


#パート 1Linux パフォーマンスの最適化
#1 パフォーマンスの最適化
パフォーマンス指標
高い同時実行性と高速応答は、パフォーマンス最適化の 2 つのコアに対応しますメトリック: スループットおよびレイテンシー
アプリケーション負荷角度: 製品端末のユーザー エクスペリエンスに直接影響します -
システム リソース視点: リソースの使用量、飽和度など
パフォーマンス問題の本質は、システム リソースがボトルネックに達しているにもかかわらず、リクエストの処理速度が十分ではないため、より多くのリクエストをサポートできないことです。パフォーマンス分析は実際には、アプリケーションまたはシステムのボトルネックを見つけて、それらを回避または軽減することを目的としています。
#アプリケーションとシステムのパフォーマンスを評価するためのメトリクスを選択する - #アプリケーションとシステムのパフォーマンス目標を設定する
- パフォーマンス ベンチマーク テストの実行
- ボトルネックを特定するためのパフォーマンス分析
- パフォーマンスの監視とアラーム
平均負荷: 単位時間あたりのシステムの実行可能および中断不可能な状態にあるプロセスの平均数、つまりアクティブなプロセスの平均数。これは、私たちが従来理解しているように、CPU 使用率とは直接関係しません。 無中断プロセスは、カーネル状態で重要なプロセス (デバイスを待機している共通 I/O 応答など) にあるプロセスです。 無停電状態は、実際には、プロセスとハードウェア デバイスに対するシステムの保護メカニズムです。 実際の運用環境では、システムの平均負荷を監視し、過去のデータに基づいて負荷の変化傾向を判断します。データ。負荷が明らかに増加傾向にある場合は、タイムリーに分析と調査を実施します。もちろん、しきい値を設定することもできます (平均負荷が CPU 数の 70% を超える場合など) #実際の作業では、平均という概念が混同されることがよくあります。負荷と CPU 使用率実際、この 2 つは完全に同等ではありません: ##CPU コンテキストの切り替え は、前のタスクの CPU コンテキスト (CPU レジスタと PC) を保存し、新しいタスクのコンテキストをこれらのレジスタとプログラム カウンタにロードし、最後に指定されたプログラム カウンタにジャンプします。新しいタスクを実行する場所。このうち、保存されたコンテキストはシステム カーネルに保存され、元のタスクのステータスが影響を受けないように、タスクの実行が再スケジュールされるときに再度ロードされます。 タスクの種類に応じて、CPU コンテキストの切り替えは次のように分類されます: Linux プロセスは、次に従ってプロセスの実行スペースを割り当てます。パーミッションのレベルまで カーネル空間とユーザー空間に分割されます。ユーザーモードからカーネルモードへの移行は、システムコールを通じて完了する必要があります。 システム コール プロセスは、実際には 2 つの CPU コンテキスト スイッチを実行します。 # システムコール処理中に、仮想メモリなどのプロセスのユーザーモードリソースが関与したり、プロセスが切り替わったりすることはありません。これは、従来の意味でのプロセス コンテキストの切り替えとは異なります。したがって、 システム コールは特権モード スイッチ と呼ばれることがよくあります。 プロセスはカーネルによって管理およびスケジュールされ、プロセス コンテキストの切り替えはカーネル状態でのみ発生します。したがって、システムコールと比較して、現在のプロセスのカーネル状態と CPU レジスタを保存する前に、プロセスの仮想メモリとスタックを最初に保存する必要があります。新しいプロセスのカーネル状態をロードした後、プロセスの仮想メモリとユーザー スタックを更新する必要があります。 プロセスは、CPU 上で実行するようにスケジュールされている場合にのみコンテキストを切り替える必要があります。次のようなシナリオがあります: CPU タイム スライスが順番に割り当てられ、システム リソースが不十分なためにプロセスがアクティブサスペンドでは、優先度の高いプロセスがタイムスライスを占有し、ハードウェア割り込みが発生すると、CPU 上のプロセスが一時停止され、代わりにカーネル内の割り込みサービスが実行されます。 スレッド コンテキストの切り替えは 2 つのタイプに分けられます。 # 同じプロセス内でスレッドを切り替えると、消費するリソースが少なくなります。これもマルチスレッドの利点です。 割り込みコンテキストの切り替えにはプロセスのユーザー モードが関与しないため、割り込みコンテキストにはカーネル モードの実行に必要な状態のみが含まれます。割り込みサービス プログラム (CPU レジスタ、カーネル スタック、ハードウェア割り込みパラメータなど)。 ##割り込み処理の優先順位がプロセスよりも高いため、割り込みコンテキストの切り替えとプロセスのコンテキスト切り替えが同時に発生することはありません Docker K8s Jenkins メインストリーム テクノロジの包括的なビデオ情報 vmstat 说明运行/等待CPU的进程过多,导致大量的上下文切换,上下文切换导致系统的CPU占用率高 从结果中看出是sysbench导致CPU使用率过高,但是pidstat输出的上下文次数加起来也并不多。分析sysbench模拟的是线程的切换,因此需要在pidstat后加-t参数查看线程指标。 另外对于中断次数过多,我们可以通过/proc/interrupts文件读取 发现次数变化速度最快的是重调度中断(RES),该中断用来唤醒空闲状态的CPU来调度新的任务运行。分析还是因为过多任务的调度问题,和上下文切换分析一致。 Linux作为多任务操作系统,将CPU时间划分为很短的时间片,通过调度器轮流分配给各个任务使用。为了维护CPU时间,Linux通过事先定义的节拍率,触发时间中断,并使用全局变了jiffies记录开机以来的节拍数。时间中断发生一次该值+1. CPU使用率,除了空闲时间以外的其他时间占总CPU时间的百分比。可以通过/proc/stat中的数据来计算出CPU使用率。