
次世代監視システムとも言われるその実力を試してみましょう!
- Linux中文社区転載
- 2023-08-03 15:40:151728ブラウズ

Prometheus は、時系列データベースに基づいたオープンソースの監視および警報システムです。 Prometheus について言及する必要があります。SoundCloud は、ビデオ共有の YouTube に似たオンライン音楽共有プラットフォームです。マイクロサービス アーキテクチャの道をさらに進むにつれ、従来の監視システム StatsD と Graphite を使用して、何百ものサービスが登場しました。多くの制限があります。
そこで彼らは 2012 年に新しい監視システムの開発を開始しました。 Prometheus のオリジナルの作者は Matt T. Proud で、彼も 2012 年に SoundCloud に入社しました。実際、Matt は SoundCloud に入社する前に Google で働いていました。彼は Google のクラスタ マネージャー Borg とその監視システム Borgmon からインスピレーションを得て、オープンなプロメテウスを開発しました。ソース監視システム Prometheus. 多くの Google プロジェクトと同様に、使用されるプログラミング言語は Go です。
Prometheus は、マイクロサービス アーキテクチャ監視システムのソリューションとして、コンテナーと切り離せないものであることは明らかです。 2006 年 8 月 9 日には、Eric Schmidt が Search Engine Conference で初めてクラウド コンピューティング (クラウド コンピューティング) の概念を提案し、その後 10 年間でクラウド コンピューティングの発展が急速に進みました。
2013 年、Pivotal の Matt Stine は、クラウド ネイティブの概念を提案しました。クラウド ネイティブは、マイクロサービス アーキテクチャ、DevOps、コンテナに代表されるアジャイル インフラストラクチャで構成され、企業が迅速かつ持続的にソフトウェアを確実かつ大規模に配信できるように支援します。
クラウド コンピューティング インターフェイスと関連標準を統一するために、2015 年 7 月に Linux Foundation と提携する Cloud Native Computing Foundation (CNCF) が設立されました。 CNCF に参加した最初のプロジェクトは Google の Kubernetes で、Prometheus は 2 番目に参加したプロジェクト (2016 年) でした。
1. Prometheus の概要
SoundCloud の公式ブログで、新しいモニタリング システム Prometheus を開発する必要がある理由に関する記事を見つけることができます。 SoundCloud でのモニタリングでは、この記事で、必要なモニタリング システムは次の 4 つの特性を満たす必要があると紹介しました。
多次元データ モデル。インスタンス、サービス、エンドポイント、メソッドなどの側面に沿って、自由にスライスしたり、さいの目に切り分けたりできます。 運用のシンプルさにより、監視サーバーを起動できます。分散ストレージ バックエンドをセットアップしたり世界を再構成したりすることなく、いつでもどこでも、ローカル ワークステーション上でも実行できます。 スケーラブルなデータ収集と分散型アーキテクチャにより、サービスの多数のインスタンスを確実に監視でき、独立したチームが独立した監視サーバーをセットアップできます。 最後に、データを活用する強力なクエリ言語です。意味のあるアラート (簡単なサイレンシングを含む) とグラフ作成 (ダッシュボードおよびアドホック探索用) のモデル。
つまり、次の 4 つの機能です。
- #多次元データ モデル
- 便利な展開とメンテナンス
- 柔軟なデータ収集
- 強力なクエリ言語
これらの 4 つの主要な機能に加えて、Prometheus の継続的な開発により、サービス検出、より豊富なチャート表示、外部ストレージの使用、強力なアラーム ルール、さまざまな通知方法など、より高度な機能がサポートされ始めています。 . .
次の図は、Prometheus の全体的なアーキテクチャ図です。
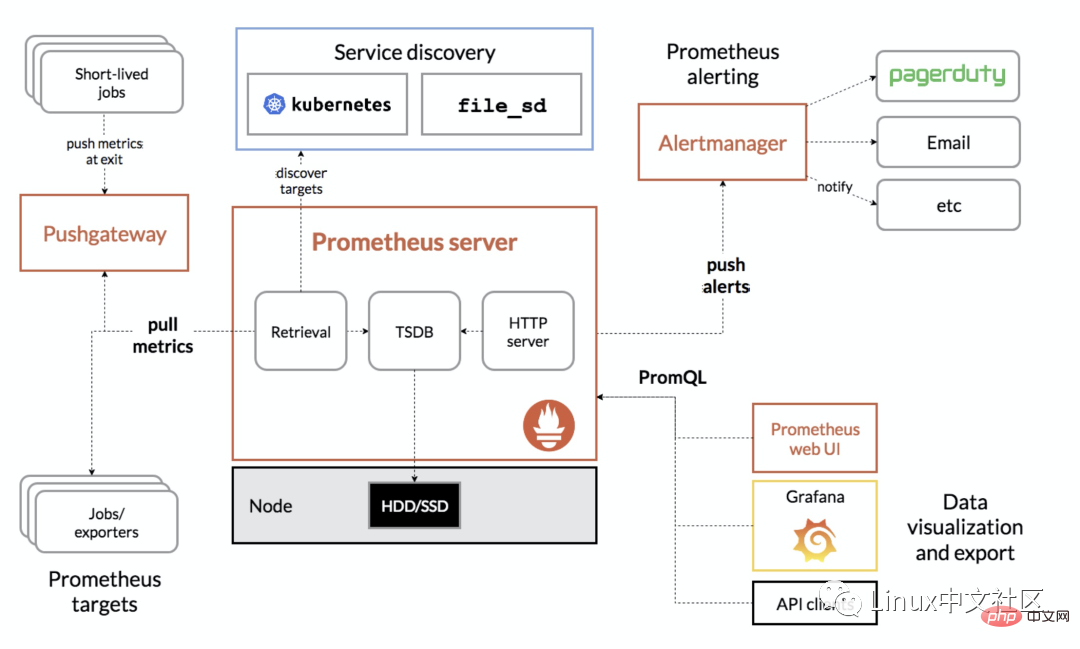
2. Prometheus サーバーのインストール
Prometheus は、Docker、Ansible、Chef、Puppet、Saltstack などの複数のインストール方法をサポートします。 。ここでは、コンパイル済みの実行ファイルをそのまま使用する方法と、Docker イメージを使用する方法の 2 つの最も簡単な方法を紹介します。
2.1 すぐに使える
まず、公式 Web サイトのダウンロード ページから Prometheus の最新バージョンとダウンロード アドレスを取得します (最新バージョンは 2.4.3 (2018 年 10 月))。以下のコマンドを実行して、ダウンロードして解凍します。 :
$ wget https://github.com/prometheus/prometheus/releases/download/v2.4.3/prometheus-2.4.3.linux-amd64.tar.gz $ tar xvfz prometheus-2.4.3.linux-amd64.tar.gz
次に、解凍ディレクトリに切り替えて、Prometheus のバージョンを確認します:
$ cd prometheus-2.4.3.linux-amd64 $ ./prometheus --version prometheus, version 2.4.3 (branch: HEAD, revision: 167a4b4e73a8eca8df648d2d2043e21bdb9a7449) build user: root@1e42b46043e9 build date: 20181004-08:42:02 go version: go1.11.1
Prometheus サーバーを実行します:
$ ./prometheus --config.file=prometheus.yml
2.2 Docker イメージを使用します
Docker を使用して Prometheus をインストールします。次のコマンドを実行するだけなので簡単です:
$ sudo docker run -d -p 9090:9090 prom/prometheus
通常、構成ファイルの場所も指定します:
