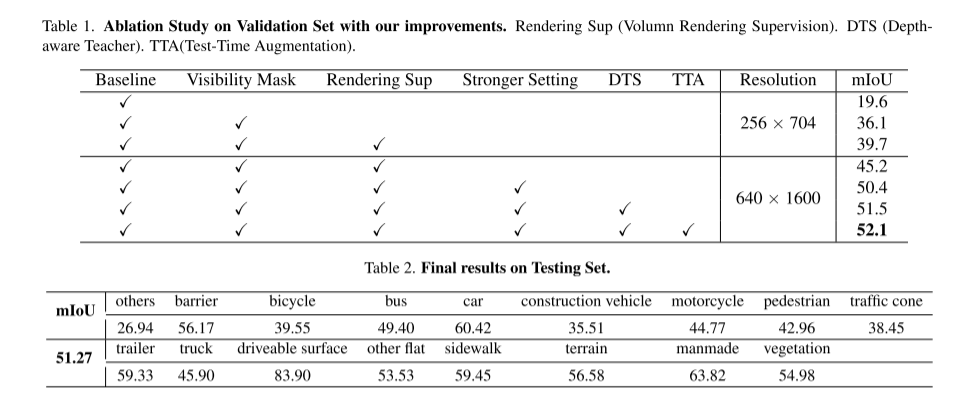
この技術レポートでは、CVPR 2023 ビジョン中心の nuScenes で使用するための UniOCC と呼ばれるソリューションを提案します。 3D 占有予測軌跡は、Open Dataset Challenge で実行されます。既存の占有予測方法は、主に 3D 占有ラベルを使用して 3D 体積空間の投影特性を最適化することに重点を置いています。ただし、これらのラベルの生成プロセスは非常に複雑でコストがかかり(3D セマンティック アノテーションに依存)、ボクセル解像度によって制限され、きめ細かい空間セマンティクスを提供できません。この制限に対処するために、空間幾何学的制約を明示的に課し、ボリューム レイ レンダリングによるきめ細かいセマンティック監視を補足する、新しい統合占有 (UniOcc) 予測方法を提案します。私たちの方法はモデルのパフォーマンスを大幅に向上させ、手動によるアノテーションのコスト削減に大きな可能性を示しています。 3D 占有状況に注釈を付ける手間を考慮して、ラベルなしデータを使用して予測精度を向上させるために、深さを認識した教師生徒 (DTS) フレームワークをさらに提案します。当社のソリューションは、公式の単一モデル ランキングで 51.27% の mIoU を達成し、この課題で 3 位にランクされました
ネットワーク設計:
こちらこの課題の一環として、この文書では次のことを提案します。 UniOcc は、ボリューム レンダリングを利用して 2D 表現と 3D 表現の監視を統合し、マルチカメラ占有予測モデルを改善する一般的なソリューションです。このペーパーでは、新しいモデル アーキテクチャを設計するのではなく、多用途かつプラグ アンド プレイの方法で既存のモデル [3、18、20] を強化することに焦点を当てています。
次のように書き直します: この論文では、表現を NeRF スタイルの表現にアップグレードすることで、ボリューム レンダリングを使用して 2D セマンティック マップと深度マップを生成する機能を実装します [1,15,21]。これにより、2D ピクセル レベルでのきめ細かい監視が可能になります。 3 次元ボクセルをレイ サンプリングすることにより、レンダリングされた 2 次元ピクセル セマンティクスと深度情報を取得できます。