
ホームページ >Java >&#&チュートリアル >6,000語以上 | Flash Killシステム設計時の注意点
6,000語以上 | Flash Killシステム設計時の注意点
- Java后端技术全栈転載
- 2023-08-23 14:28:011050ブラウズ
5 つのアーキテクチャ原則
データはできる限り小さくする必要があります
まず、ユーザーがリクエストできることです。できるだけ少ないデータで。要求されたデータには、システムにアップロードされたデータと、システムからユーザーに返されたデータ (通常は Web ページ) が含まれます。
リクエストの数はできる限り少なくする必要があります。
ユーザーがリクエストしたページが返された後、ブラウザはこのページをレンダリングするときに他の追加のリクエストを含めます。たとえば、このページは CSS/JavaScript に依存しており、画像、および Ajax リクエストはすべて「追加リクエスト」として定義されており、これらの追加リクエストはできる限り少なくする必要があります。
パスはできるだけ短くする必要があります。
ユーザーがリクエストを行ってから返されるまでのプロセスで通過する必要がある中間ノードの数です。データ。
依存関係はできるだけ少なくする必要があります
とは、ユーザー リクエストを完了するために依存する必要があるシステムまたはサービスを指します。ここでの依存関係とは、強い依存関係を指します。
高可用性
システム内の単一点は、バックアップが存在せず、リスクを制御できないことを意味するため、システム アーキテクチャにおけるタブーであると言えます。分散システム 最も重要な原則は、「高可用性」とも呼ばれる「単一点の排除」です。
建築はバランスの芸術であり、最高の建築が適応するシーンから切り離されてしまえば、すべては空虚な話になってしまいます。ここで注意しなければならないのは、ここで述べた点はあくまでも方向性であり、その方向に向けて最善を尽くすべきですが、他の要素とのバランスも考慮する必要があります。
動的データと静的データを分離する方法
動的データと静的データとは
では、動的データと静的データとは正確には何ですか?分離?いわゆる「動的データと静的データの分離」とは、実際には、ユーザーが要求したデータ (HTML ページなど) を「動的データ」と「静的データ」に分割することを意味します。簡単に言えば、「動的データ」と「静的データ」の主な違いは、ページに出力されるデータが URL、ブラウザ、時間、地域に関連しているかどうか、Cookie などのプライベート データが含まれているかどうかを確認することです。
多くのメディア Web サイトでは、特定の記事の内容は、あなたがアクセスしても、私がアクセスしても同じです。つまり、これは典型的な静的データですが、動的ページです。 今タオバオのホームページにアクセスすると、みんなが見るページは違うかもしれません。タオバオのホームページには訪問者の特性に基づいたお勧め情報がたくさん含まれており、その性格は次のように理解できます。動的データ。
#静的データをキャッシュするにはどうすればよいですか?
