
ホームページ >テクノロジー周辺機器 >AI >アリ巨大モデルが再びオープンソース化!完全な画像理解機能と物体認識機能を備えており、一般的な問題セット 7B に基づいてトレーニングされており、商用アプリケーションに使用可能です。
アリ巨大モデルが再びオープンソース化!完全な画像理解機能と物体認識機能を備えており、一般的な問題セット 7B に基づいてトレーニングされており、商用アプリケーションに使用可能です。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-09-03 13:01:08799ブラウズ
Alibaba は新しい大規模モデルをオープンソース化しました。これは非常にエキサイティングです~
Tongyi Qianwen-7B (Qwen-7B) に続き、Alibaba Cloud が 大規模モデルを開始しましたビジュアル言語モデル Qwen-VL であり、オンラインになるとすぐにオープンソース化されます。

Qwen-VL は、Tongyi Qianwen-7B をベースにした大規模なマルチモーダル モデルで、具体的には、さまざまな画像、テキスト、検出フレームをサポートしています。テキストの出力だけでなく、検出フレームの出力も可能
例えば、アニヤの写真を入力すると、Qwen-VL-Chatは質問と回答の形で写真の内容を要約し、写真の中のアニヤを正確に見つけるため
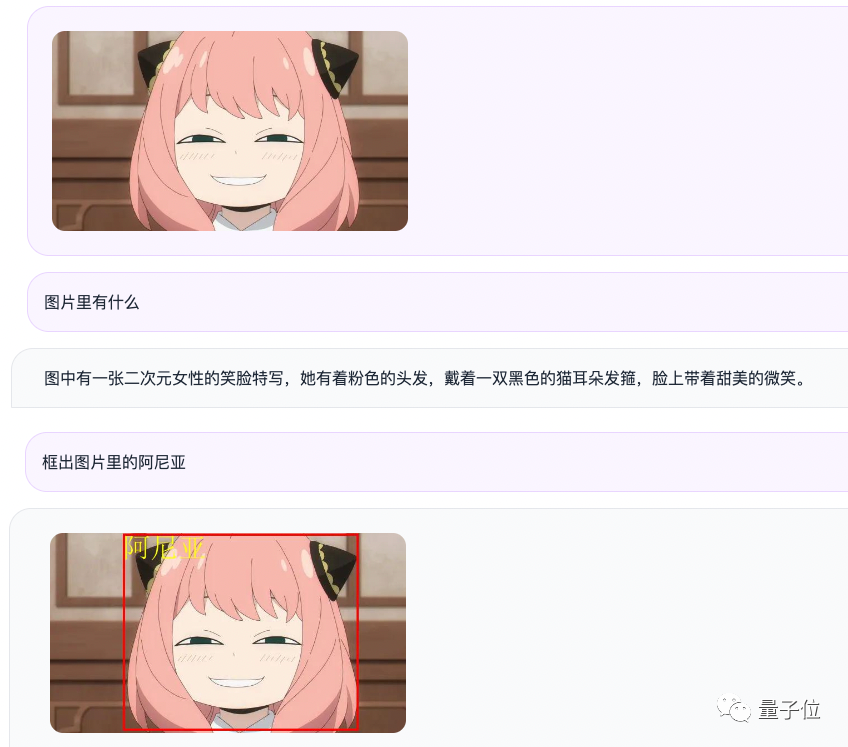

