

 テクノロジー周辺機器AI「知識ベースのイメージ問答」を微調整しても無駄なのでしょうか? Googleが検索システムAVISをリリース:教師ありPALIを超えるサンプルはほとんどなく、精度は3倍に
テクノロジー周辺機器AI「知識ベースのイメージ問答」を微調整しても無駄なのでしょうか? Googleが検索システムAVISをリリース:教師ありPALIを超えるサンプルはほとんどなく、精度は3倍に「知識ベースのイメージ問答」を微調整しても無駄なのでしょうか? Googleが検索システムAVISをリリース:教師ありPALIを超えるサンプルはほとんどなく、精度は3倍に

大規模言語モデル (LLM) のサポートにより、画像説明、視覚的質問応答 (VQA)、オープン語彙オブジェクト検出など、視覚と組み合わせたマルチモーダル タスクが大幅に進歩しました。
ただし、現在の視覚言語モデル (VLM) は基本的に画像内の視覚情報のみを使用してタスクを完了するため、インフォームシークと OK-VQA による外部知識の支援が必要です。データセットのパフォーマンスが低下することがよくあります。

最近 Google は、外部ツールの使用を動的に定式化する大規模言語モデル (LLM) を使用する、新しい自律的な視覚情報検索手法 AVIS をリリースしました。 API の呼び出し、出力結果の分析、意思決定、その他の操作を含む戦略は、画像の質問と回答のための重要な知識を提供します。

次のリンクをクリックして論文をお読みください: https://arxiv.org/pdf/2306.08129.pdf
AVIS には主に 3 種類のツールが統合されています:
1. 画像から視覚情報を抽出するツール
2. 検索オープンワールドの知識と事実のための Web 検索ツール
#3. 視覚的に類似した画像を取得するために使用できる画像検索ツール
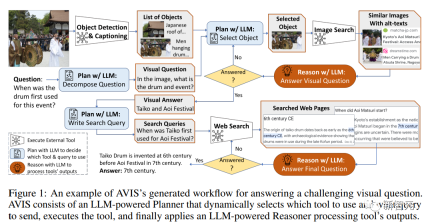
次に、大規模な言語モデルに基づくプランナーを使用してツールを選択し、各ステップで結果をクエリして、質問に対する回答を動的に生成します。
人間の意思決定のシミュレーションInfoseek および OK-VQA データセットの視覚的な問題の多くは人間にとってさえ非常に難しく、通常はさまざまな外部ツールの支援が必要です。そこで研究者らは、人間が複雑な視覚的問題をどのように解決するかを観察するために、まずユーザー調査を実施することにした。