まず、ユーザーに最も近い静的データをキャッシュする必要があります。静的データは比較的変化しないデータであるため、キャッシュすることができます。どこにキャッシュされていますか?一般的なものは、ユーザーのブラウザー、CDN、サーバーのキャッシュの 3 つです。状況に応じて、できるだけユーザーの近くにキャッシュする必要があります。 2 番目の静的変換では、HTTP 接続を直接キャッシュします。通常のデータ キャッシュと比較して、システムの静的変換について聞いたことがあるはずです。静的変換では、単にデータをキャッシュするのではなく、HTTP 接続を直接キャッシュし、下図に示すように、Web プロキシ サーバーがリクエスト URL に応じて、対応する HTTP レスポンス ヘッダーとレスポンスボディを直接取り出して直接返します。非常にシンプルなので、HTTP プロトコルも使用せず、再アセンブルすると、HTTP リクエスト ヘッダーさえ解析する必要がありません。 3 番目に、誰が静的データをキャッシュするかということも重要です。異なる言語で書かれたキャッシュ ソフトウェアは、キャッシュされたデータの処理効率が異なります。 Java を例に挙げます。Java システム自体にも弱点があるからです (たとえば、大量の接続リクエストの処理が苦手、各接続でより多くのメモリを消費する、サーブレット コンテナによる HTTP プロトコルの解析が遅いなど)。したがって、Java 層でキャッシュを行うことはできませんが、Web サーバー層で直接キャッシュを行うことで、Java 言語レベルでのいくつかの弱点を防ぐことができます。それに比べて、Web サーバー (Nginx、Apache、Varnish など) はまた、同時に発生する大規模な静的ファイル要求の処理にも優れています。動的分離と静的分離の変換方法
一意の URL ブラウザ関連の要素を分離する 分離時間要因 非同期地域要因 Cookie の削除
動的および静的分離のためのいくつかのアーキテクチャ ソリューション
アーキテクチャの複雑さに応じて、次の 3 つのオプションが利用可能です。
単一マシンの展開物理マシンの数:
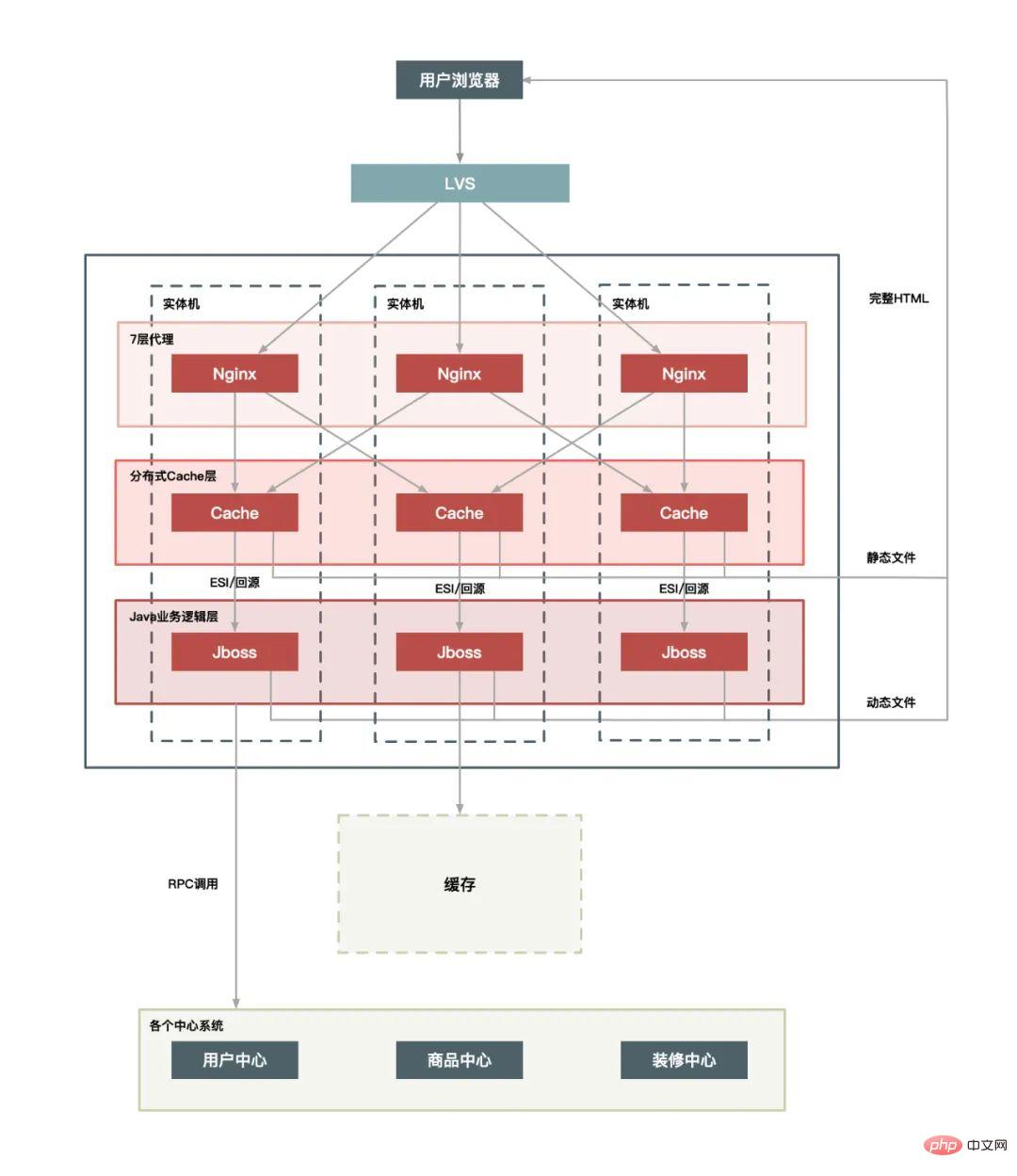
統合キャッシュ レイヤー:
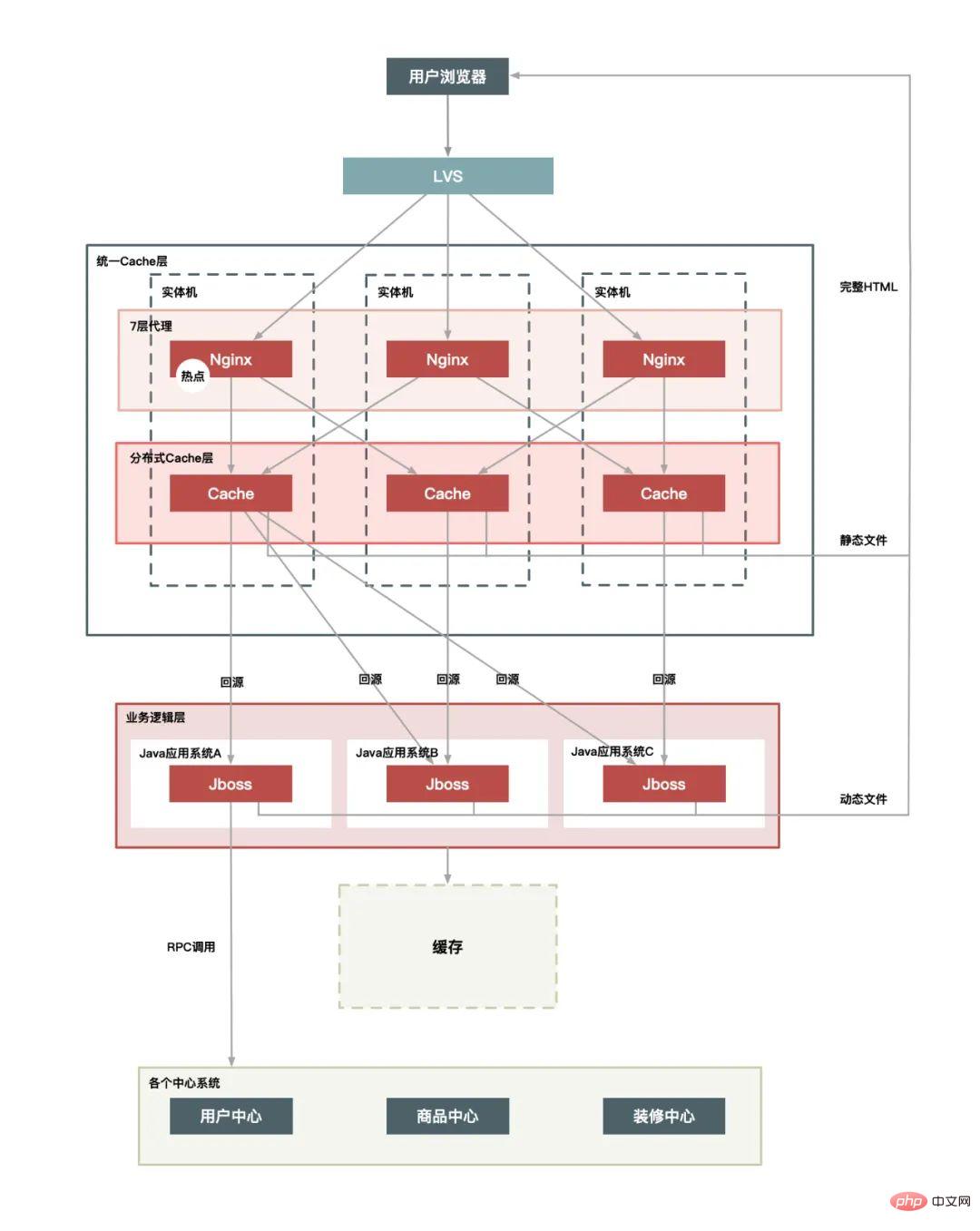
プラス CDN レイヤー:
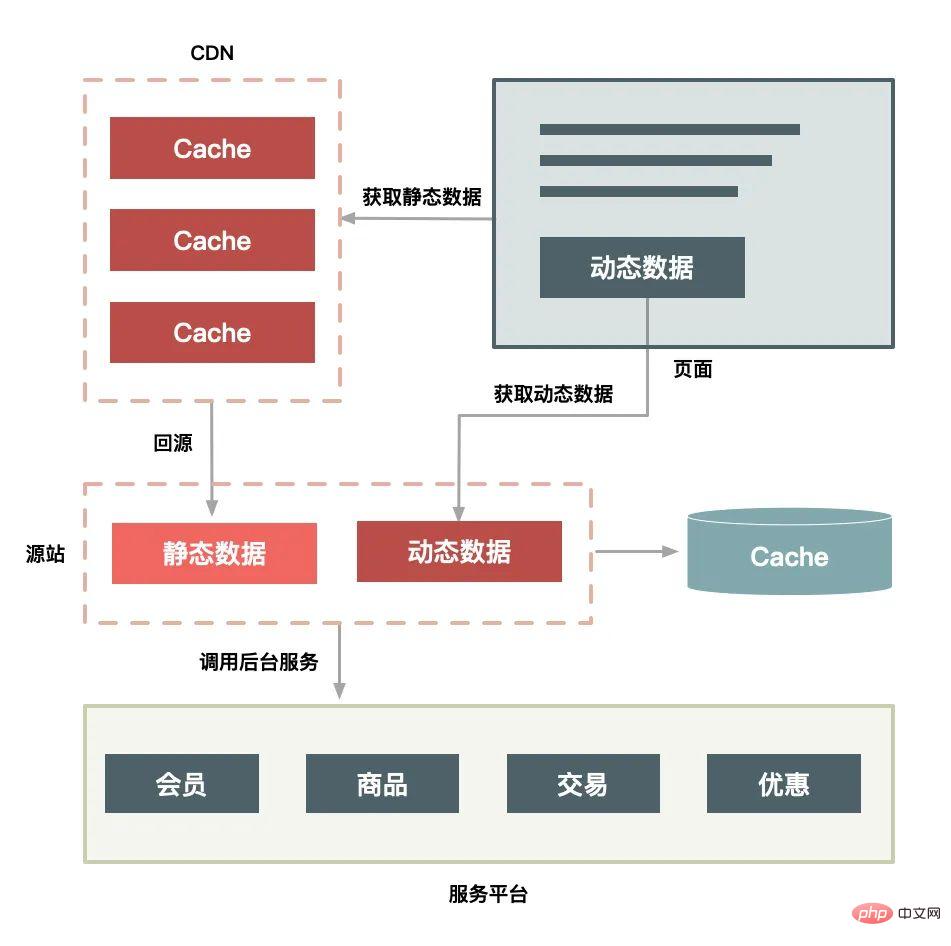
CDN 導入ソリューションには次の機能もあります:
ページ全体をユーザーのブラウザにキャッシュします; ページ全体を強制的に更新すると、CDN も要求されます; 実際の有効なリクエストは、ユーザーが「Refresh Treasure Grab」ボタンをクリックするだけです。
フラッシュセールシステムのホットデータをどのように扱うか?
「ホットスポット」とは
ホットスポットは、ホットスポット操作とホットスポット データに分類されます。
