
ホームページ >Java >&#&チュートリアル >これは、これまで読んだマイクロサービス アーキテクチャに関する最も詳細な記事かもしれません。
これは、これまで読んだマイクロサービス アーキテクチャに関する最も詳細な記事かもしれません。
- Java学习指南転載
- 2023-07-26 15:42:28898ブラウズ
この記事では、マイクロサービス アーキテクチャと関連コンポーネントについて説明し、それらが何であるか、またマイクロサービス アーキテクチャとこれらのコンポーネントを使用する理由を紹介します。この記事では、マイクロサービス アーキテクチャの全体像を簡潔に表現することに重点を置いているため、コンポーネントの使用方法などの詳細には触れません。
マイクロサービスを理解するには、まずマイクロサービスではないものを理解する必要があります。通常、マイクロサービスの反対はモノリシック アプリケーションです。これは、すべての機能を独立したユニットにパッケージ化したアプリケーションです。モノリシック アプリケーションからマイクロサービスへの移行は一夜にして起こるものではなく、段階的な進化のプロセスです。この記事では、オンライン スーパーマーケットのアプリケーションを例に、このプロセスを説明します。
初期需要
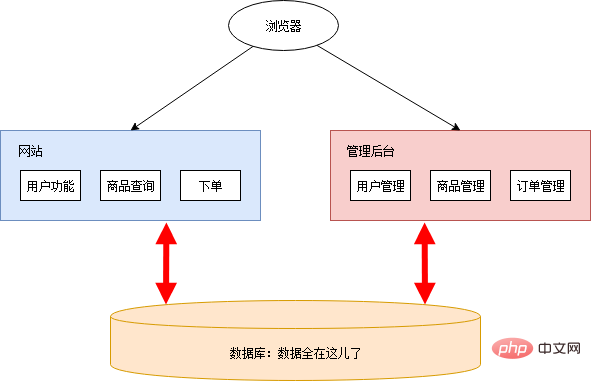
数年前、Xiao Ming と Xiao Pi は一緒にオンライン スーパーマーケットを始めました。 Xiao Ming はプログラム開発を担当し、Xiao Pi はその他の事項を担当します。当時はまだインターネットが発達しておらず、ネットスーパーもまだブルーオーシャンでした。機能が実装されていれば、自由にお金を稼ぐことができます。したがって、彼らのニーズは非常に単純です。必要なのは、ユーザーが製品を閲覧して購入できるパブリック ネットワーク上の Web サイトだけです。また、製品、ユーザー、注文データを管理できる管理バックエンドも必要です。
機能リストを整理しましょう:
Website - ##ユーザー登録とログイン機能
- 商品展示
- ご注文
- #製品管理
##注文管理 -
# 要件が簡単だったので、Xiao Ming が左手と右手をスローモーションで動かすと、Web サイトの準備が整いました。セキュリティ上の理由から、管理バックエンドは Web サイトと同じ場所には配置されていません。Xiao Ming の右手と左手がスローモーションで再生され、管理 Web サイトの準備が整います。全体的なアーキテクチャ図は次のとおりです。 
Xiao Ming は手を振り、導入するクラウド サービスを見つけました。Web サイトはオンラインでした。オンラインで発売後、大好評を博し、あらゆるファットハウスから愛されました。シャオミンとシャオピーは喜んで横になってお金を集め始めました。ビジネスの発展に伴い...
良い時代は長くは続かず、数日のうちにさまざまなオンラインスーパーマーケットが出現し、シャオ社に多大な損害を与えました。ミンとシャオピ、強烈なインパクト。
競争のプレッシャーを受けて、Xiao Ming Xiaopi はいくつかのマーケティング方法を実行することにしました:
プロモーション活動を実施します。たとえば、サイト全体での元旦の割引、春節に 2 つ買うと 1 つ無料、バレンタインデーのドッグフード クーポンなどです。 チャネルを拡大し、モバイル マーケティングを追加します。 Web サイトに加えて、モバイル APP、WeChat アプレットなども開発する必要があります。 精密マーケティング。履歴データを使用してユーザーを分析し、パーソナライズされたサービスを提供します。 ....
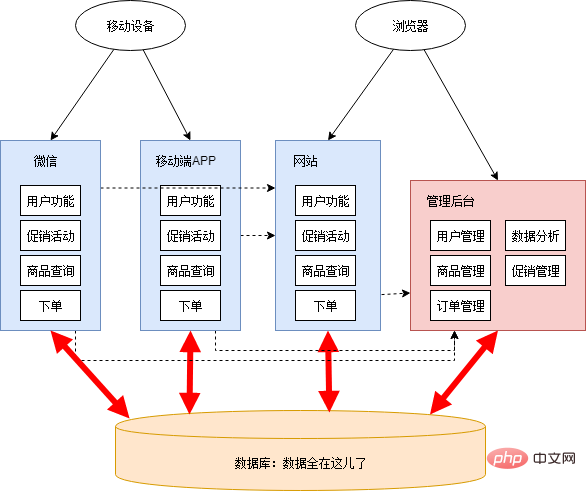
これらのアクティビティには、プログラム開発のサポートが必要です。シャオミンはクラスメートのシャオホンをチームに引き入れた。 Xiaohongはデータ分析とモバイル端末関連の開発を担当しています。 Xiao Mingは、プロモーション活動に関連する機能の開発を担当しています。
開発課題が比較的緊急だったため、シャオミンとシャオホンはシステム全体のアーキテクチャを計画せず、頭を撫でるだけで、プロモーション管理とデータ分析を管理の背景に置くことにしました。 WeChat とモバイル APP は別々に構築されました。数日間徹夜で作業すると、新機能や新アプリケーションはほぼ完成する。この時点でのアーキテクチャ図は次のとおりです。
この段階では無理な部分が多々あります。Web サイトとモバイル アプリケーションには、同じビジネス ロジックを持つ重複コードが多数あります。 データはデータベースを通じて共有されることもあれば、インターフェイス呼び出しを通じて送信されることもあります。インターフェイスの呼び出し関係が厄介です。 他のアプリケーションにインターフェイスを提供するために、1 つのアプリケーションは徐々に変更され、最初からそのアプリケーションに属さないロジックも多数含まれます。アプリケーションの境界があいまいになり、関数の帰属がわかりにくくなります。 管理バックエンドは、当初、低レベルのセキュリティで設計されました。データ分析やプロモーション管理に関連する機能を追加した後、パフォーマンスのボトルネックが発生し、他のアプリケーションに影響を及ぼしました。 - #データベース テーブル構造は複数のアプリケーションに依存しているため、再構築および最適化することはできません。
- すべてのアプリケーションはデータベース上で動作するため、データベース内でパフォーマンスのボトルネックが発生します。特にデータ分析の実行中は、データベースのパフォーマンスが急激に低下します。
- 開発、テスト、導入、メンテナンスはますます困難になってきています。たとえ小さな機能を変更するだけでも、アプリケーション全体をまとめてリリースする必要があります。場合によっては、テストされていないコードが誤って記者会見に含まれたり、関数を変更した後に別の予期しないエラーが発生したりすることがあります。リリースによって発生する可能性のある問題やオンライン業務停止の影響を軽減するために、すべてのアプリケーションは午前 3 時または 4 時にリリースする必要があります。リリース後、アプリケーションが正常に動作していることを確認するために、翌日の日中のユーザーのピーク時間帯に注目する必要があります...
