
ホームページ >バックエンド開発 >Python チュートリアル >3000 ワードの長い記事、Pandas が Excel テーブルを美しくします。
3000 ワードの長い記事、Pandas が Excel テーブルを美しくします。

- Python当打之年転載
- 2023-08-10 15:15:111861ブラウズ
- 通貨値を処理するときに通貨記号を使用します。たとえば、データに値 25.00 が含まれている場合、その値が中国人民元、米ドル、英国ポンド、またはその他の通貨であるかどうかはすぐにはわかりません。
- パーセンテージも便利な指標です。0.05 ですか、それとも 5% ですか?データの解釈方法を明確にするには、パーセント記号を使用します。
- Pandas スタイルには、色やその他の視覚要素を出力に追加するためのより高度なツールも含まれています。
この記事では、仮想データを使用して皆さんに説明します。このデータは、架空の組織の 2018 年の売上データです。
データセットのリンクは次のとおりです:
https://www.aliyundrive.com/s/Tu9zBN2x81c
1。関連するライブラリをインポートし、データを読み取ります。
import numpy as np import pandas as pd df = pd.read_excel('2018_Sales_Total.xlsx')
効果は次のとおりです。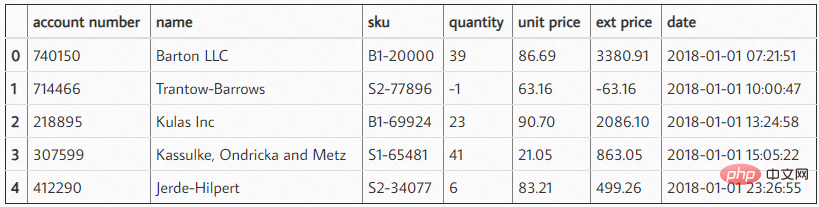 これらのデータを読み取った後、顧客がどのくらいの量のライブラリを使用したかを確認するための簡単な要約を作成できます。当社から購入した平均購入金額はいくらですか。わかりやすくするために、ここでは最初の 5 つのデータをインターセプトしました。
これらのデータを読み取った後、顧客がどのくらいの量のライブラリを使用したかを確認するための簡単な要約を作成できます。当社から購入した平均購入金額はいくらですか。わかりやすくするために、ここでは最初の 5 つのデータをインターセプトしました。
df.groupby('name')['ext price'].agg(['mean', 'sum'])
結果は次のようになります: 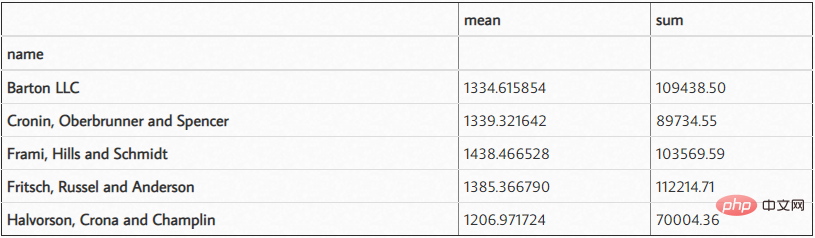
#2. 通貨記号を追加します
このデータを見ると、小数点以下 6 桁とそれより大きな数値が含まれているため、数値のスケールを理解するのが少し難しくなります。さらに、これが米ドルなのか別の通貨なのかも不明です。この問題は、DataFrame style.format を使用して解決できます。
(df.groupby('name')['ext price']
.agg(['mean', 'sum'])
.style.format('${0:,.2f}'))結果は次のとおりです。 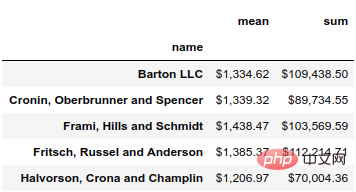 format 関数を使用すると、データに対して Python の文字列書式設定ツールのすべての機能を使用できます。この場合、${0:,.2f} を使用して先頭にドル記号を付け、カンマを追加し、結果を小数点第 2 位に四捨五入します。
format 関数を使用すると、データに対して Python の文字列書式設定ツールのすべての機能を使用できます。この場合、${0:,.2f} を使用して先頭にドル記号を付け、カンマを追加し、結果を小数点第 2 位に四捨五入します。
たとえば、小数点以下 0 桁に四捨五入したい場合は、形式を ${0:,.0f} に変更できます。
(df.groupby('name')['ext price']
.agg(['mean', 'sum'])
.style.format('${0:,.0f}'))結果は次のとおりです:
3. パーセンテージを追加します