大量のページ更新、大量のショッピング カートの追加、ダブル イレブンの 0:00 に行われる大量の注文など、いわゆる「ホット オペレーション」はすべてこれに属します。このタイプの操作に。システムの場合、これらの操作は「読み取りリクエスト」と「書き込みリクエスト」に抽象化できます。これら 2 つのホットスポット リクエストは、まったく異なる方法で処理されます。読み取りリクエストの最適化スペースはより大きくなりますが、書き込みリクエストのボトルネックは通常、最適化の考え方はCAP理論に基づいてバランスを取ることですが、この内容については「在庫削減」の記事で詳しく紹介します。
「ホットスポット データ」は、ユーザーのホットスポット要求に対応するデータ、つまり、理解しやすいものです。ホットスポット データは、「静的ホットスポット データ」と「動的ホットスポット データ」に分類されます。
いわゆる「静的ホットスポット データ」とは、事前に予測できるホットスポット データを指します。たとえば、登録を通じて事前に販売者を除外し、登録システムを通じてこれらの人気商品をマークすることができます。さらに、ビッグデータ分析を使用して、人気の製品を事前に発見することもできます。たとえば、過去の取引記録やユーザーのショッピング カートの記録を分析して、どの製品がより人気があり、よりよく売れているのかを発見します。これらはすべて、可能性のあるホットスポットです。事前に分析することができます。
いわゆる「動的ホットスポット データ」とは、事前に予測できず、システムの動作中に一時的に生成されるホットスポットを指します。たとえば、販売者が Douyin で広告を掲載すると、その商品はすぐに人気になり、短期間で大量に購入されるようになります。
ホットスポットの操作はユーザーの行動であるため変更することはできませんが、いくつかの制限や保護を設けることはできますので、この記事では主にホットスポットのデータを最適化する方法を紹介します。
ホットスポット データの検出
静的ホットスポット データの検出 -
動的ホットスポット データの検出
ホットスポット データの処理
最適化
ホットスポット データを最適化する最も効果的な方法は、ホットスポット データをキャッシュすることです。ホットスポット データが静的データから分離されている場合、静的データは長期間キャッシュできます。ただし、ホットスポット データのキャッシュは、どちらかというと「一時的な」キャッシュです。つまり、静的データであっても動的データであっても、キューに数秒間短時間キャッシュされます。キューの長さは制限されているため、次のキャッシュに置き換えることができます。 LRU 除去アルゴリズム。
制限
制限はどちらかというと保護メカニズムであり、制限する方法はたくさんあります。たとえば、アクセスされているアイテムの ID に対して一貫性のあるハッシュを実行し、そのハッシュに基づいてバケットに分類します。特定のホット プロダクトがサーバー リソースを占有しすぎて、他のリクエストがサーバーから処理リソースを受け取らないようにするために、ホット プロダクトはリクエスト キューに制限されます。
分離
フラッシュ セール システム設計の第一原則は、このホット データを分離することです。リクエストの 1% が残りの 99% に影響を与えないようにして、その後分離します。この 1% のリクエストに対してターゲットを絞った最適化を行う方が便利です。分離は、ビジネス分離、システム分離、データ分離に分類できます。
交通ピークを抑える方法
