
ホームページ >テクノロジー周辺機器 >AI >さまざまなスタイルの VCT ガイダンスを 1 つの画像で簡単に導入できます。
さまざまなスタイルの VCT ガイダンスを 1 つの画像で簡単に導入できます。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-08-22 13:49:041414ブラウズ
近年、画像生成テクノロジーは多くの重要な進歩を遂げてきました。特に、DALLE2 や Stable Diffusion などの大型モデルのリリース以来、テキスト生成画像技術は徐々に成熟しており、高品質画像生成には幅広い実用的なシナリオがあります。しかし、既存の画像の詳細な編集は依然として困難な問題です
一方で、テキスト記述の制限により、既存の高品質テキスト画像モデルは、画像を説明的に編集するにはテキストのみを使用できますが、特定の効果についてはテキストで説明するのが困難です。一方、実際のアプリケーション シナリオでは、 画像調整編集タスクには参照画像が少数しかないことがよくあります。 これにより、データ量が少ない場合、特に参照画像が 1 つしかない場合、トレーニングに大量のデータを必要とする多くのソリューションが機能することが困難になります。
最近、NetEase Interactive Entertainment AI Lab の研究者は、単一の画像ガイダンスに基づいた 画像間編集ソリューションを提案しました。単一の参照画像が与えられた場合、オブジェクトまたはスタイルを転送します。ソース イメージの全体的な構造を変更することなく、参照イメージをソース イメージに変換します。 研究論文は ICCV 2023 に受理され、関連コードはオープンソースになりました。
- 論文アドレス: https://arxiv.org/abs/2307.14352
- コードアドレス: https://github.com/CrystalNeuro/visual-concept-translator
まず一連の写真を見て、その効果を感じてみましょう。

論文のレンダリング: 各画像セットの左上隅がソース画像、左下隅が参照画像、右隅が参照画像です。側面は生成された結果の画像です
本体フレームワーク
論文の著者は、Inversion-に基づく画像編集フレームワークを提案しました。フュージョン (反転-融合) - VCT (ビジュアル コンセプト トランスレータ、ビジュアル コンセプト コンバータ)。 下図に示すように、VCT の全体的な枠組みには、内容概念反転処理 (Content-concept Inversion) と内容概念融合処理 (Content-concept Fusion) の 2 つの処理が含まれます。内容概念反転プロセスでは、2 つの異なる反転アルゴリズムを使用して、元の画像の構造情報と参照画像の意味情報の潜在ベクトルをそれぞれ学習して表現します。内容概念融合プロセスでは、構造情報の潜在ベクトルを使用します。およびセマンティック情報を融合して最終結果を生成します。
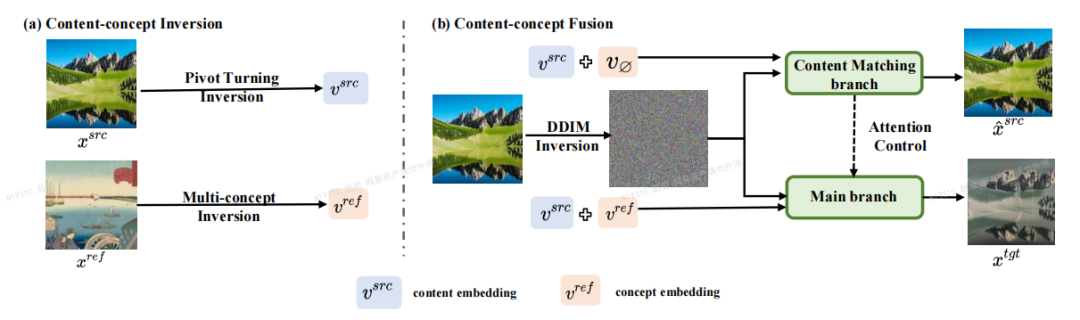
書き直す必要がある内容は次のとおりです: 論文の主要なフレームワーク
です。近年、反転手法は敵対的生成ネットワーク (GAN) の分野で広く使用されており、多くの画像生成タスクで顕著な成果を上げています [1]。 GAN がコンテンツを書き換えるときは、元のテキストを中国語に書き換える必要があります。元の文章を表示する必要はありません。訓練された GAN ジェネレーターの隠れた空間に画像をマッピングでき、編集の目的は、学習済みの GAN ジェネレーターを制御することで達成できます。隠れた空間。この反転スキームは、事前トレーニングされた生成モデルの生成能力を最大限に活用できます。この研究は実際に内容をGANで書き換えたものであり、原文を中国語に書き換える必要があり、原文の出現は不要であり、拡散モデルをアプリオリとした画像誘導に基づく画像編集作業に適用されている
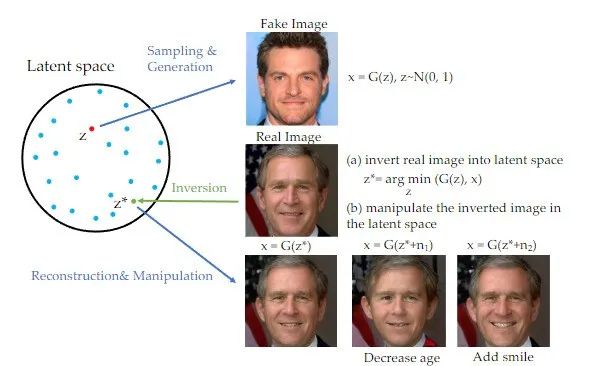
内容を書き換える場合、原文を中国語に書き直す必要があり、元の文章を書き直す必要はありません。
