
ホームページ >テクノロジー周辺機器 >AI >7,500 の軌道データ、CMU および Meta を使用したトレーニングにより、ロボットはオールラウンドなリビングルームとキッチンのレベルに到達できます。
7,500 の軌道データ、CMU および Meta を使用したトレーニングにより、ロボットはオールラウンドなリビングルームとキッチンのレベルに到達できます。

- PHPz転載
- 2023-08-24 18:17:12991ブラウズ
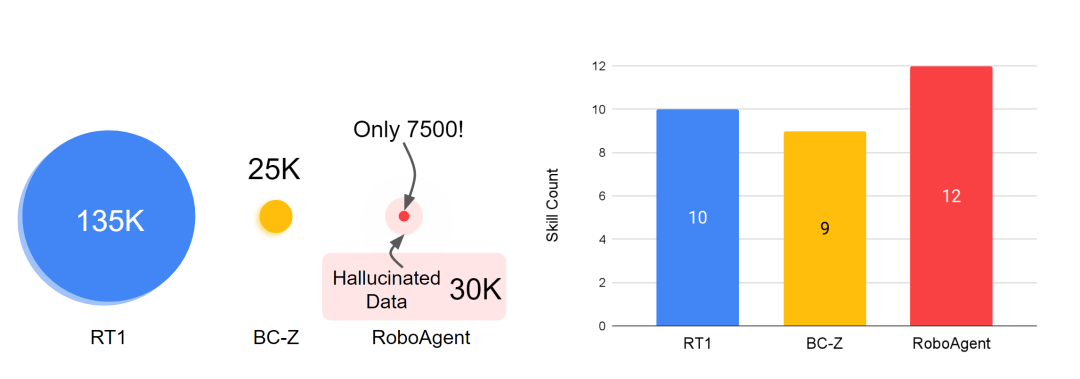
このロボットは、7500 の軌跡データを使用してトレーニングするだけで、ピッキングやプッシュに限定されず、関節オブジェクトの操作やオブジェクトの位置変更など、38 のタスクで 12 の異なる操作スキルを実証できます。さらに、これらのスキルは、未知の物体、未知の作業、さらにはまったく未知のキッチン環境など、何百もの異なる未知の状況に適用できます。こういうロボットって本当にカッコいいですね!

何十年もの間、多様な環境で任意の物体を操作できるロボットを作成することは、とらえどころのない目標でした。理由の 1 つは、そのようなエージェントをトレーニングするための多様なロボット データセットが不足していること、およびそのようなデータセットを生成できる汎用エージェントが不足していることです。
この問題を克服するには、カーネギー メロン大学の著者と Meta AI は、2 年をかけてユニバーサル RoboAgent を開発しました。彼らの主な目標は、限られたデータで複数のスキルを備えた一般的なエージェントをトレーニングし、これらのスキルをさまざまな未知の状況に一般化できる効率的なパラダイムを開発することです