因为/proc/stat时开机以来的节拍数累加值,计算出来的是开机以来的平均CPU使用率,一般意义不大。可以间隔取一段时间的两次值作差来计算该段时间内的平均CPU使用率。性能分析工具给出的都是间隔一段时间的平均CPU使用率,要注意间隔时间的设置。 CPU使用率可以通过top 或 ps来查看。分析进程的CPU问题可以通过perf,它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。 perf top / perf record / perf report (-g 开启调用关系的采样) 发现此时每秒可承受请求给长少,此时将测试的请求数从100增加到10000。在另外一个终端运行top查看每个CPU的使用率。发现系统中几个php-fpm进程导致CPU使用率骤升。 接着用perf来分析具体是php-fpm中哪个函数导致该问题。 发现其中sqrt和add_function占用CPU过多, 此时查看源码找到原来是sqrt中在发布前没有删除测试代码段,存在一个百万次的循环导致。将该无用代码删除后发现nginx负载能力明显提升 实验结果中每秒请求数依旧不高,我们将并发请求数降为5后,nginx负载能力依旧很低。 此时用top和pidstat发现系统CPU使用率过高,但是并没有发现CPU使用率高的进程。 出现这种情况一般时我们分析时遗漏的什么信息,重新运行top命令并观察一会。发现就绪队列中处于Running状态的进行过多,超过了我们的并发请求次数5. 再仔细查看进程运行数据,发现nginx和php-fpm都处于sleep状态,真正处于运行的却是几个stress进程。 下一步就利用pidstat分析这几个stress进程,发现没有任何输出。用ps aux交叉验证发现依旧不存在该进程。说明不是工具的问题。再top查看发现stress进程的进程号变化了,此时有可能时以下两种原因导致: 可以通过pstree来查找 stress的父进程,找出调用关系。 发现是php-fpm调用的该子进程,此时去查看源码可以看出每个请求都会调用一个stress命令来模拟I/O压力。之前top显示的结果是CPU使用率升高,是否真的是由该stress命令导致的,还需要继续分析。代码中给每个请求加了verbose=1的参数后可以查看stress命令的输出,在中断测试该命令结果显示stress命令运行时存在因权限问题导致的文件创建失败的bug。 此时依旧只是猜测,下一步继续通过perf工具来分析。性能报告显示确实时stress占用了大量的CPU,通过修复权限问题来优化解决即可. 对于不可中断状态,一般都是在很短时间内结束,可忽略。但是如果系统或硬件发生故障,进程可能会保持不可中断状态很久,甚至系统中出现大量不可中断状态,此时需注意是否出现了I/O性能问题。 僵尸进程一般多进程应用容易遇到,父进程来不及处理子进程状态时子进程就提前退出,此时子进程就变成了僵尸进程。大量的僵尸进程会用尽PID进程号,导致新进程无法建立。 可以看到此时有多个app进程运行,状态分别时Ss+和D+。其中后面s表示进程是一个会话的领导进程,+号表示前台进程组。 其中进程组表示一组相互关联的进程,子进程是父进程所在组的组员。会话指共享同一个控制终端的一个或多个进程组。 用top查看系统资源发现:1)平均负载在逐渐增加,且1分钟内平均负载达到了CPU个数,说明系统可能已经有了性能瓶颈;2)僵尸进程比较多且在不停增加;3)us和sys CPU使用率都不高,iowait却比较高;4)每个进程CPU使用率也不高,但有两个进程处于D状态,可能在等待IO。 分析目前数据可知:iowait过高导致系统平均负载升高,僵尸进程不断增长说明有程序没能正确清理子进程资源。 用dstat来分析,因为它可以同时查看CPU和I/O两种资源的使用情况,便于对比分析。 可以看到当wai(iowait)升高时磁盘请求read都会很大,说明iowait的升高和磁盘的读请求有关。接下来分析到底时哪个进程在读磁盘。 之前top查看的处于D状态的进程号,用pidstat -d -p XXX 展示进程的I/O统计数据。发现处于D状态的进程都没有任何读写操作。在用pidstat -d 查看所有进程的I/O统计数据,看到app进程在进行磁盘读操作,每秒读取32MB的数据。进程访问磁盘必须使用系统调用处于内核态,接下来重点就是找到app进程的系统调用。 报错没有权限,因为已经时root权限了。所以遇到这种情况,首先要检查进程状态是否正常。ps命令查找该进程已经处于Z状态,即僵尸进程。 这种情况下top pidstat之类的工具无法给出更多的信息,此时像第5篇一样,用perf record -d和perf report进行分析,查看app进程调用栈。 看到app确实在通过系统调用sys_read()读取数据,并且从new_sync_read和blkdev_direct_IO看出进程时进行直接读操作,请求直接从磁盘读,没有通过缓存导致iowait升高。 通过层层分析后,root cause是app内部进行了磁盘的直接I/O。然后定位到具体代码位置进行优化即可。 上記の最適化後、iowait は大幅に減少しましたが、ゾンビ プロセスの数は依然として増加しています。まず、ゾンビ プロセスの親プロセスを見つけます。pstree -aps XXX を使用してゾンビ プロセスの呼び出しツリーを出力し、親プロセスがアプリ プロセスであることを確認します。 アプリ コードをチェックして、子プロセスの終了が正しく処理されているかどうか (wait()/waitpid() が呼び出されているかどうか、SIGCHILD 信号処理関数が登録されているかどうか、等。)。 iowait の増加が発生した場合は、まず dstat pidstat などのツールを使用してディスク I/O の問題があるかどうかを確認し、次にどのプロセスが原因となっているのかを特定します。 I/O.Strace は使用できません プロセス呼び出しを直接分析する場合は、perf ツールを使用できます。 #ゾンビ問題の場合は、pstree を使用して親プロセスを見つけ、ソース コードを参照して子の最後までの処理ロジックを確認します。プロセス。 