- チーム内での責任転嫁現象。一部のパブリック関数をどのアプリケーションに基づいて構築するかについて長い議論が行われることはよくありますが、最終的には独自の機能を実行するか、メンテナンスせずにランダムな場所に配置するかのどちらかになります。
緊急で重いタスクは、人々が簡単に部分的かつ短期的な思考に陥り、妥協した決定を下してしまう可能性があります。この種の構造では、誰もが自分のエーカーの 3 分の 1 だけに集中し、全体的かつ長期的な設計が欠けています。このままでは制度構築はますます困難になり、打倒と再構築が繰り返されるサイクルに陥る可能性すらある。
今こそ変化を起こす時です幸いなことに、シャオミンとシャオホンは追求と理想を持った良い若者です。問題を認識した後、シャオミンとシャオホンは些細なビジネスニーズからエネルギーを解放し、全体の構造を整理し始め、問題を変革する準備をしました。
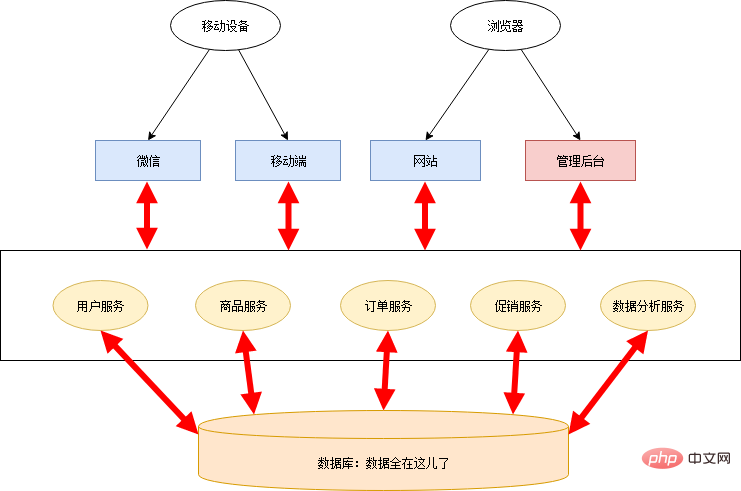
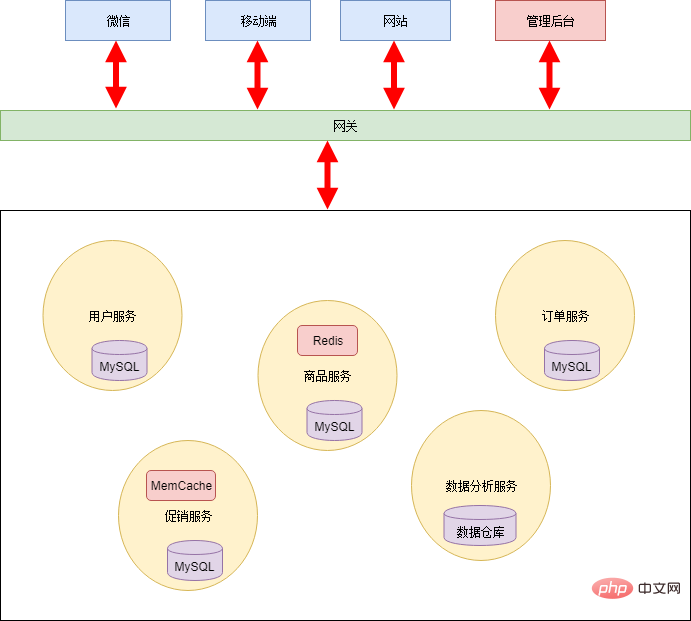
変革を行うには、まず十分なエネルギーとリソースが必要です。需要側 (ビジネス スタッフ、プロジェクト マネージャー、上司など) が需要の進捗を追求することに非常に強く、追加のエネルギーやリソースを割り当てることができない場合は、何もできない可能性があります...プログラミングの世界において最も重要なことは、抽象能力です。マイクロサービス変換のプロセスは、実際には抽象的なプロセスです。 Xiao Ming と Xiao Hon は、オンライン スーパーマーケットのビジネス ロジックを整理し、共通のビジネス機能を抽象化し、いくつかのパブリック サービスを作成しました。 ##コモディティ サービス
プロモーション サービス オーダー サービス -
データ分析サービス 各アプリケーション バックグラウンドは、これらのサービスから必要なデータを取得するだけでよいため、大量の冗長コードが削除され、薄い制御層とフロント エンドのみが残ります。このステージのアーキテクチャは次のとおりです。 - このステージはサービスを分離するだけであり、データベースは引き続き共有されるため、chimney システムのいくつかの欠点がまだ存在します。 :
データベースはパフォーマンスのボトルネックとなり、単一障害点のリスクがあります。
データ管理は混乱する傾向があります。最初は優れたモジュール設計があったとしても、時間が経つと、あるサービスが別のサービスのデータをデータベースから直接取得するという現象が常に発生します。データベースのテーブル構造は複数のサービスに依存している可能性があり、全体に影響を及ぼし、調整が困難になります。 共有データベース モデルを常に維持すると、アーキテクチャ全体がますます硬直化し、マイクロサービス アーキテクチャの意味が失われます。そのため、Xiao Ming と Xiao Hon は協力してデータベースを分割しました。すべての永続層は互いに分離されており、各サービスが責任を負います。さらに、システムのリアルタイム パフォーマンスを向上させるために、メッセージ キュー メカニズムが追加されています。アーキテクチャは次のとおりです。 - #完全に分割した後、各サービスは異種テクノロジを使用できます。たとえば、データ分析サービスはデータ ウェアハウスを永続層として使用して統計計算を効率的に実行できます。商品サービスやプロモーション サービスはより頻繁にアクセスされるため、キャッシュ メカニズムが追加されます。
