昨日、Meta はコード生成に特化した基本モデル Code Llama をオープンソース化し、研究および商用目的に無料で使用できます。 Code Llama シリーズ モデルには、パラメーター サイズがそれぞれ 7B、13B、34B の 3 つのパラメーター バージョンがあります。また、Python、C、Java、PHP、Typescript (Javascript)、C#、Bash などの複数のプログラミング言語をサポートします。 Meta が提供する Code Llama バージョンには次のものが含まれます:
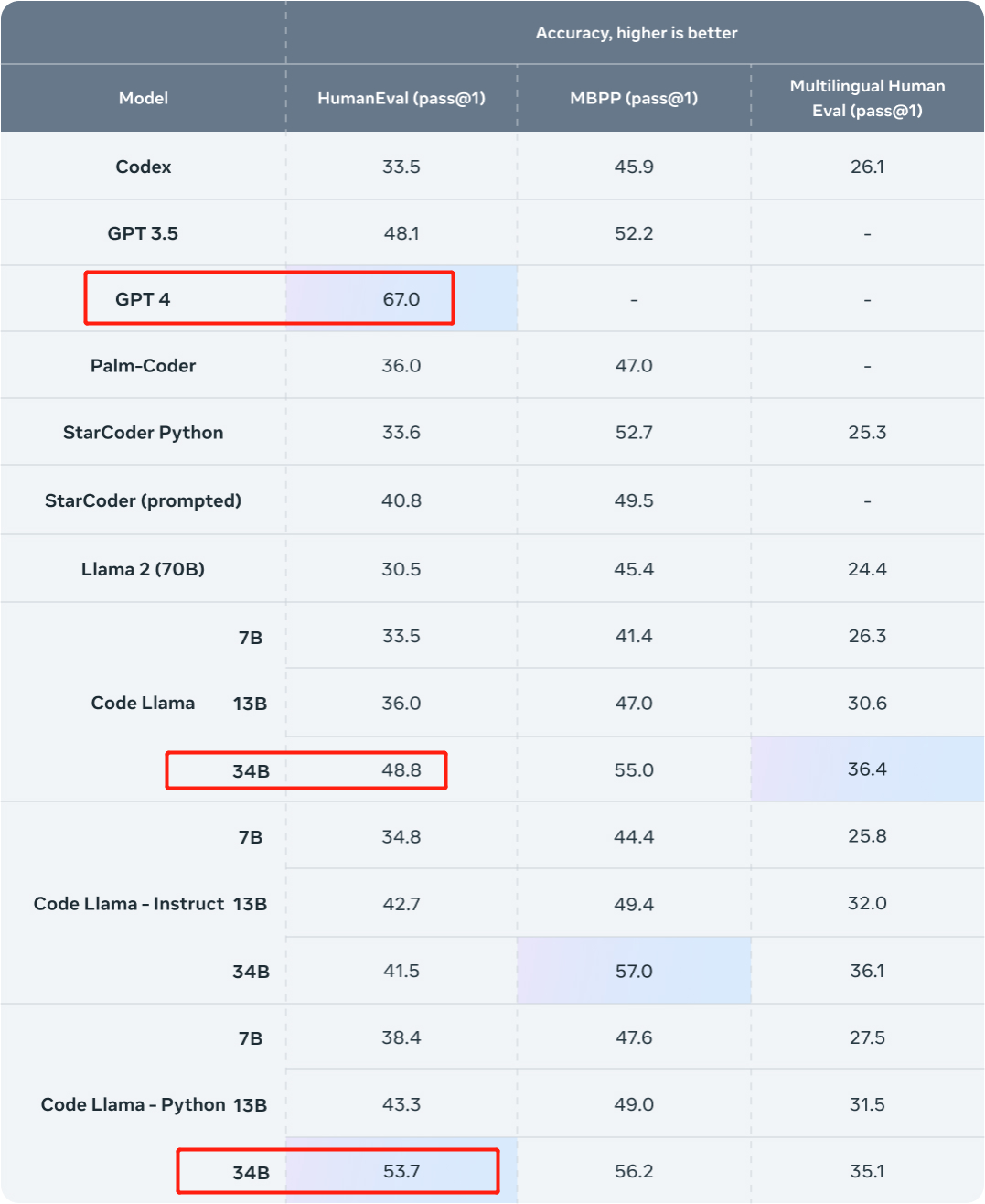
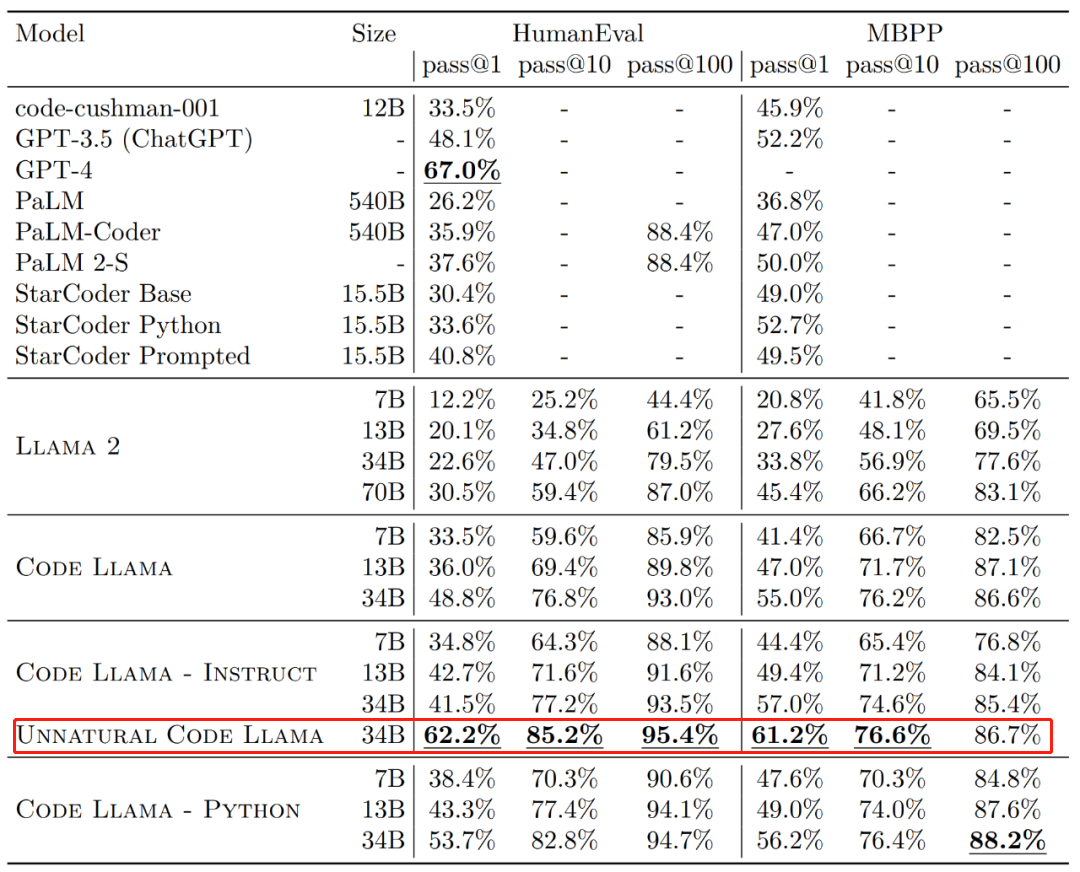
その効果 一般的に、HumanEval および MBPP データ セット上の Code Llama のさまざまなバージョンの 1 回限りの生成パス率 (pass@1) は GPT-3.5 を超えています。 さらに、HumanEval データセットにおける Code Llama の「Unnatural」 34B バージョンの pass@1 は GPT-4 に近い値です (62.2% 対 67.0%)。ただし、Meta はこのバージョンをリリースしませんでしたが、高品質のエンコードされたデータの小規模なセットでのトレーニングを通じて大幅なパフォーマンスの向上が達成されました。  #画像ソース: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
#画像ソース: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
その直後、ある研究者が GPT-4 への挑戦を開始しました。彼らは、開発者向けの AI 検索エンジンの構築を目的とした組織である Phind から来ており、この研究では、HumanEval 評価で GPT-4
を上回るために 細かく調整されたコード Llama-34B を使用しました。 Phind 共同創設者 Michael Royzen 氏は次のように述べています。「これは単なる初期の実験であり、メタ論文の「不自然なコード ラマ」の結果を再現 (そしてそれを超える) ことを目的としています。将来的には、実際のワークフローで競争力があると思われる、さまざまな CodeLlama モデルの専門家ポートフォリオを用意する予定です。 》
両方のモデルはオープンソースです:
研究者はこれら 2 つのモデルを Huggingface でリリースしました。そしてそれをチェックしてください。
- Phind-CodeLlama-34B-v1:https://huggingface.co/Phind/Phind-CodeLlama-34B-v1
- Phind -CodeLlama-34B-Python-v1: https://huggingface.co/Phind/Phind-CodeLlama-34B-Python-v1
次に、この研究がどのように実現されるかを見てみましょう。
#微調整されたコード Llama-34B が GPT-4 を上回る