CPU 使用率 平均負荷 理想的な負荷平均 論理 CPU の数に等しい場合は、各 CPU が最大限に活用されていることを意味し、大きいほどシステム負荷が高いことを意味します。 プロセス コンテキスト スイッチ リソースを取得できない場合の自発的な切り替えと、システムがスケジュールを強制する場合の非自発的な切り替えが含まれます。コンテキストの切り替え自体は、Linux の正常な動作を保証するためのコア機能です。過度の切り替えは、元々実行されていたプロセスの CPU 時間を削減します。レジスタ、カーネル占有、仮想メモリなどのデータの保存と復元に消費されます。さらに、パブリック アカウント プログラマー Xiaole のバックステージを検索して「インタビューの質問」に答え、サプライズ ギフト パッケージを入手します。 #CPU キャッシュ ヒット率 CPU キャッシュの再利用状況は、ヒット率が高くなります。パフォーマンスが高いほど優れています。L1/L2 はシングルコアでよく使用され、L3 はマルチコアで使用されます さまざまな情報によると、パフォーマンス インジケーター 適切なツールを見つけます: から引用運用環境 開発者は新しいツール パッケージをインストールする権限を持たないことが多く、システムにすでにインストールされているツールを最大限に活用することしかできません。したがって、一部の主流ツールがどのような指標分析を提供できるかを理解する必要があります。 まず、top/vmstat など、より多くのインジケーターをサポートするいくつかのツールを実行します。 /pidstat の出力に基づいて、パフォーマンスの問題の種類を判断できます。プロセスを見つけたら、strace/perf を使用して呼び出し状況を分析し、さらに分析します。ソフト割り込みが原因の場合は、/proc/softirqs を使用します。 #同時実行性 #QPS(TPS)=同時実行数/平均応答時間 ##サーバーの内部処理 サーバーは戻りますto Client
QPS (Queries Per Second) 1 秒あたりのクエリ レート、サーバーが 1 秒あたりに応答できるクエリの数。 #TPS (Transactions Per Second) 1 秒あたりのトランザクション数、ソフトウェア テストの結果。 ##システム スループット (いくつかの重要なパラメータを含む): ほとんどのコンピュータで使用されるメイン メモリはダイナミック ランダム アクセス メモリ (DRAM) であり、物理メモリに直接アクセスできるのはカーネルだけです。メモリ。 Linux カーネルはプロセスごとに独立した仮想アドレス空間を提供し、このアドレス空間は連続的です。このようにして、プロセスはメモリ (仮想メモリ) に簡単にアクセスできます。 仮想アドレス空間の内部はカーネル空間とユーザー空間の2つに分かれており、ワード長の異なるプロセッサではアドレス空間の範囲が異なります。 32 ビット システムのカーネル空間は 1G を占有し、ユーザー空間は 3G を占有します。 64 ビット システムのカーネル空間とユーザー空間は両方とも 128T で、それぞれメモリ空間の最高位と最低位の部分を占め、中間部分は未定義です。 すべての仮想メモリが物理メモリを割り当てるわけではなく、実際に使用される場合のみ割り当てられます。割り当てられた物理メモリは、メモリ マッピングを通じて管理されます。メモリ マッピングを完了するために、カーネルはプロセスごとにページ テーブルを維持し、仮想アドレスと物理アドレス間のマッピング関係を記録します。ページ テーブルは実際には CPU のメモリ管理ユニット MMU に格納されており、プロセッサはハードウェアを介してアクセスするメモリを直接見つけることができます。 プロセスによってアクセスされた仮想アドレスがページ テーブルで見つからない場合、システムはページ フォールト例外を生成し、カーネル空間に入って物理メモリを割り当て、プロセス ページを更新します。テーブルにアクセスし、ユーザーに戻ります。 スペース回復プロセスが実行されます。 MMU は、ページ サイズが 4KB のページ単位でメモリを管理します。ページ テーブル エントリが多すぎる問題を解決するために、Linux は マルチレベル ページ テーブル および HugePage メカニズムを提供します。 ユーザー空間メモリには、低位から高位まで 5 つの異なるメモリ セグメントがあります: #malloc そこにありますは、システム コールに対応する 2 つの実装メソッドです: #前者のキャッシュでは、ページ フォールト例外の発生を減らし、メモリ アクセス効率を向上させることができます。ただし、メモリはシステムに返されないため、メモリがビジー状態のときにメモリの割り当て/解放が頻繁に行われると、メモリの断片化が発生します。 後者は解放時にシステムに直接返されるため、mmap が発生するたびにページフォールト例外が発生します。メモリ作業がビジーな場合、メモリ割り当てが頻繁に行われると、大量のページ フォールト例外が発生し、カーネル管理の負担が増加します。 上記の 2 つの呼び出しでは、実際にはメモリが割り当てられません。これらのメモリは、最初にアクセスされたときにのみページ フォールト例外を通じてカーネルに入り、カーネルによって割り当てられます メモリが不足している場合、システムは次の方法でメモリを再利用します: ##キャッシュをリサイクルする: LRU アルゴリズムは最も最近使用されていないメモリ ページをリサイクルします; アクセス頻度の低いメモリをリサイクルします: 使用頻度が低いメモリをリサイクルしますスワップ パーティションを介してディスクに書き込みます プロセスを強制終了します: OOM カーネル保護メカニズム (プロセスによって消費されるメモリが大きくなるほど、 oom_score が大きいほど、CPU 占有率が高くなります。oom_score が大きいほど、値は小さくなります。oom_adj は、/proc) を通じて手動で調整できます。 free来查看整个系统的内存使用情况 top/ps来查看某个进程的内存使用情况
「平均負荷」をどのように理解すればよいか
妥当な平均負荷とは何ですか?