$ sudo docker run -d -p 9090:9090 \ -v ~/docker/prometheus/:/etc/prometheus/ \ prom/prometheus
構成ファイルをローカルに置きます~/docker /prometheus/prometheus.yml は、簡単に編集および表示できます。-v パラメーターを使用して、ローカル構成ファイルを /etc/prometheus にマウントします。 / 場所。これは、コンテナ内の prometheus によってロードされるデフォルトの構成ファイルの場所です。
如果我们不确定默认的配置文件在哪,可以先执行上面的不带 -v 参数的命令,然后通过 docker inspect 命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):
$ sudo docker inspect 0c [...] "Id": "0c4c2d0eed938395bcecf1e8bb4b6b87091fc4e6385ce5b404b6bb7419010f46", "Created": "2018-10-15T22:27:34.56050369Z", "Path": "/bin/prometheus", "Args": [ "--config.file=/etc/prometheus/prometheus.yml", "--storage.tsdb.path=/prometheus", "--web.console.libraries=/usr/share/prometheus/console_libraries", "--web.console.templates=/usr/share/prometheus/consoles" ], [...]
2.3 配置 Prometheus
正如上面两节看到的,Prometheus 有一个配置文件,通过参数 <span style="outline: 0px;color: rgb(0, 0, 0);">--config.file</span> 来指定,配置文件格式为 YAML。我们可以打开默认的配置文件 <span style="outline: 0px;color: rgb(0, 0, 0);">prometheus.yml</span> 看下里面的内容:
/etc/prometheus $ cat prometheus.yml # my global config global: scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s). # Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml" # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ['localhost:9090']
Prometheus 默认的配置文件分为四大块:
グローバル ブロック: Prometheus のグローバル構成。たとえば、 scrape_intervalは Prometheus がデータをクロールする頻度を示し、evaluation_intervalはアラーム ルールが検出される頻度を示します。- #alerting ブロック: Alertmanager の構成については、後で説明します;
- rule_files ブロック: アラート ルール、これについては後で説明します;
- scrape_config ブロック: Prometheus によってスクレイピングされるターゲットを定義します。
prometheus
という名前のジョブがデフォルトで設定されていることがわかります。場合によっては、HTTP インターフェースを介して独自のインジケーター データも公開します。これは、Prometheus 自体の監視に相当します。これは、実際に Prometheus を使用する場合にはほとんど役に立ちませんが、この例を通じて Prometheus の使用方法を学ぶことができます。# にアクセスしてください。 ##http ://localhost:9090/metricsPrometheus が公開するメトリクスを確認してください;
3. PromQL## について学ぶ#上記の手順で Prometheus をインストールした後、Prometheus を体験し始めることができます。 Prometheus は、操作を容易にするビジュアルな Web UI を提供します。http://localhost:9090/
に直接アクセスするだけです。デフォルトでグラフ ページにジャンプします:初めてこのページにアクセスすると、圧倒されるかもしれません。最初に他のメニューの内容を確認できます。例: アラートには、定義されたすべてのアラーム ルールが表示されます。ステータスには、ランタイムとビルドを含むさまざまな Prometheus ステータス情報が表示されます情報、コマンドラインフラグ、構成、ルール、ターゲット、サービスディスカバリなど
実際、グラフ ページは Prometheus の最も強力な機能です。ここでは、Prometheus が提供する特別な式を使用して、監視データをクエリできます。この式は PromQL (Prometheus Query Language) と呼ばれます。 PromQL を介してグラフ ページ上のデータをクエリできるだけでなく、Prometheus が提供する HTTP API を介してデータをクエリすることもできます。クエリされた監視データは、リストとグラフの 2 つの形式で表示できます (上図の Console と Graph の 2 つのラベルに対応します)。
上で述べたように、Prometheus 自体も多くのモニタリング インジケーターを公開しており、グラフ ページでクエリすることもできます。[実行] ボタンの横にあるドロップダウン ボックスを展開すると、多くのインジケーター名が表示されます。任意に選択できます (例: promhttp_metric_handler_requests_total)。このインジケーターは、/metrics ページへの訪問数を表します。Prometheus は、このページを使用して独自の監視データを取得します。 Console タグのクエリ結果は次のとおりです。

上記の Prometheus 設定ファイルを導入すると、scrape_interval が表示されます。 パラメーターは 15 秒です。これは、Prometheus が /metrics ページに 15 秒ごとにアクセスすることを意味します。そのため、15 秒後にページを更新すると、インジケーターの値が自動的に増加することがわかります。これは、Graph タグでより明確に確認できます:
