
ホームページ >バックエンド開発 >Python チュートリアル >クローラー|Python はステーション B の女の子の写真をクロールし、学習意欲を高めます!
クローラー|Python はステーション B の女の子の写真をクロールし、学習意欲を高めます!

- Python当打之年転載
- 2023-08-09 17:11:321120ブラウズ
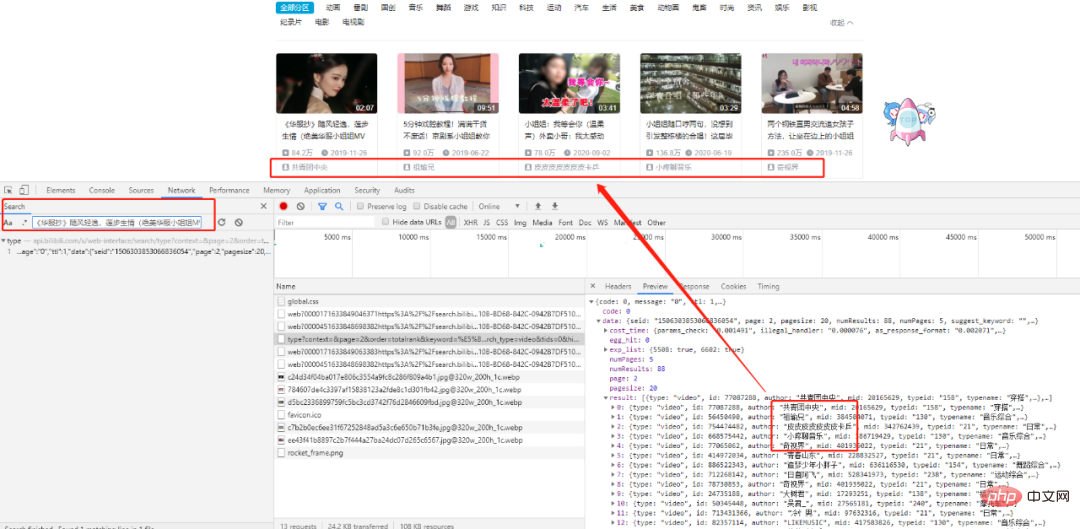
ミスシスター': 最初の 1 つのタイトルを検索すると、対応する XHR リクエストが見つかります。慎重に分析した結果、 すべてのデータは json 形式のデータ セットに存在し、目標は # であることがわかりました。 ##結果リスト。 get リクエスト です。リクエストのエントリ数には page と # が含まれます# #keyword要求されたページ番号とキーワードにそれぞれ対応する 2 つのエントリ。 さらにいくつかのページをチェックしてパターンを見つけてください: 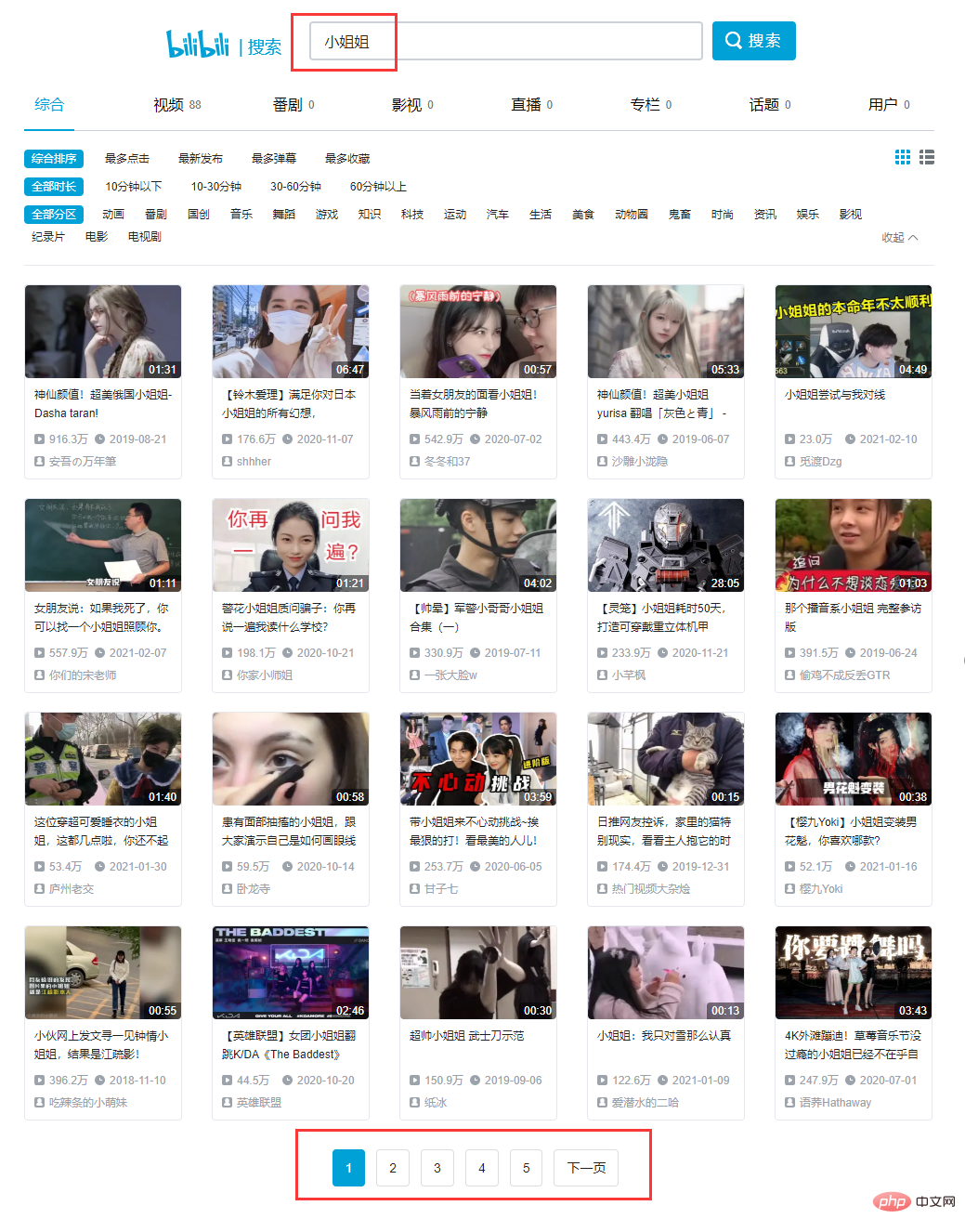
# 第一页
'https://api.bilibili.com/x/web-interface/search/all/v2?context=&page=1&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&tids=0&highlight=1&single_column=0'
# 第二页
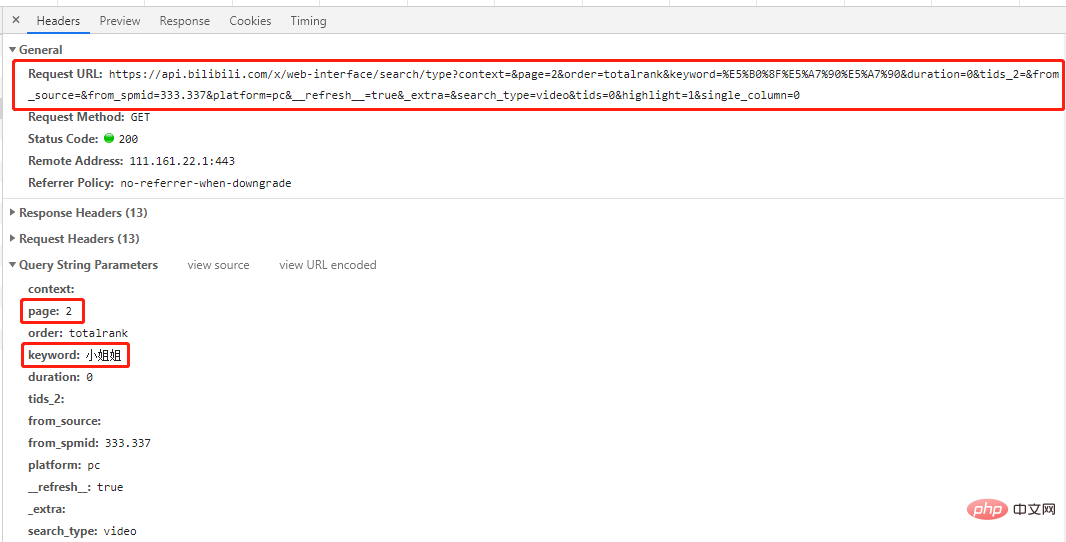
'https://api.bilibili.com/x/web-interface/search/type?context=&page=2&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
