#遠隔医療の台頭により、患者は便利で効率的な医療サポートを求めてオンライン診察や診察を選択する傾向が高まっています。最近、大規模言語モデル (LLM) は強力な自然言語対話機能を実証し、医療アシスタントが人々の生活に参入するという希望をもたらしています
医療および健康相談のシナリオは通常複雑であるため、パーソナルアシスタントには豊富な医療知識と、複数回の対話を通じて患者の意図を理解し、専門的かつ詳細な対応を行う能力が必要です。医療や健康に関する相談に直面した場合、一般言語モデルは、医療知識の不足のために会話を避けたり、質問されていない質問に答えたりすることがよくありますが、同時に、現在の一連の質問で相談を完了する傾向があり、満足のいく回答能力を欠いています。複数回の質問をフォローアップします。さらに、現在、高品質の中国の医療データセットは非常に希少であるため、医療分野で強力な言語モデルをトレーニングすることが課題となっています。 復丹大学データ インテリジェンスおよびソーシャル コンピューティング研究所 (FudanDISC) は、中国の医療および健康パーソナル アシスタント DISC-MedLLM をリリースしました。単一ラウンドの質疑応答および複数ラウンドの対話の医療および健康相談評価において、モデルのパフォーマンスは、既存の大規模な医療対話モデルと比較して明らかな利点を示します。研究チームはまた、470,000 人を含む高品質の教師あり微調整 (SFT) データセット DISC-Med-SFT をリリースし、モデル パラメーターと技術レポートもオープンソースとして公開しています。