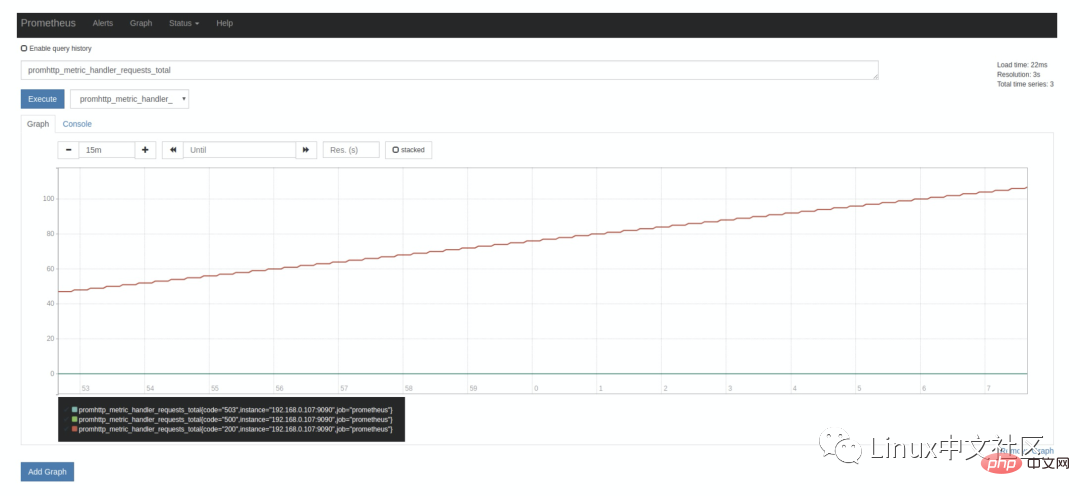
要学习 PromQL,首先我们需要了解下 Prometheus 的数据模型,一条 Prometheus 数据由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,比如下面这个例子:
promhttp_metric_handler_requests_total{code="200",instance="192.168.0.107:9090",job="prometheus"} 106这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。
このデータ モデルは OpenTSDB のデータ モデルに似ています。詳細については、公式 Web サイトのドキュメント「データ モデル」を参照してください。さらに、インジケーターとラベルの命名に関しては、公式 Web サイトにいくつかのヒントが記載されています。「メトリックとラベルの命名」を参照してください。
Prometheus に格納されるデータは float64 値ですが、型ごとに分けると、Prometheus データを次の 4 つの主要なカテゴリに分けることができます。
-
Counter ゲージ ヒストグラム 概要
カウンターはリクエスト数、タスク完了数、エラー数などのカウントに使用されます。この値は常に増加し、減少しません。ゲージは一般的な値であり、温度の変化やメモリ使用量の変化など、大きくても小さくてもかまいません。ヒストグラムはヒストグラムまたは棒グラフであり、リクエスト時間や応答サイズなどのイベントの規模を追跡するためによく使用されます。
これの特別な点は、記録されたコンテンツをグループ化し、カウントおよび合計関数を提供できることです。サマリーはヒストグラムに非常に似ており、イベント発生の規模を追跡するためにも使用されますが、異なる点は、追跡結果をパーセンテージで除算できる分位数関数を提供することです。たとえば、分位値 0.95 は、サンプル値のデータの 95% を取得することを意味します。詳細については、公式 Web サイトのドキュメント「メトリック タイプ」を参照してください。サマリーとヒストグラムの概念は比較的混同しやすく、比較的上位の指標タイプです。ヒストグラムとサマリーについては、ここでの説明を参照してください。
这四种类型的数据只在指标的提供方作区分,也就是上面说的 Exporter,如果你需要编写自己的 Exporter 或者在现有系统中暴露供 Prometheus 抓取的指标,你可以使用 Prometheus client libraries,这个时候你就需要考虑不同指标的数据类型了。如果你不用自己实现,而是直接使用一些现成的 Exporter,然后在 Prometheus 里查查相关的指标数据,那么可以不用太关注这块,不过理解 Prometheus 的数据类型,对写出正确合理的 PromQL 也是有帮助的。
3.2 PromQL 入门
我们从一些例子开始学习 PromQL,最简单的 PromQL 就是直接输入指标名称,比如:
# 表示 Prometheus 能否抓取 target 的指标,用于 target 的健康检查 up
这条语句会查出 Prometheus 抓取的所有 target 当前运行情况,譬如下面这样:
up{instance="192.168.0.107:9090",job="prometheus"} 1 up{instance="192.168.0.108:9090",job="prometheus"} 1 up{instance="192.168.0.107:9100",job="server"} 1 up{instance="192.168.0.108:9104",job="mysql"} 0也可以指定某个 label 来查询:
up{job="prometheus"}这种写法被称为 Instant vector selectors,这里不仅可以使用 = 号,还可以使用 !=、=~、!~,比如下面这样:
up{job!="prometheus"} up{job=~"server|mysql"} up{job=~"192\.168\.0\.107.+"}=~ 是根据正则表达式来匹配,必须符合 RE2 的语法。
和 Instant vector selectors 相应的,还有一种选择器,叫做 Range vector selectors,它可以查出一段时间内的所有数据:
http_requests_total[5m]
这条语句查出 5 分钟内所有抓取的 HTTP 请求数,注意它返回的数据类型是 Range vector,没办法在 Graph 上显示成曲线图,一般情况下,会用在 Counter 类型的指标上,并和 rate() 或 irate() 函数一起使用(注意 rate 和 irate 的区别)。
搜索公众号Java后端栈回复“面试”,送你一份惊喜礼包。
# 计算的是每秒的平均值,适用于变化很慢的 counter # per-second average rate of increase, for slow-moving counters rate(http_requests_total[5m]) # 计算的是每秒瞬时增加速率,适用于变化很快的 counter # per-second instant rate of increase, for volatile and fast-moving counters irate(http_requests_total[5m])
此外,PromQL 还支持 count、sum、min、max、topk 等 聚合操作,还支持 rate、abs、ceil、floor 等一堆的 内置函数,更多的例子,还是上官网学习吧。如果感兴趣,我们还可以把 PromQL 和 SQL 做一个对比,会发现 PromQL 语法更简洁,查询性能也更高。
3.3 HTTP API
我们不仅仅可以在 Prometheus 的 Graph 页面查询 PromQL,Prometheus 还提供了一种 HTTP API 的方式,可以更灵活的将 PromQL 整合到其他系统中使用,譬如下面要介绍的 Grafana,就是通过 Prometheus 的 HTTP API 来查询指标数据的。实际上,我们在 Prometheus 的 Graph 页面查询也是使用了 HTTP API。
我们看下 Prometheus 的 HTTP API 官方文档,它提供了下面这些接口:
GET /api/v1/query - ##GET /api/v1/query_range
- GET /api / v1/シリーズ
- GET /api/v1/label/f63ca0dce42272c7c1497a632ea47c1d/values