RoboAgent はモジュール式で構成されています:
- #RoboPen - 長期ノンストップ運用を可能にする汎用ハードウェアで構築された分散ロボット インフラストラクチャ; #RoboHive - シミュレーションおよび現実世界の操作におけるロボット学習のための統合フレームワーク;
- RoboSet - さまざまなシナリオで日常の物体を使用する複数のスキルを表す高品質のデータセット。
- MT-ACT - 効率的な言語条件付きマルチタスクオフライン模倣学習フレームワーク。既存のロボットの経験に基づいて意味的に強化された多様なコレクションを作成し、それによってオフラインデータセットを拡張し、限られたデータ予算戦略の下で良好なパフォーマンスを回復するための、新しいポリシー アーキテクチャと効率的なアクション表現方法。
さまざまな分野で一般化できるデータ セットを構築しますさまざまな状況 ロボット エージェントはまず、広範囲をカバーするデータ セットを必要とします。スケールアップの取り組みが役立つ場合が多いことを考えると(たとえば、RT-1 は約 130,000 のロボット軌道で結果を実証しました)、限られたデータセット、多くの場合低データのコンテキストで学習システムの効率と汎化原理を理解する必要があります。過学習につながります。したがって、著者らの主な目標は、過剰適合の問題を回避しながら、低データ状況で一般化可能な一般戦略を学習できる強力なパラダイムを開発することです。
 #ロボット学習におけるスキルとデータのパノラマは重要な分野です。ロボット学習におけるスキルとは、ロボットが学習とトレーニングを通じて獲得し、特定のタスクを実行するために使用できる能力を指します。これらのスキルの開発は、大量のデータのサポートから切り離すことはできません。データはロボット学習の基礎であり、データを分析および処理することで、ロボットはデータから学習し、スキルを向上させることができます。したがって、スキルとデータはロボット学習に不可欠な 2 つの側面です。継続的に学習して新しいデータを取得することによってのみ、ロボットはスキル レベルを向上し続け、さまざまなタスクでより高い知能と効率を発揮できます
#ロボット学習におけるスキルとデータのパノラマは重要な分野です。ロボット学習におけるスキルとは、ロボットが学習とトレーニングを通じて獲得し、特定のタスクを実行するために使用できる能力を指します。これらのスキルの開発は、大量のデータのサポートから切り離すことはできません。データはロボット学習の基礎であり、データを分析および処理することで、ロボットはデータから学習し、スキルを向上させることができます。したがって、スキルとデータはロボット学習に不可欠な 2 つの側面です。継続的に学習して新しいデータを取得することによってのみ、ロボットはスキル レベルを向上し続け、さまざまなタスクでより高い知能と効率を発揮できます
RoboAgent のトレーニングに使用されるデータセット RoboSet (MT-ACT) には、7,500 個の軌跡しか含まれていません (RT-1 のデータの 18 分の 1)。このデータセットは事前に収集され、凍結されたままになります。このデータセットは、汎用ロボット ハードウェア (Robotiq グリッパーを備えた Franka-Emika ロボット) を使用した人間の遠隔操作中に、複数のタスクとシナリオにわたって収集された高品質の軌跡で構成されています。 RoboSet (MT-ACT) は、いくつかの異なる状況における 12 の固有のスキルをまばらにカバーしています。データは、毎日のキッチン活動 (お茶を入れる、パンを焼くなど) をさまざまなサブタスクに分割することによって収集され、それぞれが独自のスキルを表します。データセットには、一般的なピック アンド プレイス スキルだけでなく、拭く、蓋をする、多関節オブジェクトに関連するスキルなどの接触が多いスキルも含まれています。 書き直された内容: RoboAgent のトレーニングに使用されるデータセットである RoboSet (MT-ACT) には、わずか 7,500 個の軌跡が含まれています (RT-1 のデータより 18 分の 1)。このデータセットは事前に収集され、凍結されたままになります。このデータセットは、汎用ロボット ハードウェア (Robotiq グリッパーを備えた Franka-Emika ロボット) を使用した人間の遠隔操作中に、複数のタスクとシナリオにわたって収集された高品質の軌跡で構成されています。 RoboSet (MT-ACT) は、いくつかの異なる状況における 12 の固有のスキルをまばらにカバーしています。データは、毎日のキッチン活動 (お茶を入れる、パンを焼くなど) をさまざまなサブタスクに分割することによって収集され、それぞれが独自のスキルを表します。データセットには、一般的なピック アンド プレイス スキルだけでなく、ワイピング、キャッピング、多関節オブジェクトに関連するスキルなどの接触が豊富なスキルも含まれています

# MT- ACT: マルチタスク アクション チャンキング トランスフォーマー
RoboAgent は、2 つの重要な洞察に基づいて、低データ状況における共通ポリシーを学習します。これは、基礎となるモデルの世界に関する事前知識を活用してモード崩壊を回避し、高度にマルチモーダルなデータを取り込むことができる新しい効率的な表現戦略を採用します。 1. セマンティック強化: RoboAgent は、セマンティック強化により、既存の基本モデルから世界の事前知識を RoboSet (MT-ACT) に注入します。結果として得られるデータセットは、追加の人的コストやロボットコストを発生させることなく、ロボットの経験と世界に関する事前知識を組み合わせたものです。 SAM を使用してターゲット オブジェクトをセグメント化し、形状、色、テクスチャの変更に関して意味的に強化します。 書き換えられた内容: 1. セマンティック強化: RoboAgent は、セマンティック強化により、既存の基本モデルから世界の事前知識を RoboSet (MT-ACT) に注入します。このようにして、人間やロボットに追加のコストをかけることなく、ロボットの経験と世界に関する事前知識を組み合わせることができます。 SAM を使用してターゲット オブジェクトをセグメント化し、形状、色、テクスチャの変更に関してセマンティック拡張を実行します
#2. 効率的な戦略表現: 結果として得られるデータセットは非常にマルチモーダルであり、豊富な情報が含まれています。さまざまなスキル、タスク、シナリオ。私たちはアクション チャンキング手法をマルチタスク設定に適用し、過剰適合を回避しながら少量のデータで高度にマルチモーダルなデータセットを取得できる、斬新で効率的なポリシー表現 (MT-ACT) を開発します。
##実験結果