#2CPU
CPU コンテキストの切り替え (パート 1)
プロセス コンテキスト切り替え
スレッド コンテキストの切り替え
割り込みコンテキストの切り替え
CPU コンテキスト スイッチング (パート 2)
vmstat 5 #每隔5s输出一组数据
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 103388 145412 511056 0 0 18 60 1 1 2 1 96 0 0
0 0 0 103388 145412 511076 0 0 0 2 450 1176 1 1 99 0 0
0 0 0 103388 145412 511076 0 0 0 8 429 1135 1 1 98 0 0
0 0 0 103388 145412 511076 0 0 0 0 431 1132 1 1 98 0 0
0 0 0 103388 145412 511076 0 0 0 10 467 1195 1 1 98 0 0
1 0 0 103388 145412 511076 0 0 0 2 426 1139 1 0 99 0 0
4 0 0 95184 145412 511108 0 0 0 74 500 1228 4 1 94 0 0
0 0 0 103512 145416 511076 0 0 0 455 723 1573 12 3 83 2 0
各プロセスの詳細を表示するには、次の手順を実行する必要があります。 pidstat を使用して各プロセスを表示する プロセス コンテキストの切り替え状況pidstat -w 5
14时51分16秒 UID PID cswch/s nvcswch/s Command
14时51分21秒 0 1 0.80 0.00 systemd
14时51分21秒 0 6 1.40 0.00 ksoftirqd/0
14时51分21秒 0 9 32.67 0.00 rcu_sched
14时51分21秒 0 11 0.40 0.00 watchdog/0
14时51分21秒 0 32 0.20 0.00 khugepaged
14时51分21秒 0 271 0.20 0.00 jbd2/vda1-8
14时51分21秒 0 1332 0.20 0.00 argusagent
14时51分21秒 0 5265 10.02 0.00 AliSecGuard
14时51分21秒 0 7439 7.82 0.00 kworker/0:2
14时51分21秒 0 7906 0.20 0.00 pidstat
14时51分21秒 0 8346 0.20 0.00 sshd
14时51分21秒 0 20654 9.82 0.00 AliYunDun
14时51分21秒 0 25766 0.20 0.00 kworker/u2:1
14时51分21秒 0 28603 1.00 0.00 python3
vmstat 1 1 #首先获取空闲系统的上下文切换次数
sysbench --threads=10 --max-time=300 threads run #模拟多线程切换问题
vmstat 1 1 #新终端观察上下文切换情况
此时发现cs数据明显升高,同时观察其他指标:
r列: 远超系统CPU个数,说明存在大量CPU竞争
us和sy列:sy列占比80%,说明CPU主要被内核占用
in列: 中断次数明显上升,说明中断处理也是潜在问题
pidstat -w -u 1 #查看到底哪个进程导致的问题
watch -d cat /proc/interrupts
某个应用的CPU使用率达到100%,怎么办?
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx
sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
ab -c 10 -n 100 http://XXX.XXX.XXX.XXX:10000/ #测试Nginx服务性能
perf top -g -p XXXX #对某一个php-fpm进程进行分析
系统的CPU使用率很高,为什么找不到高CPU的应用?
sudo docker run --name nginx -p 10000:80 -itd feisky/nginx:sp
sudo docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:sp
ab -c 100 -n 1000 http://XXX.XXX.XXX.XXX:10000/ #并发100个请求测试
pstree | grep stress
システム内に多数の中断不可能なプロセスやゾンビ プロセスが存在する場合はどうすればよいですか?
プロセス ステータス
磁盘O_DIRECT问题
sudo docker run --privileged --name=app -itd feisky/app:iowait
ps aux | grep '/app'
dstat 1 10 #间隔1秒输出10组数据
sudo strace -p XXX #对app进程调用进行跟踪
ゾンビ プロセス
CPU パフォーマンス インジケーター
パフォーマンス ツール



#QPS(TPS)
#3メモリ
Linux メモリの仕組み
メモリ マッピング
仮想メモリ空間の分散
メモリの割り当てとリサイクル
割り当て
リサイクル
echo -16 > /proc/$(pidof XXX)/oom_adj
如何查看内存使用情况
#メモリ内のバッファとキャッシュを理解するにはどうすればよいですか?
#buffer はディスク データのキャッシュ、cache はファイル データのキャッシュです。これらは読み取りリクエストと書き込みリクエストの両方で使用されます
システム キャッシュを使用してプログラムの実行効率を最適化する方法
キャッシュ ヒット率
#キャッシュ ヒット率 は、キャッシュを通じて直接データを取得するリクエストの数を指し、すべてのリクエストの割合を占めます。 ヒット率が高いほど、キャッシュによってもたらされる利点が大きくなり、アプリケーションのパフォーマンスが向上します。
bcc パッケージをインストールした後は、cachestat および cachetop を通じてキャッシュの読み取りおよび書き込みヒットを監視できます。
安装pcstat后可以查看文件在内存中的缓存大小以及缓存比例
#首先安装Go export GOPATH=~/go export PATH=~/go/bin:$PATH go get golang.org/x/sys/unix go ge github.com/tobert/pcstat/pcstat
dd缓存加速
dd if=/dev/sda1 of=file bs=1M count=512 #生产一个512MB的临时文件 echo 3 > /proc/sys/vm/drop_caches #清理缓存 pcstat file #确定刚才生成文件不在系统缓存中,此时cached和percent都是0 cachetop 5 dd if=file of=/dev/null bs=1M #测试文件读取速度 #此时文件读取性能为30+MB/s,查看cachetop结果发现并不是所有的读都落在磁盘上,读缓存命中率只有50%。 dd if=file of=/dev/null bs=1M #重复上述读文件测试 #此时文件读取性能为4+GB/s,读缓存命中率为100% pcstat file #查看文件file的缓存情况,100%全部缓存
O_DIRECT选项绕过系统缓存
cachetop 5 sudo docker run --privileged --name=app -itd feisky/app:io-direct sudo docker logs app #确认案例启动成功 #实验结果表明每读32MB数据都要花0.9s,且cachetop输出中显示1024次缓存全部命中
但是凭感觉可知如果缓存命中读速度不应如此慢,读次数时1024,页大小为4K,五秒的时间内读取了1024*4KB数据,即每秒0.8MB,和结果中32MB相差较大。说明该案例没有充分利用缓存,怀疑系统调用设置了直接I/O标志绕过系统缓存。因此接下来观察系统调用.
