
ホームページ >Java >&#&チュートリアル >【おすすめ作品集】魂責め!動物園飼育員の 31 発の大砲
【おすすめ作品集】魂責め!動物園飼育員の 31 発の大砲
- Java后端技术全栈転載
- 2023-08-28 16:45:46893ブラウズ
#Zookeeper の主要な知識の概要
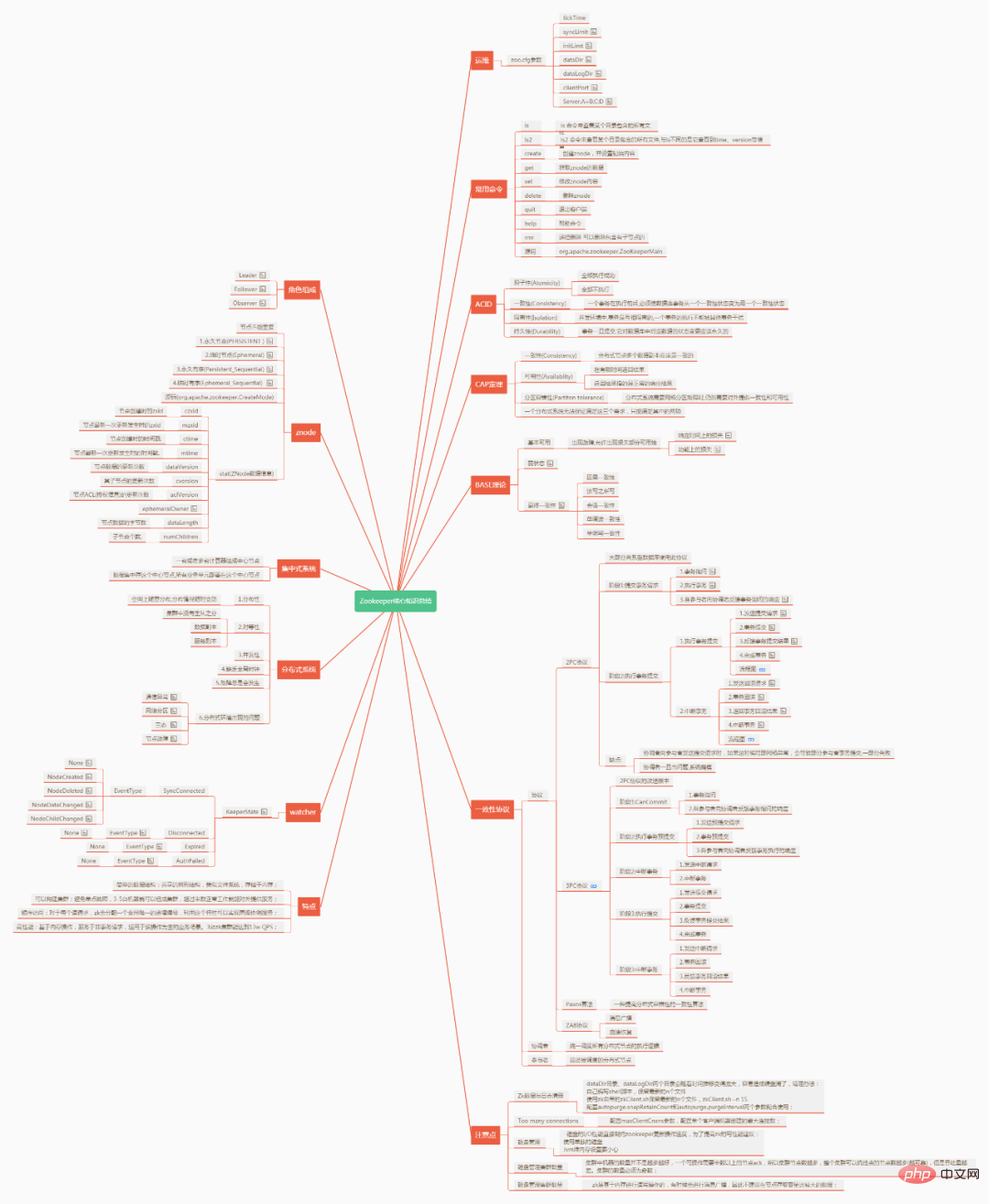
タイトルをお読みください
ZooKeeper とは何ですか? ZooKeeper は何を提供しますか? Zookeeper ファイル システム Zookeeper はどのようにしてマスター ノードとスレーブ ノードのステータスが同期していることを確認しますか? - #4 種類のデータ ノード Znode
- Zookeeper Watcher メカニズム - データ変更通知
- クライアント登録ウォッチャーはどのように実装されますか?