## 見てみましょう。まずは結果。この研究では、Phind 内部データ セットを使用して Code Llama-34B と Code Llama-34B-Python を微調整し、それぞれ 2 つのモデル Phind-CodeLlama-34B-v1 と Phind-CodeLlama-34B-Python-v1 を作成しました。
新しく取得した 2 つのモデルは、HumanEval でそれぞれ 67.6% と 69.5% の pass@1 を達成しました。
比較のために、CodeLlama-34B pass@1 は 48.8%、CodeLlama-34B-Python pass@1 は 53.7% です。
そして、HumanEval における GPT-4 の pass@1 は 67% です (今年 3 月にリリースされた「GPT-4 テクニカル レポート」で OpenAI が発表したデータ)。
#画像ソース: https://ai.meta.com/blog/code-llama-large- language-model-coding/
## 画像ソース: https://cdn.openai.com/papers/gpt-4.pdf 微調整に関しては、データ セットがあるのが自然です。この研究では、約 80,000 の高品質なプログラミングの問題と解決策を含む独自のデータ セットに基づいて、Code Llama-34B と Code Llama-34B-Python を微調整しました。 。 このデータセットはコード補完の例を使用しませんが、代わりに指示と回答のペアを使用します。これは HumanEval データ構造とは異なります。その後、この研究では、合計約 160,000 の例を使用して、2 つのエポックにわたって Phind モデルをトレーニングしました。研究者らは、トレーニングではLoRA技術は使用されなかったが、局所的な微調整が使用されたと述べた。 さらに、この調査では DeepSpeed ZeRO 3 および Flash Attendant 2 テクノロジーも使用され、32 個の A100-80GB GPU で 3 時間を費やしてこれらのモデルとシーケンスをトレーニングしました。長さは 4096 トークンです。 さらに、この研究では、モデルの結果をより効果的にするために、OpenAI の除染手法をデータセットに適用しました。 誰もが知っているように、非常に強力な GPT-4 でさえデータ汚染のジレンマに直面します。平たく言えば、トレーニング済みモデルは評価データでトレーニングされている可能性があります。 . . この問題は LLM にとって非常に困難です。たとえば、モデルのパフォーマンスを評価するプロセスでは、科学的に信頼できる評価を行うために、研究者は次のことを確認する必要があります。問題がモデルのトレーニング データにあるかどうか。そうである場合、モデルはこれらの問題を記憶することができ、モデルを評価するときにこれらの特定の問題に対して明らかにパフォーマンスが向上します。 人は試験を受ける前に試験問題をすでに知っているようなものです。 この問題を解決するために、OpenAI は GPT-4 がデータ汚染をどのように評価するかを公開の GPT-4 技術文書「GPT-4 Technical Report」で公開しました。彼らは、このデータ汚染を定量化して評価するための戦略を開示しています。 