
オペレーティング システムの概要を詳しく示す 30 枚の画像!
- Linux中文社区転載
- 2023-08-02 17:56:011674ブラウズ
##1. 概要
基本機能
1. 同時実行性
同時性とは巨視的な期間内に複数のプログラムを同時に実行できる能力を指し、並列処理とは複数の命令を同時に実行できる能力を指します。 並列処理には、複数のパイプライン、マルチコア プロセッサ、分散コンピューティング システムなどのハードウェア サポートが必要です。 オペレーティング システムでは、プロセスとスレッドを導入することでプログラムを同時に実行できます。2. 共有
共有とは、システム内のリソースを複数の同時プロセスで使用できることを意味します。 共有方法には、相互排他共有と同時共有の 2 つがあります。 相互に排他的な共有リソースは、プリンタなどのクリティカル リソースと呼ばれます。これらのリソースに同時にアクセスできるのは 1 つのプロセスのみです。相互に排他的なアクセスを実現するには、同期メカニズムが必要です。3. 仮想
仮想テクノロジーは、物理エンティティを複数の論理エンティティに変換します。 仮想化技術には大きく分けて、時間(時間)分割多重技術と空間(空間)分割多重技術の2つがあります。時分割多重技術を使用して、同じプロセッサ上で複数のプロセスを同時に実行できます。これにより、各プロセスが順番にプロセッサを占有し、毎回小さなタイム スライスだけを実行し、素早く切り替えることができます。
仮想メモリは、物理メモリをアドレス空間に抽象化する空間分割多重化テクノロジを使用しており、各プロセスは独自のアドレス空間を持ちます。アドレス空間内のページは物理メモリにマップされます。アドレス空間内のすべてのページが物理メモリ内にある必要はありません。物理メモリ内にないページが使用される場合、ページ置換アルゴリズムが実行されて、ページがメモリに置き換えられます。
4. 非同期
非同期とは、プロセスが一度に実行されるのではなく、停止したり実行されたりして、未知の速度で進行することを意味します。
#基本機能
1. プロセス管理
プロセス制御、プロセス同期、プロセス通信、デッドロック処理、プロセッサーのスケジューリングなど。2. メモリ管理
メモリ割り当て、アドレス マッピング、メモリ保護と共有、仮想メモリなど。3. ファイル管理
ファイルストレージスペースの管理、ディレクトリ管理、ファイルの読み書き管理と保護など。4. デバイス管理
ユーザーの I/O リクエストを完了し、ユーザーがさまざまなデバイスを使用できるようにし、デバイスの使用率を向上させます。 主にバッファ管理、デバイス割り当て、デバイス処理、仮想デバイスなどが含まれます。システムコール
プロセスがユーザーモードでカーネル状態の関数を使用する必要がある場合、プロセスはシステムコールを発行してカーネルに入り、オペレーティングシステムは代わりにそれを完了します。
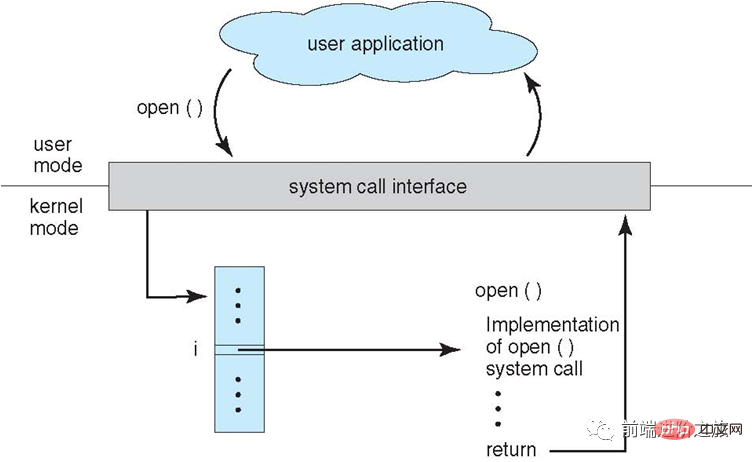

1. ビッグ カーネル
ビッグ カーネルは、オペレーティング システムの機能を緊密に統合された全体としてカーネルに組み込みます。
各モジュールが情報を共有するため、高いパフォーマンスを発揮します。
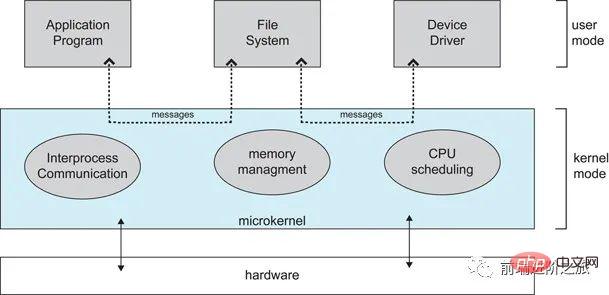
2. マイクロカーネルオペレーティング システムが複雑になるにつれて、カーネルの複雑さを軽減するために、一部のオペレーティング システム機能がカーネルの外に移動されます。削除された部分は、階層化の原則に基づいて、互いに独立した複数のサービスに分割されます。
マイクロカーネル構造では、オペレーティング システムは明確に定義された小さなモジュールに分割されており、マイクロカーネル モジュールのみがカーネル モードで実行され、他のモジュールはユーザー モードで実行されます。
ユーザー モードとコア モードを頻繁に切り替える必要があるため、パフォーマンスがある程度低下します。
割り込みの分類
##1. 外部割り込み#デバイスの入出力処理が完了し、プロセッサが次の入出力要求を送信できることを示す I/O 完了割り込みなど、CPU が命令を実行する以外のイベントによって発生します。その他、クロック割り込み、コンソール割り込みなどがあります。
 #2. 例外
#2. 例外
は、CPU が不正なオペコード、アドレス出力などの命令を実行するときの内部イベントによって発生します。範囲、算術オーバーフローなど。
3. トラップされた
ユーザー プログラムでシステム コールを使用します。
2. プロセス管理
プロセスとスレッド
1. プロセス
プロセスはリソース割り当ての基本単位です。
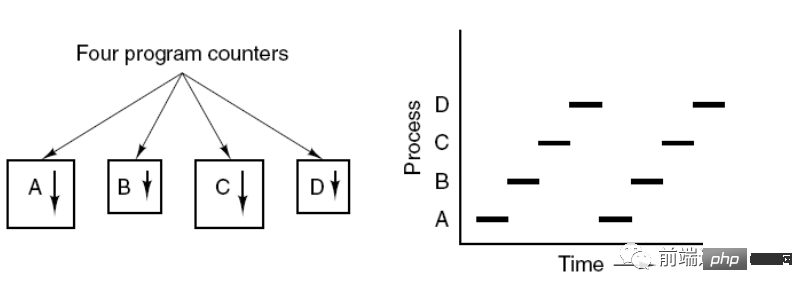
プロセス制御ブロック (PCB) は、プロセスの基本情報と実行ステータスを記述します。いわゆるプロセスの作成とキャンセルは、PCB 上の操作を指します。
次の図は、4 つのプログラムが 4 つのプロセスを作成し、これらの 4 つのプロセスを同時に実行できることを示しています。
#2. スレッド
スレッドは、独立したスケジューリングの基本単位です。 プロセス内に複数のスレッドが存在することがあり、それらはプロセス リソースを共有します。 QQ とブラウザは 2 つのプロセスです。ブラウザ プロセスには、HTTP リクエスト スレッド、イベント応答スレッド、レンダリング スレッドなど、多くのスレッドがあります。スレッドの同時実行により、ブラウザ したがって、HTTP リクエストが開始されると、ブラウザはユーザーからの他のイベントにも応答できます。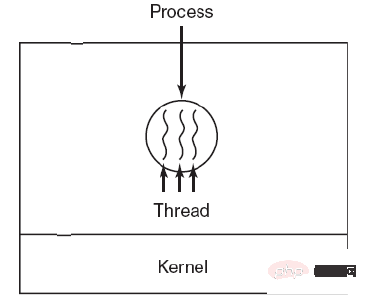
Ⅰ リソースの所有
プロセスにはリソースが割り当てられます基本単位ですが、スレッドはリソースを所有せず、プロセスに属するリソースにアクセスできます。
Ⅱ スケジューリング
スレッドは独立スケジューリングの基本単位です。同じプロセス内では、スレッドの切り替えはプロセス切り替えを引き起こしません。あるプロセスのスレッドから別のプロセスのスレッドに切り替えても、プロセスの切り替えが発生します。
Ⅲ システムオーバーヘッド
プロセスを作成またはキャンセルするとき、システムはメモリ空間や I/O デバイスなどのリソースをそのプロセスに割り当てるか再利用する必要があるため、支払われるオーバーヘッドはスレッドの作成またはキャンセル時のオーバーヘッドよりもはるかに大きくなります。プロセスを切り替える場合も同様に、現在実行中のプロセスのCPU環境を保存し、新たにスケジュールするプロセスのCPU環境を設定する必要がありますが、スレッドを切り替える場合は、少数のレジスタ内容を保存して設定するだけで済みます。オーバーヘッドは非常に小さいです。
Ⅳ 通信
スレッドは、同じプロセス内でデータを直接読み書きすることで通信できますが、プロセス通信には IPC の助けが必要です。
プロセス状態の切り替え
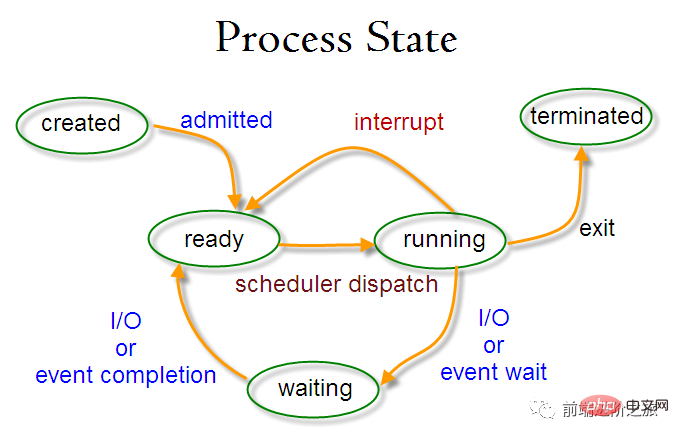
##準備完了状態 (ready):スケジュール待ち
実行状態 (running)
ブロッキング状態 (待機中) : リソースを待機中
準備完了状態と実行状態のみ相互に変換できますが、その他はすべて一方向の変換です。準備完了状態のプロセスは、スケジューリング アルゴリズムを通じて CPU 時間を取得し、実行状態に変化します。一方、実行状態のプロセスは、割り当てられた CPU タイム スライスが使い果たされると準備完了状態に変化し、次のスケジューリングを待ちます。 。
ブロッキング状態は必要なリソースが不足しており、実行状態から変換されます。ただし、このリソースには CPU 時間は含まれません。CPU 時間の不足実行状態から準備完了状態に変換されます。