- Watcher のサーバー側の処理はどのように実装されますか?
- クライアントはどのようにして Watcher にコールバックするのでしょうか?
- ACL 権限制御メカニズムについてご存知ですか?
- Chroot の機能についてご存知ですか?
- セッション管理についてご存知ですか?
- サーバーの役割は何ですか?
- Zookeeper でのサーバーの動作ステータス
- データはどのように同期されますか?
- 動物園の飼育員はトランザクションの逐次一貫性をどのようにして確保しているのでしょうか?
- 分散クラスターにマスター ノードがあるのはなぜですか?
- zk ノードのダウンタイムにどう対処するか?
- #Zookeeper の負荷分散と nginx の負荷分散の違い
- Zookeeper のデプロイメント モードは何ですか?
- クラスターに必要なマシンの最小数は何ですか?クラスター ルールは何ですか?クラスター内に 3 つのサーバーがあり、ノードの 1 つがダウンしています。現時点でも Zookeeper は使用できますか? #クラスターはマシンの動的な追加をサポートしていますか?
- Zookeeper のノードに対する監視通知は永続的ですか?なぜ永続的ではないのですか?
- #Zookeeper の Java クライアントとは何ですか?
- ぽっちゃりとは何ですか?動物園の飼育員と比較するとどう思いますか?
- Zookeeper でよく使用されるコマンドについて説明しましょう。
1. ZooKeeper とは何ですか?
ZooKeeper は、オープンソースの分散調整サービスです。分散アプリケーションに一貫性サービスを提供するソフトウェアであり、分散アプリケーションは、データのパブリッシュ/サブスクリプション、ロード バランシング、ネーミング サービス、分散調整/通知、クラスター管理、マスター選出、分散ロック、分散キュー、その他の機能などのタスクを実装できます。 ZooKeeper の目標は、複雑でエラーが発生しやすい主要なサービスをカプセル化し、シンプルで使いやすいインターフェイスと、効率的なパフォーマンスと安定した機能を備えたシステムをユーザーに提供することです。 Zookeeper は、次の分散一貫性機能を保証します:- シーケンシャル一貫性
- アトミシティ
- 単一ビュー
- 信頼性
- リアルタイム (結果整合性)
2. ZooKeeper は何を提供しますか?
ファイル システム 通知メカニズム
##3. Zookeeper ファイル システム
Zookeeper は、マルチレベルのノード名前空間を提供します (ノードは znode と呼ばれます)。ファイルシステムとは異なり、これらのノードは関連するデータを設定できますが、ファイルシステムではファイルノードのみがデータを格納でき、ディレクトリノードはデータを格納できません。 「インタビューコラム」をフォローして、より詳しいインタビュー辛口情報を入手しましょう。
高スループットと低遅延を確保するために、Zookeeper はこのツリー状のディレクトリ構造をメモリ内に維持します。この機能により、Zookeeper が大量のデータを保存するために使用されるのを防ぎます。データ ストレージの上限各ノードのサイズは 1M です。#4. Zookeeper はどのようにしてマスター ノードとスレーブ ノードのステータスの同期を確保しますか?