データベースの分割には、データベース間のカスケードの必要性、サービスを介したデータ クエリの粒度など、いくつかの問題や課題もあります。しかし、これらの問題は合理的な設計によって解決できます。全体として、データベースの分割には短所よりも長所の方が多くあります。
マイクロサービス アーキテクチャには、技術以外の利点もあります。システム全体の分業と責任がより明確になり、誰もがより良いサービスを他の人に提供する責任を負います。モノリシック アプリケーションの時代では、パブリック ビジネス機能には明確な所有権がないことがよくあります。最終的には、全員が独自の作業を行ってそれを再度実装するか、ランダムな人 (通常はより有能または熱心な人) が担当するアプリケーションを実装するかのどちらかになります。後者の場合、この人は自分のアプリケーションに対する責任に加えて、これらの公開機能を他の人に提供する責任も負っています - そしてこの機能は元々誰に対しても責任を負うものではありません。 (この状況は、婉曲的に「有能な人は努力をする」とも呼ばれます)。結局、公的機能を提供しようとする人は誰もいませんでした。時間が経つにつれて、チーム内の人々は徐々に独立し、全体的なアーキテクチャ設計を気にしなくなりました。公式アカウント Java Journey をフォローすると電子書籍が受け取れます。
この観点から見ると、マイクロサービス アーキテクチャを使用するには、それに応じて組織構造を調整する必要もあります。したがって、マイクロサービスの変革にはマネージャーのサポートが必要です。
変身が完了した後、シャオミンとシャオホンはそれぞれの役割を明確に分けました。二人はとても満足し、すべてがマクスウェルの方程式のように美しく完璧でした。
しかし...
特効薬はありません
春が到来し、すべてが回復しつつあり、毎年恒例のショッピング カーニバルが再び始まります。毎日の注文数が着実に増加しているのを見て、シャオピー、シャオミン、シャオホンは幸せそうに微笑みました。残念なことに、楽しい時間は長くは続かず、極度の喜びが悲しみをもたらし、突然システムがクラッシュしました。
これまで、単一アプリケーションのトラブルシューティングには、ログを確認し、エラー メッセージとコール スタックを調査することが一般的でした。 マイクロサービス アーキテクチャでは、アプリケーション全体が複数のサービスに分散されるため、障害点を特定することが非常に困難になります。 Xiao Ming はログを 1 つずつ確認し、各サービスを手動で呼び出しました。 10 分以上の検索の後、Xiao Ming は最終的に障害点を特定しました。受信した大量のリクエストにより、プロモーション サービスが応答を停止したのです。他のサービスは直接的または間接的にプロモーション サービスを呼び出すため、それらもダウンします。 マイクロサービス アーキテクチャでは、サービス障害が雪崩現象を引き起こし、システム全体に障害が発生する可能性があります。実際、休暇前に、シャオミンとシャオホンはリクエスト量の評価を実施しました。推定によると、サーバー リソースは休暇中のリクエスト数をサポートするのに十分であるため、何か問題があるに違いありません。しかし、状況は緊急であり、一分一秒が無駄に費やされていたため、Xiao Ming には問題のトラブルシューティングを行う時間がなく、すぐにクラウド上にいくつかの新しい仮想マシンを作成することを決定し、新しいプロモーション プログラムを展開しました。サービスを 1 つずつノードに追加します。数分間の操作後、システムは最終的に正常に戻りました。失敗期間全体で数十万の売上が失われたと推定され、3 人の心は血を流していました...