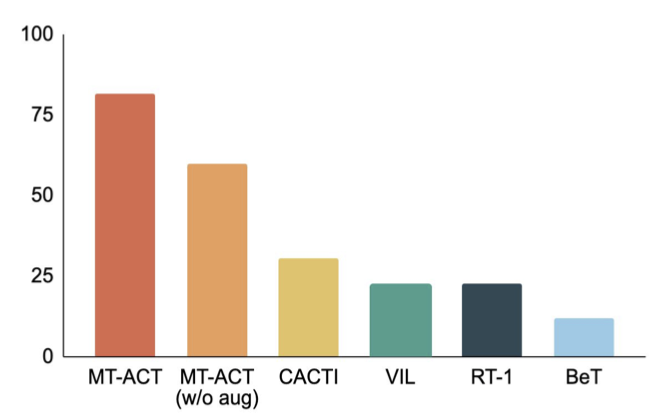
次の図は、著者が提案した MT-ACT 戦略表現といくつかの模倣学習アーキテクチャを比較しています。作成者は、オブジェクトのポーズの変更や部分的な照明の変更などの環境変更のみを使用します。以前の研究と同様に、著者らはこれが L1 一般化によるものであると考えています。 RoboAgent の結果から、アクション チャンキングを使用してサブ軌道をモデル化することは、すべてのベースライン手法よりも大幅に優れていることが明らかです。したがって、サンプル効率の学習における著者の提案した戦略表現の有効性がさらに証明されています
RoboAgent は複数の抽象化レベルで優れています
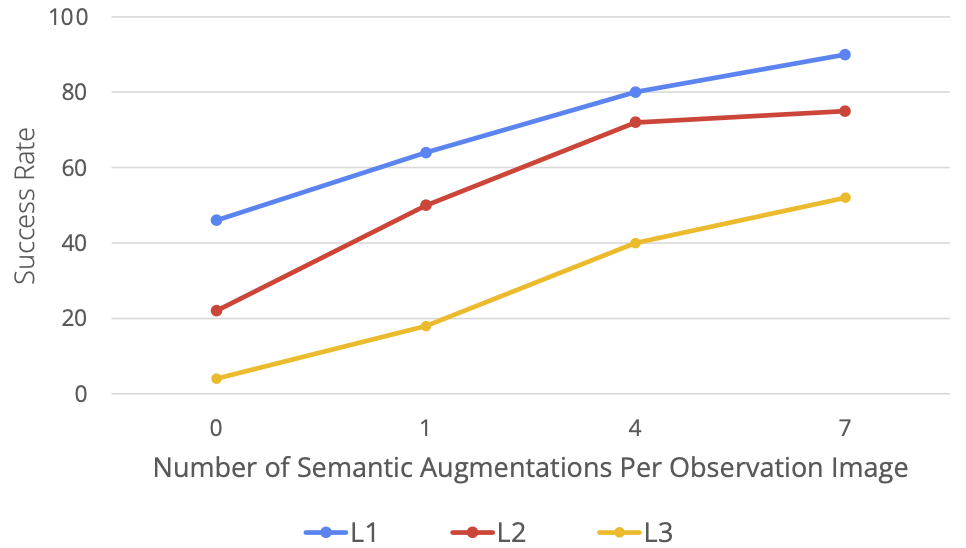
次の図は、著者がさまざまな一般化レベルでメソッドをテストした結果を示しています。同時に、一般化レベルも視覚化によって示されます。L1 はオブジェクトのポーズの変化を表し、L2 はさまざまなデスクトップの背景と干渉要因を表し、L3 は新しいスキルとオブジェクトの組み合わせを表します。次に、著者らは、各手法がこれらの一般化レベルでどのように機能するかを示します。厳密な評価研究では、MT-ACT は、特に一般化のより難しいレベル (L3) ## RoboAgent は拡張性が高い 著者らは、セマンティック強化のレベルを上げながら RoboAgent のパフォーマンスを評価し、それをアクティビティで評価される 5 つのスキルで示しました。以下の図からわかるように、データが増加すると (つまり、フレームあたりの拡張の数が増加すると)、一般化のすべてのレベルでパフォーマンスが大幅に向上します。特に注目に値するのは、より困難なタスク (L3 汎化) では、パフォーマンスの向上がより明白であることです。 RoboAgent は次のことを行うことができます。さまざまな活動で彼のスキルを実証する ##


以上が7,500 の軌道データ、CMU および Meta を使用したトレーニングにより、ロボットはオールラウンドなリビングルームとキッチンのレベルに到達できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。