幾何学的オクルージョン関係とセマンティック一貫性制約を明示的に統合することにより、この論文はモデルに明示的なガイダンスを提供し、これらの制約への準拠を保証します。UniOcc には高価な 3D セマンティック アノテーションの必要性を削減する可能性があることは言及する価値があります。 3D 占有ラベルがない場合、ボリューム レンダリング監視のみを使用してトレーニングされたモデルは、3D ラベル監視を使用してトレーニングされたモデルよりもさらに優れたパフォーマンスを発揮します。これは、シーン表現を手頃な価格の 2D セグメンテーション ラベルから直接学習できるため、高価な 3D セマンティック アノテーションへの依存を軽減できる素晴らしい可能性を強調しています。さらに、SAM [6] や [14,19] などの高度なテクノロジーを使用すると、2D セグメンテーション アノテーションのコストをさらに削減できます。
この記事では、自己教師ありトレーニング方法であるディープ センシング教師-生徒 (DTS) フレームワークについても紹介します。従来の Mean Teacher とは異なり、DTS は教師モデルの詳細な予測を強化し、ラベルなしのデータを利用しながら安定した効果的なトレーニングを実現します。さらに、このペーパーでは、モデルのパフォーマンスを向上させるために、いくつかのシンプルだが効果的な手法を適用します。これには、トレーニングでの可視マスクの使用、より強力な事前トレーニングされたバックボーン ネットワークの使用、ボクセル解像度の向上、およびテスト時データ拡張 (TTA) の実装が含まれます。 UniOcc フレームワークの概要: 図 1
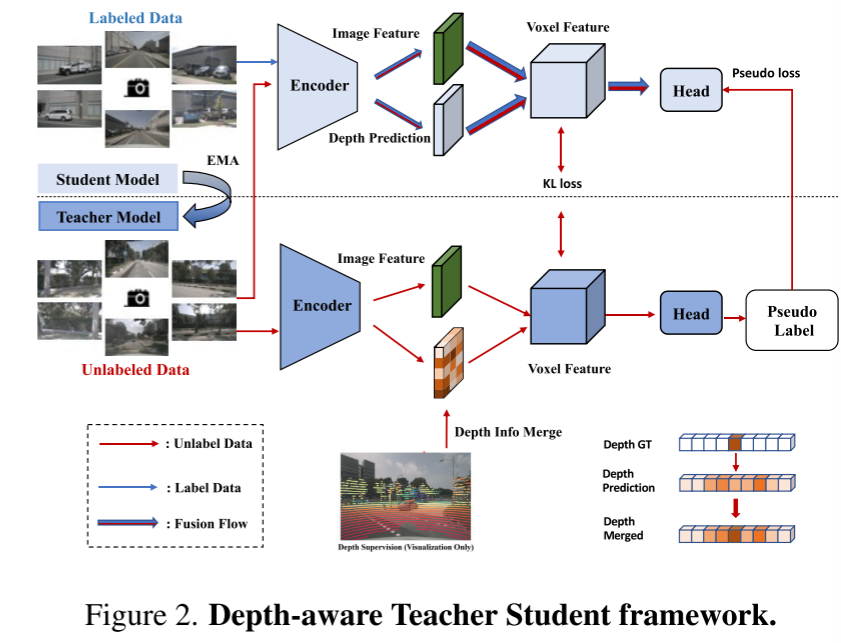
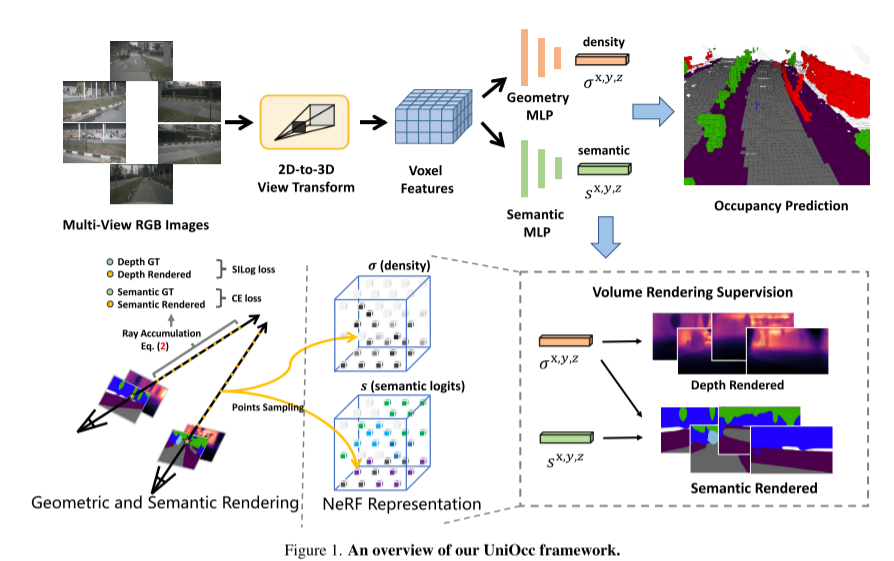 図 2。奥行きを意識した教師と生徒のフレームワーク。
図 2。奥行きを意識した教師と生徒のフレームワーク。
#引用:

元のリンク: https://mp.weixin.qq.com/s/iLPHMtLzc5z0f4bg_W1vIg
以上がUniOcc: 視覚中心の占有予測を幾何学的およびセマンティック レンダリングと統合します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。