その後、Xiao Ming は単純にログ分析ツールを作成し (量が多すぎてテキスト エディタで開くのがほとんど不可能で、肉眼では見えませんでした)、プロモーションのアクセス ログをカウントしました。コードの問題により、サービスは特定のシナリオでプロモーション サービスに対する大量のリクエストを開始することになります。この問題は複雑ではなく、Xiao Ming は数十万の価値があるこのバグを指のフリックで修正しました。
問題は解決されましたが、同様の問題が再び発生しないとは誰も保証できません。マイクロサービス アーキテクチャは論理設計としては完璧に見えますが、積み木で建てられた豪華な宮殿のようなもので、風や波には耐えられません。マイクロサービス アーキテクチャは古い問題を解決しますが、新しい問題も引き起こします。
マイクロサービス アーキテクチャのアプリケーション全体が複数のサービスに分散されているため、障害点を特定することが非常に困難になります。 - #安定性が低下しました。サービスの数が増えると、1 つのサービスで障害が発生する可能性が高まり、サービスの障害によりシステム全体がハングアップする可能性があります。実際、アクセス量が多い運用シナリオでは、必ず障害が発生します。
- サービスの数は非常に多く、導入と管理の作業負荷は膨大です。
- 開発側面: 継続的な開発にもかかわらず、さまざまなサービスが連携を維持できるようにする方法。
- テストの側面: サービスを分割すると、ほぼすべての機能に複数のサービスが関与するようになります。単一プログラムの元のテストは、サービス間の呼び出しのテストになります。テストはより複雑になります。
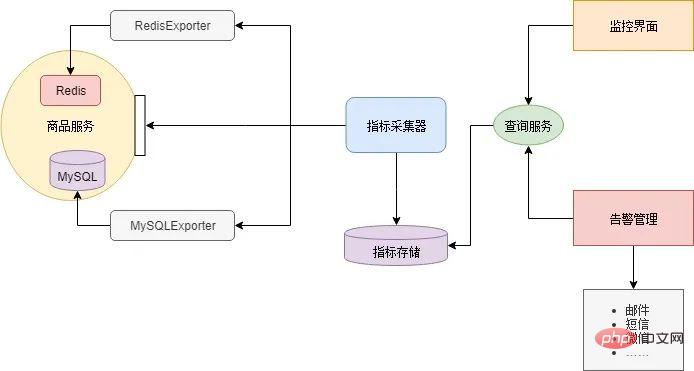
監視 - 障害の兆候の発見
高同時実行性の分散シナリオでは、障害が突然発生することがよくあります。雪崩。したがって、故障の兆候を可能な限り検出するために、万全の監視システムを確立する必要があります。 マイクロサービス アーキテクチャには多くのコンポーネントがあり、各コンポーネントはさまざまなインジケーターを監視する必要があります。たとえば、Redis キャッシュは通常、メモリ占有値とネットワーク トラフィックを監視し、データベースは接続数とディスク容量を監視し、ビジネス サービスは同時実行数、応答遅延、エラー率などを監視します。したがって、各コンポーネントを監視するために大規模で包括的な監視システムを構築することは非現実的であり、拡張性も非常に劣ります。一般的なアプローチは、各コンポーネントに現在のステータスを報告するためのインターフェイス (メトリクス インターフェイス) を提供させることであり、このインターフェイスによって出力されるデータ形式は一貫している必要があります。次に、インジケーター コレクター コンポーネントをデプロイして、クエリ サービスを提供しながら、これらのインターフェイスからコンポーネントのステータスを定期的に取得して維持します。最後に、インジケーター コレクターからさまざまなインジケーターをクエリしたり、監視インターフェイスを描画したり、しきい値に基づいてアラームを発行したりするには、UI が必要です。ほとんどのコンポーネントは自分で開発する必要はありません。インターネット上にはオープン ソース コンポーネントがあります。 Xiao Ming は、RedisExporter と MySQLExporter をダウンロードしました。これら 2 つのコンポーネントは、それぞれ Redis キャッシュと MySQL データベースのインジケーター インターフェイスを提供します。マイクロサービスは、各サービスのビジネス ロジックに基づいてカスタマイズされたインジケーター インターフェイスを実装します。次に、Xiao Ming は Prometheus をインジケーター コレクターとして使用し、Grafana が監視インターフェイスと電子メール アラートを構成します。このようなマイクロサービス監視システムは次のように構築されます。
位置付けの問題 - リンク追跡マイクロサービス内 サービスの下アーキテクチャでは、ユーザーのリクエストには複数の内部サービス呼び出しが含まれることがよくあります。問題の特定を容易にするためには、各ユーザーが要求したときにマイクロサービス内で生成されたサービス呼び出しの数と、それらの呼び出し関係を記録できる必要があります。これをリンクトラッキングと呼びます。
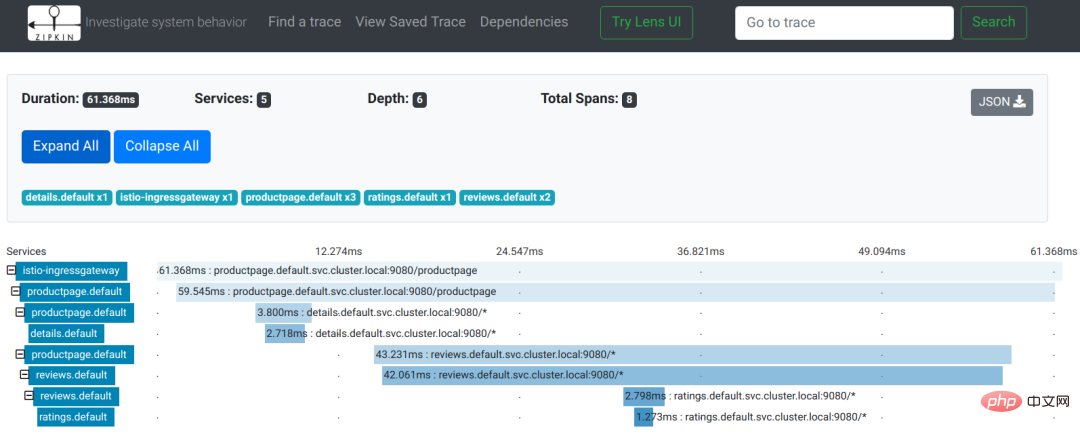
Istio ドキュメントでリンク追跡の例を使用して効果を確認してみましょう:
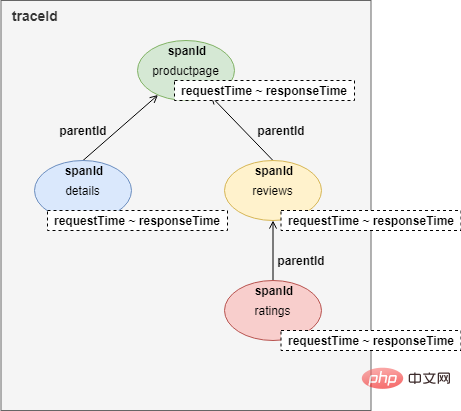