strace -p $(pgrep app) #strace 结果可以看到openat打开磁盘分区/dev/sdb1,传入参数为O_RDONLY|O_DIRECT
这就解释了为什么读32MB数据那么慢,直接从磁盘读写肯定远远慢于缓存。找出问题后我们再看案例的源代码发现flags中指定了直接IO标志。删除该选项后重跑,验证性能变化。
メモリ リーク、それを特定して対処する方法は?
アプリケーションにとって、動的なメモリの割り当てとリサイクルは、中核となる複雑な論理機能モジュールです。記憶を管理する過程でさまざまな「事故」が起こります:
#割り当てられたメモリが適切に再利用されず、リークが発生します。 割り当てられたメモリ境界外のアドレスは次のとおりです。にアクセスすると、プログラムが異常終了します。
メモリの割り当てとリサイクル
仮想メモリの低位から高位への配分is読み取り専用セグメント、データセグメント、ヒープ、メモリマッピングセグメント、スタックの5つの部分。その中で、メモリ リークを引き起こすものは次のとおりです:
ヒープ: アプリケーション自体によって割り当ておよび管理され、プログラムが終了しない限り、これらのヒープ メモリはシステムによって自動的に解放されません。 -
#メモリ マッピング セグメント: ダイナミック リンク ライブラリと共有メモリを含み、共有メモリはプログラムによって自動的に割り当てられ、管理されます
メモリ リークはさらに有害で、解放し忘れられたメモリにアプリケーション自体がアクセスできないだけでなく、システムはそのメモリを他のアプリケーションに再度割り当てることもできません。 メモリ リークは蓄積し、システム メモリを使い果たすこともあります。
メモリ リークを検出する方法
systat、docker、bcc# を事前にインストールします## 可以看到free在不断下降,buffer和cache基本保持不变。说明系统的内存一致在升高。但并不能说明存在内存泄漏。此时可以通过memleak工具来跟踪系统或进程的内存分配/释放请求。另外,搜索公众号Linux就该这样学后台回复“git书籍”,获取一份惊喜礼包。 从memleak输出可以看到,应用在不停地分配内存,并且这些分配的地址并没有被回收。通过调用栈看到是fibonacci函数分配的内存没有释放。定位到源码后查看源码来修复增加内存释放函数即可. 系统内存资源紧张时通过内存回收和OOM杀死进程来解决。其中可回收内存包括: スワップの本質は、ディスク領域の一部またはローカル ファイルをメモリとして使用することです。これには、スワップインとスワップアウトの 2 つのプロセスが含まれます。 Linux はメモリ リソースが不足しているかどうかをどのように測定しますか? ダイレクト メモリ リサイクル 新しい大きなブロック メモリ割り当て要求ですが、残りのメモリが不十分です。このとき、システムはメモリの一部を再利用します。 kswapd0 カーネル スレッドは定期的にメモリを再利用します。メモリ。メモリ使用量を測定するために、pages_min、pages_low、pages_high の 3 つのしきい値が定義され、それらに基づいてメモリのリサイクル操作が実行されます。 残りメモリ ## になるまでメモリのリサイクルを実行します 剩余内存 > pages_high,说明剩余内存较多,无内存压力 pages_low = pages_min 5 / 4 pages_high = pages_min 3 / 2 很多情况下系统剩余内存较多,但SWAP依旧升高,这是由于处理器的NUMA架构。 在NUMA架构下多个处理器划分到不同的Node,每个Node都拥有自己的本地内存空间。在分析内存的使用时应该针对每个Node单独分析 内存三个阈值可以通过/proc/zoneinfo来查看,该文件中还包括活跃和非活跃的匿名页/文件页数。 ノードのメモリが不足すると、システムは他のノードから空きリソースを見つけたり、ローカル メモリからメモリを再利用したりできます。 /proc/sys/vm/zone_raclaim_mode で調整します。 実際のリサイクル プロセス中に、Linux は /proc/sys/vm に従って使用量を調整します。 /swapiness オプション Swap の積極性の範囲は 0 ~ 100 です。値が大きいほど、Swap がより積極的に使用され、つまり匿名ページをリサイクルする傾向が高くなります。値が小さいほど、Swap の使用がより受動的になります。 、ファイルページをリサイクルする傾向が高くなります。 注意:这只是调整Swap积极程度的权重,即使设置为0,当剩余内存+文件页小于页高阈值时,还是会发生Swap。 说明剩余内存和缓冲区的波动变化正是由于内存回收和缓存再次分配的循环往复。有时候Swap用的多,有时候缓冲区波动更多。此时查看swappiness值为60,是一个相对中和的配置,系统会根据实际运行情况来选去合适的回收类型. システム メモリ インデックス# プロセス メモリ インジケーター ページ欠落例外 さまざまな情報に基づいて適切なツールを見つけてください。パフォーマンス指標 :######
一般的な最適化アイデア: pidstat主要用于监控全部或指定进程占用系统资源的情况,如CPU,内存、设备IO、任务切换、线程等。 使用方法: ##1. IO 使用量に関する統計 2、统计CPU使用情况 3. 統計的なメモリ使用量 4、查看具体进程使用情况sudo docker run --name=app -itd feisky/app:mem-leak
sudo docker logs app
vmstat 3
/usr/share/bcc/tools/memleak -a -p $(pidof app)
为什么系统的Swap变高
プログラムによって自動的に割り当てられたヒープ メモリ (メモリ管理の匿名ページ) については、このメモリを直接解放することはできませんが、Linux は、アクセス頻度の低いメモリをメモリに書き込むためのスワップ メカニズムを提供します。ディスクをメモリに読み込むだけでメモリが解放されます。
スワップの原理
NUMA 与 SWAP
numactl --hardware #查看处理器在Node的分布情况,以及每个Node的内存使用情况
swappiness
Swap升高时如何定位分析
free #首先通过free查看swap使用情况,若swap=0表示未配置Swap