## 手法の紹介
反転のアイデアに基づいて、VCT は 2 分岐拡散プロセスを設計しました。コンテンツ再構築用のブランチ B* と編集用のメイン ブランチ B。これらは、それぞれコンテンツ再構築のために、拡散モデルを使用して画像からノイズを計算するアルゴリズムである DDIM Inversion[2] から得られた同じノイズ xT から始まります。そしてコンテンツ編集。この論文で使用される事前トレーニング モデルは潜在拡散モデル (LDM) です。拡散プロセスは潜在ベクトル空間 z 空間で発生します。二重分岐プロセスは次のように表現できます:
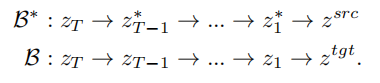
二重分岐拡散プロセス コンテンツ再構成ブランチ B* は、コンテンツの構造を復元するために使用される T 個のコンテンツ特徴ベクトル つまり、拡散のステップ数がモデルが特定の範囲内にある場合、編集メインブランチの注目特徴マップをコンテンツ再構成ブランチの特徴マップに置き換えて、生成された画像の構造制御を実現します。編集メインブランチ B は、原画像から学習した内容特徴ベクトル #ノイズ空間 ( # 拡散していますモデルの各ステップで、ノイズ空間内で特徴ベクトルの融合が発生します。これは、特徴ベクトルが拡散モデルに入力された後に予測されるノイズの重み付けです。コンテンツ再構築ブランチの特徴混合は、コンテンツ特徴ベクトル と概念特徴ベクトル # と単一の参照画像から概念情報 # ############################## 学習構造情報とは異なり、参照画像内の概念情報は、単一の高度に一般化された特徴ベクトルで表す必要があります。拡散モデルの T ステージは、概念特徴ベクトルを共有します。 記事はこのテーマに関するものです置換および様式化タスク ソース画像の構造情報をより適切に維持しながら、コンテンツを参照画像の本体またはスタイルに変換するための実験が行われました。 以前のソリューションと比較して、この記事で提案する VCT フレームワークには次の利点があります。 (1) 以前の画像編集との比較画像ガイダンスに基づいたタスクを実行するため、VCT はトレーニングに大量のデータを必要とせず、生成品質と汎用性が優れています。これは反転の考え方に基づいており、オープンワールド データで事前トレーニングされた高品質のヴィンセント グラフ モデルに基づいており、実際のアプリケーションでは、より優れた画像編集効果を達成するために 1 つの入力画像と 1 つの参照画像のみが必要です。 画像の最近のテキスト編集ソリューションと比較して、VCT は参照ガイドとして画像を使用します。画像参照を使用すると、テキストによる説明よりも正確に画像を編集できます。次の図は、VCT と他のソリューションとの比較結果を示しています。 #被験者置換タスクの効果の比較 #スタイル転送タスクの効果の比較 (3) 追加情報は必要ありません: 比較 ガイダンス制御のために追加の制御情報 (マスク マップや深度マップなど) を追加する必要がある最近のソリューションでは、VCT はフュージョン生成のためにソース画像と参照画像から構造情報と意味情報を直接学習します。いくつかの比較結果。このうち、Paint-by-example は、ソース画像のマスク マップを提供することで、対応するオブジェクトを参照画像内のオブジェクトに置き換えます。Controlnet は、線描画や深度マップなどを通じて生成された結果を制御します。VCT は、ソースから直接描画します。画像と参照画像を学習し、追加の制限なしにターゲット画像に融合される構造情報とコンテンツ情報を学習します。 #画像ガイダンスに基づく画像編集スキームの効果の比較 NetEase Interactive Entertainment AI Laboratory は 2017 年に設立されました。NetEase Interactive Entertainment Business Group に所属し、ゲーム業界をリードする人工知能研究所です。この研究室は、コンピューター ビジョン、音声および自然言語処理、ゲーム シナリオにおける強化学習の研究と応用に重点を置いています。 AI技術を通じてNetEase Interactive Entertainmentの人気ゲームや製品の技術レベルを向上させることを目的としています。現在、この技術は、「ファンタジー西遊記」、「ハリー・ポッター:魔法の目覚め」、「陰陽師」、「西遊記」など、多くの人気ゲームで使用されています。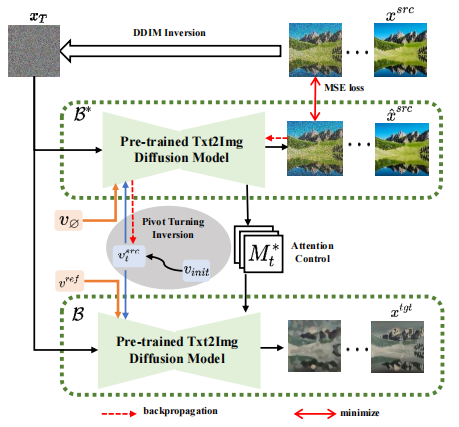 #