Zookeeper の中核は、サーバー間の同期を保証するアトミック ブロードキャスト メカニズムです。このメカニズムを実装するプロトコルは、Zab プロトコルと呼ばれます。 Zab プロトコルには、リカバリ モードとブロードキャスト モードという 2 つのモードがあります。リカバリ モード
サービスの開始時、またはリーダーがクラッシュした後、Zab はリカバリ モードに入ります。リーダーが選出され、過半数を獲得したとき、サーバーが完了した後、リーダーとのステータス同期が完了すると、リカバリーモードが終了します。状態の同期により、リーダーとサーバーのシステム状態が確実に同じになります。
ブロードキャスト モード
リーダーがほとんどのフォロワーとステータスを同期すると、メッセージのブロードキャストを開始できます。つまり、ブロードキャスト状態になります。現時点では、サーバーが ZooKeeper サービスに参加すると、サーバーは回復モードで起動し、リーダーを検出し、ステータスをリーダーと同期します。同期が完了するとメッセージブロードキャストにも参加します。 ZooKeeper サービスは、リーダーがクラッシュするか、リーダーがフォロワーのサポートの大部分を失うまで、ブロードキャスト状態のままになります。
5. 飼育員がどのようなデータ ノードを持っているかについて話す
#手動で削除しない限り、ノードは常に Zookeeper に存在します
#EPHEMERAL-Temporary ノード
一時ノードのライフ サイクルはクライアント セッションにバインドされています。クライアント セッションが期限切れになると (クライアントと動物園管理者の間の切断が必ずしもセッションの期限切れを意味するわけではありません)、クライアントによって作成されたすべての一時ノードは、削除されました。
基本的な特性は、シーケンスが異なることを除き、永続ノードと同じです。属性がノード名の後に追加されます。親ノードによって維持される自動増加する整数値が追加されます。
EPHEMERAL_SEQUENTIAL - 一時シーケンス ノード
基本的な特性は一時ノードと同じですが、シーケンス属性が追加されています。親ノードによって維持されるノード名の後に追加される、自動増加する整数。
6. Zookeeper Watcher メカニズムについて話しましょう
Zookeeper を使用すると、クライアントはサーバー上の Znode に Watcher を登録できます。サーバー上の指定されたイベントによって、このウォッチャーがトリガーされます。サーバーは、分散通知機能を実装するために指定されたクライアントにイベント通知を送信し、クライアントはウォッチャーの通知ステータスとイベント タイプに基づいてビジネスを変更します。面接のヒントをさらに得るために、「面接コラム」に注目してください。
動作メカニズム:
(1) クライアントはウォッチャーを登録します
(2) サーバーはウォッチャーをプロセスします
(3) クライアント コールバック ウォッチャー
Watcher 機能の概要:
(1) 1 回限り
サーバーであってもクライアントであっても、Watcher がトリガーされると、Zookeeper は対応するストレージからそれを削除します。この設計により、サーバーへの負荷が効果的に軽減されます。そうでないと、ノードが非常に頻繁に更新される場合、サーバーはイベント通知をクライアントに継続的に送信することになり、ネットワークとサーバーの両方に大きな負荷がかかります。
(2) クライアントのシリアル実行
クライアントの Watcher コールバックの処理はシリアル同期処理です。
(3) 軽量
3.1. ウォッチャー通知は非常にシンプルで、イベントが発生したことをクライアントに通知するだけで、イベントの具体的な内容については説明しません。
3.2. クライアントがサーバーにウォッチャーを登録するとき、クライアントの実際のウォッチャー オブジェクト エンティティはサーバーに渡されず、クライアント リクエスト内のブール型属性でマークされるだけです。
(4) ウォッチャー イベントが非同期で送信される
ウォッチャー通知イベントがサーバーからクライアントに非同期で送信されます。これにより問題が発生します。異なるクライアントとサーバーはソケットを介して通信します。 Zookeeper 自体が順序保証を提供しているため、クライアントはイベントをリッスンするまで監視している znode の変更を認識しません。したがって、Zookeeper を使用する場合、ノードのすべての変更を監視できることは期待できません。 Zookeeper は最終的な整合性のみを保証できますが、強い整合性は保証できません。
(5) ウォッチャーの登録 getData、exists、getChildren
(6) トリガー ウォッチャーの作成、削除、setData
(7) クライアントが新しいサーバーに接続すると、セッション イベントによって監視がトリガーされます。サーバーへの接続が失われると、時計を受信できなくなります。クライアントが再接続すると、必要に応じて、以前に登録されたすべてのウォッチが再登録されます。通常、これは完全に透明です。監視が失われる可能性がある特殊なケースは 1 つだけあります。未作成の znode 上の既存の監視の場合、クライアントが切断されている間に作成され、その後クライアントが接続する前に削除された場合、この監視イベントは失われる可能性があります。