都市の道路と同じように、朝のピークと夕方のピークの問題があるため、ピークをシフトし、交通制限。
ピーク クリッピングの存在により、第一にサーバー側の処理がより安定し、第二にサーバーのリソース コストが節約されます。
フラッシュ セール シナリオの場合、ピーク クリッピングは、一部の無効なリクエストを減らして除外するために、基本的にユーザー リクエストの発行を遅らせます。これは、「リクエストの数はできる限り少なくすべきである」という原則に従います。
トラフィック ピーク削減のアイデア
キュー
トラフィックをピークにするには、メッセージ キューを使用して瞬間的なトラフィックをバッファリングすることが最も簡単に考えられます。中間では、一方の端で瞬間的なトラフィックのピークを処理するためにキューが使用され、もう一方の端ではメッセージがスムーズにプッシュされます。
メッセージ キューに加えて、次のような同様のキューイング方法が多数あります。
スレッド プールを使用してロックして待機することも、一般的なキューイング方法です。 先入れ先出しや先入れ後出しなどの一般的なメモリ キューイング アルゴリズムの実装; シリアル化リクエストをファイルに保存し、ファイルを順番に読み取り (MySQL binlog に基づく同期メカニズムなど)、リクエストなどを復元します。
これらの方法には共通の特徴があることがわかります。それは、「1 ステップ操作」を「2 ステップ操作」に変換することです。ステップ操作はバッファーの役割に使用されます。
#パフォーマンスの最適化
- エンコーディングの削減
- シリアル化の削減 #Java Ultimate Optimization
- 同時読み取りの最適化
これは、非常に重要ですが、他の手順はすべて補助的なものです。在庫が 100 個ある場合は、100 個を販売してデータベース内で 0 にします。何が問題ですか?はい、理論的にはそうなりますが、特定のビジネス シナリオでは、「在庫を削減する」ことはそれほど単純ではありません。
在庫を減らす方法は何ですか。商品ページの「今すぐ購入する」ボタンをクリックし、情報を確認して「注文を送信する」をクリックしてください。 Next Single オペレーションと呼ばれます。注文後、支払い操作を完了して初めて実際に購入できるようになります。これは、「安全はポケットに」という言葉の通りです。
在庫を削減するには通常、いくつかの方法があります:
注文後に在庫を減らす
つまり、購入者が注文した後、購入者が購入した数量が製品の総在庫から差し引かれます。在庫削減のための発注は、在庫を削減する最も簡単な方法であり、最も正確な制御方法でもあります. 発注すると、商品の在庫はデータベースのトランザクションメカニズムを通じて直接管理されるため、売れすぎた状態が発生することはありません発生しない。ただし、注文後に支払いをしない人もいることを知っておく必要があります。
在庫削減のための支払い
つまり、購入者が注文した後、在庫はすぐには削減されませんが、ユーザーが支払うまで実際に在庫は削減されます。それ以外の場合、在庫は他の購入者に保持されます。ただし、支払いが行われて初めて在庫が削減されるため、同時実行性が比較的高い場合、商品が他の人に購入されている可能性があり、注文後に購入者が支払いを行えない状況が発生する可能性があります。