画像は Istio ドキュメントからのものです画像からわかるように、これは製品ページ ページにアクセスするためのユーザー リクエストです。リクエスト プロセス中に、productpage サービスは詳細およびレビュー サービスのインターフェイスを順番に呼び出します。レビュー サービスは、応答プロセス中に評価インターフェイスを呼び出します。リンク追跡全体のレコードはツリーです:
#リンク追跡を実装するには、各サービス呼び出しは HTTP HEADERS データに少なくとも 4 つのレコードを記録します。traceId:traceId は、ユーザーが要求した呼び出しリンクを識別します。同じトレース ID を持つ呼び出しは同じリンクに属します。 spanId: サービスコールを識別するID、つまりリンクトラッキングのノードIDです。 parentId: 親ノードのspanId。 requestTime と responseTime: リクエスト時間と応答時間。
さらに、ログの収集と保存のためのコンポーネントや、リンク呼び出しを表示するための UI コンポーネントも呼び出す必要があります。
上記は最小限の説明です。リンク追跡の理論的根拠の詳細については、Google の Dapper を参照してください。理論的根拠を理解した後、Xiao Ming Dapper のオープンソース実装である Zipkin を選択しました。次に、彼の指のフリックで、HTTP リクエスト インターセプターを作成し、これらのデータを生成して HTTP リクエストごとに HEADERS に挿入し、同時に通話ログを Zipkin のログ コレクターに非同期で送信しました。ここでさらに言及するのは、HTTP リクエスト インターセプターはマイクロサービスのコードに実装できること、またはネットワーク プロキシ コンポーネントを使用して実装できることです (ただし、この場合、各マイクロサービスはプロキシのレイヤーを追加する必要があります)。
リンク追跡は、どのサービスに問題があるかを特定することしかできず、特定のエラー情報を提供することはできません。特定のエラー情報を検索する機能は、ログ分析コンポーネントによって提供される必要があります。
分析の問題 - ログ分析
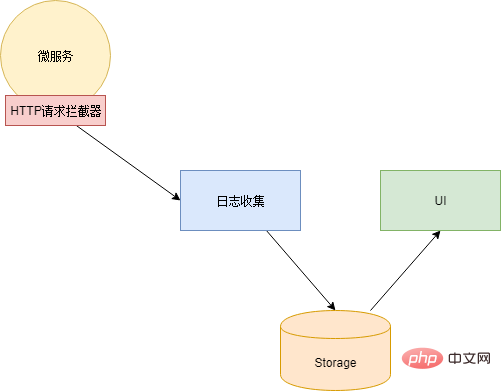
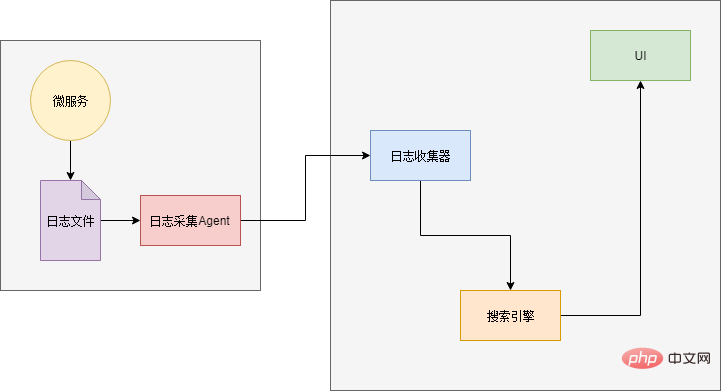
ログ分析コンポーネントは、マイクロサービスが台頭する前に広く使用されていたはずです。単一のアプリケーション アーキテクチャであっても、アクセス数が増加したり、サーバーの規模が増大したりすると、ログ ファイルのサイズはテキスト エディターでアクセスするのが困難なほど肥大化します。複数のサーバーに分散しています。問題のトラブルシューティングを行うには、各サーバーにログインしてログ ファイルを取得し、目的のログ情報を 1 つずつ検索する必要があります (開いたり検索したりするのに非常に時間がかかります)。
したがって、アプリケーションの規模が大きくなると、「検索エンジン」というログが必要になります。必要なログを正確に見つけることができます。さらに、データ ソース側には、ログを収集するためのコンポーネントと結果を表示するための UI コンポーネントも必要です。
Xiao Ming は、有名な ELK ログ分析コンポーネントを調査して使用しました。 ELK は、Elasticsearch、Logstash、Kibana の 3 つのコンポーネントの略称です。Elasticsearch: 検索エンジンとログ ストレージ。 Logstash: ログ入力を受け取るログ コレクターは、ログに対して前処理を実行し、それを Elasticsearch に出力します。 Kibana: UI コンポーネント。Elasticsearch API を通じてデータを検索し、ユーザーに表示します。
最後に、ログを Logstash に送信する方法という小さな問題があります。解決策の 1 つは、ログを出力するときに Logstash インターフェイスを直接呼び出してログを送信することです。この方法では、コードを再度変更する必要があります (おい、なぜ「and」を使用するのか)... そこで、Xiao Ming は別の解決策を選択しました。ログは引き続きファイルに出力され、ログをスキャンするために各サービスにエージェントがデプロイされます。ファイルを作成し、Logstash に出力します。
広告休憩:公開アカウントをフォローしてください:Java スタディ ガイド , さらに技術的な記事を入手してください。
ゲートウェイ - 権限制御、サービス ガバナンス
マイクロサービスに分割した後、多数のサービスとインターフェイスが登場し、呼び出し関係全体が煩雑になってしまいました。開発プロセス中に、書き続けていると、特定のデータに対してどのサービスを呼び出す必要があるのか、突然思い出せなくなることがよくあります。または、呼び出すべきではないサービスを呼び出すという不正な記述があり、読み取り専用関数によってデータが変更されてしまいました...