- ホームページアドレス: https://med.fudan-disc.com
- Github アドレス: https://github.com/FudanDISC/DISC-MedLLM
- 技術レポート: https://arxiv.org/abs/2308.14346

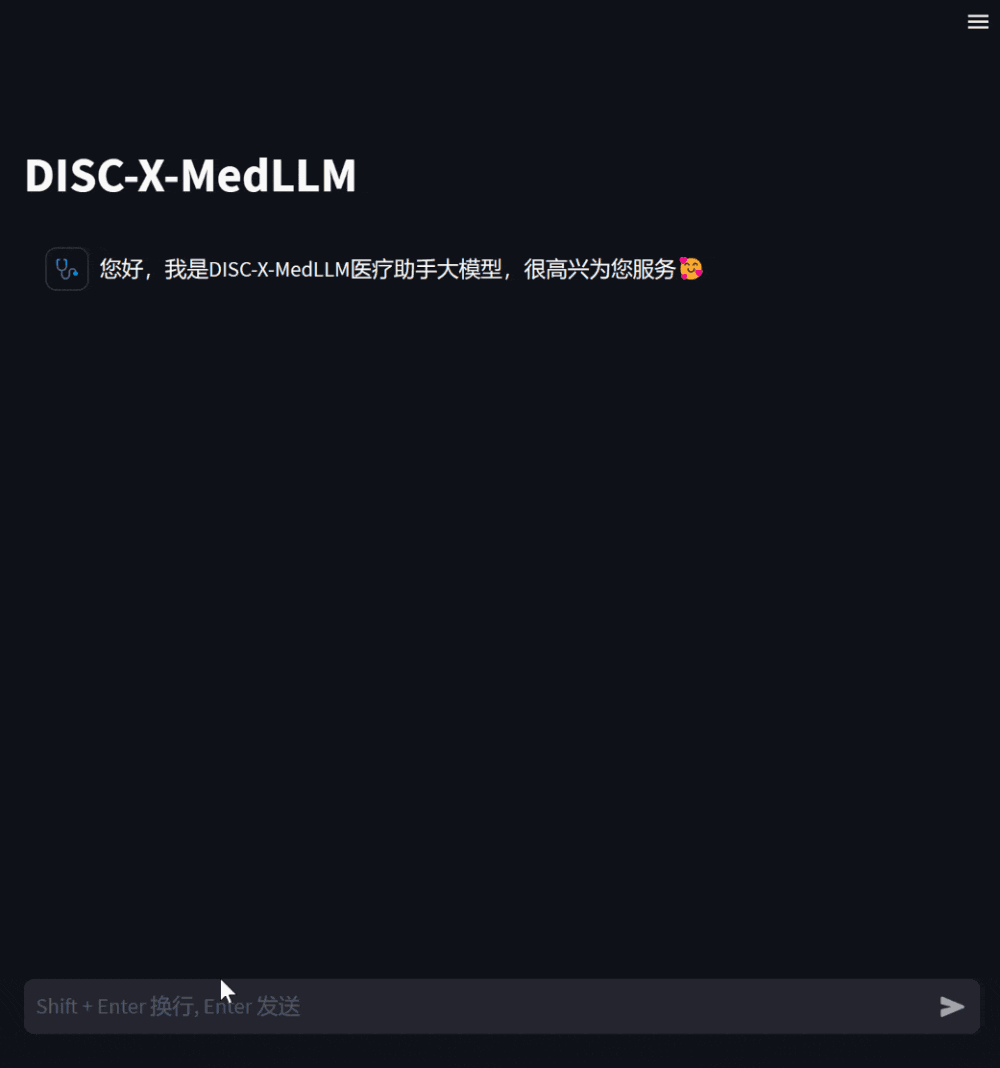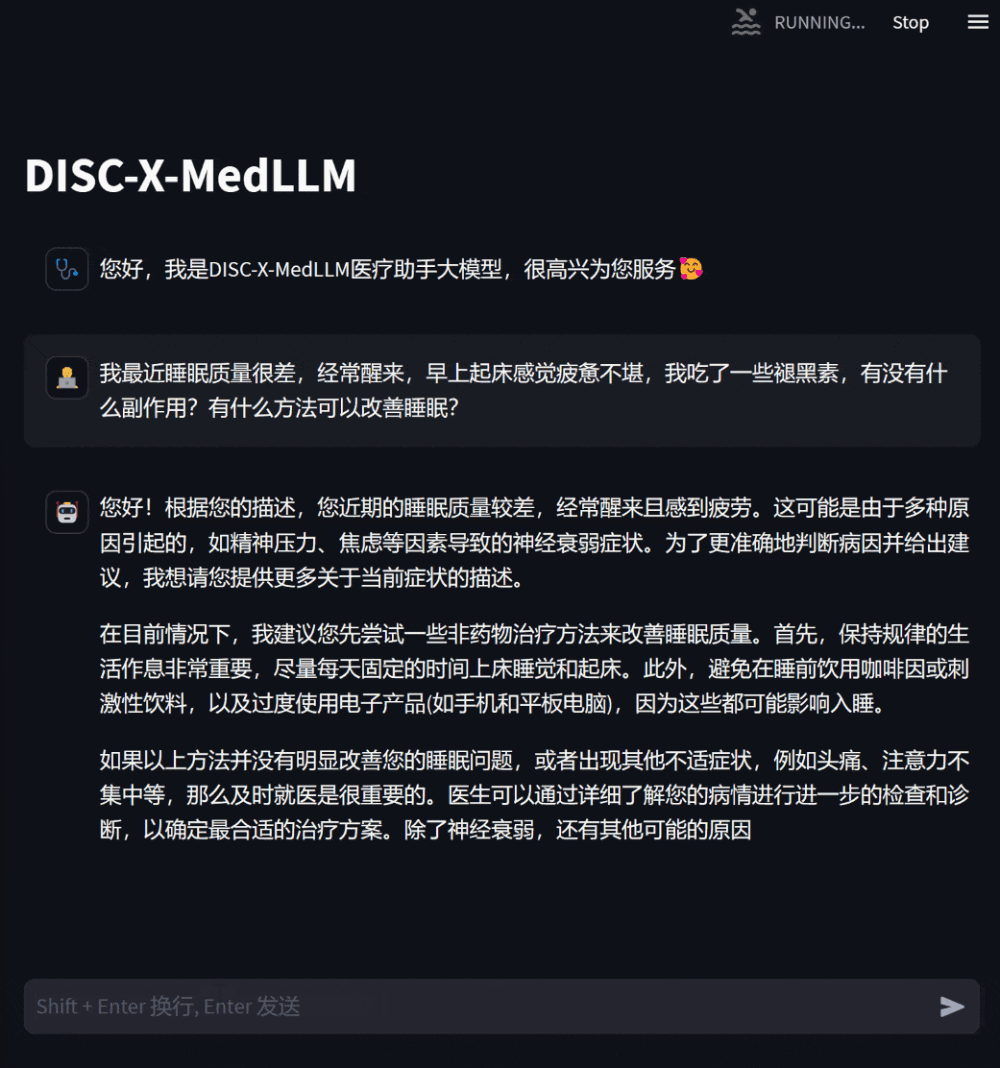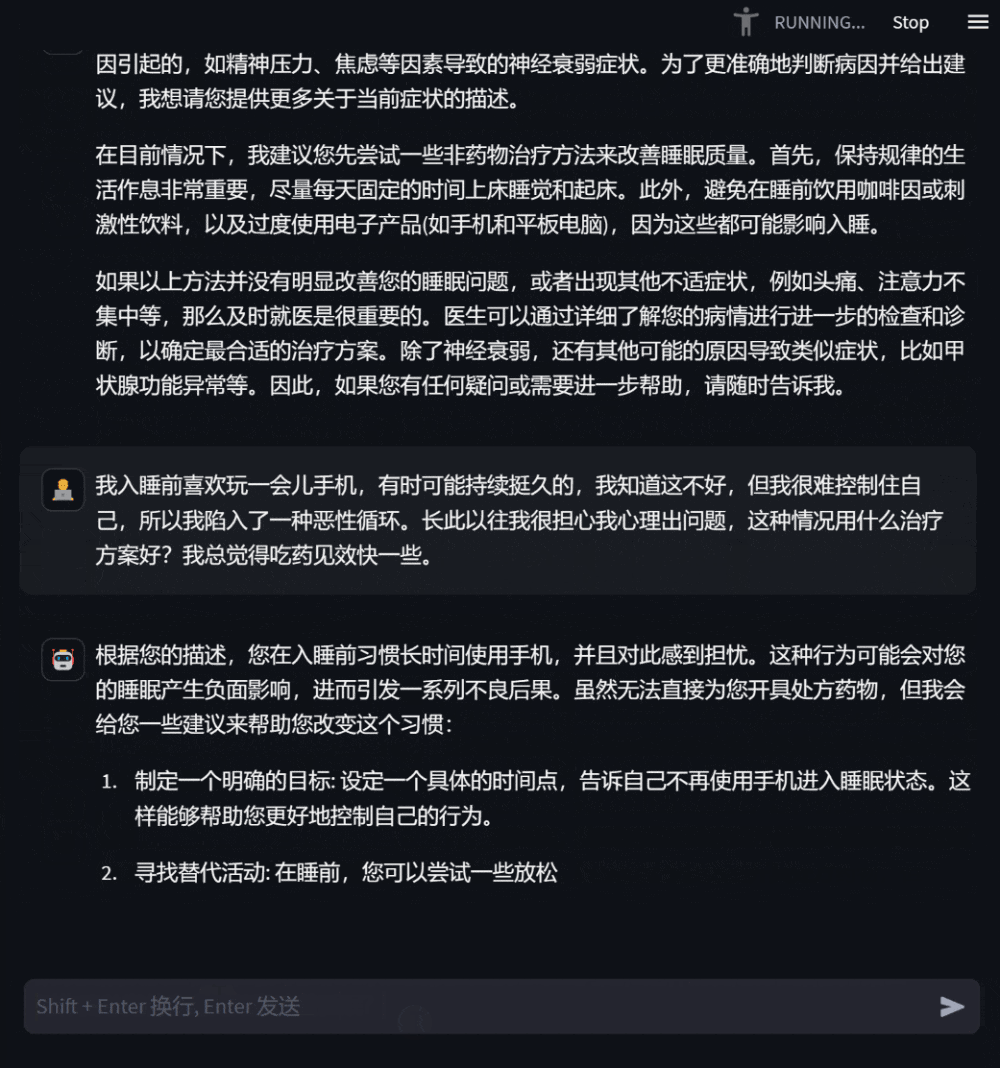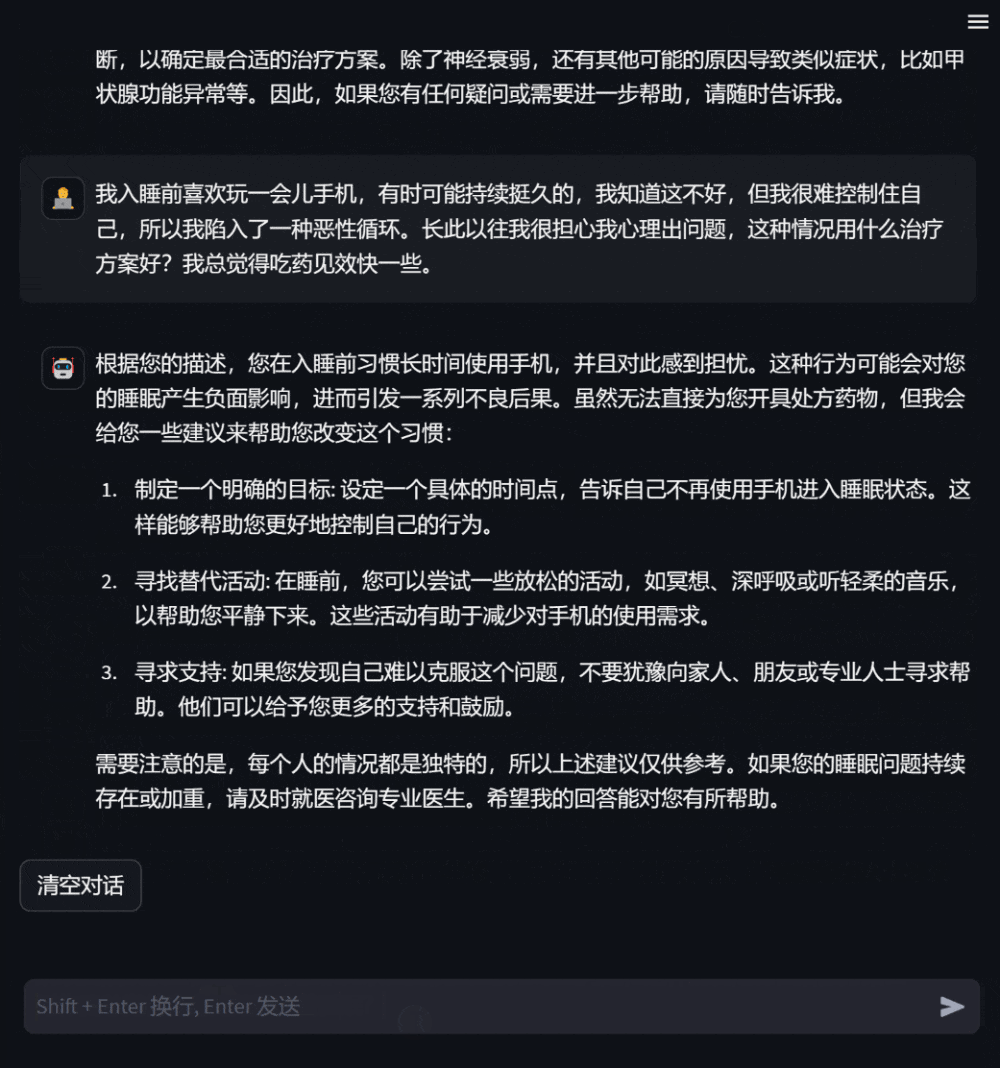
患者が気分が悪くなった場合、モデルに相談して症状を説明すると、モデルは考えられる原因や推奨される治療計画などを提示します。情報が不足している場合は、症状の詳細な説明を積極的に求めました。
#図 2: 相談現場での対話
ユーザーは自分の健康状態に基づいてモデル固有の相談質問をすることもできます。モデルは詳細で役立つ回答を返し、情報が不足している場合は積極的に質問して、回答の適切性と正確性を高めます。 #図 3: 自分の健康状態についての相談に基づく対話
##ユーザーは、自分とは関係のない医学知識について質問することもできますが、その際、ユーザーが総合的かつ正確に理解できるよう、モデルは可能な限り専門的に回答します。
図 4: 自分とは関係のない医療知識の問い合わせダイアログ DISC-MedLLM は、当社が構築した高品質データセット DISC-Med-SFT に基づいて、一般領域の中国の大型モデル Baichuan-13B でトレーニングされた大規模な医療モデルです。 。私たちのトレーニング データとトレーニング方法は、あらゆる基本的な大規模モデルに適応できることは注目に値します。 DISC-MedLLM には 3 つの重要な特徴があります:
- 信頼性と豊富な専門知識。医療知識グラフを情報源として使用し、トリプルをサンプルし、一般的な大規模モデルの言語機能を使用して対話サンプルを構築します。
- 複数ラウンドの対話のための調査能力。実際の診療対話記録を情報源として使用し、大規模なモデルを使用して対話を再構築しますが、その構築プロセスでは、対話内の医療情報を完全に整合させるモデルが必要です。
- 人間の好みに合わせて応答を調整します。患者は、診察の過程でより豊富な裏付け情報や背景知識を得ることを望んでいますが、人間の医師の回答は簡潔であることが多いため、手動スクリーニングを通じて、患者のニーズに合わせた高品質で小規模な指示サンプルを構築します。
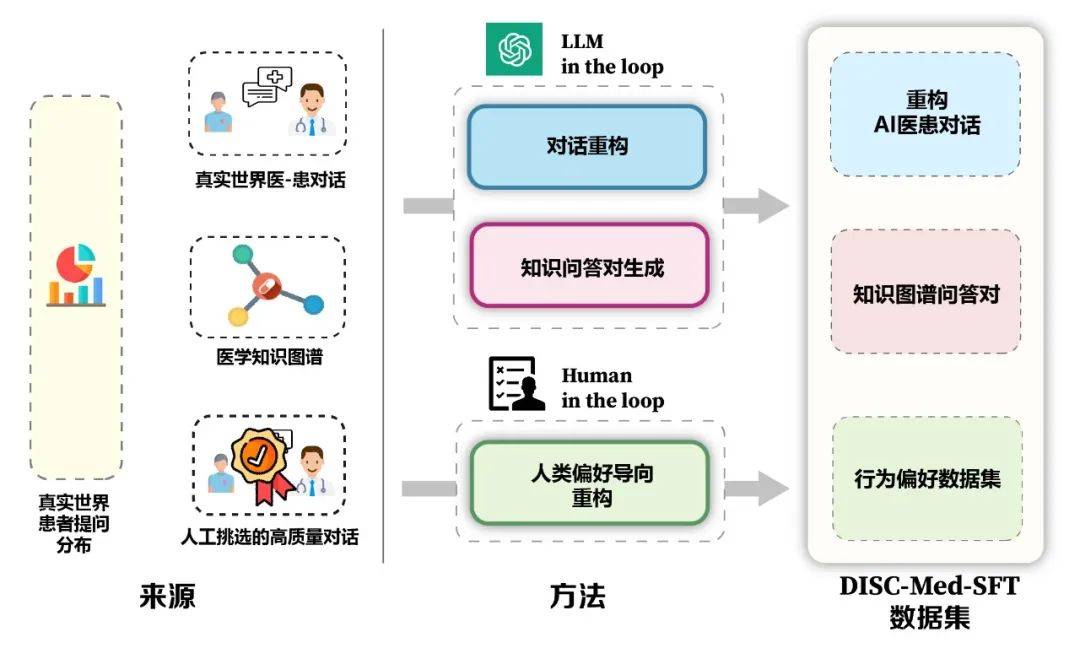
モデルとデータ構築フレームワークの利点を図 5 に示します。データセットのサンプル構築をガイドするために、実際の診察シナリオから患者の実際の分布を計算しました。医療知識グラフと実際の診察データに基づいて、大規模なモデルインザループとピープルインザループという 2 つのアイデアを使用しました。データセットを構築するためのループ。
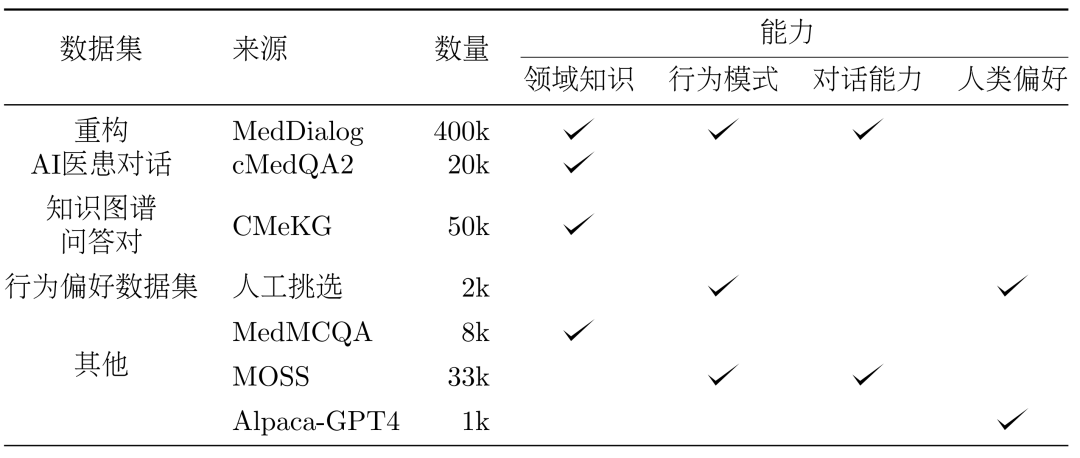
