
ホームページ >テクノロジー周辺機器 >AI >Microsoft の最新の NaturalSpeech2 音声合成モデル: より正確な音声再構成を提供し、棒読み効果を回避します。
Microsoft の最新の NaturalSpeech2 音声合成モデル: より正確な音声再構成を提供し、棒読み効果を回避します。

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-08-04 09:41:051176ブラウズ

7 月 27 日のニュースによると、Microsoft は最近、NaturalSpeech2 と呼ばれる音声モデルを発表しました。 このモデルは、「潜在的拡散」設計を採用しており、ゼロサンプルの音声合成レベルにあります。 Microsoft は、このモデルが「商用グレード」の音声/歌唱ソリューションを提供し、ユーザーに高品質で多様な音声合成エクスペリエンスを提供できると主張しています。
マイクロソフトは、サンプルを使用せずにさまざまな話者のアイデンティティ、韻律、スタイル (歌など) で音声を生成する NaturalSpeech2 の機能を紹介する一連のデモを実施しました

▲ 画像ソースは NaturalSpeech 2 論文からのものです
従来の音声テキスト変換 (TTS) システムとは異なり、Microsoft の NaturalSpeech2 は「離散マーカー」の代わりに「連続ベクトル」を使用して、音声を表現することで、より完全な音声セグメントを生成します。 は、「感情の欠如」である「棒読み (一言一句話す)」という現象を引き起こしません。
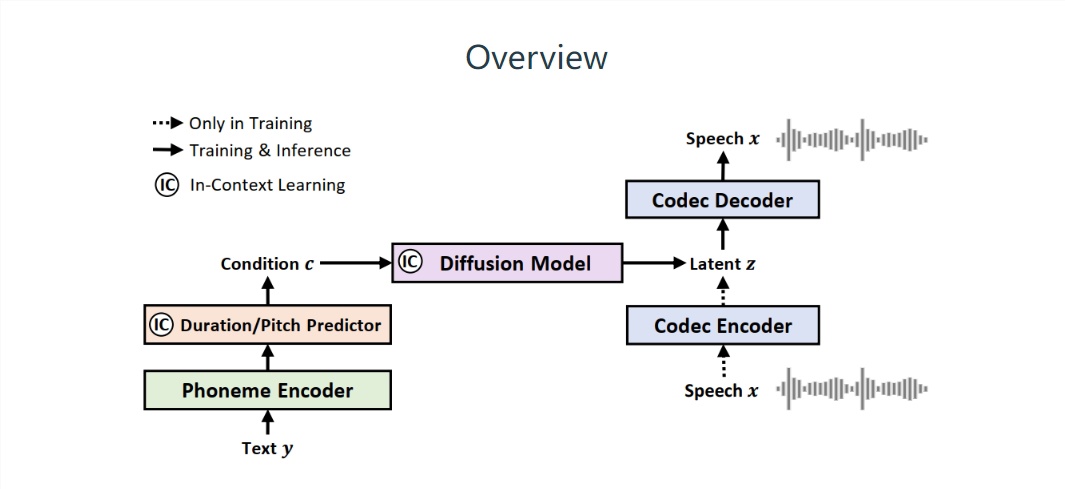
NaturalSpeech2 がゼロサンプル条件下で音声と音声プロンプトを生成し、 real 音声の韻律はほぼ一貫しており、LibriTTS および VCTK テスト セットでの自然さ (CMOS で測定) は人間の音声と区別できません。 このプロジェクトの論文は GitHub で公開されています。興味のある IT House の友人は、
ここをクリックして以上がMicrosoft の最新の NaturalSpeech2 音声合成モデル: より正確な音声再構成を提供し、棒読み効果を回避します。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。