これらの状況に対処するために、マイクロサービスの呼び出しにはチェッカーが必要です、つまりゲートウェイです。呼び出し元と呼び出し先の間にゲートウェイ層を追加し、呼び出されるたびに権限検証を実行します。さらに、ゲートウェイはサービス インターフェイス ドキュメントを提供するプラットフォームとしても使用できます。
ゲートウェイの使用に関する 1 つの問題は、ゲートウェイをどの程度細分化して使用するかを決定することです。最も大まかなソリューションは、マイクロサービス全体のゲートウェイです。マイクロサービスの外部は、ゲートウェイを介してマイクロサービスにアクセスします。マイクロサービスの内部では直接呼び出しが行われます。粒度としては、マイクロサービスへの内部呼び出しであるか外部からの呼び出しであるかにかかわらず、すべての呼び出しがゲートウェイを経由する必要があります。折衷的な解決策は、マイクロサービスをビジネス領域に応じていくつかの領域に分割し、領域内で直接呼び出したり、ゲートウェイ経由で呼び出したりすることです。
オンライン スーパー全体のサービス数はそれほど多くないため、Xiao Ming は最も粗いソリューションを採用しました。
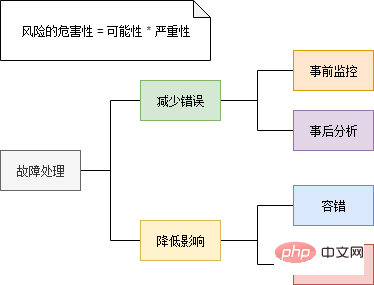
# #サービスの登録と検出 - 動的な拡張
これまでのコンポーネントはすべて、障害の可能性を減らすように設計されています。ただし、障害は必ず発生するため、障害の影響をいかに軽減するかという点も検討する必要があります。 最も粗雑な (そして最も一般的に使用される) 障害処理戦略は冗長性です。一般に、サービスは複数のインスタンスをデプロイすることで、負荷を分散してパフォーマンスを向上させることができます。次に、1 つのインスタンスに障害が発生した場合でも、他のインスタンスが引き続き応答できます。冗長性に関する問題の 1 つは、使用される冗長性の数です。タイムライン上では、この質問に対する明確な答えはありません。サービスの機能と期間に応じて、必要なインスタンスの数は異なります。たとえば、平日は 4 つのインスタンスで十分ですが、プロモーション期間中はトラフィックが大幅に増加するため、40 のインスタンスが必要になる場合があります。したがって、冗長性の量は固定値ではなく、必要に応じてリアルタイムに調整できます。 一般的に、新しいインスタンスを追加する操作は次のとおりです。
- 新しいインスタンスをデプロイする
- 新しいインスタンスを登録する負荷分散や DNS への
- 操作は 2 ステップだけですが、負荷分散や DNS への登録操作が手動の場合、作業は簡単ではありません。 40 個のインスタンスを追加した後、40 個の IP を手動で入力しなければならない気持ちを考えてみてください...
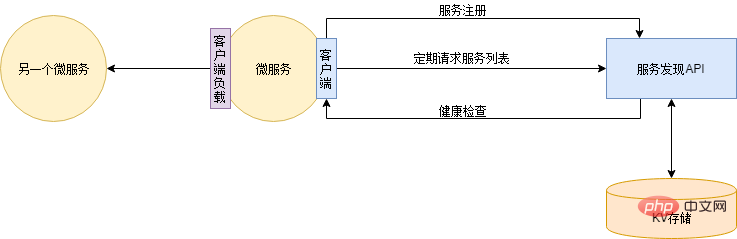
この問題の解決策は、サービスの自動登録と検出です。まず、登録されているすべてのサービスのアドレス情報を提供するサービス検出サービスを展開する必要があります。 DNS はサービス検出サービスとみなすこともできます。その後、各アプリケーション サービスは、開始時にサービス検出サービスに自動的に登録されます。そして、アプリケーションサービスの起動後、各アプリケーションサービスのアドレスリストがサービスディスカバリサービスからローカルにリアルタイム(定期的)に同期されます。サービス検出サービスは、アプリケーション サービスの健全性ステータスを定期的にチェックし、異常なインスタンス アドレスを削除します。このように、インスタンスを追加するときは、新しいインスタンスをデプロイするだけで済みます。インスタンスがオフラインになった場合は、サービスを直接シャットダウンできます。サービス ディスカバリは、サービス インスタンスの増加または減少を自動的にチェックします。
サービス検出には、Zookeeper、Eureka、Consul、Etcd など、多数のコンポーネントから選択できます。しかし、Xiao Ming は自分が得意だと感じており、自分のスキルを誇示したいと考えたので、Redis に基づいて Redis を作成しました...回線、サービスの低下、電流制限