 # 具体的な性能を見てみましょう!
# 具体的な性能を見てみましょう!
中国のオープンドメインポジショニングをサポートする最初の一般的なモデル
まず、Qwen-VL シリーズ モデルの全体的な特徴を見てみましょう:
多言語ダイアログ : 多言語ダイアログをサポート、画像内の中国語と英語の長文認識をエンドツーエンドでサポート;- マルチ画像インターリーブダイアログ: 複数画像の入力と比較をサポート、指定された画像の質問と回答、複数の画像による文学作品など;
- 中国語のオープンドメイン測位をサポートする最初の一般的なモデル:中国語のオープンドメイン言語表現による検出フレームの注釈、つまり、ターゲットオブジェクトは画像内で正確に検出;
- きめ細かい認識と理解: 他のオープンソース LVLM
- (大規模視覚言語モデル)で現在使用されている 224 解像度との比較 # , Qwen-VL は、オープンソース初の 448 解像度 LVLM モデルです。解像度が高くなると、きめの細かいテキスト認識、文書の質問応答、および検出ボックスの注釈が向上します。 元の意味を変えることなく、書き換える必要がある内容は次のとおりです。 Qwen-VL は、知識質疑応答、画像質疑応答、文書質疑応答、細かい質問などのシナリオで使用できます。 -粒状の視覚的位置決めなど
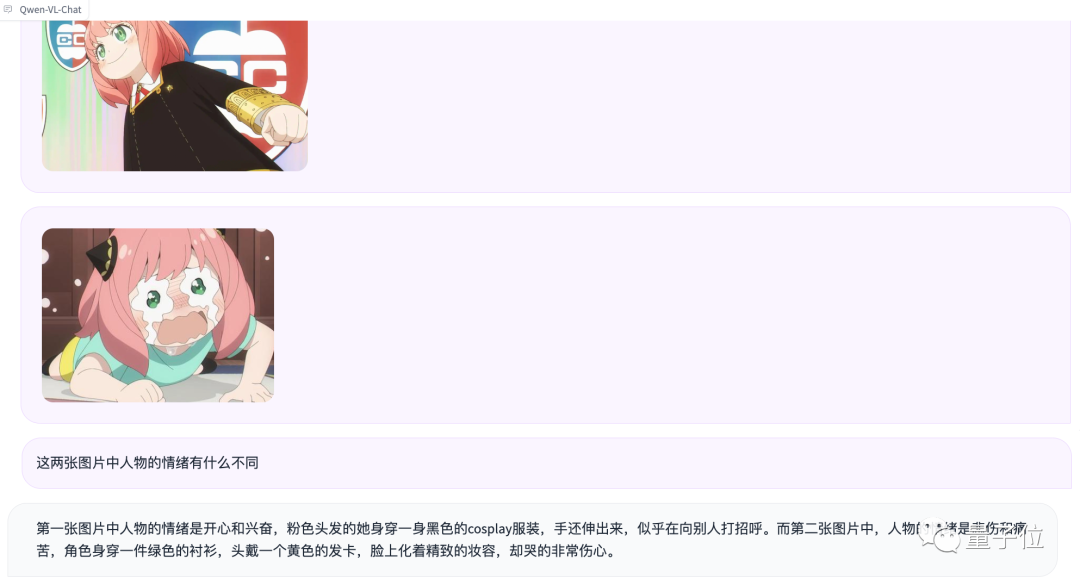
アニヤは認識されませんでしたが、感情的な判断は確かに非常に正確です(手動の犬の頭)
 #Qwen-VL は Qwen- を使用します。技術的な詳細では、ベース言語モデルとして 7B を導入し、モデルが視覚信号入力をサポートできるようにするビジュアル エンコーダー ViT と位置認識ビジュアル言語アダプターを導入します。
#Qwen-VL は Qwen- を使用します。技術的な詳細では、ベース言語モデルとして 7B を導入し、モデルが視覚信号入力をサポートできるようにするビジュアル エンコーダー ViT と位置認識ビジュアル言語アダプターを導入します。
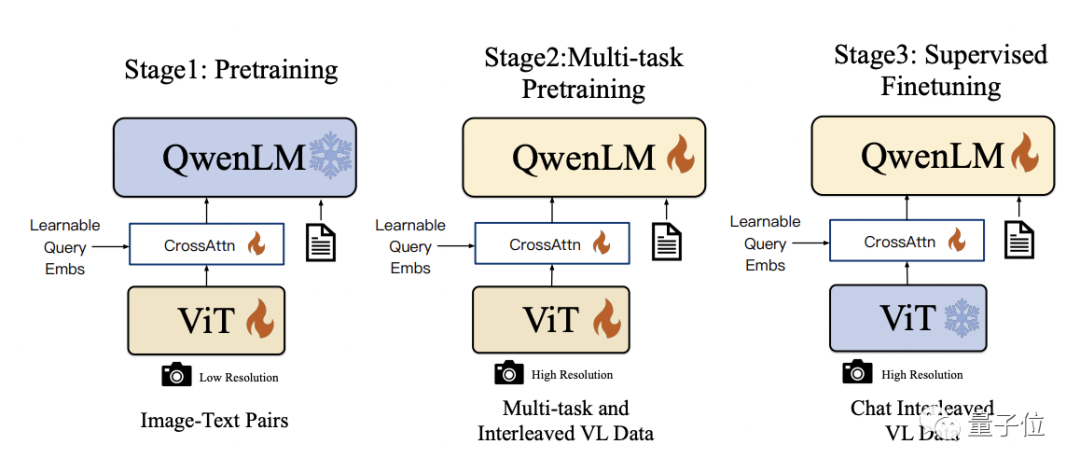
具体的なトレーニング プロセスは 3 つのステップに分かれています:
- 事前トレーニング: ビジュアル エンコーダーとビジュアル言語アダプターのみを最適化し、言語モデルをフリーズします。 。大規模な画像とテキストのペア データを使用する場合、入力画像の解像度は 224x224 です。
- マルチタスク事前トレーニング: マルチタスク共同事前トレーニング用に、VQA、テキスト VQA、参照理解などの高解像度 (448x448) マルチタスク視覚言語データを導入します。
- 監視付き微調整: ビジュアル エンコーダーをフリーズし、言語モデルとアダプターを最適化します。ダイアログ インタラクション データを使用してプロンプト チューニングを行い、インタラクティブ機能を備えた最終的な Qwen-VL-Chat モデルを取得します。
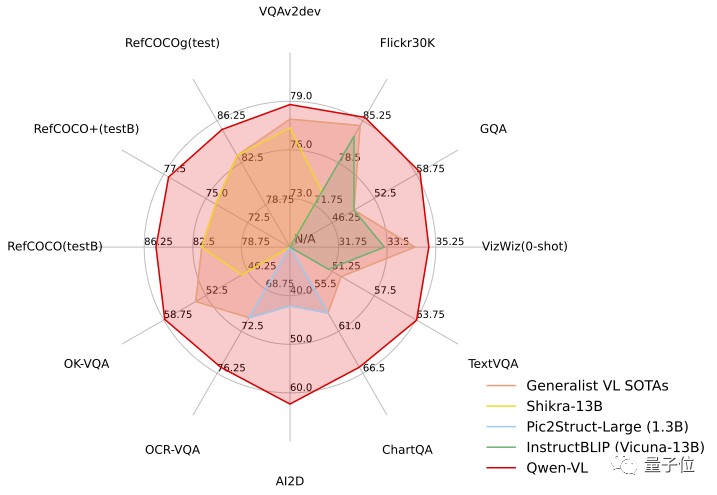
Qwen-VL の標準英語評価では、研究者はマルチモーダル タスクの 4 つの主要カテゴリ (ゼロショット キャプション/VQA/DocVQA/グラウンディング)をテストしました
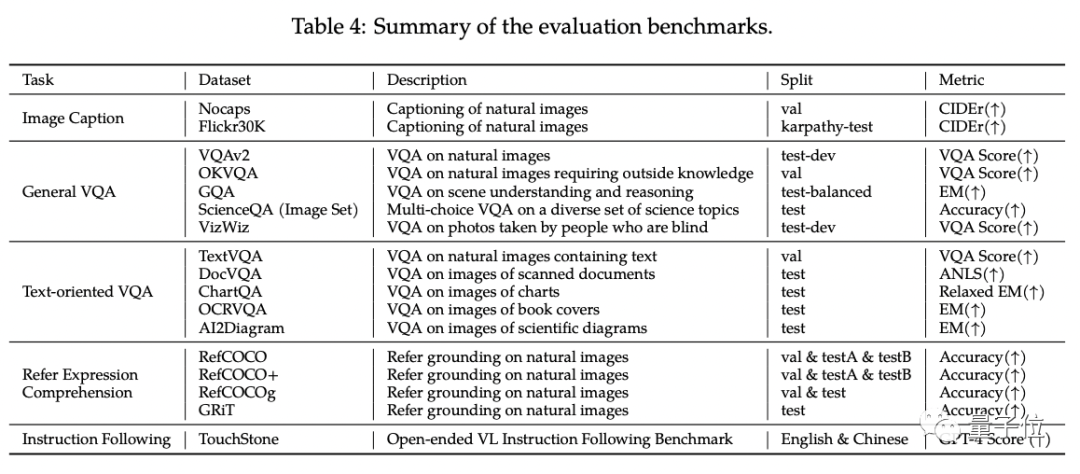
結果によると、同じサイズのオープンソース LVLM と比較した場合、Qwen-VL が最高の結果を達成しました。
さらに、研究者らは GPT に基づいて一連のスコアリング システムを構築しました。 4 メカニズムテストセットTouchStone。


プロジェクトリンク:https://modelscope.cn/ models/qwen/Qwen-VL /summary
https://modelscope.cn/models/qwen/Qwen-VL-Chat/summary
https:// hackingface.co/Qwen/Qwen -VL
https://huggingface.co/Qwen/Qwen-VL-Chat
https://github.com/ QwenLM/Qwen-VL
論文を表示するには、次のリンクをクリックしてください: https://arxiv.org/abs/2308.12966
以上がアリ巨大モデルが再びオープンソース化!完全な画像理解機能と物体認識機能を備えており、一般的な問題セット 7B に基づいてトレーニングされており、商用アプリケーションに使用可能です。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。