在庫の保留
#この方法は比較的複雑で、購入者が注文した後、在庫は一定期間 (10 分など) 保留されます。この時間を超えると、在庫は自動的に解放され、解放後も他の購入者が購入を続けることができます。購入者が支払う前に、システムは注文の在庫がまだ予約されているかどうかを確認します。予約がない場合は、源泉徴収が再度試行されます。在庫が不十分な場合 (つまり、源泉徴収が失敗した場合)、支払いは行われません。続行が許可されます; 源泉徴収が成功した場合、支払いが完了し、在庫が実際に差し引かれます。高可用性構築はどこから始めるべきか
システムの高可用性構築に関して、実際に考慮する必要があるのはシステム プロジェクトです。つまり、次の図に示すように、実際にはシステム構築のライフサイクル全体を通じて実行されます。アーキテクチャ フェーズ
アーキテクチャ フェーズでは、主にシステムのスケーラビリティとフォールト トレランスを考慮し、システム内の単一点の問題を回避します。例えば、複数のコンピュータ室を単位として配備する場合、ある都市の特定のコンピュータ室が全体的に障害を起こしても、Webサイト全体の運用には影響しません。
コーディング段階
コーディングで最も重要なことは、コードの堅牢性を確保することです。たとえば、リモート呼び出しの問題が関係する場合、適切なタイムアウト終了メカニズムが必要です。返された結果がプログラムの処理範囲を超えないようにするために、最も一般的な方法は、エラー例外をキャプチャし、予期せぬエラーに対するデフォルトの処理結果を用意することです。
テスト フェーズ
テストは主に、テスト ケースが確実にカバーされていることを確認し、最悪のケースが発生した場合に対応する処理手順があることを確認することを目的としています。
リリース フェーズ
また、公開時にエラーが発生する可能性が最も高いため、公開時に注意する必要がある点がいくつかあります。緊急ロールバックメカニズム。
実行フェーズ
実行時間は、システムの通常の状態です。システムは、ほとんどの時間、実行状態になります。実行段階で最も重要なことは、システムの通常の状態です。システムを正確かつタイムリーに監視することが重要であり、問題が発見された場合には正確なアラームを発することができ、トラブルシューティングを容易にするためにアラーム データは正確かつ詳細である必要があります。
障害が発生した場合
障害が発生した場合、まず最も重要なことは、プログラムの問題により製品の価格が間違っていた場合など、損失を時間内に食い止めることです。 、製品を棚から削除するか、時間内に購入リンクを閉じる必要があり、重大な資産の損失を防ぎます。次に、タイムリーにサービスを復元し、原因を特定して問題を解決できる必要があります。
大量のトラフィックが発生した場合、システムの通常の動作を最大限に高めるにはどうすればよいでしょうか?
ダウングレード
いわゆる「ダウングレード」とは、システムの容量が一定のレベルに達すると、システムの一部の非コア機能が制限されるか、または制限されることを意味します。シャットダウンして限られたリソースを削減し、よりコアなビジネスのために予約されています。これは目的を持った計画的な実行プロセスであるため、ダウングレードの場合は通常、実行を調整するための一連の計画を立てる必要があります。システム化すれば、計画体系と切替体系でデグレードを実現できます。