7. クライアントが Watcher 実装を登録する方法
(1) getData()/getChildren() / を呼び出す3 つの API を使用して、Watcher オブジェクトを渡します。
(2) リクエストをマークし、Watcher を WatchRegistration にカプセル化します。
(3) それを Packet オブジェクトにカプセル化し、リクエストを送信します# # サーバーへ
#(4) サーバー応答を受信後、管理用にZKWatcherManagerにWatcherを登録 (5) リクエストが返され、登録が完了します。8. サーバーがウォッチャーの実装を処理する方法
(1) サーバーはウォッチャーを受信し、保存します。 クライアント要求を受信し、要求を処理してウォッチャーを登録する必要があるかどうかを判断し、必要に応じてデータ ノードのノード パスを ServerCnxn に追加します (ServerCnxn はクライアントとサーバー間の接続を表します) 、Watcher のプロセス インターフェイスを実装します。この時点で Watcher オブジェクトに表示され、WatcherManager の WatchTable と watch2Paths に保存されます。#(2) ウォッチャー トリガー
setData() トランザクション リクエストを受信するサーバーを例として、NodeDataChanged イベントをトリガーします。
2.1 WatchedEvent のカプセル化
will notification ステータス (SyncConnected)、イベント タイプ (NodeDataChanged)、およびノード パスは WatchedEvent オブジェクトにカプセル化されます
2.2 Watcher のクエリ
WatchTable からのノード パスに基づいて Watcher を検索します
2.3 見つかりません ;クライアントがこのデータ ノードに Watcher
を登録していないことを示します2.4 検索; WatchTable と Watch2Paths から対応する Watcher を抽出して削除します (ここから、Watcher はサーバー側で 1 回限りであり、1 回トリガーされると無効になることがわかります)
(3 ) Watcher をトリガーするための処理メソッドを呼び出します。
ここでの処理は主に、ServerCnxn に対応する TCP 接続を通じて Watcher イベント通知を送信することです。
9. クライアントがウォッチャーをコールバックする方法
クライアントの SendThread スレッドがイベント通知を受信し、それを渡しますEventThread スレッド Callback Watcher に送信します。
クライアントのウォッチャー メカニズムも 1 回限りであり、一度トリガーされると、ウォッチャーは無効になります。
10. ACL 権限制御メカニズムについてご存知ですか?
UGO (ユーザー/グループ/その他) は、現在 Linux/Unix ファイル システムで使用されており、最も広く使用されている権限制御方法でもあります。これは、大まかなファイル システムのアクセス許可制御モードです。 ACL (アクセス制御リスト) アクセス制御リスト次の 3 つの側面が含まれます:##アクセス許可モード (スキーム)
(1) IP: IP アドレス粒度による権限制御
(2) ダイジェスト: 最も一般的に使用され、ユーザー名:パスワードのような権限識別子を使用して権限を構成し、さまざまなアプリケーションの区別を容易にします。権限制御
(3) ワールド: 最もオープンな権限制御方法。権限識別子「world:anyone」を 1 つだけ持つ特殊なダイジェスト モードです。
(4) スーパー: スーパー ユーザー
認可オブジェクト
認可オブジェクトは、IP アドレスやマシンなど、権限が付与されるユーザーまたは指定されたエンティティを指します。ライト。
権限
(1) CREATE: データノード作成権限。承認されたオブジェクトが Znode
の下にサブノードを作成できるようにします。 ( 2) DELETE: 子ノードの削除権限。許可されたオブジェクトがデータ ノードの子ノードを削除できるようにします。
(3) READ: データ ノードの読み取り権限。許可されたオブジェクトがデータ ノードにアクセスできるようにします。そのデータ内容や子ノードのリストなどを読み取ります。
(4) WRITE: データ ノードの更新権限。承認されたオブジェクトがデータ ノードを更新できるようにします。
(5) ADMIN: データノード管理権限、承認されたオブジェクトを許可する データ ノードで ACL 関連の設定操作を実行します
11. Chroot 機能を理解していますか
##バージョン 3.2.0 以降、Chroot 機能が追加されました。これにより、各クライアントが自身の名前空間を設定できるようになります。クライアントが Chroot を設定している場合、クライアントがサーバー上で行う操作は、そのクライアント自身の名前空間に制限されます。 Chroot を設定すると、クライアントを Zookeeper サーバーのサブツリーに適用できます。複数のアプリケーションがグループ内で Zookeeper を共有するシナリオでは、異なるアプリケーション間の相互分離を実現するのに非常に役立ちます。12. セッション管理についてご存知ですか?