まず、PALI、PALM、ネットワーク検索などの利用可能なツールのセットをユーザーに提供します。次に、入力画像、質問、検出されたオブジェクトの切り取り、画像検索結果からリンクされたナレッジ グラフ エンティティ、類似した画像のタイトル、関連製品のタイトル、および画像の説明を表示します。ユーザーのアクションと出力を記録し、システムが応答するように導く 2 つの方法を使用します:
1. ユーザーが行った一連の意思決定を分析して変換を構築する さまざまな状態を含むグラフ、それぞれに使用可能なアクションのセットが異なります。
#書き直された内容: AVIS 変換図 再設計された AVIS 変換図は、AVIS 変換プロセスを説明するために使用されるグラフィック表現です。この図は、AVIS のさまざまな段階とステップを明確に図示しており、ユーザーにわかりやすい方法で提示されています。この変換図を通じて、ユーザーは AVIS の動作原理と操作プロセスをよりよく理解できます。このチャートのデザインは簡潔かつ明確であり、ユーザーは AVIS 変換プロセスをすぐに把握できます。初心者も経験豊富なユーザーも、この AVIS 変換図を通じて変換プロセスを簡単に理解し、適用することができます
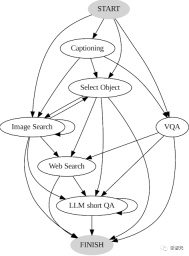
#システムのパフォーマンスと有効性を向上させるために、人間の意思決定の例を使用して、プランナーと推論者が関連するコンテキスト インスタンスと対話できるようにすることができます
全体のフレームワーク
AVIS アプローチは、視覚情報のクエリに応答するように設計された動的な意思決定戦略を採用しています。
システムは 3 つの主要なコンポーネントで構成されています。
書き直す必要がある内容は次のとおりです。 1. プランナー。処理する必要がある適切な API 呼び出しやクエリなど、後続の操作を決定するために使用されます。
2 。作業メモリ: API の実行によって得られた結果情報を保持する作業メモリ。
3. 推論器は、API 呼び出しの出力を処理するために使用され、取得した情報が最終応答を生成するのに十分であるかどうか、または追加のデータ取得が必要かどうかを判断できます
どのツールを使用するか、どのクエリをシステムに送信するかを決定する必要があるたびに、プランナーは一連のアクションを実行します。現在の状態に応じて、プランナーは潜在的なフォローも提供します。アップアクション
潜在的なアクションスペースが多すぎるために検索スペースが大きすぎるという問題を解決するには、プランナーは遷移グラフを参照して無関係なアクションを削除する必要があります。以前に実行され、作業記憶に保存されているアクション。
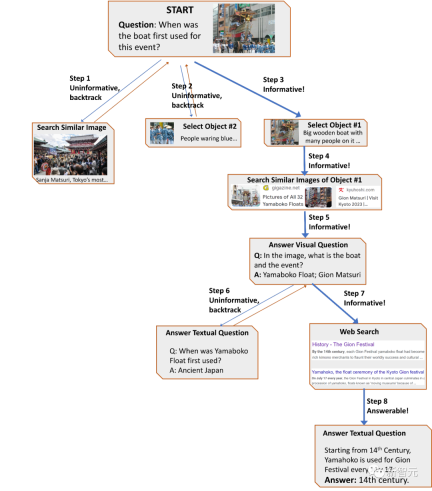
プランナーは、プロンプトを作成した後、ユーザー調査データからコンテキスト例のセットを組み立て、以前のツール操作の記録と組み合わせます。 LLM は、言語モデルへの入力として、次にアクティブ化するツールとディスパッチするクエリを決定する構造化された回答を返します。
#設計プロセス全体は、プランナーへの複数回の呼び出しによって推進され、動的な意思決定を推進し、徐々に答えを生成します。