- #GET /api/v1/targets
- GET /api/v1/rules
- GET /api/v1/alerts
- GET /api /v1/targets/metadata ##GET /api/v1/alertmanagers
- ##GET /api/v1/status/config
- GET /api/v1/status/flags
- Prometheus v2.1 から、TSDB を管理するための新しいインターフェイスがいくつか追加されました :
- ##POST /api/v1/admin/tsdb/snapshot ##POST /api/v1/admin/tsdb/delete_series
-
Prometheus が提供する Web UI は、さまざまなインジケーターを適切に表示することもできます。この機能は非常にシンプルであり、デバッグにのみ適しています。強力なモニタリング システムを実装するには、さまざまなインジケーターを表示し、さまざまな種類の表示方法 (曲線グラフ、円グラフ、ヒート マップ、TopN など) をサポートするようにカスタマイズできるパネルも必要です。これがダッシュボード機能です。
そこで、プロメテウスはダッシュボード システム PromDash を開発しましたが、このシステムはすぐに廃止され、当局はプロメテウスのインジケーター データを視覚化するために Grafana の使用を推奨し始めました。これは、Grafana の機能が非常に強力であるためだけではなく、 Prometheus と完全かつシームレスに統合できます。 Grafana は、大規模な測定データを視覚化するためのオープン ソース システムです。非常に強力な機能と非常に美しいインターフェイスを備えています。これを使用して、カスタマイズされたコントロール パネルを作成し、データを次のように構成できます。パネルに表示されるデータや表示方法に加えて、Graphite、InfluxDB、OpenTSDB、Elasticsearch、Prometheus などのさまざまなデータ ソースをサポートし、多くのプラグインもサポートします。 次に、Grafana を使用して Prometheus インジケーター データを表示することを体験します。まず、Grafana をインストールします。最も単純な Docker インストール方法を使用します:$ docker run -d -p 3000:3000 grafana/grafana
运行上面的 docker 命令,Grafana 就安装好了!你也可以采用其他的安装方式,参考 官方的安装文档。安装完成之后,我们访问 http://localhost:3000/ 进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。
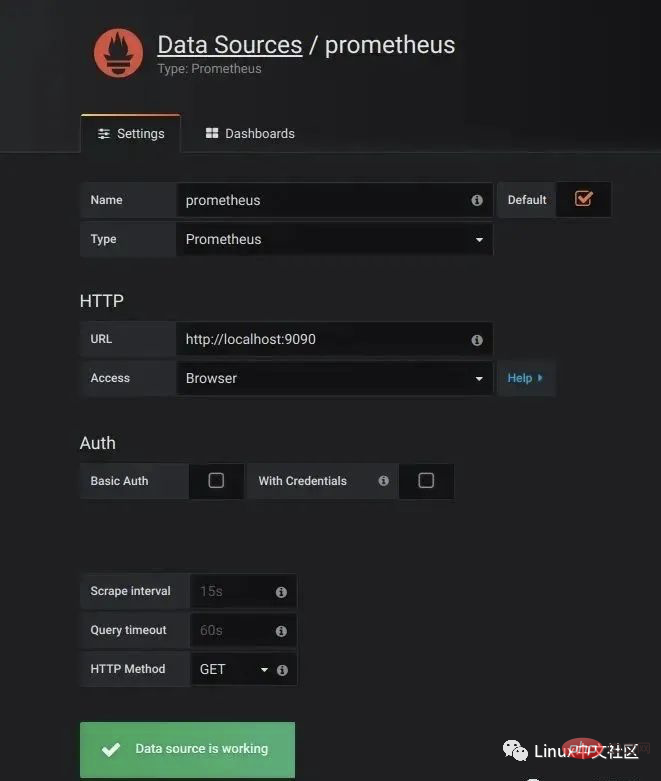
要使用 Grafana,第一步当然是要配置数据源,告诉 Grafana 从哪里取数据,我们点击 Add data source 进入数据源的配置页面:
 图片
图片
我们在这里依次填上:
Name: prometheus Type: Prometheus URL: http://localhost:9090 Access: Browser
要注意的是,这里的 Access 指的是 Grafana 访问数据源的方式,有 Browser 和 Proxy 两种方式。Browser 方式表示当用户访问 Grafana 面板时,浏览器直接通过 URL 访问数据源的;而 Proxy 方式表示浏览器先访问 Grafana 的某个代理接口(接口地址是 /api/datasources/proxy/),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。
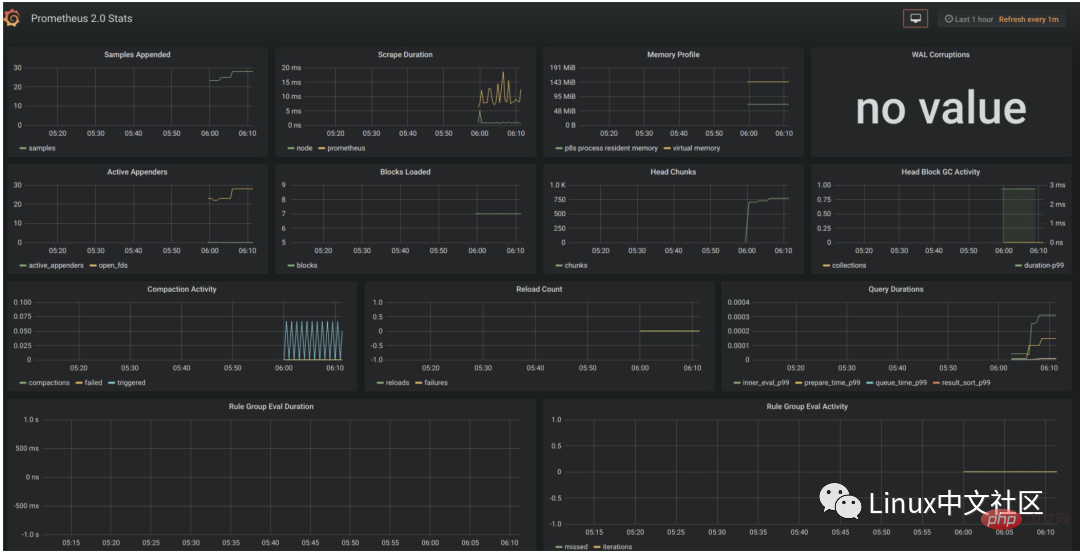
データ ソースを構成した後、Grafana はデフォルトで使用できるいくつかの構成済みパネルを提供します。以下の図に示すように、Prometheus Stats、Prometheus 2.0 Stats、Grafana metrics の 3 つのパネルがデフォルトで提供されます。このパネルをインポートして使用するには、「インポート」をクリックします。
5. エクスポーターを使用してインジケーターを収集する
これまでのところ、いくつかのインジケーターのみを確認しました。実稼働環境で実際に Prometheus を使用したい場合は、サーバーの CPU 負荷、メモリ使用量、IO オーバーヘッド、送受信ネットワーク トラフィックなどのさまざまな指標に注意を払う必要があることがよくあります。
上記のように、Prometheus はプル メソッドを使用してインジケーター データを取得します。Prometheus がターゲットからデータを取得するには、まずインジケーター収集プログラムをターゲットにインストールし、Prometheus Query の HTTP インターフェイスを公開する必要があります。 , この指標収集プログラムはエクスポーターと呼ばれます。指標が異なれば、収集するには異なるエクスポーターが必要です。現在、利用可能なエクスポーターが多数あり、私たちが一般的に使用するほぼすべての種類のシステムやソフトウェアをカバーしています。
公式 Web サイトには、一般的に使用されるエクスポーターのリストが記載されています。各エクスポーターは、ポートの競合を避けるためのポート規則に従います。つまり、9100 から始まり、順番に増加します。完全なエクスポーター ポートのリストは次のとおりです。 Kubernetes、Grafana、Etcd、Ceph など、一部のソフトウェアやシステム自体が Prometheus 形式でインジケーター データを公開する機能を提供しているため、Exporter をインストールする必要がないことにも注意してください。
这一节就让我们来收集一些有用的数据。
5.1 收集服务器指标
首先我们来收集服务器的指标,这需要安装 node_exporter,这个 exporter 用于收集 *NIX 内核的系统,如果你的服务器是 Windows,可以使用 WMI exporter。
和 Prometheus server 一样,node_exporter 也是开箱即用的:
$ wget https://github.com/prometheus/node_exporter/releases/download/v0.16.0/node_exporter-0.16.0.linux-amd64.tar.gz $ tar xvfz node_exporter-0.16.0.linux-amd64.tar.gz $ cd node_exporter-0.16.0.linux-amd64 $ ./node_exporter