バケット化戦略: 類似したセッションを同じブロックに配置する 管理Zookeeper が異なるブロックのセッションを分離し、同じブロックを統一された方法で処理できるようにするために実行されます。 分配原則:各セッションの「次回タイムアウト時点」(ExpirationTime) 計算式:ExpirationTime_ = currentTime sessionTimeoutExpirationTime = (ExpirationTime_ / ExpirationInrerval 1) *ExpirationInterval、ExpirationInterval は、Zookeeper セッションのタイムアウト チェック間隔を指します。デフォルトは、tickTimeです。
13. サーバーの役割とは
リーダー
(1) 独自のスケジューリングと処理クラスタのトランザクション処理の順序を確保するため
(2) クラスタ内の各サービスのスケジューラ
フォロワー
(1) クライアントの非トランザクションを処理するトランザクションのリクエストと転送 リーダーサーバーへのリクエスト
#(2) トランザクションリクエストの提案投票に参加#(3) リーダー選挙の投票に参加
#オブザーバー(1) バージョン 3.0 サーバーの役割は、クラスターのトランザクション処理機能に影響を与えることなく、クラスターの非トランザクション処理機能を向上させるために後で導入されます。(2) クライアントの非トランザクション要求を処理し、リーダー サーバーへのトランザクション リクエスト(3) いかなる形式の投票にも参加しない ##14. Zookeeper でのサーバーの動作ステータス#サーバーには、LOOKING、FOLLOWING、LEADING、OBSERVING の 4 つの状態があります。 (1) 探しています: リーダーのステータスを探しています。サーバーがこの状態にある場合、サーバーは現在のクラスターにリーダーが存在しないと判断するため、リーダー選出状態に入る必要があります。
(2) FOLLOWING: フォロワーのステータス。現在のサーバーの役割がフォロワーであることを示します。 (3) LEADING: リーダーのステータス。現在のサーバーの役割がリーダーであることを示します。 (4) OBSERVING: オブザーバーのステータス。現在のサーバーの役割がオブザーバーであることを示します。15. データはどのように同期されるのか教えていただけますか?
クラスター全体がリーダーの選出を完了すると、学習者 (フォロワーとオブザーバーの総称) がリーダー サーバーに再登録されます。学習者サーバーは、リーダー サーバーへの登録を完了すると、データ同期フェーズに入ります。
データ同期プロセス: (すべてメッセージングによって実行されます)
学習者がリーダーに登録
データ同期
同期確認
Zookeeper のデータ同期は通常、次の 4 つのカテゴリに分類されます。
(1) 直接差分同期 (DIFF 同期)
(2) 最初にロールバックしてから差分同期 (TRUNC DIFF 同期)
(3) ロールバック同期のみ (TRUNC 同期)
(4) 完全同期 (SNAP 同期)
データ同期の前に、リーダー サーバーはデータ同期の初期化を完了します。
peerLastZxid:
学習者サーバーが登録するときに送信される ACKEPOCH メッセージから lastZxid (学習者サーバーによって処理された最後の ZXID) を抽出します。
minCommittedLog:
リーダー サーバー プロポーザル キャッシュ キュー commitLog 最小 ZXID maxCommittedLog: リーダー サーバー プロポーザル キャッシュ キュー commitLog 最大 ZXID 直接 差分同期 (DIFF 同期) ) シナリオ:peerLastZxid は minCommittedLog と maxCommittedLog の間にあります。最初にロールバックし、次に差分同期 (TRUNC DIFF 同期) -
シナリオ:新しいリーダー サーバーは、ラーナー サーバーに存在しないトランザクション レコードが含まれていることを検出します。ラーナー サーバーにトランザクション ロールバックを実行させる必要があります。つまり、リーダー サーバー上に存在し、リーダー サーバー上に存在するものに最も近いものにロールバックします。リーダー サーバー。peerLastZxid の
ZXID ロールバック同期のみ (TRUNC 同期)
シナリオ:peerLastZxid が maxCommittedLog より大きい
完全同期 (SNAP 同期)
シナリオ 1:peerLastZxidは minCommittedLog 未満です シナリオ 2: リーダー サーバーにプロポーザル キャッシュ キューがなく、peerLastZxid が lastProcessZxid と等しくありません
#16. Zookeeper はトランザクションの逐次一貫性をどのようにして確保しますか?