具体的には、OpenAI は部分文字列マッチングを使用して、評価データセットと事前トレーニング データの間の相互汚染を測定します。評価データとトレーニング データは両方とも、スペースと記号をすべて削除し、文字 (数字を含む) のみを残すことによって処理されます。 各評価例について、OpenAI は 3 つの 50 文字の部分文字列をランダムに選択します (50 文字未満の場合は、例全体が使用されます)。 3 つのサンプリングされた評価部分文字列のいずれかが、処理されたトレーニング サンプルの部分文字列である場合、一致と判断されます。 これにより、汚染されたサンプルのリストが生成されます。OpenAI はこれを破棄し、再実行して汚染されていないスコアを取得します。ただし、このフィルタリング方法にはいくつかの制限があり、部分文字列の一致では、偽陽性だけでなく偽陰性 (評価データとトレーニング データの間にわずかな差がある場合) が発生する可能性があります。その結果、OpenAI は評価例の情報の一部のみを使用し、質問、コンテキスト、または同等のデータのみを活用し、回答、応答、または同等のデータを無視します。場合によっては、多肢選択オプションも除外されます。これらの除外により、誤検知が増加する可能性があります。 この部分に関して、興味のある読者は論文を参照して詳細を学ぶことができます。 論文アドレス: https://cdn.openai.com/papers/gpt-4.pdfただし、Phind が GPT-4 のベンチマークを行う際に使用した HumanEval スコアについては議論があります。 GPT-4の最新のテストスコアは85%に達したという人もいます。しかしフィンド氏は、このスコアを導き出した関連研究では汚染研究は実施されておらず、GPT-4が新たなテストを受けた際にHumanEvalのテストデータを見たかどうかを判断することは不可能だと答えた。 「GPT-4 は愚かになる 」に関する最近の研究を考慮すると、元の技術レポートのデータを使用する方が安全です。
ただし、大規模モデルの評価の複雑さを考慮すると、これらの評価結果がモデルの真の機能を反映できるかどうかは、依然として議論の余地があります。モデルをダウンロードしてご自身で体験していただけます。 書き換えた内容は以下の通りです。 参考リンク:
書き換える内容は以下の通りです: https://benjaminmarie.com/the- decontaminated-evaluation-of-gpt-4/
書き換える必要がある内容は次のとおりです: https://www.phind.com/blog/code-llama-beats-gpt4
以上がCode Llama のコーディング能力は急上昇し、HumanEval の微調整バージョンは GPT-4 よりも高いスコアを獲得し、1 日でリリースされましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。


 #画像ソース: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
#画像ソース: https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/