node_exporter 启动之后,我们访问下 /metrics 接口看看是否能正常获取服务器指标:
$ curl http://localhost:9100/metrics
如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到 scrape_configs 中:
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['192.168.0.107:9090'] - job_name: 'server' static_configs: - targets: ['192.168.0.107:9100']
修改配置后,需要重启 Prometheus 服务,或者发送 HUP 信号也可以让 Prometheus 重新加载配置:
$ killall -HUP prometheus
在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器:
在 Graph 页面的指标下拉框可以看到很多名称以 node 开头的指标,譬如我们输入 node_load1 观察服务器负载:
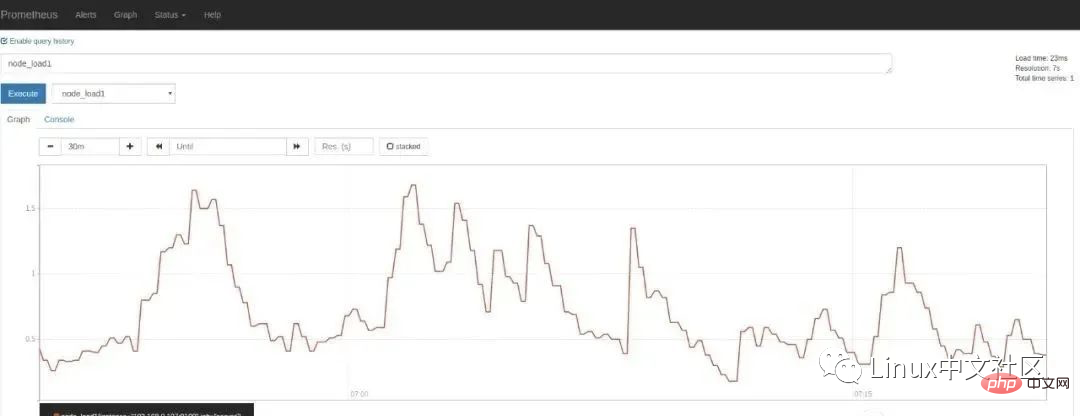
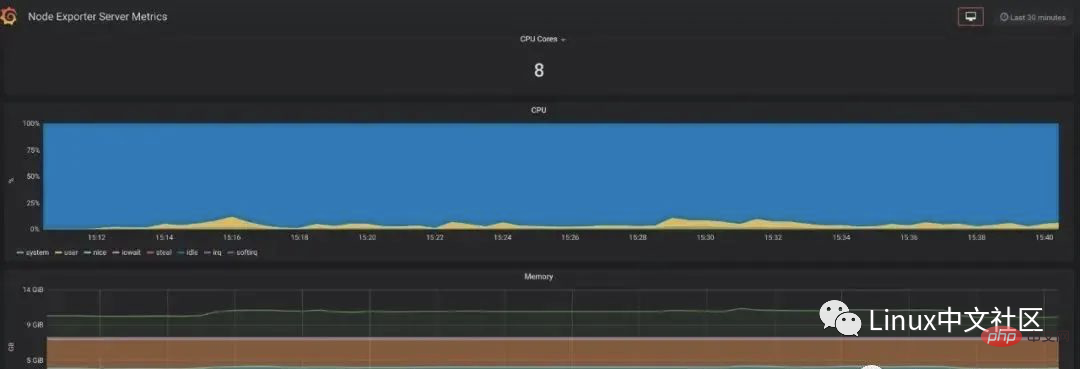
如果想在 Grafana 中查看服务器的指标,可以在 Grafana 的 Dashboards 页面 搜索 node exporter,有很多的面板模板可以直接使用,譬如:Node Exporter Server Metrics 或者 Node Exporter Full 等。我们打开 Grafana 的 Import dashboard 页面,输入面板的 URL(https://grafana.com/dashboards/405)或者 ID(405)即可。
注意事项
一般情况下,node_exporter 都是直接运行在要收集指标的服务器上的,官方不推荐用 Docker 来运行 node_exporter。如果逼不得已一定要运行在 Docker 里,要特别注意,这是因为 Docker 的文件系统和网络都有自己的 namespace,收集的数据并不是宿主机真实的指标。可以使用一些变通的方法,比如运行 Docker 时加上下面这样的参数:
docker run -d \ --net="host" \ --pid="host" \ -v "/:/host:ro,rslave" \ quay.io/prometheus/node-exporter \ --path.rootfs /host
关于 node_exporter 的更多信息,可以参考 node_exporter 的文档 和 Prometheus 的官方指南 Monitoring Linux host metrics with the Node Exporter,另外,Julius Volz 的这篇文章 How To Install Prometheus using Docker on Ubuntu 14.04 也是很好的入门材料。
5.2 收集 MySQL 指标
mysqld_exporter 是 Prometheus 官方提供的一个 exporter,我们首先 下载最新版本 并解压(开箱即用):
$ wget https://github.com/prometheus/mysqld_exporter/releases/download/v0.11.0/mysqld_exporter-0.11.0.linux-amd64.tar.gz $ tar xvfz mysqld_exporter-0.11.0.linux-amd64.tar.gz $ cd mysqld_exporter-0.11.0.linux-amd64/
mysqld_exporter 需要连接到 mysqld 才能收集它的指标,可以通过两种方式来设置 mysqld 数据源。第一种是通过环境变量 DATA_SOURCE_NAME,这被称为 DSN(数据源名称),它必须符合 DSN 的格式,一个典型的 DSN 格式像这样:user:password@(host:port)/。
$ export DATA_SOURCE_NAME='root:123456@(192.168.0.107:3306)/' $ ./mysqld_exporter
另一种方式是通过配置文件,默认的配置文件是 ~/.my.cnf,或者通过 --config.my-cnf 参数指定:
$ ./mysqld_exporter --config.my-cnf=".my.cnf"
配置文件的格式如下:
$ cat .my.cnf [client] host=localhost port=3306 user=root password=123456
如果要把 MySQL 的指标导入 Grafana,可以参考 这些 Dashboard JSON。另外,MySQL 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
注意事项
这里为简单起见,在 mysqld_exporter 中直接使用了 root 连接数据库,在真实环境中,可以为 mysqld_exporter 创建一个单独的用户,并赋予它受限的权限(PROCESS、REPLICATION CLIENT、SELECT),最好还限制它的最大连接数(MAX_USER_CONNECTIONS)。
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'password' WITH MAX_USER_CONNECTIONS 3; GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
5.3 收集 Nginx 指标
官方提供了两种收集 Nginx 指标的方式。另外,Nginx 系列面试题和答案全部整理好了,微信搜索互联网架构师,在后台发送:2T,可以在线阅读。
第一种是 Nginx metric library,这是一段 Lua 脚本(prometheus.lua),Nginx 需要开启 Lua 支持(libnginx-mod-http-lua 模块)。为方便起见,也可以使用 OpenResty 的 OPM(OpenResty Package Manager) 或者 luarocks(The Lua package manager) 来安装。