プロセス スケジューリング アルゴリズム
環境ごとにスケジューリング アルゴリズムの目標は異なるため、環境ごとにスケジューリング アルゴリズムについて議論する必要があります。
1. バッチ処理システム
バッチ処理システムでは、ユーザー操作があまり多くありません。このシステムでは、スケジューリング アルゴリズムの目標は、スループットとターンアラウンド タイムを確保することです。 (提出から終了までの時間)。
1.1 先着順サーバー (FCFS)
ノンプリエンプティブなスケジューリング アルゴリズム。リクエストの順序でスケジューリングします。
これは、長いジョブには適していますが、短いジョブには適していません。短いジョブは、実行する前に前の長いジョブが完了するまで待つ必要があり、長いジョブは長時間実行する必要があるからです。その結果、短いジョブでも長い待ち時間が発生します。
1.2 最短ジョブ優先 (SJF)
推定実行時間が短い順にスケジュールを設定する非プリエンプティブ スケジューリング アルゴリズム。
長いジョブは餓死する可能性があり、短いジョブが完了するのを待っている状態になります。なぜなら、常に短いジョブが来る場合、長いジョブは決してスケジュールされないからです。
1.3 次の最短残り時間 (SRTN)
最初に最短のジョブのプリエンプティブ バージョンで、残りの実行時間の順にスケジュールされます。新しいジョブが到着すると、その実行時間全体が現在のプロセスの残り時間と比較されます。新しいプロセスに必要な時間が短い場合は、現在のプロセスが一時停止され、新しいプロセスが実行されます。それ以外の場合、新しいプロセスは待機します。
2. インタラクティブ システム
インタラクティブ システムでは多数のユーザー インタラクションが行われ、このシステムのスケジューリング アルゴリズムの目標は、迅速に応答することです。
2.1 タイムスライスの回転
FCFS 原則に従って、すべての準備完了プロセスをキューに配置し、スケジュールされるたびに、タイム スライスを実行できるキュー リーダー プロセスに CPU 時間を割り当てます。タイム スライスが使い果たされると、タイマーによってクロック割り込みが発行され、スケジューラはプロセスの実行を停止してレディ キューの最後に送り、その一方で、先頭のプロセスに CPU 時間を割り当て続けます。待ち行列。
タイム スライス ローテーション アルゴリズムの効率は、タイム スライスのサイズと大きな関係があります。
プロセスの切り替えには、プロセス情報の保存とロードが必要なためです。 new プロセス情報の場合、タイムスライスが小さすぎると、プロセスの切り替えが頻繁に発生し、プロセスの切り替えに時間がかかりすぎます。
#タイム スライスが長すぎる場合、リアルタイムのパフォーマンスは保証できません。
2.2 優先度のスケジューリング
#各プロセスに優先度を割り当てるそして優先順位に従ってスケジュールを立てます。
優先度の低いプロセスがスケジューリングをまったく待機しないようにするために、待機しているプロセスの優先度を時間の経過とともに高めることができます。
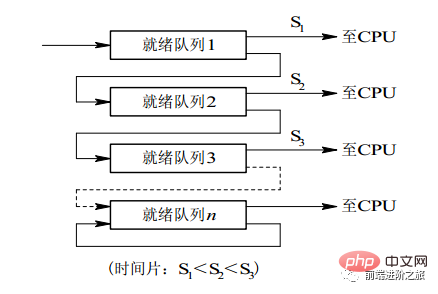
2.3 マルチレベル フィードバック キュー
プロセスは 100 個のタイム スライスを実行する必要があります。タイム スライス ローテーション スケジューリング アルゴリズムを使用する場合、100 回の交換が必要です。
マルチレベル キューは、複数のタイム スライスを連続的に実行する必要があるプロセス用に考慮されます。複数のキューが設定され、各キューには 1、2、4、8 などの異なるタイム スライス サイズが設定されます。 ..プロセスが最初のキューで実行を終了しない場合、プロセスは次のキューに移動します。このようにすると、前のプロセスを 7 回スワップするだけで済みます。
各キューには異なる優先度があり、一番上のキューの優先度が最も高くなります。したがって、現在のキューのプロセスは、前のキューにプロセスが存在しない場合にのみスケジュールできます。
このスケジューリング アルゴリズムは、タイム スライス ローテーション スケジューリング アルゴリズムと優先度スケジューリング アルゴリズムを組み合わせたものとみなすことができます。
#3. リアルタイム システム
リアルタイム システムでは、リクエストに応答する必要があります。一定の時間内に。牛逼啊!接私活必备的 N 个开源项目!赶快收藏吧...ハード リアルタイムとソフト リアルタイムに分かれており、前者は絶対期限を守る必要があり、後者は一定のタイムアウトを許容できます。
プロセス同期
1. クリティカル セクション
クリティカル リソースにアクセスするコードは、クリティカル セクションと呼ばれます。 クリティカルなリソースへのアクセスを相互に排除するには、クリティカルセクションに入る前に各プロセスをチェックする必要があります。// entry section // critical section; // exit section
2. 同期と相互排他
#同期: 複数のプロセスには連携による直接的な制約があるため、プロセスhave 一定の逐次実行関係が存在します。
#相互排他: 複数のプロセスのうち 1 つのプロセスのみが同時にクリティカル セクションに入ることができます。
3. セマフォ
信号量(Semaphore)是一个整型变量,可以对其执行 down 和 up 操作,也就是常见的 P 和 V 操作。
down : 如果信号量大于 0 ,执行 -1 操作;如果信号量等于 0,进程睡眠,等待信号量大于 0;
up :对信号量执行 +1 操作,唤醒睡眠的进程让其完成 down 操作。
down 和 up 操作需要被设计成原语,不可分割,通常的做法是在执行这些操作的时候屏蔽中断。
如果信号量的取值只能为 0 或者 1,那么就成为了 互斥量(Mutex) ,0 表示临界区已经加锁,1 表示临界区解锁。
typedef int semaphore;
semaphore mutex = 1;
void P1() {
down(&mutex);
// 临界区
up(&mutex);
}
void P2() {
down(&mutex);
// 临界区
up(&mutex);
}使用信号量实现生产者-消费者问题
问题描述:使用一个缓冲区来保存物品,只有缓冲区没有满,生产者才可以放入物品;只有缓冲区不为空,消费者才可以拿走物品。
因为缓冲区属于临界资源,因此需要使用一个互斥量 mutex 来控制对缓冲区的互斥访问。
为了同步生产者和消费者的行为,需要记录缓冲区中物品的数量。数量可以使用信号量来进行统计,这里需要使用两个信号量:empty 记录空缓冲区的数量,full 记录满缓冲区的数量。其中,empty 信号量是在生产者进程中使用,当 empty 不为 0 时,生产者才可以放入物品;full 信号量是在消费者进程中使用,当 full 信号量不为 0 时,消费者才可以取走物品。
注意,不能先对缓冲区进行加锁,再测试信号量。也就是说,不能先执行 down(mutex) 再执行 down(empty)。如果这么做了,那么可能会出现这种情况:生产者对缓冲区加锁后,执行 down(empty) 操作,发现 empty = 0,此时生产者睡眠。消费者不能进入临界区,因为生产者对缓冲区加锁了,消费者就无法执行 up(empty) 操作,empty 永远都为 0,导致生产者永远等待下,不会释放锁,消费者因此也会永远等待下去。
#define N 100
typedef int semaphore;
semaphore mutex = 1;
semaphore empty = N;
semaphore full = 0;
void producer() {
while(TRUE) {
int item = produce_item();