#先创建并开启swap
fallocate -l 8G /mnt/swapfile
chmod 600 /mnt/swapfile
mkswap /mnt/swapfile
swapon /mnt/swapfile
free #再次执行free确保Swap配置成功
dd if=/dev/sda1 of=/dev/null bs=1G count=2048 #模拟大文件读取
sar -r -S 1 #查看内存各个指标变化 -r内存 -S swap
#根据结果可以看出,%memused在不断增长,剩余内存kbmemfress不断减少,缓冲区kbbuffers不断增大,由此可知剩余内存不断分配给了缓冲区
#一段时间之后,剩余内存很小,而缓冲区占用了大部分内存。此时Swap使用之间增大,缓冲区和剩余内存只在小范围波动
停下sar命令
cachetop5 #观察缓存
#可以看到dd进程读写只有50%的命中率,未命中数为4w+页,说明正式dd进程导致缓冲区使用升高
watch -d grep -A 15 ‘Normal’ /proc/zoneinfo #观察内存指标变化
#发现升级内存在一个小范围不停的波动,低于页低阈值时会突然增大到一个大于页高阈值的值
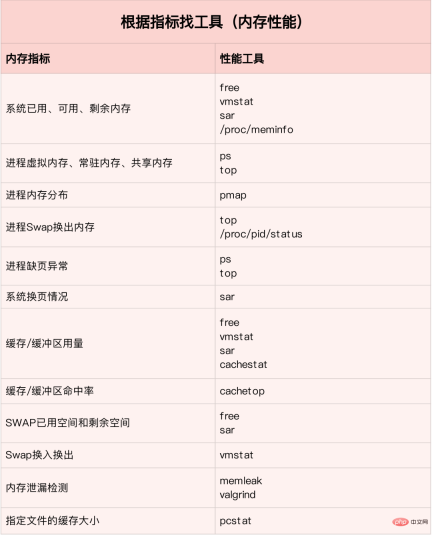
システム メモリの問題を迅速かつ正確に見つける方法
メモリ パフォーマンス インジケーター
メモリ パフォーマンス ツール
 画像出典: www.ctq6.cn
画像出典: www.ctq6.cn
通常は、free、top、vmstat、pidstat など、比較的広い範囲をカバーするいくつかのパフォーマンス ツールを最初に実行します。
vmstat 2
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
1 0 0 1379064 282244 11537528 0 0 3 104 0 0 3 0 97 0 0
0 0 0 1372716 282244 11537544 0 0 0 24 4893 8947 1 0 98 0 0
0 0 0 1373404 282248 11537544 0 0 0 96 5105 9278 2 0 98 0 0
0 0 0 1374168 282248 11537556 0 0 0 0 5001 9208 1 0 99 0 0
0 0 0 1376948 282248 11537564 0 0 0 80 5176 9388 2 0 98 0 0
0 0 0 1379356 282256 11537580 0 0 0 202 5474 9519 2 0 98 0 0
1 0 0 1368376 282256 11543696 0 0 0 0 5894 8940 12 0 88 0 0
1 0 0 1371936 282256 11539240 0 0 0 10554 6176 9481 14 1 85 1 0
1 0 0 1366184 282260 11542292 0 0 0 7456 6102 9983 7 1 91 0 0
1 0 0 1353040 282260 11556176 0 0 0 16924 7233 9578 18 1 80 1 0
0 0 0 1359432 282260 11549124 0 0 0 12576 5495 9271 7 0 92 1 0
0 0 0 1361744 282264 11549132 0 0 0 58 8606 15079 4 2 95 0 0
1 0 0 1367120 282264 11549140 0 0 0 2 5716 9205 8 0 92 0 0
0 0 0 1346580 282264 11562644 0 0 0 70 6416 9944 12 0 88 0 0
0 0 0 1359164 282264 11550108 0 0 0 2922 4941 8969 3 0 97 0 0
1 0 0 1353992 282264 11557044 0 0 0 0 6023 8917 15 0 84 0 0
# 结果说明
- r 表示运行队列(就是说多少个进程真的分配到CPU),我测试的服务器目前CPU比较空闲,没什么程序在跑,当这个值超过了CPU数目,就会出现CPU瓶颈了。这个也和top的负载有关系,一般负载超过了3就比较高,超过了5就高,超过了10就不正常了,服务器的状态很危险。top的负载类似每秒的运行队列。如果运行队列过大,表示你的CPU很繁忙,一般会造成CPU使用率很高。
- b 表示阻塞的进程,这个不多说,进程阻塞,大家懂的。
- swpd 虚拟内存已使用的大小,如果大于0,表示你的机器物理内存不足了,如果不是程序内存泄露的原因,那么你该升级内存了或者把耗内存的任务迁移到其他机器。
- free 空闲的物理内存的大小,我的机器内存总共8G,剩余3415M。
- buff Linux/Unix系统是用来存储,目录里面有什么内容,权限等的缓存,我本机大概占用300多M
- cache cache直接用来记忆我们打开的文件,给文件做缓冲,我本机大概占用300多M(这里是Linux/Unix的聪明之处,把空闲的物理内存的一部分拿来做文件和目录的缓存,是为了提高 程序执行的性能,当程序使用内存时,buffer/cached会很快地被使用。)
- si 每秒从磁盘读入虚拟内存的大小,如果这个值大于0,表示物理内存不够用或者内存泄露了,要查找耗内存进程解决掉。我的机器内存充裕,一切正常。
- so 每秒虚拟内存写入磁盘的大小,如果这个值大于0,同上。
- bi 块设备每秒接收的块数量,这里的块设备是指系统上所有的磁盘和其他块设备,默认块大小是1024byte,我本机上没什么IO操作,所以一直是0,但是我曾在处理拷贝大量数据(2-3T)的机器上看过可以达到140000/s,磁盘写入速度差不多140M每秒
- bo 块设备每秒发送的块数量,例如我们读取文件,bo就要大于0。bi和bo一般都要接近0,不然就是IO过于频繁,需要调整。
- in 每秒CPU的中断次数,包括时间中断