第二种是 Nginx VTS exporter,这种方式比第一种要强大的多,安装要更简单,支持的指标也更丰富,它依赖于 nginx-module-vts 模块,vts 模块可以提供大量的 Nginx 指标数据,可以通过 JSON、HTML 等形式查看这些指标。Nginx VTS exporter 就是通过抓取 /status/format/json 接口来将 vts 的数据格式转换为 Prometheus 的格式。
ただし、新しいインターフェイスが nginx-module-vts の最新バージョンに追加されました: /status/format/prometheus. このインターフェイスは、Prometheus の形式を直接返すことができます。 Prometheus の影響により、Nginx VTS エクスポータは近々廃止されると予想されます (TODO: 要確認)。
さらに、Nginx インジケーターを収集するには、他にも次のような多くの方法があります。 nginx_exporter Nginx に付属の統計ページ /nginx_status を取得することで、いくつかの情報を取得できます。比較的単純なインジケーター (ngx_http_stub_status_module モジュールを有効にする必要があります); nginx_request_exporter syslog プロトコルを通じて Nginx アクセス ログを収集および分析し、HTTP リクエストに関連するいくつかのインジケーターをカウントします。 prometheus-shiny-exporter は nginx_request_exporter に似ており、アクセス ログの収集に syslog プロトコルを使用しますが、Crystal 言語で記述されています。また、vovolie/lua-nginx-prometheus は、Openresty、Prometheus、Consul、Grafana に基づいて、ドメイン名とエンドポイント レベルでトラフィック統計を実装します。
5.4 收集 JMX 指标
最后让我们来看下如何收集 Java 应用的指标,Java 应用的指标一般是通过 JMX(Java Management Extensions) 来获取的,顾名思义,JMX 是管理 Java 的一种扩展,它可以方便的管理和监控正在运行的 Java 程序。
JMX Exporter 用于收集 JMX 指标,很多使用 Java 的系统,都可以使用它来收集指标,比如:Kafaka、Cassandra 等。首先我们下载 JMX Exporter:
$ wget https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/0.3.1/jmx_prometheus_javaagent-0.3.1.jar
JMX Exporter 是一个 Java Agent 程序,在运行 Java 程序时通过 -javaagent 参数来加载:
$ java -javaagent:jmx_prometheus_javaagent-0.3.1.jar=9404:config.yml -jar spring-boot-sample-1.0-SNAPSHOT.jar
其中,9404 是 JMX Exporter 暴露指标的端口,config.yml 是 JMX Exporter 的配置文件,它的内容可以 参考 JMX Exporter 的配置说明 。
然后检查下指标数据是否正确获取:
$ curl http://localhost:9404/metrics
六、告警和通知
至此,我们能收集大量的指标数据,也能通过强大而美观的面板展示出来。不过作为一个监控系统,最重要的功能,还是应该能及时发现系统问题,并及时通知给系统负责人,这就是 Alerting(告警)。
Prometheus 的告警功能被分成两部分:一个是告警规则的配置和检测,并将告警发送给 Alertmanager,另一个是 Alertmanager,它负责管理这些告警,去除重复数据,分组,并路由到对应的接收方式,发出报警。常见的接收方式有:Email、PagerDuty、HipChat、Slack、OpsGenie、WebHook 等。
6.1 配置告警规则
我们在上面介绍 Prometheus 的配置文件时了解到,它的默认配置文件 prometheus.yml 有四大块:global、alerting、rule_files、scrape_config,其中 rule_files 块就是告警规则的配置项,alerting 块用于配置 Alertmanager,这个我们下一节再看。现在,先让我们在 rule_files 块中添加一个告警规则文件:
rule_files: - "alert.rules"
然后参考 官方文档,创建一个告警规则文件 alert.rules:
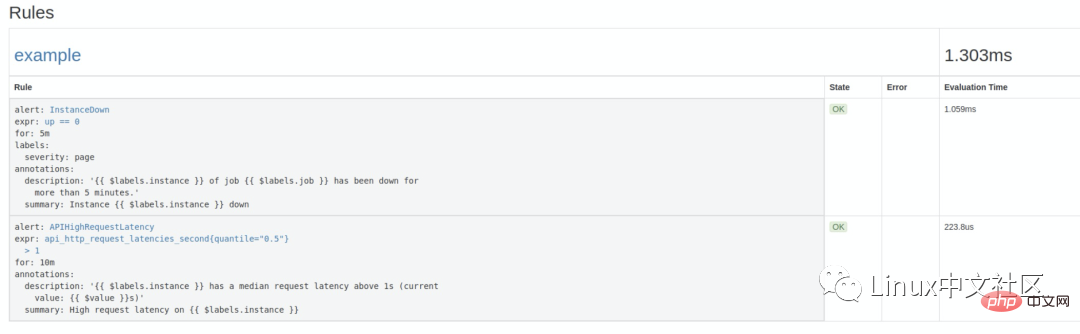
groups: - name: example rules: # Alert for any instance that is unreachable for >5 minutes. - alert: InstanceDown expr: up == 0 for: 5m labels: severity: page annotations: summary: "Instance {{ $labels.instance }} down" description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes." # Alert for any instance that has a median request latency >1s. - alert: APIHighRequestLatency expr: api_http_request_latencies_second{quantile="0.5"} > 1 for: 10m annotations: summary: "High request latency on {{ $labels.instance }}" description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"这个规则文件里,包含了两条告警规则:InstanceDown 和 APIHighRequestLatency。顾名思义,InstanceDown 表示当实例宕机时(up === 0)触发告警,APIHighRequestLatency 表示有一半的 API 请求延迟大于 1s 时(api_http_request_latencies_second{quantile="0.5"} > 1)触发告警。
搜索公众号GitHub猿回复“理财”,送你一份惊喜礼包。