3. 方法: データセット DISC-Med-SFT の構築モデルのトレーニングの過程で、DISC-Med-SFT に質問しました。 Med-SFT は、既存のコーパスからの一般的なドメイン データセットとデータ サンプルで補足されて DISC-Med-SFT-ext を形成します。詳細は表 1 に示されています。
表 1: DISC-Med-SFT-ext データ内容の紹介
データセット。 SFT データセット構築のためのソース サンプルとして、2 つの公開データ セット MedDialog と cMedQA2 からそれぞれ 400,000 サンプルと 20,000 サンプルがランダムに選択されました。
リファクタリング。実際の医師の回答を必要な高品質で統一された形式の回答に調整するために、GPT-3.5 を利用してこのデータセットの再構成プロセスを完了しました。プロンプトは、次の原則に従うように書き直す必要があります:
口頭表現を削除し、統一された表現を抽出し、医師の言語使用箇所の不一致を修正します。
- 元の医師の回答の重要な情報にこだわり、より徹底的かつ論理的になるように適切な説明を提供します。
- 患者に予約を求めるなど、AI 医師が送信すべきではない応答を書き換えるか削除します。
# 図 6 は、リファクタリングの例を示しています。調整された医師の回答は AI 医療アシスタントのアイデンティティと一致しており、元の医師から提供された重要な情報を遵守しながら、より豊富で包括的な支援を患者に提供します。
医療ナレッジ グラフには、よく整理された医療専門知識が大量に含まれており、これに基づいてノイズの少ない QA トレーニング サンプルを生成できます。 CMeKGに基づいて、疾患ノードの部門情報に従ってナレッジグラフにサンプリングし、適切に設計されたGPT-3.5モデルプロンプトを使用して、合計50,000を超える多様な医療現場の対話サンプルを生成しました。 #行動嗜好データセット