#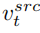 を学習します。元の画像情報を取得し、その構造情報をソフト アテンション コントロール スキームを通じて編集メイン ブランチ B に渡します。ソフト アテンション コントロール スキームは、Google のプロンプト 2 プロンプト [3] の成果を利用しています。式は次のとおりです:
を学習します。元の画像情報を取得し、その構造情報をソフト アテンション コントロール スキームを通じて編集メイン ブランチ B に渡します。ソフト アテンション コントロール スキームは、Google のプロンプト 2 プロンプト [3] の成果を利用しています。式は次のとおりです: 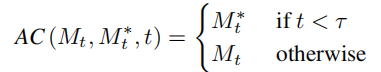
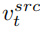 と参照画像から学習した概念特徴ベクトル
と参照画像から学習した概念特徴ベクトル 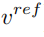 を組み合わせて編集画像を生成します。
を組み合わせて編集画像を生成します。 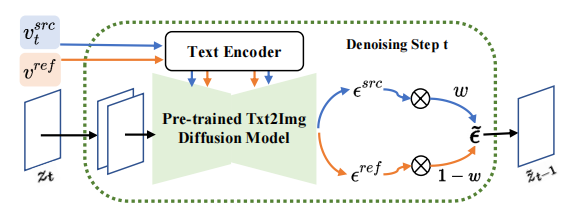
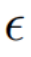 スペース) フュージョン
スペース) フュージョン 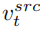 と空のテキスト ベクトルで発生します。これは、分類子なしの拡散ガイダンス [4] の形式と一致しています。
と空のテキスト ベクトルで発生します。これは、分類子なしの拡散ガイダンス [4] の形式と一致しています。 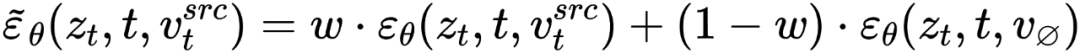
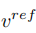 の混合物です。 、つまり
の混合物です。 、つまり 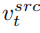
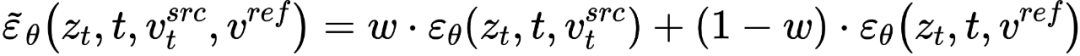
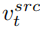 の特徴ベクトルを取得します。この記事では、2 つの異なる反転スキームを通じてこの目的を達成しています。
の特徴ベクトルを取得します。この記事では、2 つの異なる反転スキームを通じてこの目的を達成しています。 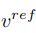
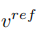 # ##。この記事は、既存の反転スキーム Textual Inversion [6] と DreamArtist [7] を最適化します。参照画像の内容を表すために多概念特徴ベクトルを使用します。損失関数には、拡散モデルのノイズ推定項と潜在ベクトル空間で推定された再構成損失項が含まれます:
# ##。この記事は、既存の反転スキーム Textual Inversion [6] と DreamArtist [7] を最適化します。参照画像の内容を表すために多概念特徴ベクトルを使用します。損失関数には、拡散モデルのノイズ推定項と潜在ベクトル空間で推定された再構成損失項が含まれます: 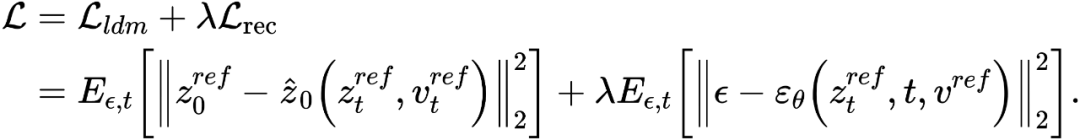
実験結果




以上がさまざまなスタイルの VCT ガイダンスを 1 つの画像で簡単に導入できます。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。