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
void consumer() {
while(TRUE) {
down(&full);
down(&mutex);
int item = remove_item();
consume_item(item);
up(&mutex);
up(&empty);
}
}4. 管程
使用信号量机制实现的生产者消费者问题需要客户端代码做很多控制,而管程把控制的代码独立出来,不仅不容易出错,也使得客户端代码调用更容易。
c 语言不支持管程,下面的示例代码使用了类 Pascal 语言来描述管程。示例代码的管程提供了 insert() 和 remove() 方法,客户端代码通过调用这两个方法来解决生产者-消费者问题。
monitor ProducerConsumer
integer i;
condition c;
procedure insert();
begin
// ...
end;
procedure remove();
begin
// ...
end;
end monitor;管程有一个重要特性:在一个时刻只能有一个进程使用管程。进程在无法继续执行的时候不能一直占用管程,否则其它进程永远不能使用管程。
管程引入了 条件变量 以及相关的操作:wait() 和 signal() 来实现同步操作。对条件变量执行 wait() 操作会导致调用进程阻塞,把管程让出来给另一个进程持有。signal() 操作用于唤醒被阻塞的进程。
使用管程实现生产者-消费者问题
// 管程
monitor ProducerConsumer
condition full, empty;
integer count := 0;
condition c;
procedure insert(item: integer);
begin
if count = N then wait(full);
insert_item(item);
count := count + 1;
if count = 1 then signal(empty);
end;
function remove: integer;
begin
if count = 0 then wait(empty);
remove = remove_item;
count := count - 1;
if count = N -1 then signal(full);
end;
end monitor;
// 生产者客户端
procedure producer
begin
while true do
begin
item = produce_item;
ProducerConsumer.insert(item);
end
end;
// 消费者客户端
procedure consumer
begin
while true do
begin
item = ProducerConsumer.remove;
consume_item(item);
end
end;经典同步问题
生产者和消费者问题前面已经讨论过了。
1. 哲学家进餐问题
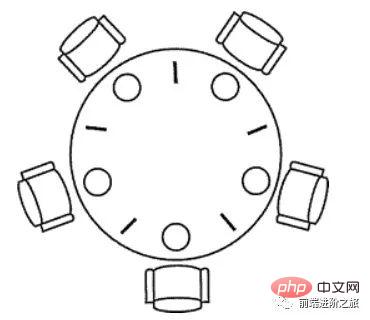
五个哲学家围着一张圆桌,每个哲学家面前放着食物。哲学家的生活有两种交替活动:吃饭以及思考。当一个哲学家吃饭时,需要先拿起自己左右两边的两根筷子,并且一次只能拿起一根筷子。
下面是一种错误的解法,如果所有哲学家同时拿起左手边的筷子,那么所有哲学家都在等待其它哲学家吃完并释放自己手中的筷子,导致死锁。
#define N 5
void philosopher(int i) {
while(TRUE) {
think();
take(i); // 拿起左边的筷子
take((i+1)%N); // 拿起右边的筷子
eat();
put(i);
put((i+1)%N);
}
}为了防止死锁的发生,可以设置两个条件:
必须同时拿起左右两根筷子;
只有在两个邻居都没有进餐的情况下才允许进餐。
#define N 5
#define LEFT (i + N - 1) % N // 左邻居
#define RIGHT (i + 1) % N // 右邻居
#define THINKING 0
#define HUNGRY 1
#define EATING 2
typedef int semaphore;
int state[N]; // 跟踪每个哲学家的状态
semaphore mutex = 1; // 临界区的互斥,临界区是 state 数组,对其修改需要互斥
semaphore s[N]; // 每个哲学家一个信号量
void philosopher(int i) {
while(TRUE) {
think(i);
take_two(i);
eat(i);
put_two(i);
}
}
void take_two(int i) {
down(&mutex);
state[i] = HUNGRY;
check(i);
up(&mutex);
down(&s[i]); // 只有收到通知之后才可以开始吃,否则会一直等下去
}
void put_two(i) {
down(&mutex);
state[i] = THINKING;
check(LEFT); // 尝试通知左右邻居,自己吃完了,你们可以开始吃了
check(RIGHT);
up(&mutex);
}
void eat(int i) {
down(&mutex);
state[i] = EATING;
up(&mutex);
}
// 检查两个邻居是否都没有用餐,如果是的话,就 up(&s[i]),使得 down(&s[i]) 能够得到通知并继续执行
void check(i) {
if(state[i] == HUNGRY && state[LEFT] != EATING && state[RIGHT] !=EATING) {
state[i] = EATING;
up(&s[i]);
}
}2. 读者-写者问题
允许多个进程同时对数据进行读操作,但是不允许读和写以及写和写操作同时发生。另外,搜索公众号顶级算法后台回复“算法”,获取一份惊喜礼包。
一个整型变量 count 记录在对数据进行读操作的进程数量,一个互斥量 count_mutex 用于对 count 加锁,一个互斥量 data_mutex 用于对读写的数据加锁。
typedef int semaphore;
semaphore count_mutex = 1;
semaphore data_mutex = 1;
int count = 0;
void reader() {
while(TRUE) {
down(&count_mutex);
count++;
if(count == 1) down(&data_mutex); // 第一个读者需要对数据进行加锁,防止写进程访问
up(&count_mutex);
read();
down(&count_mutex);
count--;
if(count == 0) up(&data_mutex);
up(&count_mutex);
}
}
void writer() {
while(TRUE) {
down(&data_mutex);
write();
up(&data_mutex);
}
}以下内容由 @Bandi Yugandhar 提供。
The first case may result Writer to starve. This case favous Writers i.e no writer, once added to the queue, shall be kept waiting longer than absolutely necessary(only when there are readers that entered the queue before the writer).