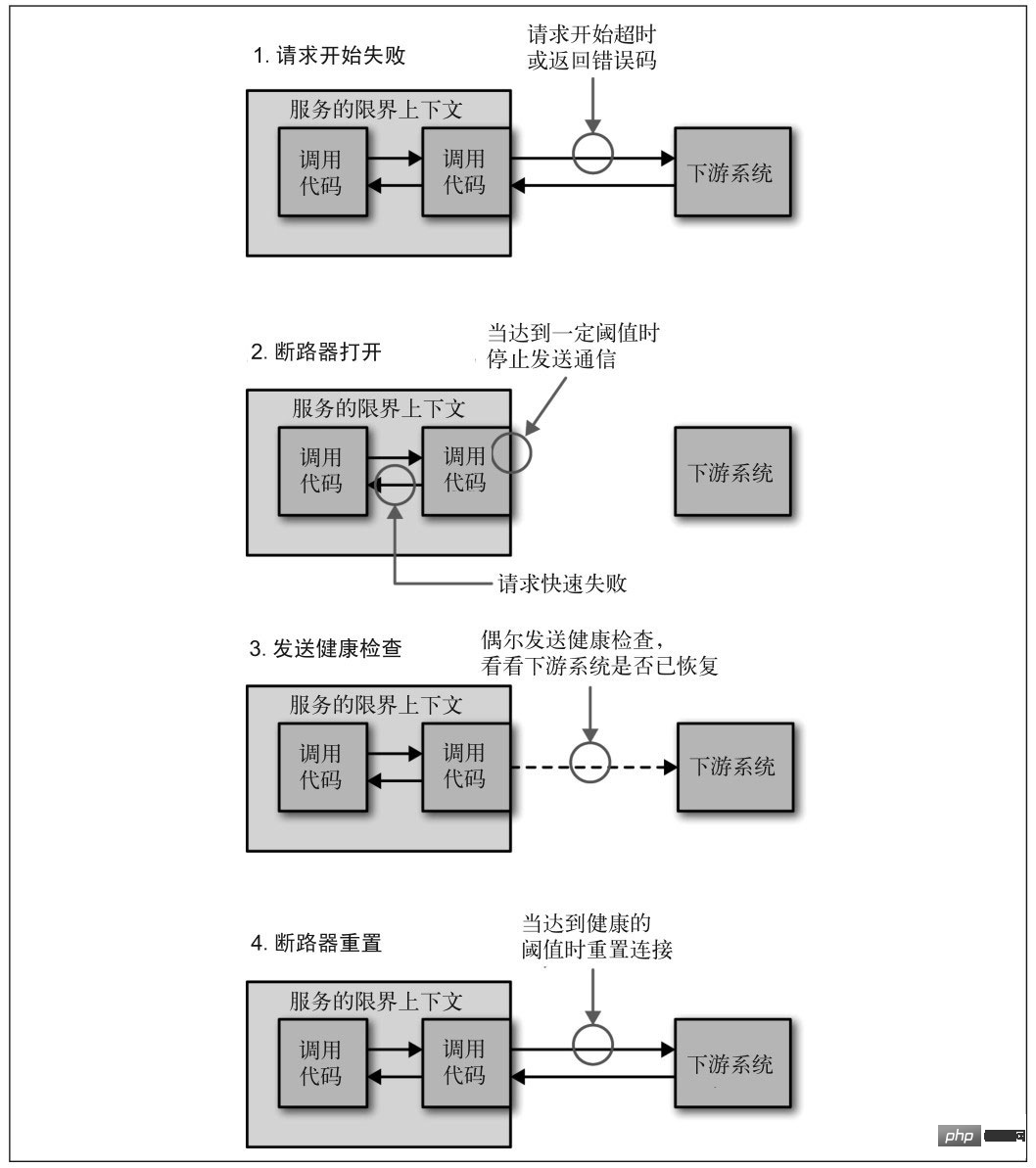
回線
サービスがさまざまな理由で応答を停止した場合、呼び出し元は通常、応答を待ちます。その間、タイムアウトになるか、エラーが返されます。呼び出し元のリンクが比較的長い場合、リクエストが蓄積する可能性があり、リンク全体が多くのリソースを占有し、ダウンストリームの応答を待機することになります。したがって、サービスへのアクセスが複数回失敗した場合は、サーキット ブレーカーが壊れ、サービスが動作を停止したものとしてマークされ、エラーが直接返される必要があります。サービスが通常に戻るまで待ってから、接続を再確立してください。
#サービスのダウングレード#「マイクロサービス設計」からの画像
ダウンストリーム サービスが動作を停止した場合、そのサービスがコア ビジネスではない場合は、コア ビジネスが中断されないようにアップストリーム サービスをダウングレードする必要があります。例えば、ネットスーパーの注文インターフェースには、レコメンド商品の注文を集める機能がありますが、レコメンドモジュールがダウンしているときは、同時に注文機能をダウンさせることはできず、レコメンド機能を一時的にオフにするだけで済みます。
電流制限サービスがハングアップした後、上流のサービスまたはユーザーは通常、定期的にアクセスを再試行します。これは、サービスが通常に戻っても、過剰なネットワーク トラフィックによりすぐにハングアップし、棺の中で腹筋運動を繰り返す可能性があることを意味します。したがって、サービスはそれ自体を保護し、トラフィックを制限できる必要があります。電流制限の方法は数多くありますが、最も簡単な方法は、単位時間あたりのリクエストが多すぎる場合に超過リクエストを破棄することです。さらに、パーティション電流制限も考慮できます。大量のリクエストを生成するサービスからのリクエストのみを拒否します。たとえば、製品サービスと注文サービスの両方がプロモーション サービスにアクセスする必要があります。製品サービスはコードの問題により大量のリクエストを開始します。プロモーション サービスは製品サービスからのリクエストのみを制限し、注文サービスからのリクエストは応答します。通常は。
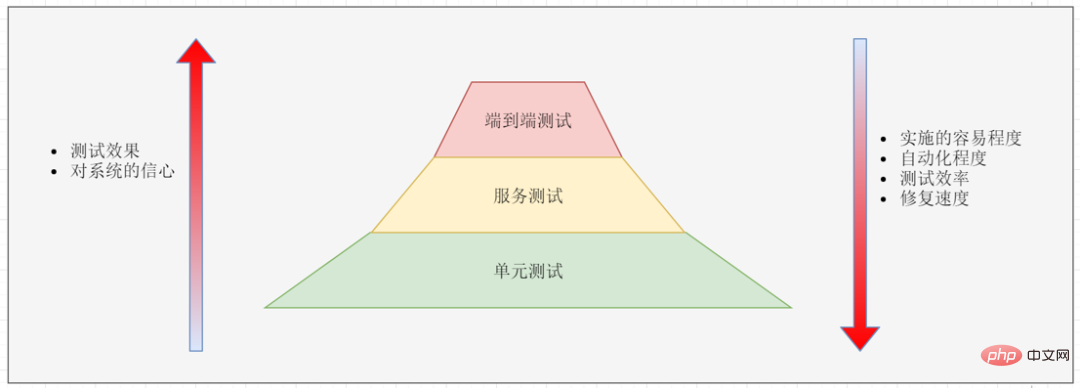
#テスト
マイクロサービス アーキテクチャでは、テストは 3 つのレベルに分割されます。- エンドツーエンドのテスト: システム全体を対象とし、通常はユーザー インターフェイス モデルでテストされます。
- サービスのテスト: サービス インターフェイスをテストします。
- 単体テスト: コード単位をテストします。
エンドツーエンドのテストは実装が難しいため、通常、エンドツーエンドのテストはコア機能に対してのみ行われます。エンドツーエンドのテストが失敗したら、それを単体テストに分割する必要があります。次に、失敗の理由が分析され、問題を再現する単体テストが作成され、同じエラーをより早く検出できるようになります。未来。
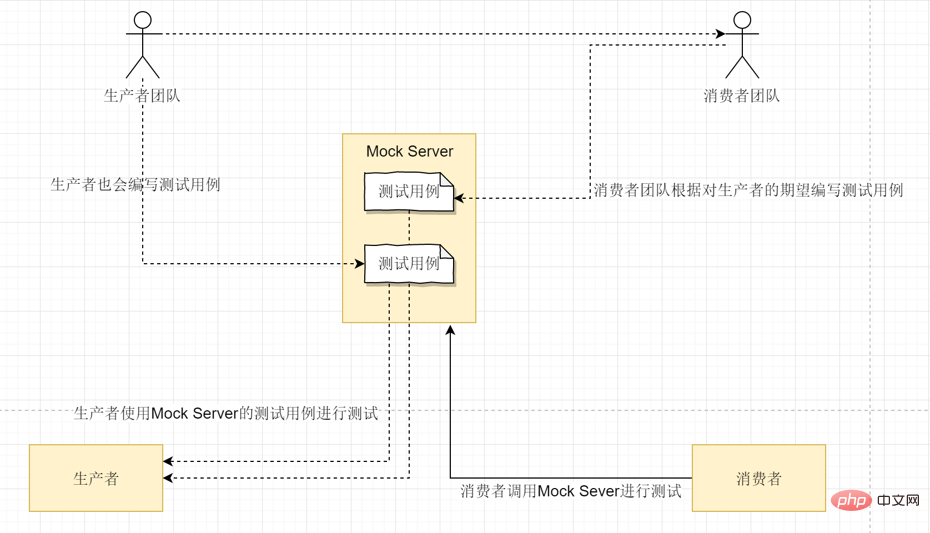
サービスのテストの難しさは、サービスが他のサービスに依存していることが多いことです。この問題は、Mock Server を使用して解決できます。単体テストについては誰もがよく知っています。通常、すべてのコードをカバーするために、多数の単体テスト (回帰テストを含む) を作成します。
マイクロサービス フレームワーク
インジケーター インターフェイス、リンク トラッキング インジェクション、ログ転送、サービス登録検出、ルーティング ルール、その他のコンポーネント、およびサーキット ブレーカー、電流制限、その他の機能はすべて、アプリケーション サービス上にあるドッキング コードを追加します。各アプリケーション サービスを単独で実装するには、非常に時間と労力がかかります。 Xiao Ming は DRY の原則に基づいてマイクロサービス フレームワークを開発し、各コンポーネントとのインターフェイスとなるコードやその他のパブリック コードをフレームワークに抽出し、すべてのアプリケーション サービスはこのフレームワークを使用して開発されています。