zookeeper は、グローバルに増分されるトランザクション ID を使用して識別します。すべての提案には、提案されるときに zxid が追加されます。zxid は実際には 64 ビットです。番号、上位32ビットはリーダーサイクルを識別するためのエポック(ピリオド、エポック、世紀、新時代)で、新しいリーダーが生成されると自動的にエポックが増加し、下位32ビットはカウントアップに使用されます。新しいプロポーザルが生成されると、まずデータベースの2段階のプロセスに基づいて他のサーバーにトランザクションの実行要求を発行し、半数以上のマシンが実行して成功すると実行が開始されます。
#17. 分散クラスターにマスター ノードがあるのはなぜですか?
分散環境では、一部のビジネス ロジックはクラスター内の特定のマシンでのみ実行する必要があり、他のマシンが結果を共有できるため、繰り返しの計算が大幅に削減されます。 . パフォーマンスが向上するため、リーダーの選出が必要です。
#18. zk ノードのダウンタイムにどう対処するか?
Zookeeper 自体もクラスターなので、3 つ以上のサーバーを構成することをお勧めします。 Zookeeper 自体も、1 つのノードがダウンしても他のノードがサービスを提供し続けることを保証する必要があります。
フォロワーがダウンしても、アクセスを提供するサーバーはまだ 2 つあります。Zookeeper 上のデータには複数のコピーがあるため、データは失われません。
リーダーがマシンにダウンした場合、Zookeeper新しいリーダーを選出します。
ZK クラスタの仕組みは、半分以上のノードが正常であれば、クラスタは正常にサービスを提供できます。クラスターが失敗するのは、ZK ノードが多すぎて、半分または半分未満のノードしか機能しない場合に限られます。 ######それで###
3 ノードのクラスターは 1 つのノードを強制終了できます (リーダーは 2 票を獲得できます > 1.5)
2 ノードのクラスターはどのノードも強制終了できません (リーダーは 1 票を獲得できます
19. Zookeeper のロード バランシングと nginx のロード バランシングの違い
zk のロード バランシングは制御できますが、nginx は制御できます。重みの調整のみで、その他制御が必要な部分は自分で記述する必要がありますが、nginx のスループットは zk よりもはるかに優れており、業務に応じてどちらの方法を使用するかを選択する必要があると言えます。 。
#20. Zookeeper の展開モードは何ですか?
Zookeeper には 3 つの展開モードがあります:
単一マシンの展開: クラスター上で実行; クラスターのデプロイメント: 複数のクラスターが実行されています; 疑似クラスターのデプロイメント: 1 つのクラスターが複数の Zookeeper インスタンスを開始して実行します。
21. クラスターに必要なマシンの最小数は何ですか? クラスター ルールは何ですか?クラスター内に 3 つのサーバーがあり、ノードの 1 つがダウンしています。現時点でも Zookeeper は使用できますか?
クラスタ ルールは 2N 1 ユニット、N>0、つまり 3 ユニットです。サーバーの半分以上がダウンしていない限り、奇数番号のサーバーを引き続き使用できます。
#22. クラスターはマシンの動的な追加をサポートしていますか?