int readcount, writecount; //(initial value = 0)
semaphore rmutex, wmutex, readLock, resource; //(initial value = 1)
//READER
void reader() {
<ENTRY Section>
down(&readLock); // reader is trying to enter
down(&rmutex); // lock to increase readcount
readcount++;
if (readcount == 1)
down(&resource); //if you are the first reader then lock the resource
up(&rmutex); //release for other readers
up(&readLock); //Done with trying to access the resource
<CRITICAL Section>
//reading is performed
<EXIT Section>
down(&rmutex); //reserve exit section - avoids race condition with readers
readcount--; //indicate you're leaving
if (readcount == 0) //checks if you are last reader leaving
up(&resource); //if last, you must release the locked resource
up(&rmutex); //release exit section for other readers
}
//WRITER
void writer() {
<ENTRY Section>
down(&wmutex); //reserve entry section for writers - avoids race conditions
writecount++; //report yourself as a writer entering
if (writecount == 1) //checks if you're first writer
down(&readLock); //if you're first, then you must lock the readers out. Prevent them from trying to enter CS
up(&wmutex); //release entry section
<CRITICAL Section>
down(&resource); //reserve the resource for yourself - prevents other writers from simultaneously editing the shared resource
//writing is performed
up(&resource); //release file
<EXIT Section>
down(&wmutex); //reserve exit section
writecount--; //indicate you're leaving
if (writecount == 0) //checks if you're the last writer
up(&readLock); //if you're last writer, you must unlock the readers. Allows them to try enter CS for reading
up(&wmutex); //release exit section
}We can observe that every reader is forced to acquire ReadLock. On the otherhand, writers doesn’t need to lock individually. Once the first writer locks the ReadLock, it will be released only when there is no writer left in the queue.
From the both cases we observed that either reader or writer has to starve. Below solutionadds the constraint that no thread shall be allowed to starve; that is, the operation of obtaining a lock on the shared data will always terminate in a bounded amount of time.
int readCount; // init to 0; number of readers currently accessing resource
// all semaphores initialised to 1
Semaphore resourceAccess; // controls access (read/write) to the resource
Semaphore readCountAccess; // for syncing changes to shared variable readCount
Semaphore serviceQueue; // FAIRNESS: preserves ordering of requests (signaling must be FIFO)
void writer()
{
down(&serviceQueue); // wait in line to be servicexs
// <ENTER>
down(&resourceAccess); // request exclusive access to resource
// </ENTER>
up(&serviceQueue); // let next in line be serviced
// <WRITE>
writeResource(); // writing is performed
// </WRITE>
// <EXIT>
up(&resourceAccess); // release resource access for next reader/writer
// </EXIT>
}
void reader()
{
down(&serviceQueue); // wait in line to be serviced
down(&readCountAccess); // request exclusive access to readCount
// <ENTER>
if (readCount == 0) // if there are no readers already reading:
down(&resourceAccess); // request resource access for readers (writers blocked)
readCount++; // update count of active readers
// </ENTER>
up(&serviceQueue); // let next in line be serviced
up(&readCountAccess); // release access to readCount
// <READ>
readResource(); // reading is performed