トレーニングの最終段階で、モデルをさらに改善する パフォーマンスを向上させるために、人間の行動の好みとより一貫性のあるデータセットを二次教師付き微調整に使用します。 MedDialog と cMedQA2 の 2 つのデータセットから約 2000 の高品質で多様なサンプルを手動で選択し、いくつかのサンプルを書き換えて GPT-4 に手動で修正した後、小サンプル法を使用してそれらを GPT-3.5 に提供し、高品質のサンプルを生成しました-質の高い行動嗜好データセット。
一般データ。トレーニング セットの多様性を高め、SFT トレーニング段階でのモデルの基本機能の低下のリスクを軽減するために、2 つの一般的な教師あり微調整データセット、moss-sft-003 および alpaca gpt4 データからランダムにいくつかのサンプルを選択しました。 zh. MedMCQA。モデルの Q&A 機能を強化するために、英語の医療分野の多肢選択式質問データ セットである MedMCQA を選択し、GPT-3.5 を使用して多肢選択式質問の質問と正解を最適化し、約 8,000 の専門的な中国語を生成しました。医療Q&Aのサンプルです。
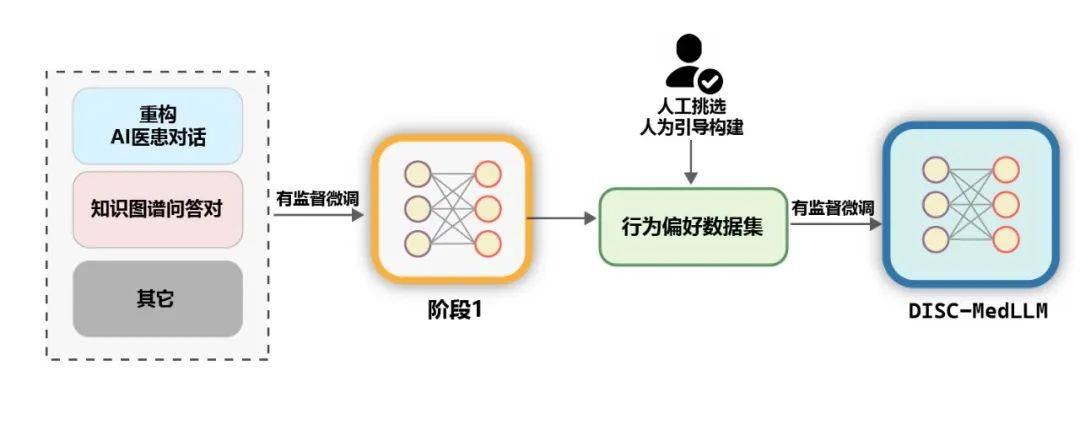
トレーニング。以下の図に示すように、DISC-MedLLM のトレーニング プロセスは 2 つの SFT ステージに分かれています。