配置好后,需要重启下 Prometheus server,然后访问 http://localhost:9090/rules 可以看到刚刚配置的规则:
访问 http://localhost:9090/alerts 可以看到根据配置的规则生成的告警:
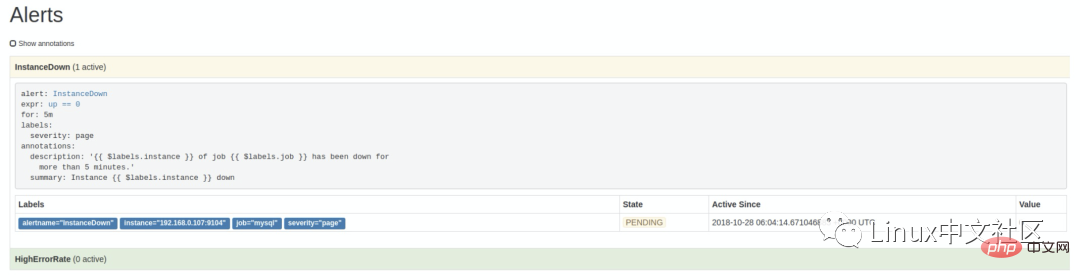
这里我们将一个实例停掉,可以看到有一条 alert 的状态是 PENDING,这表示已经触发了告警规则,但还没有达到告警条件。这是因为这里配置的 for 参数是 5m,也就是 5 分钟后才会触发告警,我们等 5 分钟,可以看到这条 alert 的状态变成了 FIRING。
6.2 使用 Alertmanager 发送告警通知
虽然 Prometheus 的 <span style="outline: 0px;color: rgb(0, 0, 0);">/alerts</span> 页面可以看到所有的告警,但是还差最后一步:触发告警时自动发送通知。这是由 Alertmanager 来完成的,我们首先 下载并安装 Alertmanager,和其他 Prometheus 的组件一样,Alertmanager 也是开箱即用的:
$ wget https://github.com/prometheus/alertmanager/releases/download/v0.15.2/alertmanager-0.15.2.linux-amd64.tar.gz $ tar xvfz alertmanager-0.15.2.linux-amd64.tar.gz $ cd alertmanager-0.15.2.linux-amd64 $ ./alertmanager
Alertmanager 启动后默认可以通过 http://localhost:9093/ 来访问,但是现在还看不到告警,因为我们还没有把 Alertmanager 配置到 Prometheus 中,我们回到 Prometheus 的配置文件 prometheus.yml,添加下面几行:
alerting: alertmanagers: - scheme: http static_configs: - targets: - "192.168.0.107:9093"
这个配置告诉 Prometheus,当发生告警时,将告警信息发送到 Alertmanager,Alertmanager 的地址为 http://192.168.0.107:9093。也可以使用命名行的方式指定 Alertmanager:
$ ./prometheus -alertmanager.url=http://192.168.0.107:9093
这个时候再访问 Alertmanager,可以看到 Alertmanager 已经接收到告警了:
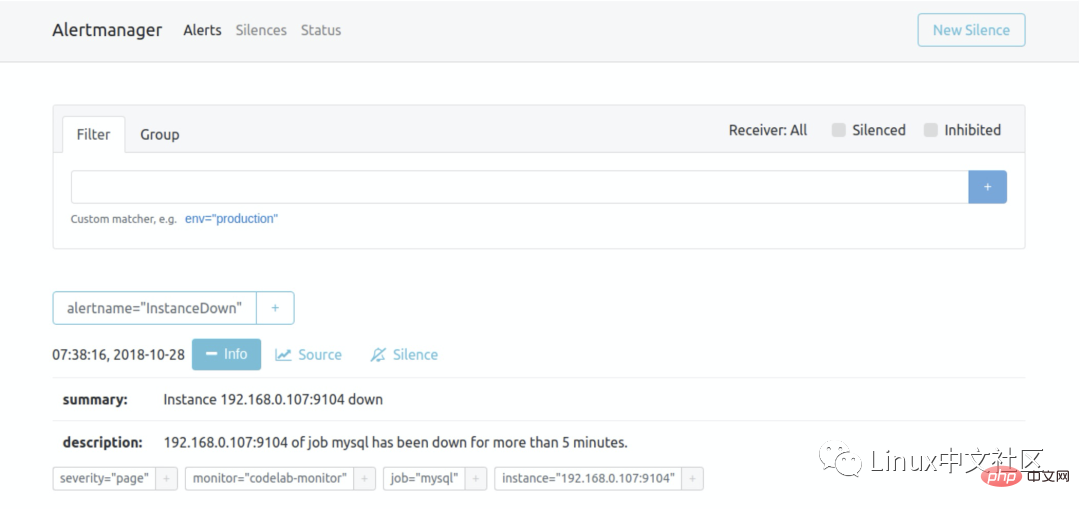
下面的问题就是如何让 Alertmanager 将告警信息发送给我们了,我们打开默认的配置文件 alertmanager.ym:
global: resolve_timeout: 5m route: group_by: ['alertname'] group_wait: 10s group_interval: 10s repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']
参考 官方的配置手册 了解各个配置项的功能,其中 global 块表示一些全局配置;route 块表示通知路由,可以根据不同的标签将告警通知发送给不同的 receiver,这里没有配置 routes 项,表示所有的告警都发送给下面定义的 web.hook 这个 receiver;如果要配置多个路由,可以参考 这个例子:
routes: - receiver: 'database-pager' group_wait: 10s match_re: service: mysql|cassandra - receiver: 'frontend-pager' group_by: [product, environment] match: team: frontend
紧接着,receivers 块表示告警通知的接收方式,每个 receiver 包含一个 name 和一个 xxx_configs,不同的配置代表了不同的接收方式,Alertmanager 内置了下面这些接收方式:
- #email_config
- hipchat_config
- pagerduty_config
- #pushover_config
- slack_config
- opsgenie_config ##victorops_config
- wechat_configs
- webhook_config
- 受信方法はたくさんありますが、そのほとんどは中国ではほとんど使用されていません。最も一般的に使用されるのは、
と webhook_config です。さらに、wechat_configs は、WeChat を使用したアラートをサポートでき、これは国の状況に非常に一致しています。 実際には、さまざまなメッセージング ソフトウェアがあり、国ごとに異なる可能性があるため、包括的なアラーム通知方法を提供することは困難であり、完全にカバーすることは不可能であるため、Alertmanager は追加しないことを決定しました。代わりに、Webhook を使用してカスタム受信メソッドを統合することをお勧めします。 DingTalk を Prometheus AlertManager WebHook に接続するなど、これらの統合例を参照できます。
7. 詳細はこちら
ここまでで、Prometheus のほとんどの機能を学習しました。Prometheus Grafana Alertmanager と組み合わせると、非常に完全なセット監視システム。しかし、実際に使ってみると、さらなる問題が見つかります。
7.1 Service Discovery
Prometheus は、Pull により監視データを能動的に取得するため、監視ノードのリストを手動で指定する必要があり、監視ノードの数が増加した場合は、監視ノードごとに変更する必要があります。構成ファイルは非常に面倒なので、これはサービス検出 (SD) メカニズムを通じて解決する必要があります。
Prometheus は複数のサービス検出メカニズムをサポートしており、収集するターゲットを自動的に取得できます。こちらを参照してください。含まれているサービス検出メカニズムには、azure、consul、dns、ec2、openstack、file、gce、kubernetes が含まれます、marathon、triton、zookeeper (nerve、serverset)、設定方法についてはマニュアルの設定ページを参照してください。 SD メカニズムは非常に充実していると言えますが、現在は開発リソースが限られているため、新しい SD メカニズムは開発されず、ファイルベースの SD メカニズムのみが維持されています。