// </READ>
down(&readCountAccess); // request exclusive access to readCount
// <EXIT>
readCount--; // update count of active readers
if (readCount == 0) // if there are no readers left:
up(&resourceAccess); // release resource access for all
// </EXIT>
up(&readCountAccess); // release access to readCount
}进程通信
进程同步与进程通信很容易混淆,它们的区别在于:
进程同步:控制多个进程按一定顺序执行;
进程通信:进程间传输信息。
进程通信是一种手段,而进程同步是一种目的。也可以说,为了能够达到进程同步的目的,需要让进程进行通信,传输一些进程同步所需要的信息。
1. 管道
管道是通过调用 pipe 函数创建的,fd[0] 用于读,fd[1] 用于写。
#include <unistd.h> int pipe(int fd[2]);
它具有以下限制:
只支持半双工通信(单向交替传输);
只能在父子进程或者兄弟进程中使用。
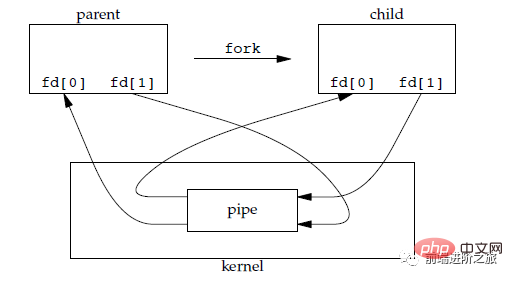
2. FIFO
也称为命名管道,去除了管道只能在父子进程中使用的限制。
#include <sys/stat.h> int mkfifo(const char *path, mode_t mode); int mkfifoat(int fd, const char *path, mode_t mode);
FIFO 常用于客户-服务器应用程序中,FIFO 用作汇聚点,在客户进程和服务器进程之间传递数据。
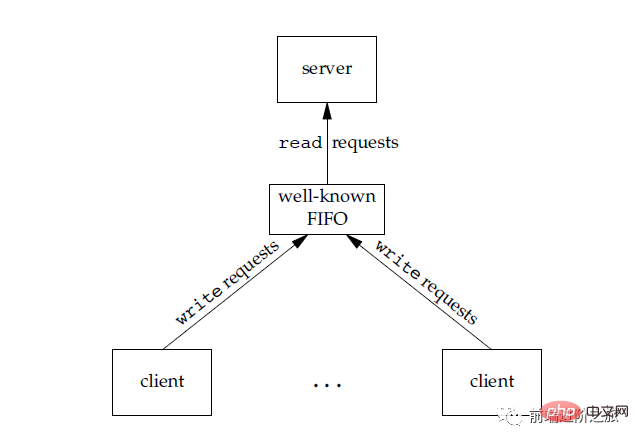
#3. メッセージ キュー
FIFO と比較して、メッセージ キューには次の利点があります:-
メッセージ キューは読み取りおよび書き込みプロセスとは独立して存在できるため、FIFO 内の同期パイプを開いたり閉じたりするときに発生する可能性のある問題を回避できます。
FIFO の同期ブロック問題を回避し、プロセスが独自の同期メソッドを提供する必要がなく、 #読み取りプロセスデフォルトでのみ受信できる FIFO とは異なり、メッセージ タイプに応じてメッセージを選択的に受信できます。
4. セマフォ
5. 共有ストレージ
複数のプロセスが特定のストレージ領域を共有できるようにします。プロセス間でデータをコピーする必要がないため、これは最も高速なタイプの IPC です。共有ストレージへのアクセスを同期するには、セマフォを使用する必要があります。
複数のプロセスは、同じファイルをアドレス空間にマップして共有メモリを実現できます。さらに、XSI 共有メモリはファイルを使用せず、メモリの匿名セグメントを使用します。6. ソケット
他の通信メカニズムとは異なり、異なるマシン間のプロセス通信に使用できます。
3. メモリ管理
仮想メモリ
仮想メモリの目的は、物理メモリをより大きなメモリに拡張することです。論理メモリを増やし、プログラムがより多くの利用可能なメモリを取得できるようにします。
メモリをより適切に管理するために、オペレーティング システムはメモリをアドレス空間に抽象化します。各プログラムには独自のアドレス空間があり、複数のブロックに分割されており、各ブロックはページと呼ばれます。ページは物理メモリにマップされますが、連続した物理メモリにマップする必要はなく、すべてのページが物理メモリ内にある必要もありません。プログラムが物理メモリにないページを参照すると、ハードウェアは必要なマッピングを実行し、不足している部分を物理メモリにロードし、失敗した命令を再実行します。
上記の説明からわかるように、仮想メモリを使用すると、プログラムはアドレス空間内のすべてのページを物理メモリにマップしなくても済みます。つまり、プログラムを実行するためにメモリにロードする必要はありません。これにより、限られたメモリで大規模なプログラムを実行できるようになります。たとえば、コンピュータが 16 ビット アドレスを生成できる場合、プログラムのアドレス空間範囲は 0 ~ 64K になります。このコンピュータの物理メモリは 32KB しかありませんが、仮想メモリ テクノロジにより、コンピュータは 64K のプログラムを実行できます。
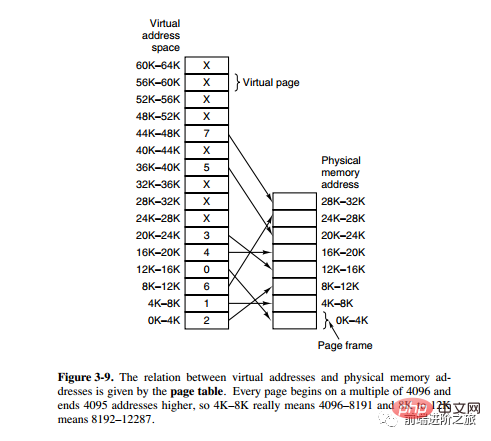
#ページング システム アドレス マッピング
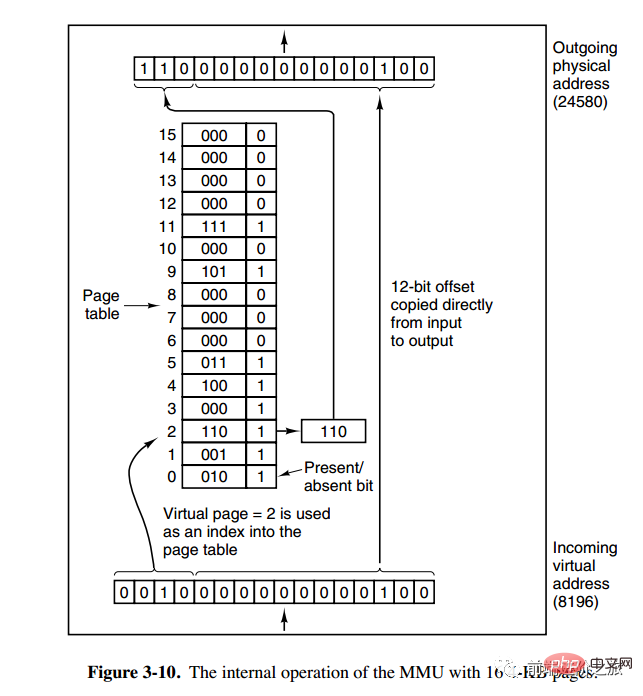
メモリ管理ユニット (MMU) は、アドレス空間と物理アドレスを管理します。メモリ変換では、ページ テーブル (ページ テーブル) にページ (プログラム アドレス空間) とページ フレーム (物理メモリ空間) 間のマッピング テーブルが格納されます。 仮想アドレスは 2 つの部分に分割され、1 つの部分にはページ番号が格納され、もう 1 つの部分にはオフセットが格納されます。下图的页表存放着 16 个页,这 16 个页需要用 4 个比特位来进行索引定位。例如对于虚拟地址(0010 000000000100),前 4 位是存储页面号 2,读取表项内容为(110 1),页表项最后一位表示是否存在于内存中,1 表示存在。后 12 位存储偏移量。这个页对应的页框的地址为 (110 000000000100)。
页面置换算法
在程序运行过程中,如果要访问的页面不在内存中,就发生缺页中断从而将该页调入内存中。此时如果内存已无空闲空间,系统必须从内存中调出一个页面到磁盘对换区中来腾出空间。
页面置换算法和缓存淘汰策略类似,可以将内存看成磁盘的缓存。在缓存系统中,缓存的大小有限,当有新的缓存到达时,需要淘汰一部分已经存在的缓存,这样才有空间存放新的缓存数据。
页面置换算法的主要目标是使页面置换频率最低(也可以说缺页率最低)。
1. 最佳
OPT, Optimal replacement algorithm
所选择的被换出的页面将是最长时间内不再被访问,通常可以保证获得最低的缺页率。
是一种理论上的算法,因为无法知道一个页面多长时间不再被访问。
举例:一个系统为某进程分配了三个物理块,并有如下页面引用序列:
7,0,1,2,0,3,0,4,2,3,0,3,2,1,2,0,1,7,0,1
开始运行时,先将 7, 0, 1 三个页面装入内存。当进程要访问页面 2 时,产生缺页中断,会将页面 7 换出,因为页面 7 再次被访问的时间最长。
2. 最近最久未使用
LRU, Least Recently Used
虽然无法知道将来要使用的页面情况,但是可以知道过去使用页面的情况。LRU 将最近最久未使用的页面换出。
为了实现 LRU,需要在内存中维护一个所有页面的链表。当一个页面被访问时,将这个页面移到链表表头。这样就能保证链表表尾的页面是最近最久未访问的。
因为每次访问都需要更新链表,因此这种方式实现的 LRU 代价很高。
4,7,0,7,1,0,1,2,1,2,6
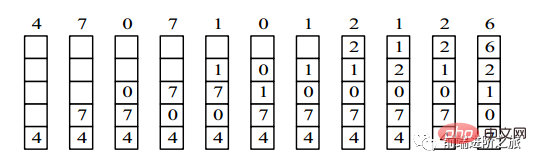
3. 最近未使用
NRU, Not Recently Used
每个页面都有两个状态位:R 与 M,当页面被访问时设置页面的 R=1,当页面被修改时设置 M=1。其中 R 位会定时被清零。可以将页面分成以下四类:
R=0,M=0 R=0,M=1 R=1,M=0 R=1,M=1
当发生缺页中断时,NRU 算法随机地从类编号最小的非空类中挑选一个页面将它换出。
NRU 优先换出已经被修改的脏页面(R=0,M=1),而不是被频繁使用的干净页面(R=1,M=0)。