実は水平展開なのですが、Zookeeperはこの点があまり得意ではありません。 2 つの方法:
#すべて再起動: すべての Zookeeper サービスをシャットダウンし、構成を変更してから開始します。以前のクライアント セッションには影響しません。
1 台ずつ再起動する: マシンの半分以上が稼働しており利用可能であるという原則に基づいて、1 台のマシンを再起動してもクラスタ全体の外部サービスには影響しません。これはより一般的に使用される方法です。
#3.5 バージョンでは、動的拡張のサポートが開始されます。
#23. Zookeeper のノードに対する監視通知は永続的なものですか? ###### #########いいえ。公式声明: Watch イベントは 1 回限りのトリガーであり、Watch が設定されているデータが変更されると、サーバーはその変更を Watch が設定されているクライアントに送信して通知します。 なぜ永続的ではないのでしょうか? たとえば、サーバーが頻繁に変更され、多くの場合、監視クライアントが変更される場合、変更のたびにすべてのクライアントに通知する必要があり、ネットワークとサーバーに多大な負荷がかかります。 。
通常、クライアントは getData("/node A", true) を実行します。ノード A が変更または削除されると、クライアントは監視イベントを取得しますが、ノード A は再び変更されます。クライアントは設定しません。監視イベントなので、クライアントには送信されなくなります。 実際のアプリケーションでは、多くの場合、クライアントはサーバー上のすべての変更を知る必要はなく、必要なのは最新のデータだけです。#24. Zookeeper の Java クライアントとは何ですか?
java クライアント: zk 独自の zkclient および Apache のオープンソース キュレーター。
25. ぽっちゃりとは何ですか?それを動物園の飼育員と比較するとどう思いますか?chubby は Google からのもので、paxos アルゴリズムを完全に実装していますが、オープンソースではありません。 Zookeeper は、paxos アルゴリズムのバリアントである zab プロトコルを使用した Chubby のオープンソース実装です。
#26. Zookeeper でよく使用されるコマンドについて説明しましょう。
一般的に使用されるコマンド: ls get set create delete など。
27. ZAB アルゴリズムと Paxos アルゴリズムの関係と違いは何ですか?
同じ点:
(1) どちらもリーダー プロセスと同様の役割を持ち、複数のフォロワー プロセスの実行を調整する責任があります
(2) リーダー プロセスは、プロポーザルを送信する前に、フォロワーの半数以上が正しいフィードバックを提供するのを待ちます。
(3) ZAB プロトコルでは、各プロポーザルには、エポック値が含まれています。現在のリーダー サイクル。Paxos での名前は Ballot
です。違い:
ZAB は、高可用性の分散データ マスターおよびバックアップ システム (Zookeeper) を構築するために使用されます。Paxos は、分散型一貫性のあるステート マシン システム。
28. Zookeeper の典型的なアプリケーション シナリオ
Zookeeper は、分散データの典型的なパブリッシュ/サブスクライブ モデルです。開発者が分散データを公開およびサブスクライブするために使用できる調整フレームワーク。
Zookeeper の豊富なデータ ノードを相互利用し、Watcher イベント通知メカニズムと連携することにより、分散アプリケーションに関与する次のような一連のコア機能を構築するのに非常に便利です。