図 7: 2 段階のトレーニング プロセス
## ##レビュー。医療 LLM のパフォーマンスは、1 ラウンドの QA と複数ラウンドの対話という 2 つのシナリオで評価されます。 単一ラウンド QA 評価: 医学知識の観点からモデルの精度を評価するために、中国国家医療機関からデータを収集しました。医師資格試験 (NMLEC) および国立修士入学試験 (NEEP) の西洋医学 306 専攻では、1 回の QA でモデルのパフォーマンスを評価するために 1,500 の多肢選択問題が選択されました。
- 複数ラウンドの対話評価: モデルの対話能力を系統的に評価するために、中国医学ベンチマーク評価 (CMB-Clin)、中国医学対話という 3 つの公開データセットを使用します。データセット (CMD) と中国医療意図データセット (CMID) を統合し、GPT-3.5 は患者の役割とモデルとの対話を担うサンプルをランダムに選択し、主体性、正確さ、有用性、言語品質の 4 つの評価指標を提案しています。 3.5 4 個の評価。
結果の確認
##モデルを比較します。私たちのモデルは、3 つの一般的な LLM と 2 つの中国医学会話 LLM と比較されます。 OpenAI の GPT-3.5、GPT-4、Baichuan-13B-Chat、BianQue-2、および HuatuoGPT-13B を含みます。
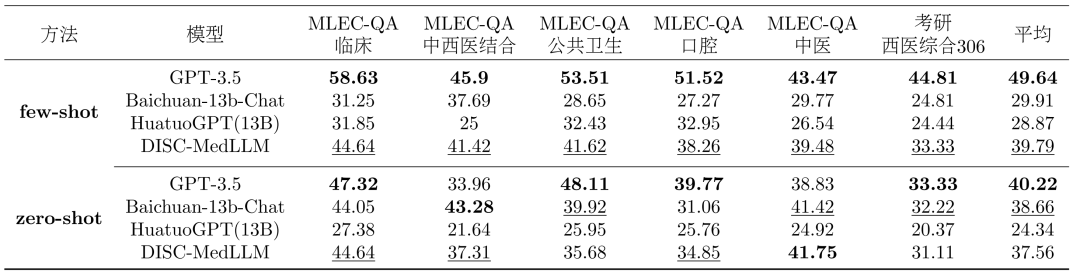