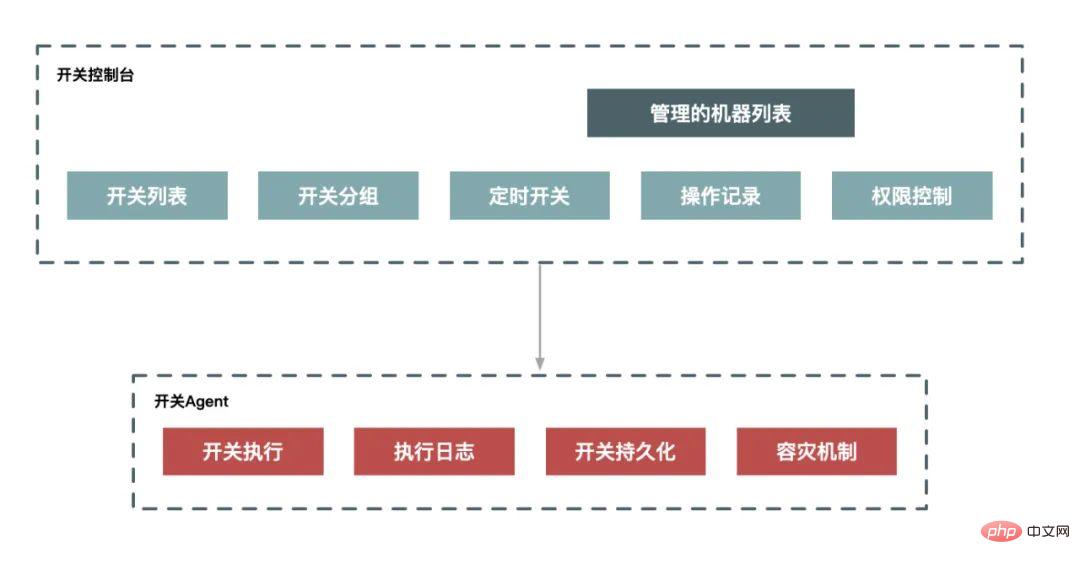
電流制限
電流制限とは、システム容量がボトルネックに達したときに、制限することでシステムを保護する必要があることを意味します。手動でスイッチを実行するだけでなく、自動保護手段もサポートします。
クライアント電流制限とサーバー電流制限の長所と短所:
クライアント電流制限には、リクエストの発行を制限し、無駄なリクエストを減らすことでシステムの消費量を削減するという利点があります。欠点は、クライアントが分散している場合、適切な電流制限しきい値を設定できないことです。しきい値の設定が小さすぎると、サーバーがボトルネックに達する前にクライアントが制限されますが、設定が大きすぎると制限されません。制限の役割。
サーバー側電流制限の利点は、サーバーの性能に応じて適切な閾値を設定できることですが、欠点は、制限されるリクエストが無効なリクエストであり、その無効なリクエストを処理すること自体がサーバーリソースを消費することです。
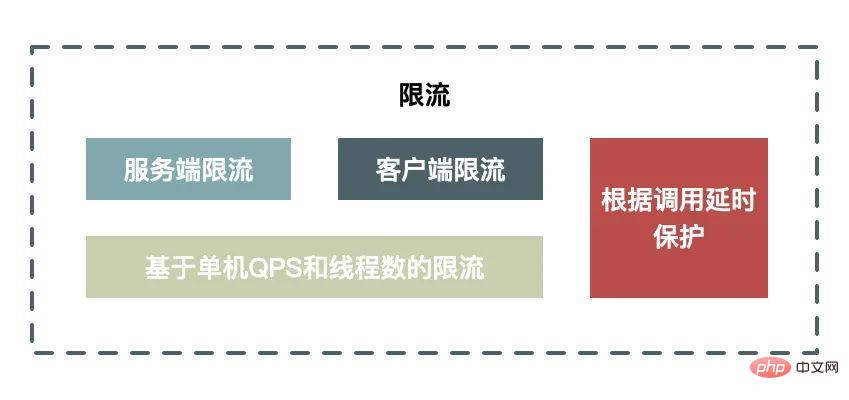
一般的な電流制限アルゴリズム
カウンター (固定ウィンドウ) アルゴリズム
カウンターこのアルゴリズムでは、カウンターを使用して期間内のアクセス数を蓄積し、設定された電流制限値に達すると、電流制限ポリシーがトリガーされます。次のサイクルの開始時にクリアされ、再びカウントされます。
このアルゴリズムは、スタンドアロンまたは分散環境での実装が非常に簡単で、redis の incr アトミック自己インクリメントとスレッド セーフを使用して簡単に実装できます。
スライディング ウィンドウ アルゴリズム
スライディング ウィンドウ アルゴリズムは、期間を N 個の小期間に分割し、各小期間内の訪問数を記録し、その期間に従ってそれらを削除します。タイムスライディング マイナーサイクルが期限切れになりました。このアルゴリズムは、固定ウィンドウ アルゴリズムの重大な問題をうまく解決できます。
リーキーバケットアルゴリズム
リーキーバケットアルゴリズムは、アクセスリクエストが到着したときに、アクセスリクエストを直接リーキーバケットに入れることです。現在の容量が上限(現在の容量)に達した場合、制限値)、それは破棄されます (電流制限ポリシーをトリガーします)。リーキー バケットは、リーキー バケットが空になるまで、固定レートでアクセス リクエストを解放します (つまり、リクエストは通過します)。
トークン バケット アルゴリズム
トークン バケット アルゴリズムでは、プログラムは、トークン バケットにトークンが追加されるまで、r (r=期間/現在の制限値) のレートでトークンを追加します。トークン バケットがいっぱいです。リクエストが到着すると、トークン バケットからトークンをリクエストします。トークンが取得された場合、リクエストは渡されます。そうでない場合は、現在の制限ポリシーがトリガーされます。