- cs 每秒上下文切换次数,例如我们调用系统函数,就要进行上下文切换,线程的切换,也要进程上下文切换,这个值要越小越好,太大了,要考虑调低线程或者进程的数目,例如在apache和nginx这种web服务器中,我们一般做性能测试时会进行几千并发甚至几万并发的测试,选择web服务器的进程可以由进程或者线程的峰值一直下调,压测,直到cs到一个比较小的值,这个进程和线程数就是比较合适的值了。系统调用也是,每次调用系统函数,我们的代码就会进入内核空间,导致上下文切换,这个是很耗资源,也要尽量避免频繁调用系统函数。上下文切换次数过多表示你的CPU大部分浪费在上下文切换,导致CPU干正经事的时间少了,CPU没有充分利用,是不可取的。
- us 用户CPU时间,我曾经在一个做加密解密很频繁的服务器上,可以看到us接近100,r运行队列达到80(机器在做压力测试,性能表现不佳)。
- sy 系统CPU时间,如果太高,表示系统调用时间长,例如是IO操作频繁。
- id 空闲CPU时间,一般来说,id + us + sy = 100,一般我认为id是空闲CPU使用率,us是用户CPU使用率,sy是系统CPU使用率。
- wt 等待IO CPU时间
pidstat 使用详解
pidstat -d 1 10
03:02:02 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:03 PM 0 816 0.00 918.81 0.00 jbd2/vda1-8
03:02:03 PM 0 1007 0.00 3.96 0.00 AliYunDun
03:02:03 PM 997 7326 0.00 1904.95 918.81 java
03:02:03 PM 997 8539 0.00 3.96 0.00 java
03:02:03 PM 0 16066 0.00 35.64 0.00 cmagent
03:02:03 PM UID PID kB_rd/s kB_wr/s kB_ccwr/s Command
03:02:04 PM 0 816 0.00 1924.00 0.00 jbd2/vda1-8
03:02:04 PM 997 7326 0.00 11156.00 1888.00 java
03:02:04 PM 997 8539 0.00 4.00 0.00 java
# 统计CPU
pidstat -u 1 10
03:03:33 PM UID PID %usr %system %guest %CPU CPU Command
03:03:34 PM 0 2321 3.96 0.00 0.00 3.96 0 ansible
03:03:34 PM 0 7110 0.00 0.99 0.00 0.99 4 pidstat
03:03:34 PM 997 8539 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 984 15517 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 0 24406 0.99 0.00 0.00 0.99 5 java
03:03:34 PM 0 32158 3.96 0.00 0.00 3.96 2 ansible
# 统计内存
pidstat -r 1 10
Average: UID PID minflt/s majflt/s VSZ RSS %MEM Command
Average: 0 1 0.20 0.00 191256 3064 0.01 systemd
Average: 0 1007 1.30 0.00 143256 22720 0.07 AliYunDun
Average: 0 6642 0.10 0.00 6301904 107680 0.33 java
Average: 997 7326 10.89 0.00 13468904 8395848 26.04 java
Average: 0 7795 348.15 0.00 108376 1233 0.00 pidstat
Average: 997 8539 0.50 0.00 8242256 2062228 6.40 java
Average: 987 9518 0.20 0.00 6300944 1242924 3.85 java
Average: 0 10280 3.70 0.00 807372 8344 0.03 aliyun-service
Average: 984 15517 0.40 0.00 6386464 1464572 4.54 java
Average: 0 16066 236.46 0.00 2678332 71020 0.22 cmagent
Average: 995 20955 0.30 0.00 6312520 1408040 4.37 java
Average: 995 20956 0.20 0.00 6093764 1505028 4.67 java
Average: 0 23936 0.10 0.00 5302416 110804 0.34 java
Average: 0 24406 0.70 0.00 10211672 2361304 7.32 java
Average: 0 26870 1.40 0.00 1470212 36084 0.11 promtail
pidstat -T ALL -r -p 20955 1 10
03:12:16 PM UID PID minflt/s majflt/s VSZ RSS %MEM Command
03:12:17 PM 995 20955 0.00 0.00 6312520 1408040 4.37 java
03:12:16 PM UID PID minflt-nr majflt-nr Command
03:12:17 PM 995 20955 0 0 java
以上がLinux パフォーマンスのオールラウンド チューニング体験の概要の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Linux操作:メンテナンスモードを利用しますApr 19, 2025 am 12:08 AM
Linux操作:メンテナンスモードを利用しますApr 19, 2025 am 12:08 AMLinuxメンテナンスモードは、Grubメニューから入力できます。特定の手順は次のとおりです。1)GRUBメニューのカーネルを選択し、「E」を押して編集し、2)「Linux」行の最後に「シングル」または「1」を追加し、3)Ctrl Xを押して開始します。メンテナンスモードは、システム修理、パスワードリセット、システムのアップグレードなどのタスクに安全な環境を提供します。