単一ラウンドの QA 結果。多肢選択式評価の全体的な結果を表 2 に示します。 GPT-3.5 が明確なリードを示しています。 DISC-MedLLM はサンプル数が少ない設定では 2 位を達成し、サンプル数がゼロの設定では Baichuan-13B-Chat に次いで 3 位にランクされました。特に、強化学習設定でトレーニングされた HuatuoGPT (13B) のパフォーマンスを上回っています。 #表 2: 多肢選択評価結果
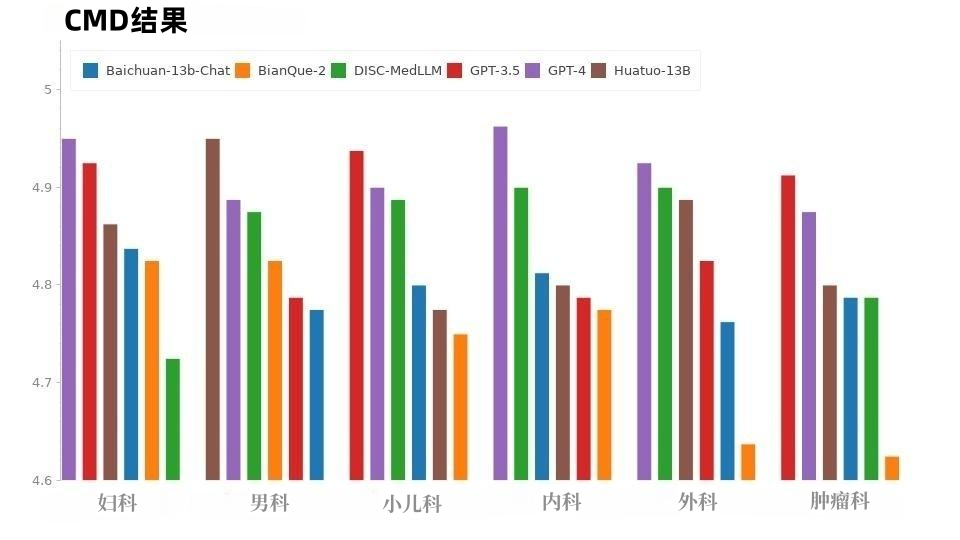
#複数ラウンドの対話の結果。 CMB-Clin の評価では、DISC-MedLLM が最高の総合スコアを達成し、僅差で HuatuoGPT がそれに続きました。私たちのモデルは陽性基準で最高のスコアを獲得し、医療行動パターンに偏りをもたらすトレーニングアプローチの有効性を浮き彫りにしました。結果を表3に示す。 図 8 に示すように、CMD サンプルでは、GPT-4 が最高のスコアを獲得しました。次はGPT-3.5です。医療分野のモデルである DISC-MedLLM と HuatuoGPT は総合的なパフォーマンス スコアが同じであり、さまざまな部門でのパフォーマンスが優れています。
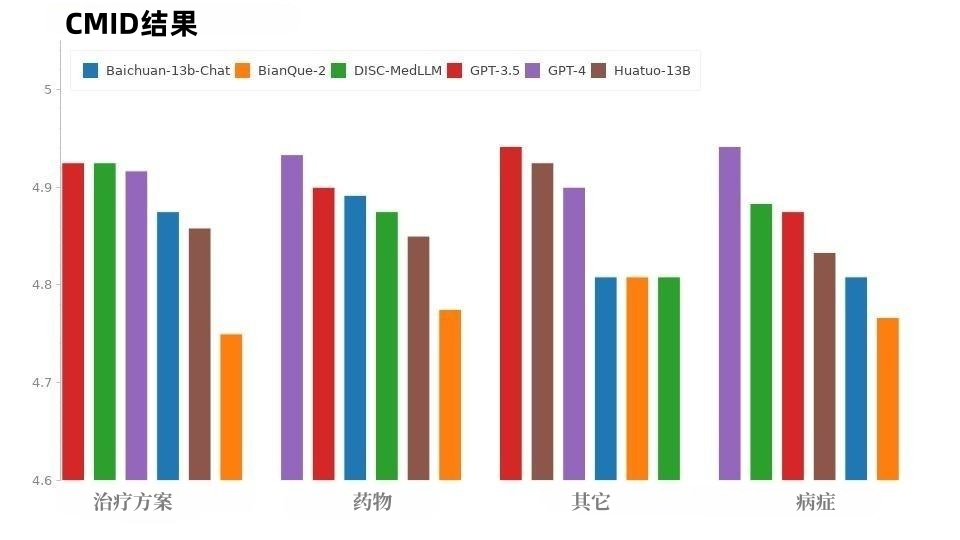
CMID の状況は CMD の状況と似ており、図 9 に示すように、GPT-4 と GPT-3.5 がリードを維持しています。 GPT シリーズを除いて、DISC-MedLLM が最も優れたパフォーマンスを示しました。状態、治療計画、投薬という 3 つの目的で HuatuoGPT を上回りました。
#図 9: CMID の結果