# # サービス拒否
電流制限では問題を解決できない場合、最後の手段はサービスを直接拒否することです。システム負荷が特定のしきい値に達すると (たとえば、CPU 使用率が 90% に達するか、システム負荷値が 2*CPU コアに達すると、システムはすべてのリクエストを直接拒否します。この方法は最も暴力的ですが、最も効果的なシステム保護方法でもあります) 。たとえば、フラッシュ セール システムでは、次の側面で過負荷保護を設計します: フロントエンド Nginx で過負荷保護を設定します。マシンの負荷が特定の値に達すると、HTTP リクエストは直接拒否され、 503 エラー コードが返される Java では、オーバーロード保護を備えたレイヤーを設計することもできます。 サービス拒否は、最悪のシナリオの発生を防ぎ、サーバーが長期間完全にサービスを提供できなくなることを防ぐための最後の手段の解決策であると言えます。このようなシステム過負荷保護は、過負荷時にはサービスを提供できませんが、システムは引き続き動作し、負荷が低下した場合には簡単に回復できるため、すべてのシステムおよびすべてのリンクがこのバックアップ計画を設定して、最悪のシナリオにシステムを備える必要があります。保護下にあります。キャッシュの問題
キャッシュ雪崩
データがキャッシュにロードされていないか、大規模なエラーでキャッシュが失敗します。すべてのリクエストがデータベースを検索するため、データベース、CPU、メモリの過負荷、さらにはダウンタイムが発生します。単純な雪崩プロセス:
1) Redis クラスターの大規模障害;
2) キャッシュ障害、しかしキャッシュ サービスへのアクセス要求が依然として大量に存在するRedis;
3) 多数の Redis リクエストが失敗した後、リクエストはデータベースに転送されました;
4) データベース リクエストが急増し、データベースが強制終了されました;
##5) アプリケーション サービスのほとんどはデータベースおよび Redis サービスに依存しているため、すぐにサーバー クラスターの雪崩を引き起こし、最終的にはシステム全体が完全に崩壊します。解決策:
事前に: 高可用性キャッシュ
高可用性キャッシュは、キャッシュ全体の障害を防ぐためのものです。個々のノード、マシン、さらにはコンピューター室がシャットダウンされた場合でも、システムは引き続きサービスを提供でき、Redis Sentinel と Redis Cluster は両方とも高可用性を実現できます。進行中: キャッシュのダウングレード (一時的なサポート)
アクセス数が急激に増加し、サービスに問題が発生した場合に、サービスを引き続き利用できるようにするにはどうすればよいですか。中国で広く使用されている Hystrix は、溶断、ダウングレード、電流制限という 3 つの方法を使用して、雪崩後の損失を削減します。データベースが死んでいないかぎり、システムはいつでもリクエストに応答できます。12306 年の春節には毎年ここに来るのではありませんか?まだ応答できる限り、少なくともチケットを手に入れるチャンスはあります。
その後: Redisのバックアップと高速ウォームアップ
1) Redisデータのバックアップとリカバリ
2) 高速キャッシュのウォームアップ
キャッシュの故障