サービス ディスカバリに関するインターネット上には多くのチュートリアルがあります。たとえば、Prometheus 公式ブログのこの記事「Advanced Service Discovery in Prometheus 0.14.0」には、これについて比較的体系的に紹介されており、再ラベル付けの設定とDNS の使用方法 - SRV、Consul、およびサービス検出用のファイル。
さらに、公式 Web サイトでは、ファイルベースのサービス検出の入門例も提供されており、Julius Volz が作成した Prometheus ワークショップの入門チュートリアルでも、サービス検出に DNS-SRV が使用されています。また、マイクロサービス シリーズのインタビューの質問と回答も整理されており、WeChat でインターネット アーキテクトを検索し、バックグラウンドで 2T を送信し、オンラインで読むことができます。
7.2 アラート構成管理
Prometheus の構成であっても、Alertmanager の構成であっても、動的に変更できる API はありません。非常に一般的なシナリオは、Prometheus に基づいてカスタマイズ可能なルールを備えたアラーム システムを構築する必要があるということです。ユーザーは、次のように、自分のニーズに応じてページ上でアラーム ルールを作成、変更、削除したり、アラーム通知方法や連絡先を変更したりできます。 Prometheus Google グループのこのユーザーからの質問: API などを介して rules.conf および prometheus yml ファイルにアラート ルールを動的に追加するにはどうすればよいですか?
しかし、残念ながら、Simon Pasquier 氏は、現在そのような API はなく、将来的にそのような API を開発する計画もない、と以下のように述べています。そのような機能は、たとえば Puppet や Chef に任せるべきであるためです。 、Ansible、Salt、その他の構成管理システム。
7.3 Pushgateway の使用
概要
このブログは、1046102779 Prometheus などの文書やブログなど、インターネット上の Prometheus に関する多数の中国語資料を参照しています。非 公式の中国語マニュアルである Song Jiayang の電子書籍「Prometheus in Action」は、ここでこれらの原作者に敬意を表しています。 Prometheus 公式ドキュメントのメディア ページにも、多くの学習リソースが提供されています。
Prometheus に関しては、このブログで取り上げていない非常に重要な部分がまだあります。ブログの冒頭で述べたように、Prometheus は Kubernetes に次いで CNCF に参加する 2 番目のプロジェクトです。Prometheus は Docker および Kubernetes と非常に密接に統合されています。 、Docker と Kubernetes の監視システムとして Prometheus を使用することがますます主流になってきています。
Docker の監視については、公式 Web サイトのガイド「cAdvisor を使用した Docker コンテナーのメトリクスの監視」を参照してください。cAdvisor を使用してコンテナーを監視する方法が紹介されていますが、Docker は Prometheus の監視もネイティブにサポートし始めています。 Docker の公式ドキュメント「Collect Docker metrics with Prometheus」を参照してください。Kubernetes の監視に関しては、Kubernetes の中国語コミュニティに Prometheus に関する多くのリソースがあります。また、電子書籍「How to Monitor Kubernetes with Elegant Posture」には Kubernetes 監視のガイドもあります. 比較的包括的な紹介です。
過去 2 年間で、Prometheus は非常に急速に発展し、コミュニティも非常に活発で、中国では Prometheus を研究する人が増えています。マイクロサービス、DevOps、クラウド コンピューティング、クラウド ネイティブなどの概念の普及に伴い、Docker や Kubernetes を使用して独自のシステムやアプリケーションを構築する企業が増えており、Nagios や Cacti などの古い監視システムがますます人気になるでしょう。適用性が低いほど、Prometheus は最終的にはクラウド環境に最適な監視システムに発展すると信じています。
付録: 時系列データベースとは何ですか?
前述したように、Prometheus は時系列データベースをベースとした監視システムであり、時系列データベースは TSDB (Time Series Database) と略されることもあります。一般的な監視システムの多くは、時系列データベースの特性が監視システムと一致するため、データの保存に時系列データベースを使用します。
+ タイムブロック内のすべてのデータを削除します#変更: 書き込まれたデータを更新する必要はありません - #チェック: 高い同時読み取り操作をサポートする必要があります、読み取り操作が時間の昇順または降順である、データ量が非常に多い、キャッシュが機能しない
- DB-Engines には時系列データベースに関するランキングがあり、以下はランキング上位数名 (2018 年 10 月):
- InfluxDB: https://influxdata.com/
- Graphite: http://graphiteapp.org/ ##RRDtool: http://oss.oetiker. ch/ rrdtool/
- OpenTSDB:http://opentsdb.net/
- Prometheus:https://prometheus.io/
- ドルイド: http://druid.io/
- さらに、liubin は自身のブログに時系列データベースに関する一連の記事を書きました: Time seriesデータベース武道会議、お勧めです。
以上が次世代監視システムとも言われるその実力を試してみましょう!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。