(1) データ公開・サブスクリプション #(2) ロードバランシング
#(3) ネーミングサービス #(4) 分散連携・通知
( 5) クラスタ管理
(6)マスター選出
(7)分散ロック
(8)分散キュー
29. Zookeeper にはどのような機能がありますか?
クラスター管理: ノードの生存ステータス、実行中のリクエストなどを監視します;
マスター ノードの選択: マスター ノードがハングアップした後、バックアップ ノードからの新しいもの マスター選出の 1 ラウンド、マスター ノード選出はこの選出プロセスに関するもので、Zookeeper を使用すると、このプロセスの完了を支援できます;
分散ロック: Zookeeper は、排他ロックとロックの 2 種類のロックを提供します。共有ロック。排他ロックは、一度に 1 つのスレッドだけがリソースを使用できることを意味します。共有ロックは、読み取りロックが共有され、読み取りと書き込みが相互に排他的であること、つまり、複数のスレッドが同じリソースを同時に読み取ることができることを意味します。書き込みロックが使用されている場合、それを使用できるのは 1 つのスレッドだけです。 Zookeeper は分散ロックを制御できます。
ネーミング サービス: 分散システムでは、ネーミング サービスを使用することにより、クライアント アプリケーションは、指定された名前に基づいてリソースまたはサービスのアドレス、プロバイダー、およびその他の情報を取得できます。
#30. Zookeeper の通知メカニズムについて教えてください。
クライアントは、特定の znode のウォッチャー イベントを作成します。znode が変更されると、これらのクライアントは zk 通知を受け取り、クライアントは znode の変更に基づいて応答できます。 . 業務変更などを行う。
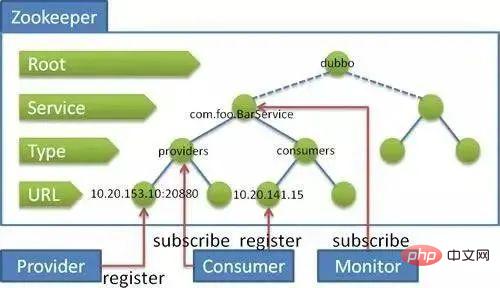
31. 動物園の飼育員とダボの関係は何ですか?
zookeeper は、サービスの登録と負荷分散の実行に使用されます。によって制御されている 呼び出し元はどのマシンがサービスを提供しているかを知っている必要がある 簡単に言えば、IP アドレスとサービス名の対応関係です。もちろん、この対応はハード コーディングを通じて呼び出し側のビジネス コードに実装することもできます。ただし、サービスを提供するマシンがハングアップした場合、呼び出し側はそれを知る方法がありません。コードが変更されない限り、要求は継続されます。サービスを提供するためにデッドマシン。 Zookeeper は、ハートビート メカニズムを通じてハングしたマシンを検出し、ハングしたマシンの IP とサービスの間の対応関係をリストから削除できます。高同時実行性のサポートについては、簡単に言えば、コードを変更せずにマシンを追加することでコンピューティング能力を向上させる、水平方向の拡張を意味します。新しいマシンを追加して ZooKeeper にサービスを登録すると、サービス プロバイダーの数が増え、より多くの顧客にサービスを提供できるようになります。
は中間層を管理するためのツールです。ビジネス層とデータ ウェアハウスの間には多くのサービス アクセスとサービス プロバイダーが存在します。スケジューリングが必要ですが、dubbo はこの問題を解決するフレームワークを提供します。 ###注意這裡的dubbo只是一個框架,至於你架子上放什麼是完全取決於你的,就像一個汽車骨架,你需要配你的輪子引擎。這個框架中要完成調度必須要有一個分散式的註冊中心,儲存所有服務的元數據,你可以用zk,也可以用別的,只是大家都用zk。
zookeeper和dubbo的關係:
Dubbo 的將註冊中心進行抽象,它可以外接不同的儲存媒介給註冊中心提供服務,有ZooKeeper,Memcached,Redis 等。
引進了 ZooKeeper 作為儲存媒介,也就把 ZooKeeper 的特性引進來。首先是負載平衡,單註冊中心的承載能力是有限的,在流量達到一定程度的時候就需要分流,負載平衡就是為了分流而存在的,一個ZooKeeper 群配合相應的Web 應用就可以很容易達到負載平衡;資源同步,單單有負載平衡還不夠,節點之間的資料和資源需要同步,ZooKeeper 叢集就天然具備有這樣的功能;命名服務,將樹狀結構用於維護全域的服務地址列表,服務提供者在啟動的時候,向ZooKeeper 上的指定節點/dubbo/${serviceName}/providers 目錄下寫入自己的URL 位址,這個操作就完成了服務的發佈。其他特色還有 Mast 選舉,分散式鎖等。
以上が【おすすめ作品集】魂責め!動物園飼育員の 31 発の大砲の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。