#キャッシュの故障とは、ホットスポット データ ストレージの有効期限が切れたときに、複数のスレッドが同時にホットスポット データを要求することを意味します。キャッシュの有効期限が切れたばかりなので、すべての同時リクエストはデータベースに送られてデータをクエリします。解決策:
実際、ほとんどの実際のビジネス シナリオでは、キャッシュの故障はリアルタイムで発生しますが、データベースに大きな負荷がかかることはありません。一般的な企業のビジネスでは、同時実行の量はそれほど多くありません。もちろん、不幸にもこのようなことが起こった場合は、これらのホットスポット キーが期限切れにならないように設定できます。もう 1 つの方法は、ミューテックス ロックを使用してクエリ データベースへのスレッド アクセスを制御することですが、これによりシステムのスループットが低下するため、実際の状況では使用する必要があります。キャッシュペネトレーション
キャッシュペネトレーションとは、明らかに存在しないデータをクエリすることを指します。キャッシュにはデータに関する情報がないため、データベース層に直接送信されます。システムレベルで見ると、キャッシュ層を突き抜けてデータベースに直接到達するようで、これをキャッシュペネトレーションと呼びますが、キャッシュ層の保護がなければ、この種の存在してはいけないデータに対するクエリは危険である可能性があります。絶対に存在しないこの種のデータを誰かが悪意を持って使用し、システムに頻繁にリクエストを行うと、正確にはシステムを攻撃することになります。リクエストはデータベース層に到達し、データベースが麻痺し、システム障害を引き起こします。
ソリューション:
キャッシュペネトレーション業界のソリューションは比較的成熟しており、主に一般的に使用されているものは次のとおりです:
-
ブルーム フィルタ: ハッシュ テーブルに似たアルゴリズムで、考えられるすべてのクエリ条件を使用してビットマップを生成します。このビットマップは、データベース クエリの前にフィルタリングするために使用されます。それらの中にない場合は、直接フィルタリングされるため、ビットマップのコストが削減されます。データベースレベルの圧力。 Null 値のキャッシュ: 比較的単純なソリューションです。存在しないデータを初めてクエリした後、キーは対応する null 値 (null またはキーのみ) と照合されます。キャッシュに保存されますが、このキーに対する短時間での大量の攻撃に対処できるように、有効期限を数分などと短く設定しています。値がビジネスに関連していない可能性があるため、その存在はほとんど重要ではなく、クエリは攻撃者によって開始される可能性がないため、長期間保存する必要がなく、早期に無効化することができます。 。
概要
この記事は理論的な記事であるため、全体にコードは 1 行もありません。記事にも記載されていますが、基本的にはフラッシュセールシステムで起こったことであり、それぞれのシステムで発生する可能性のある問題は異なります。
以上が6,000語以上 | Flash Killシステム設計時の注意点の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。