#研究者は推論器を使用してツール実行の出力を分析し、有用な情報を抽出し、ツールの出力のカテゴリ (有益、非有益、または最終的な答え) を決定します
「回答を提供する」という結果を返す場合は、それを最終結果として直接出力してタスクを終了します; 結果が情報でなければ、プランナーに戻り、現在の状態に基づいて別のアクションを選択します; リーズナーが次のことを判断した場合ツールの出力が有用な場合、状態が変更され、制御がプランナーに戻されて、新しい状態で新しい決定が行われます。
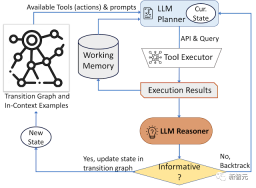
AVIS は、視覚情報の検索クエリに応答するために動的な意思決定戦略を採用しています
実験結果書き直す必要があるのは次のとおりです: ツール コレクション
#PALI 17B モデルを使用すると、画像記述モデルは入力画像の記述を生成し、検出されたオブジェクトのトリミングされた画像#PALI 17B VQA モデルを使用したビジュアル質問応答モデルは、画像と質問を入力として受け取り、テキストベースの回答を出力として受け取ります。
特定のカテゴリの Google Lens API によって提供される、Open Images データセットのスーパーセットでトレーニングされたオブジェクト検出器を使用したオブジェクト検出。高い信頼しきい値を使用し、ランキング内のランキングのみを保持します。入力画像 前方検出枠。
Google 画像検索を使用して、検出されたボックスに関連する画像の切り抜き情報を取得します。
意思決定を行う際、プランナーは各部分の利用状況を決定します。各情報には数百のトークンが含まれている可能性があり、複雑な処理と推論が必要となるため、情報の分割は別個の操作とみなされます。
場合によっては、画像には通りの名前やブランド名などのテキスト コンテンツが含まれる場合があります。 Google Lens API の光学式文字認識 (OCR) 機能を使用して、このテキストを抽出できます。
Web 検索に Google Search API を使用すると、テキスト クエリを入力して取得できます。関連するドキュメントのリンクとスニペットの出力結果のほか、直接の回答と入力クエリに関連する最大 5 つの質問を含むナレッジ グラフ パネルも提供します
実験結果
研究者らは、Infoseek および OK-VQA データセットで AVIS フレームワークを評価しました。結果から、OFA モデルや PALI モデルなどの非常に堅牢な視覚言語モデルでも取得できないことがわかります。 Infoseek データセットで微調整した後の高精度。
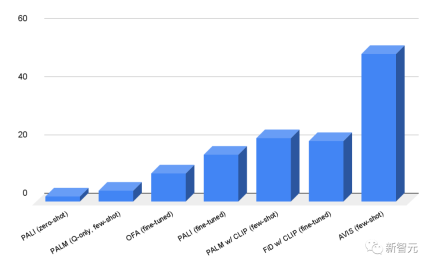
#AVIS メソッドは、微調整を行わずに、セット上の OK-VQA データで 50.7% の精度を達成しました。 、AVIS システムは、数ショット設定で 60.2% の精度を達成し、これは微調整された PALI モデルに次いで 2 番目でした。
OK-VQA のほとんどの質問と回答の例は、詳細な知識ではなく常識的な知識に依存しているため、おそらくパフォーマンスの違いが原因です。これに。 PALI は、外部知識の助けに依存することなく、モデル パラメーターにエンコードされた共通の知識を活用できます。

AVIS の重要な機能は、動的に固定シーケンスを実行するのではなく、意思決定を行う 上記の例から、さまざまな段階でさまざまなツールを使用する AVIS の柔軟性がわかります。
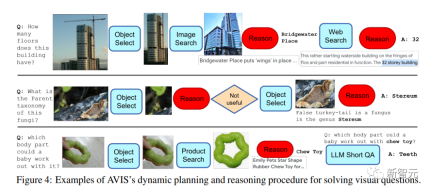
この記事の推論設計により、AVIS が無関係な情報を識別し、前の状態に戻って検索を繰り返すことができることは注目に値します。
たとえば、菌類の分類に関する 2 番目の例では、AVIS は当初、葉オブジェクトを選択するという誤った決定を下しましたが、推論機能がそれが問題と無関係であると判断した後、AVIS に再選択を促しました。 - 計画を立て、その後、偽七面鳥尾菌に関連するオブジェクトを選択することに成功し、結果として正しい答えが得られました。Stereum
結論研究者らは、A を考え出しました。新しいアプローチである AVIS は、アセンブリ センターとして LLM を使用し、さまざまな外部ツールを使用して知識集約的なビジョンの質問に答えます。
このアプローチでは、研究者らは、ユーザー調査から収集した人間の意思決定データをアンカーとして使用し、構造化フレームワークを採用し、LLM ベースのプランナーを使用して動的に意思決定ツールを選択することを選択しました。視覚的な質問に答えるために必要な情報がすべて収集されるまで、クエリ形成ツールを使用します。
以上が「知識ベースのイメージ問答」を微調整しても無駄なのでしょうか? Googleが検索システムAVISをリリース:教師ありPALIを超えるサンプルはほとんどなく、精度は3倍にの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