4. 先入れ先出し
FIFO、先入れ先出し
スワップアウトするために選択されたページは、入力されたページです初め。
このアルゴリズムは、頻繁にアクセスされるページを交換するため、ページ フォールト率が増加します。
5. セカンド チャンス アルゴリズム
FIFO アルゴリズムは、頻繁に使用されるページを置き換える可能性があります。この問題を回避するには、アルゴリズムに簡単な変更を加えます。
##ページがアクセスされるとき (読み取りまたは書き込み)、ページの R ビットを 1 に設定します。置換が必要な場合は、最も古いページの R ビットを確認してください。 R ビットが 0 の場合、そのページは古くて未使用であり、すぐに置き換えることができます。1 の場合、R ビットを 0 にクリアし、ページをリンク リストの最後に置き、次のようにロード時間を変更します。ロードされたばかりであるかのように動作し、リストの先頭から検索を続けます。
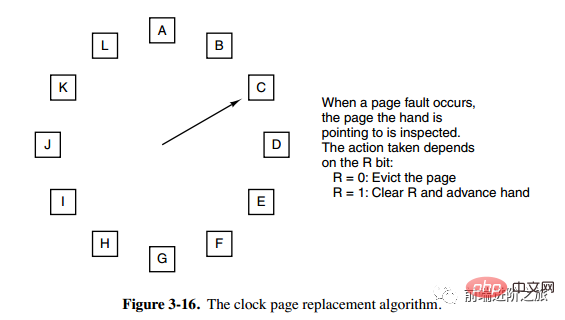
6. 時計
時計セカンド チャンス アルゴリズムでは、リンク リスト内のページを移動する必要があるため、効率が低下します。クロック アルゴリズムは、循環リンク リストを使用してページを接続し、ポインターを使用して最も古いページを指します。
セグメンテーション
仮想メモリはページング テクノロジを使用します。これは、アドレス空間が固定サイズのページに分割され、各ページがメモリにマップされることを意味します。
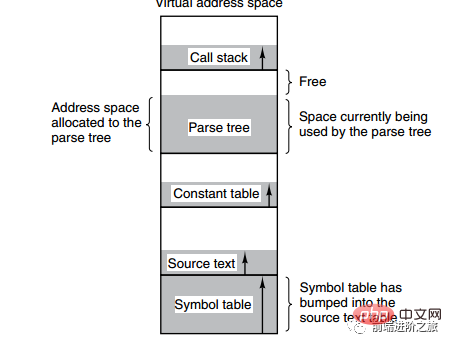
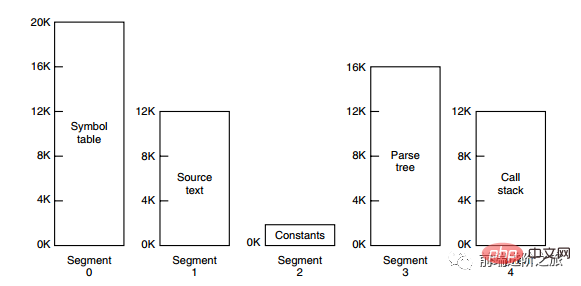
下の図は、コンパイル プロセス中にコンパイラによって作成された複数のテーブルを示しています。4 つのテーブルが動的に拡張されます。ページング システムの 1 次元アドレス空間が使用されている場合、動的拡張特性によりカバレッジの問題が発生します。現れる。
セグメント ページング
プログラムのアドレス空間は、独立したアドレス空間を持つ複数のセグメントに分割されます。 、各セグメントのアドレス空間は同じサイズのページに分割されます。これには、セグメント化されたシステムの共有と保護だけでなく、ページング システムの仮想メモリ機能もあります。ページングとセグメンテーションの比較
プログラマーに対する透過性: ページングは透過的ですが、セグメンテーションではプログラマーが各セグメントを分割することを表示する必要があります。
アドレス空間の次元: ページングは 1 次元のアドレス空間であり、セグメンテーションは 2 次元です。
#サイズを変更できるかどうか: ページのサイズは不変ですが、セグメントのサイズは動的に変更できます。
出現理由: ページングは主に仮想メモリを実装してより大きなアドレス空間を取得するために使用され、セグメンテーションは主にプログラムとデータを分割できるようにするために使用されます。論理的に独立したアドレス空間を実現し、共有と保護を容易にします。
#4. デバイス管理
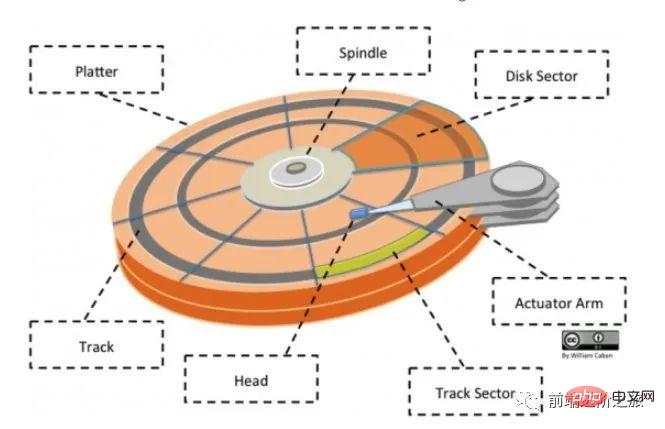
ディスク構造
## ディスク (プラッター): ディスクには複数のディスクがあります;
トラック (トラック): ディスク上の円形のストリップ領域、1 つのディスクがあります複数のトラックであること;
セクター (トラック セクター): トラック上の円弧セグメント、トラックは複数のセクターを持つことができ、最小の物理ストレージ ユニットです現在主に 2 つのサイズがあります: 512 バイトと 4 K;
ヘッド: ディスク表面に非常に近く、ディスク上にデータを保存できます 磁場は電気信号に変換される(読み取り)、または電気信号がディスク上の磁場に変換される(書き込み); さらに、公式アカウント Linux を検索して、バックグラウンドで「Linux」と返信する方法を学ぶ必要があります。サプライズギフトパッケージを手に入れましょう。
アクチュエータ アーム: トラック間で磁気ヘッドを移動するために使用されます;
スピンドル: ディスク全体を回転させます。
#ディスク スケジューリング アルゴリズム
ディスクの読み取りと書き込みブロック時間に影響を与える要因は次のとおりです。- #回転時間 (磁気ヘッドが適切なセクタに移動するように、スピンドルがディスク表面を回転させます)
- シーク時間 (ブレーキ アームが移動してヘッドを適切なトラックに移動する)
-
このうちシーク時間は最も長いため、ディスク スケジューリングの主な目標は、ディスクの平均シーク時間を最小限に抑えることです。
1. 先着順
FCFS、先着順
利点は公平性と単純さです。欠点も明らかです。シークの最適化が行われていないため、平均シーク時間が長くなる可能性があります。スケジューリングはディスクの順序で実行されます。リクエスト。
2. 最短シーク時間から順
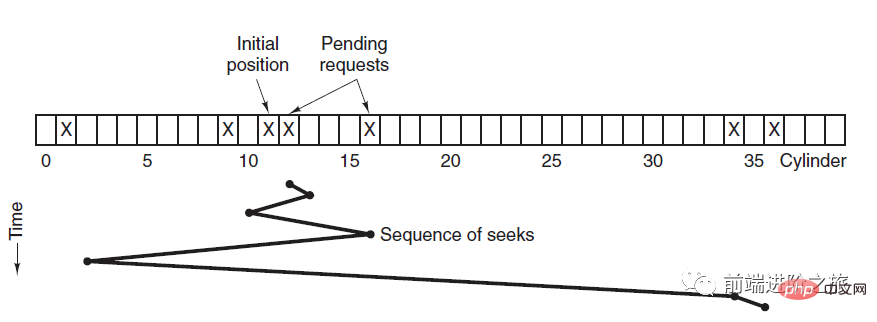
SSTF、最短シーク時間から順
現在のトラックに最も近いものを優先的にスケジュールします。ヘッドはトラックにあります。
平均シーク時間は比較的短いですが、十分に公平ではありません。新たに到着したトラック要求が待機中のトラック要求よりも常に近い場合、待機中のトラック要求は永久に待機することになり、スタベーションが発生します。具体的には、両端の追跡リクエストは飢餓状態になりやすくなります。 このリモート コントロール システムを見てください。とてもエレガントです (ソース コードが添付されています)。
3. エレベーター アルゴリズム
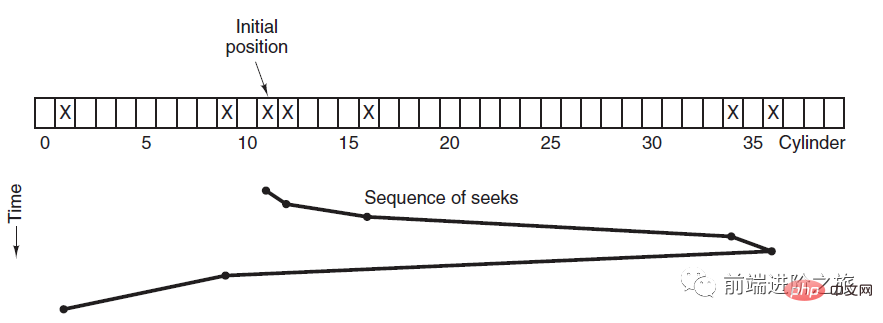
SCAN
エレベーターは常に一方向への要求がなくなるまで一方向に実行し続け、その後、実行方向を変更します。
エレベーター アルゴリズム (スキャン アルゴリズム) は、エレベーターの実行プロセスに似ており、常に一方向に未処理のディスク要求がなくなるまでディスクをスケジュールし、その後方向を変更します。
移動方向が考慮されるため、すべてのディスク要求が満たされ、SSTF の枯渇問題が解決されます。
五、链接
编译系统
以下是一个 hello.c 程序:
#include <stdio.h>
int main()
{
printf("hello, world\n");
return 0;
}在 Unix 系统上,由编译器把源文件转换为目标文件。
gcc -o hello hello.c
这个过程大致如下:

预处理阶段:处理以 # 开头的预处理命令;
编译阶段:翻译成汇编文件;
汇编阶段:将汇编文件翻译成可重定位目标文件;
链接阶段:将可重定位目标文件和 printf.o 等单独预编译好的目标文件进行合并,得到最终的可执行目标文件。
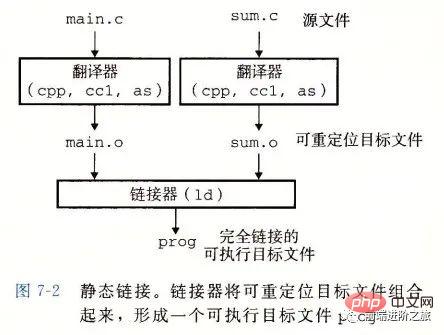
静态链接
静态链接器以一组可重定位目标文件为输入,生成一个完全链接的可执行目标文件作为输出。链接器主要完成以下两个任务:
シンボル解決: 各シンボルは、関数、グローバル変数、または静的変数に対応します。シンボル解決の目的は、各シンボル参照をシンボル定義に関連付けることです。
再配置: リンカは各シンボル定義をメモリの場所に関連付けてから、これらのシンボルへのすべての参照を変更して、シンボルがこのメモリの場所を指すようにします。
#対象ファイル
-
実行可能オブジェクト ファイル: メモリ内で直接実行可能;
再配置可能オブジェクト ファイル: リンク フェーズで他の再配置可能オブジェクト ファイルとリンク可能実行可能ターゲット ファイルを作成します;