 Linux:リカバリモード(およびメンテナンス)に入る方法Apr 18, 2025 am 12:05 AM
Linux:リカバリモード(およびメンテナンス)に入る方法Apr 18, 2025 am 12:05 AMLinux Recoveryモードを入力する手順は次のとおりです。1。システムを再起動し、特定のキーを押してGrubメニューを入力します。 2。[RecoveryMode)でオプションを選択します。 3. FSCKやrootなどの回復モードメニューで操作を選択します。リカバリモードを使用すると、シングルユーザーモードでシステムを開始し、ファイルシステムのチェックと修理を実行し、構成ファイルを編集し、システムの問題を解決するのに役立ちます。
 Linuxの重要なコンポーネント:初心者向けに説明されていますApr 17, 2025 am 12:08 AM
Linuxの重要なコンポーネント:初心者向けに説明されていますApr 17, 2025 am 12:08 AMLinuxのコアコンポーネントには、カーネル、ファイルシステム、シェル、および共通ツールが含まれます。 1.カーネルはハードウェアリソースを管理し、基本的なサービスを提供します。 2。ファイルシステムはデータを整理して保存します。 3.シェルは、ユーザーがシステムと対話するインターフェイスです。 4.一般的なツールは、毎日のタスクを完了するのに役立ちます。
 Linux:その基本構造を見てくださいApr 16, 2025 am 12:01 AM
Linux:その基本構造を見てくださいApr 16, 2025 am 12:01 AMLinuxの基本構造には、カーネル、ファイルシステム、およびシェルが含まれます。 1)カーネル管理ハードウェアリソースとUname-Rを使用してバージョンを表示します。 2)ext4ファイルシステムは、大きなファイルとログをサポートし、mkfs.ext4を使用して作成されます。 3)シェルは、BASHなどのコマンドラインインタラクションを提供し、LS-Lを使用してファイルをリストします。
 Linux操作:システム管理とメンテナンスApr 15, 2025 am 12:10 AM
Linux操作:システム管理とメンテナンスApr 15, 2025 am 12:10 AMLinuxシステムの管理とメンテナンスの重要な手順には、次のものがあります。1)ファイルシステム構造やユーザー管理などの基本的な知識をマスターします。 2)システムの監視とリソース管理を実行し、TOP、HTOP、その他のツールを使用します。 3)システムログを使用してトラブルシューティング、JournalCtlおよびその他のツールを使用します。 4)自動化されたスクリプトとタスクのスケジューリングを作成し、Cronツールを使用します。 5)セキュリティ管理と保護を実装し、iPtablesを介してファイアウォールを構成します。 6)パフォーマンスの最適化とベストプラクティスを実行し、カーネルパラメーターを調整し、良い習慣を開発します。
 Linuxのメンテナンスモードの理解:必需品Apr 14, 2025 am 12:04 AM
Linuxのメンテナンスモードの理解:必需品Apr 14, 2025 am 12:04 AMLinuxメンテナンスモードは、起動時にinit =/bin/bashまたは単一パラメーターを追加することにより入力されます。 1.メンテナンスモードの入力:GRUBメニューを編集し、起動パラメーターを追加します。 2。ファイルシステムを読み取りおよび書き込みモードに再マウントします:Mount-Oremount、RW/。 3。ファイルシステムの修復:FSCK/dev/sda1などのFSCKコマンドを使用します。 4.データをバックアップし、データの損失を避けるために慎重に動作します。
 DebianがHadoopデータ処理速度を改善する方法Apr 13, 2025 am 11:54 AM
DebianがHadoopデータ処理速度を改善する方法Apr 13, 2025 am 11:54 AMこの記事では、DebianシステムのHadoopデータ処理効率を改善する方法について説明します。最適化戦略では、ハードウェアのアップグレード、オペレーティングシステムパラメーターの調整、Hadoop構成の変更、および効率的なアルゴリズムとツールの使用をカバーしています。 1.ハードウェアリソースの強化により、すべてのノードが一貫したハードウェア構成、特にCPU、メモリ、ネットワーク機器のパフォーマンスに注意を払うことが保証されます。高性能ハードウェアコンポーネントを選択することは、全体的な処理速度を改善するために不可欠です。 2。オペレーティングシステムチューニングファイル記述子とネットワーク接続:/etc/security/limits.confファイルを変更して、システムによって同時に開くことができるファイル記述子とネットワーク接続の上限を増やします。 JVMパラメーター調整:Hadoop-env.shファイルで調整します
 Debian syslogを学ぶ方法Apr 13, 2025 am 11:51 AM
Debian syslogを学ぶ方法Apr 13, 2025 am 11:51 AMこのガイドでは、Debian SystemsでSyslogの使用方法を学ぶように導きます。 Syslogは、ロギングシステムとアプリケーションログメッセージのLinuxシステムの重要なサービスです。管理者がシステムアクティビティを監視および分析して、問題を迅速に特定および解決するのに役立ちます。 1. syslogの基本的な知識Syslogのコア関数には以下が含まれます。複数のログ出力形式とターゲットの場所(ファイルやネットワークなど)をサポートします。リアルタイムのログ表示およびフィルタリング機能を提供します。 2。syslog(rsyslogを使用)をインストールして構成するDebianシステムは、デフォルトでrsyslogを使用します。次のコマンドでインストールできます:sudoaptupdatesud


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SublimeText3 中国語版
中国語版、とても使いやすい

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