CMB-Clin と CMD/CMID の間で各モデルのパフォーマンスが一貫していないのは、3 つのデータセット間のデータ分布の違いが原因である可能性があります。 CMD と CMID には、より明確な質問のサンプルが含まれており、患者は診断を受け、症状を説明する際に明確なニーズを表明している可能性があり、患者の質問やニーズは個人の健康状態とはまったく関係がない場合もあります。多くの点で優れている汎用モデル GPT-3.5 および GPT-4 は、この状況に対処するのに優れています。 5. 概要
DISC-Med-SFT データセットは、現実世界の会話と一般的なドメイン LLM の利点と機能、および 3 つの側面におけるターゲットを絞った強化: ドメイン知識、医療会話スキル、人間の好み、高品質のデータセットが優れた大規模医療モデル DISC-MedLLM をトレーニングし、医療相互作用の観点から大幅な改善が行われました。を実現し、高いユーザビリティを実証し、大きな応用可能性を実証しました。
この分野の研究は、オンライン医療費の削減、医療リソースの促進、バランスの達成について、より多くの見通しと可能性をもたらすでしょう。 DISC-MedLLM は、より多くの人々に便利で個別化された医療サービスを提供し、健康全般の推進に貢献します。 以上が復旦大学チームが中国の医療・健康パーソナルアシスタントをリリース、47万件の高品質データセットをオープンソース化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。




 #図 3: 自分の健康状態についての相談に基づく対話
#図 3: 自分の健康状態についての相談に基づく対話