共有ターゲット ファイル: これは、実行時に動的にロードできる特別な再配置可能なターゲット ファイルです。メモリとリンクを入力してください。
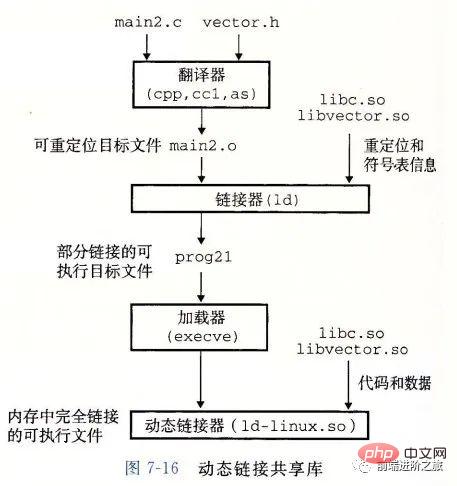
ダイナミック リンク
静的ライブラリには次の 2 つの問題があります。静的ライブラリが更新されると、プログラム全体を再リンクする必要があります;
printf のような標準関数ライブラリの場合、すべてのプログラムにコードが必要な場合、リソースの膨大な無駄になります。
共有ライブラリは、静的ライブラリのこれら 2 つの問題を解決するように設計されており、通常、Linux システムでは .so 接尾辞で表され、Windows システムでは DLL と呼ばれます。
#ライブラリには、指定されたファイル システム内にファイルが 1 つだけあります。ライブラリを参照するすべての実行可能オブジェクト ファイルは、このファイルを共有します。それを参照する実行可能ファイルにコピーされます;
#メモリ内では、共有ライブラリの .text セクション (コンパイルされたプログラムのマシン コード) をコピーできます。実行中のさまざまなプロセスによって共有されます。
6. デッドロック
必要な条件# ##################################
相互排他的: 各リソースはすでにプロセスに割り当てられているか、使用可能です。
#所有と待機: すでにリソースを取得しているプロセスは、新しいリソースを要求できます。
#非プリエンプティブル: プロセスに割り当てられたリソースを強制的にプリエンプトすることはできません。リソースを占有しているプロセスによってのみ明示的に解放できます。
ループ待機中: 2 つ以上のプロセスがループを形成しており、ループ内の各プロセスが次のプロセスを待機しています。リソースが占有されています。
#処理方法
主に以下の 4 つの方法があります。
ostrichstrategy
デッドロックの検出とデッドロックの回復
デッドロックの防止
デッドロック回避#
#ダチョウ戦略##ヘディング 頭を埋めろ砂を捨てて、まったく問題がないふりをします。
デッドロック問題を解決するコストは非常に高いため、タスク対策を講じないダチョウ戦略の方が高いパフォーマンスが得られます。
デッドロックが発生した場合、ユーザーに大きな影響を与えないか、デッドロックの可能性が非常に低い場合は、ダチョウ戦略を使用できます。
Unix、Linux、Windows を含むほとんどのオペレーティング システムは、デッドロックの問題を無視するだけで対処します。
デッドロックの検出とデッドロックの回復
デッドロックを防ぐのではなく、デッドロックが検出された場合に回復するための措置を講じます。
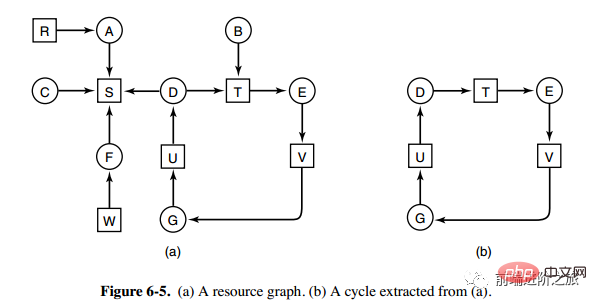
1. タイプごとに 1 つのリソースのデッドロック検出

上の図はリソース割り当て図です。ここで、ボックスはリソースを表し、円はプロセスを表します。リソースがプロセスを指しているということは、そのプロセスにリソースが割り当てられていることを意味し、プロセスがリソースを指しているということは、プロセスがリソースの取得を要求していることを意味する。
図aから図bのようにループを抽出できますが、ループ待ち条件を満たすためデッドロックが発生します。
各タイプのリソースのデッドロック検出アルゴリズムは、有向グラフにサイクルがあるかどうかを検出することによって実装されます。ノードから開始して、深さ優先検索が実行され、訪問したノードがマークされます。訪問したノードがマークされているノードは、有向グラフに循環があること、つまりデッドロックの発生が検出されることを意味します。
2. 各タイプの複数のリソースのデッドロック検出
上図では 3 つのプロセスと 4 つのリソースがあり、各データの意味は次のとおりです:
E ベクトル: 総リソース
##A ベクトル: リソースの残量
C 行列: 所有するリソースの数各行はプロセスが所有するリソースの数を表します
#R マトリクス: 各プロセスが要求したリソースの数
プロセス P1 と P2 が要求したリソースを満たすことができません。プロセス P3 のみが P3 を実行させ、P3 が所有するリソースを解放できます。このとき、A = (2 2 2 0) 。 P2 は実行可能であり、P2 が所有するリソースは実行後に解放されます (A = (4 2 2 1))。 P1も実行可能です。すべてのプロセスはデッドロックなくスムーズに実行されます。 アルゴリズムは次のように要約されます。 各プロセスは最初にマークされず、実行プロセスにマークが付けられる場合があります。アルゴリズムが終了すると、マークされていないプロセスはデッドロック プロセスになります。 要求されたリソースが A 以下であるマークのないプロセス Pi を探します。 そのようなプロセスが見つかった場合は、C 行列の i 行目のベクトルを A に追加し、そのプロセスをマークして、1 に戻します。 そのようなプロセスが存在しない場合、アルゴリズムは終了します。
3. デッドロック回復
プリエンプション回復の使用
-
ロールバックリカバリの使用
プロセスの強制終了による回復
デッドロックの防止
プログラムの実行中にrunning デッドロックの発生を事前に防ぎます。
1. 相互排他条件の破壊
たとえば、スプール プリンタ テクノロジでは、複数のプロセスが同時に出力できますが、実際に物理プリンタを要求する唯一のプロセスです。プリンターデーモンです。
2. 所有および待機条件の破棄
これを達成する 1 つの方法は、実行を開始する前に、すべてのプロセスが必要なすべてのリソースを要求するように指定することです。
3. 非プリエンプション条件を破棄します
4. ループ待機を破棄します
リソースに統一された番号を与えます。また、プロセスは番号順にリソースを要求することしかできません。
デッドロックの回避#
##プログラムの実行中のデッドロックを回避します。
1. セキュリティステータス
図 a の 2 列目の Has はすでに所有されているリソースの数を表し、3 列目の Max は必要なリソースの総数を表し、Free は使用できるリソースの数を表します。図 a から始めて、まず B に必要なすべてのリソースを持たせ (図 b)、操作が完了したら B を解放し、Free が 5 になり (図 c)、次に C と A を同じように実行して、すべてのプロセスがどちらも正常に実行できるため、図aの状態は安全であると言えます。
定義: デッドロックが発生せず、すべてのプロセスが突然リソースの最大需要を要求した場合でも、各プロセスを完了まで実行できる特定のスケジューリング順序が存在する場合、その状態は安全であると言われます。 。
安全な状態の検出はデッドロックの検出と似ています。安全な状態ではデッドロックが発生しないことが必要であるためです。次のバンカーのアルゴリズムはデッドロック検出アルゴリズムに非常に似ており、参照および比較のために組み合わせることができます。
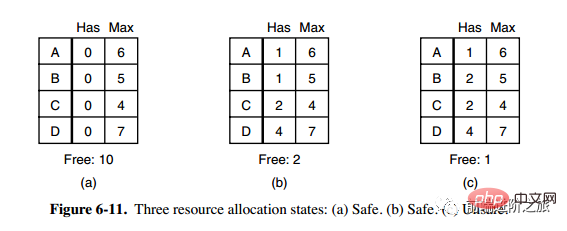
2. 単一リソースの銀行家アルゴリズム
小さな町の銀行家は、顧客グループに一定の金額を約束しました。アルゴリズムが行うことは次のとおりです。リクエストを満たすと安全でない状態になるかどうか、そうであればリクエストを拒否し、そうでない場合はリクエストを割り当てます。
上の図 c は安全でない状態であるため、アルゴリズムは図 c の状態に入ることを避けるために前のリクエストを拒否します。
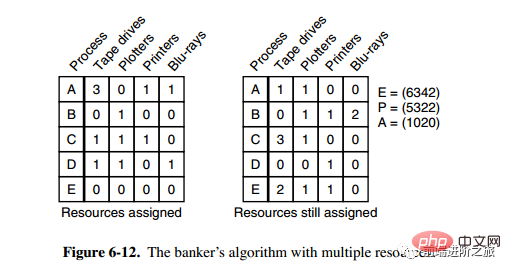