マイクロサービス フレームワークを使用すると、多くのカスタマイズされた機能を実現できます。プログラムの呼び出しスタック情報をリンク追跡に挿入して、コードレベルのリンク追跡を実現することもできます。または、スレッド プールと接続プールのステータス情報を出力し、サービスの基盤となるステータスをリアルタイムで監視します。
統合マイクロサービス フレームワークの使用には重大な問題があります。フレームワークの更新コストが非常に高いということです。フレームワークがアップグレードされるたびに、すべてのアプリケーション サービスがアップグレードに協力する必要があります。もちろん、一般的には互換性ソリューションが使用され、すべてのアプリケーション サービスがアップグレードされるまで一定期間並行して待機することができます。ただし、アプリケーション サービスが多数ある場合は、アップグレード時間が非常に長くなる可能性があります。また、非常に安定しており、ほとんど更新されないアプリケーションサービスもあり、担当者がアップグレードを拒否する場合もあります... したがって、統合されたマイクロサービスフレームワークを使用するには、完全なバージョン管理方法と開発管理仕様が必要です。
別の方法 - サービス メッシュ
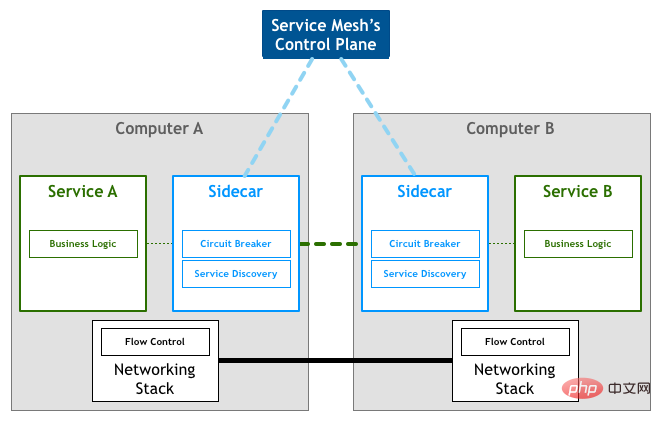
共通コードを抽象化するもう 1 つの方法は、このコードをリバース プロキシ コンポーネントに直接抽象化することです。各サービスはさらにこのプロキシ コンポーネントを展開し、すべてのアウトバウンドおよびインバウンド トラフィックはこのコンポーネントを通じて処理および転送されます。このコンポーネントはサイドカーと呼ばれます。
サイドカーでは追加のネットワーク コストは発生しません。サイドカーはマイクロサービス ノードと同じホストにデプロイされ、同じ仮想ネットワーク カードを共有します。したがって、サイドカー ノードとマイクロサービス ノード間の通信は、実際にはメモリ コピーを通じてのみ実現されます。
画像元: パターン: サービス メッシュSidecar はネットワーク通信のみを担当します。すべてのサイドカーの構成を均一に管理するためのコンポーネントも必要です。サービス メッシュでは、ネットワーク通信を担当する部分はデータ プレーンと呼ばれ、構成管理を担当する部分はコントロール プレーンと呼ばれます。データ プレーンとコントロール プレーンは、サービス メッシュの基本アーキテクチャを構成します。
画像元: パターン: サービス メッシュマイクロサービス フレームワークと比較したサービス メッシュの利点は、次のとおりです。侵入的なコードを使用しないことで、アップグレードとメンテナンスがより便利になります。パフォーマンスの問題で批判されることがよくあります。ループバック ネットワークは実際のネットワーク リクエストを生成しませんが、メモリ コピーの追加コストは依然として発生します。さらに、一部の集中トラフィック処理もパフォーマンスに影響します。
終わりは始まりでもある
マイクロサービスはアーキテクチャの進化の終わりではありません。さらに進むと、サーバーレス、FaaS、その他の方向性があります。一方で、合唱団は長く離れなければならず、長く再会しなければならないと歌い、一枚岩の建築を再発見する人もいます...
いずれにせよ、マイクロサービス アーキテクチャの変革は当面終了しました。シャオミンは満足そうに滑らかになっていく頭を撫で、今週末は休暇を取ってシャオホンとコーヒーを飲みに行くつもりだった。
- ユーザー管理
以上がこれは、これまで読んだマイクロサービス アーキテクチャに関する最も詳細な記事かもしれません。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。