if we want 月ごとの総売上高を表示するには、グルーパーを使用して月ごとに集計し、年間総売上高に対する各月の割合を計算します。
monthly_sales = df.groupby([pd.Grouper(key='date', freq='M')])['ext price'].agg(['sum']).reset_index() monthly_sales['pct_of_total'] = monthly_sales['sum'] / df['ext price'].sum()
結果は次のとおりです: 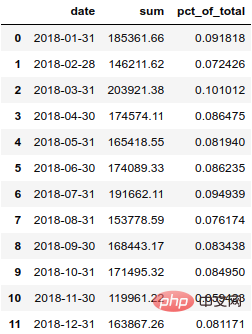 このパーセンテージをより明確に表示するには、パーセンテージに変換した方がよいでしょう。
このパーセンテージをより明確に表示するには、パーセンテージに変換した方がよいでしょう。
format_dict = {'sum':'${0:,.0f}', 'date': '{:%m-%Y}', 'pct_of_total': '{:.2%}'}
monthly_sales.style.format(format_dict).hide_index()结果如下: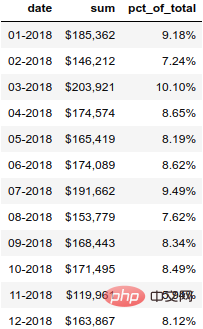
4. 突出显示数字
除了样式化数字,我们还可以设置 DataFrame 中的单元格样式。让我们用绿色突出显示最高的数字,用彩色突出显示最高、最低的数字。
(monthly_sales .style .format(format_dict) .hide_index() .highlight_max(color='lightgreen') .highlight_min(color='#cd4f39'))
结果如下: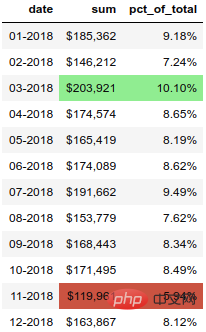
5. 设置渐变色
另一个有用的函数是 background_gradient,它可以突出显示列中的值范围。
(monthly_sales.style .format(format_dict) .background_gradient(subset=['sum'], cmap='BuGn'))
结果如下: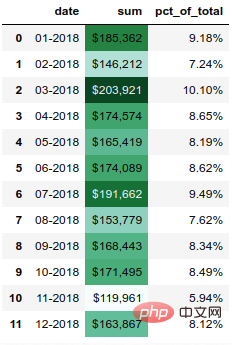
6. 设置数据条
pandas样式功能还支持在列内绘制条形图。
(monthly_sales .style .format(format_dict) .hide_index() .bar(color='#FFA07A', vmin=100_000, subset=['sum'], align='zero') .bar(color='lightgreen', vmin=0, subset=['pct_of_total'], align='zero') .set_caption('2018 Sales Performance'))
结果如下: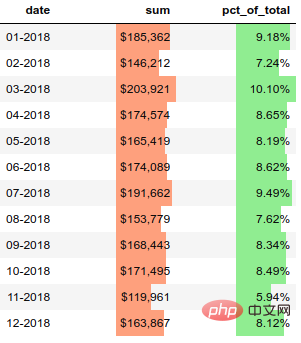
7. 绘制迷你图
我认为这是一个很酷的功能。
import sparklines
def sparkline_str(x):
bins=np.histogram(x)[0]
sl = ''.join(sparklines(bins))
return sl
sparkline_str.__name__ = "sparkline"
df.groupby('name')['quantity', 'ext price'].agg(['mean', sparkline_str])结果如下: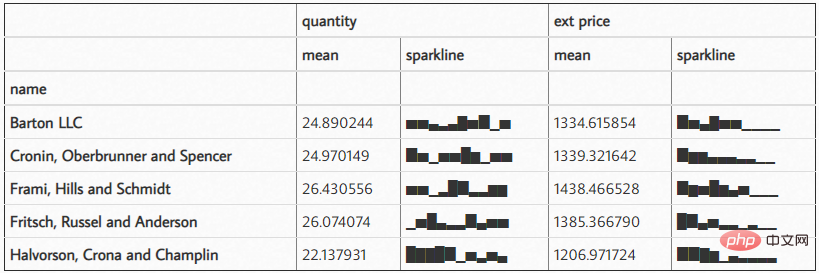
以上が3000 ワードの長い記事、Pandas が Excel テーブルを美しくします。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。