3. 複数のリソースに対するバンカー アルゴリズム
上の図には 5 つのプロセスがあります。リソース。左側の図は割り当てられているリソースを表し、右側の図はまだ割り当てる必要があるリソースを表しています。右端の E、P、A はそれぞれ、総リソース、割り当てられたリソース、および利用可能なリソースを表します。これら 3 つはベクトルであり、特定の値ではないことに注意してください。たとえば、A=(1020) は、それぞれ 1/4 のリソースが残っていることを意味します。 0/2/0。
状態が安全かどうかを確認するアルゴリズムは次のとおりです。
右側の行列に次の値より小さい行があるかどうかを見つけます。またはベクトル A と等しい。そのような行が存在しない場合、システムはデッドロックとなり、安全ではない状態になります。
そのような行が見つかった場合は、プロセスを終了済みとしてマークし、割り当てられたリソースを A に追加します。
すべてのプロセスに終了のマークが付けられるまで、上記の 2 つの手順を繰り返します。終了すると、状態は安全になります。
ある状態が安全でない場合は、この状態への移行を拒否する必要があります。
相互排他的: 各リソースはすでにプロセスに割り当てられているか、使用可能です。
#所有と待機: すでにリソースを取得しているプロセスは、新しいリソースを要求できます。
#非プリエンプティブル: プロセスに割り当てられたリソースを強制的にプリエンプトすることはできません。リソースを占有しているプロセスによってのみ明示的に解放できます。
ループ待機中: 2 つ以上のプロセスがループを形成しており、ループ内の各プロセスが次のプロセスを待機しています。リソースが占有されています。
#処理方法
主に以下の 4 つの方法があります。ostrichstrategy
デッドロックの検出とデッドロックの回復
デッドロックの防止
デッドロック回避#
##ヘディング 頭を埋めろ砂を捨てて、まったく問題がないふりをします。
デッドロック問題を解決するコストは非常に高いため、タスク対策を講じないダチョウ戦略の方が高いパフォーマンスが得られます。
デッドロックが発生した場合、ユーザーに大きな影響を与えないか、デッドロックの可能性が非常に低い場合は、ダチョウ戦略を使用できます。
Unix、Linux、Windows を含むほとんどのオペレーティング システムは、デッドロックの問題を無視するだけで対処します。
デッドロックの検出とデッドロックの回復
デッドロックを防ぐのではなく、デッドロックが検出された場合に回復するための措置を講じます。
1. タイプごとに 1 つのリソースのデッドロック検出
上の図はリソース割り当て図です。ここで、ボックスはリソースを表し、円はプロセスを表します。リソースがプロセスを指しているということは、そのプロセスにリソースが割り当てられていることを意味し、プロセスがリソースを指しているということは、プロセスがリソースの取得を要求していることを意味する。
図aから図bのようにループを抽出できますが、ループ待ち条件を満たすためデッドロックが発生します。
各タイプのリソースのデッドロック検出アルゴリズムは、有向グラフにサイクルがあるかどうかを検出することによって実装されます。ノードから開始して、深さ優先検索が実行され、訪問したノードがマークされます。訪問したノードがマークされているノードは、有向グラフに循環があること、つまりデッドロックの発生が検出されることを意味します。
2. 各タイプの複数のリソースのデッドロック検出

上図では 3 つのプロセスと 4 つのリソースがあり、各データの意味は次のとおりです:
E ベクトル: 総リソース
##A ベクトル: リソースの残量
C 行列: 所有するリソースの数各行はプロセスが所有するリソースの数を表します
#R マトリクス: 各プロセスが要求したリソースの数
3. デッドロック回復
プリエンプション回復の使用
-
ロールバックリカバリの使用
プロセスの強制終了による回復
デッドロックの防止
プログラムの実行中にrunning デッドロックの発生を事前に防ぎます。
1. 相互排他条件の破壊
たとえば、スプール プリンタ テクノロジでは、複数のプロセスが同時に出力できますが、実際に物理プリンタを要求する唯一のプロセスです。プリンターデーモンです。
2. 所有および待機条件の破棄
これを達成する 1 つの方法は、実行を開始する前に、すべてのプロセスが必要なすべてのリソースを要求するように指定することです。
3. 非プリエンプション条件を破棄します
4. ループ待機を破棄します
リソースに統一された番号を与えます。また、プロセスは番号順にリソースを要求することしかできません。
デッドロックの回避#
##プログラムの実行中のデッドロックを回避します。1. セキュリティステータス
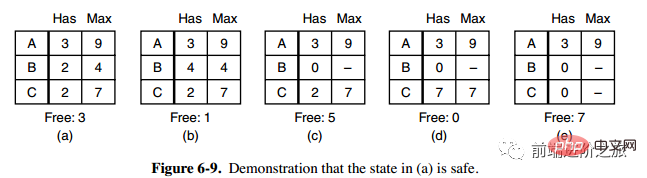
図 a の 2 列目の Has はすでに所有されているリソースの数を表し、3 列目の Max は必要なリソースの総数を表し、Free は使用できるリソースの数を表します。図 a から始めて、まず B に必要なすべてのリソースを持たせ (図 b)、操作が完了したら B を解放し、Free が 5 になり (図 c)、次に C と A を同じように実行して、すべてのプロセスがどちらも正常に実行できるため、図aの状態は安全であると言えます。
定義: デッドロックが発生せず、すべてのプロセスが突然リソースの最大需要を要求した場合でも、各プロセスを完了まで実行できる特定のスケジューリング順序が存在する場合、その状態は安全であると言われます。 。
安全な状態の検出はデッドロックの検出と似ています。安全な状態ではデッドロックが発生しないことが必要であるためです。次のバンカーのアルゴリズムはデッドロック検出アルゴリズムに非常に似ており、参照および比較のために組み合わせることができます。
2. 単一リソースの銀行家アルゴリズム
小さな町の銀行家は、顧客グループに一定の金額を約束しました。アルゴリズムが行うことは次のとおりです。リクエストを満たすと安全でない状態になるかどうか、そうであればリクエストを拒否し、そうでない場合はリクエストを割り当てます。
上の図 c は安全でない状態であるため、アルゴリズムは図 c の状態に入ることを避けるために前のリクエストを拒否します。
3. 複数のリソースに対するバンカー アルゴリズム
上の図には 5 つのプロセスがあります。リソース。左側の図は割り当てられているリソースを表し、右側の図はまだ割り当てる必要があるリソースを表しています。右端の E、P、A はそれぞれ、総リソース、割り当てられたリソース、および利用可能なリソースを表します。これら 3 つはベクトルであり、特定の値ではないことに注意してください。たとえば、A=(1020) は、それぞれ 1/4 のリソースが残っていることを意味します。 0/2/0。
状態が安全かどうかを確認するアルゴリズムは次のとおりです。
右側の行列に次の値より小さい行があるかどうかを見つけます。またはベクトル A と等しい。そのような行が存在しない場合、システムはデッドロックとなり、安全ではない状態になります。
そのような行が見つかった場合は、プロセスを終了済みとしてマークし、割り当てられたリソースを A に追加します。
すべてのプロセスに終了のマークが付けられるまで、上記の 2 つの手順を繰り返します。終了すると、状態は安全になります。
ある状態が安全でない場合は、この状態への移行を拒否する必要があります。
以上がオペレーティング システムの概要を詳しく示す 30 枚の画像!の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。