# 第三页
'https://api.bilibili.com/x/web-interface/search/type?context=&page=3&order=totalrank&keyword=%E5%B0%8F%E5%A7%90%E5%A7%90&duration=0&tids_2=&from_source=&from_spmid=333.337&platform=pc&__refresh__=true&_extra=&search_type=video&tids=0&highlight=1&single_column=0'
最初のページを除いて、他のページ URL にはページ パラメータが異なるだけであることがわかります。それでは、試してみましょう また、次のようにも使用します。他のページの URL を使用して最初のページをリクエストすると、望ましい結果が得られることがわかります (実際に試してみてください)。 ##############################結論は:################# # すべてのページ URL は page パラメータのみが異なり、残りは同じです。
#
# 导包 import re import time import json import random import requests from fake_useragent import UserAgent
2.2 获取页面信息
# 获取页面信息
def get_datas(url,headers):
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = chardet.detect(r.content)['encoding']
datas = json.loads(r.text)
return datas# 获取图片链接信息
def get_hrefs(datas):
titles,hrefs = [],[]
for data in datas['data']['result']:
# 标题
title = data['title']
# 时长
duration = data['duration']
# 播放量
video_review =data['video_review']
# 发布时间
date_rls = data['pubdate']
pubdate = time.strftime('%Y-%m-%d %H:%M', time.localtime(date_rls))
# 作者
author = data['author']
# 图片链接
link_pic = data['pic']
href_pic = 'https:' + link_pic
titles.append(title)
hrefs.append(href_pic)
return titles, hrefs代码解析了视频标题,时长,播放量,发布时间,作者,图片链接等参数,这里我们只取标题和图片链接,其他参数可根据需要自行增,删。
# 保存图片
def download_jpg(titles, hrefs):
path = "D:/B站小姐姐/"
if not os.path.exists(path):
os.mkdir(path)
for i in range(len(hrefs)):
title_t = titles[i].replace('/','').replace(',','').replace('?','')
title_t = title_t.replace(' ','').replace('|','').replace('。','')
filename = '{}{}.jpg'.format(path,title_t)
with open(filename, 'wb') as f:
req = requests.get(url=hrefs[i], headers=headers)
f.write(req.content)
time.sleep(random.uniform(1.5,3.4))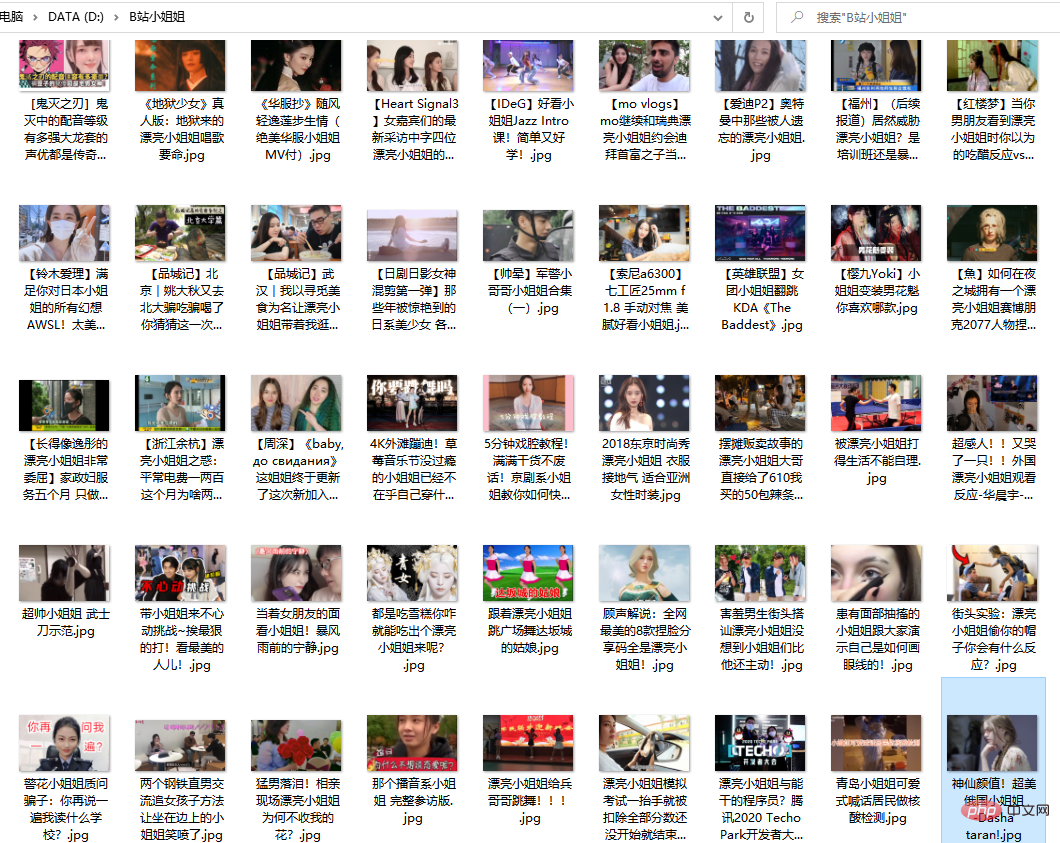
以上がクローラー|Python はステーション B の女の子の写真をクロールし、学習意欲を高めます!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。