


PHP 関数の概要 - get_headers(): URL の応答ヘッダー情報を取得する
概要:
PHP 開発では、Web ページまたはリモート リソースの応答ヘッダー情報を取得する必要があることがよくあります。 。 PHP 関数 get_headers() を使用すると、対象 URL のレスポンスヘッダ情報を簡単に取得し、配列で返すことができます。この記事では、get_headers() 関数の使用法を紹介し、関連するコード例をいくつか示します。
get_headers() 関数の使用法: get_headers()この関数は、指定された URL の応答ヘッダーを取得し、配列として返すことができます。関数の基本的な構文は次のとおりです。
array get_headers(string $url, int $format = 0)
$url パラメータはターゲット URL を表し、$format パラメータは形式を設定するために使用されるオプションのパラメータです。返された配列の。デフォルトでは、$format は 0 で、インデックスと値を含む連想配列が返されることを示します。 $format が 1 に設定されている場合、インデックス配列が返されます。
コード例:
$url = "https://www.example.com";
$headers = get_headers($url);
// 打印所有的响应头信息
print_r($headers);
// 打印指定的响应头信息
echo $headers[0]; // 打印第一个响应头
echo $headers[1]; // 打印第二个响应头
/*
输出示例:
Array (
[0] => HTTP/1.1 200 OK
[1] => Date: Thu, 19 Nov 2020 08:00:00 GMT
[2] => Server: Apache/2.4.41
[3] => Content-Type: text/html; charset=UTF-8
[4] => Content-Length: 12345
...
)
*/
応用シナリオ: get_headers()実際の開発における関数の応用シナリオは非常に多岐にわたります。一般的なアプリケーション シナリオの一部を次に示します。
- リモート ファイルのファイル情報を取得する: ターゲット URL の応答ヘッダー情報を取得することで、ファイル サイズ、MIME タイプ、およびその他の情報を取得できます。 # #リモート ファイルが存在するかどうかを確認する: HTTP 応答ヘッダーのステータス コードを使用して、リモート ファイルが存在するか有効であるかを判断します;
- クローラーとネットワークの監視: Web コンテンツをクロールするとき、またはネットワークを実行するとき監視を行う場合、まずターゲット URL を取得できます。応答ヘッダー情報は、後続の処理のためのステータス コードやその他の重要な情報を決定するために使用されます。
get_headers() 関数は通常、HTTP プロトコルの応答ヘッダー情報のみを取得でき、FTP などの他のプロトコルには適用できないことに注意してください。プロトコル。
get_headers()関数は、対象URLのレスポンスヘッダ情報を簡単に取得できる非常に実用的なPHP関数です。この機能により、ステータスコード、日付、サーバー情報、ファイルサイズなど、HTTP レスポンスヘッダーのさまざまな情報を取得できます。実際の開発では、get_headers() 関数を使いこなして柔軟に適用することで、コードの使いやすさと効率を向上させることができます。
- PHP 公式ドキュメント: [get_headers](https://www.php.net/manual/en/function.get-headers.php)
以上がPHP 関数の紹介 - get_headers(): URL の応答ヘッダー情報を取得しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 PHP函数介绍—get_headers(): 获取URL的响应头信息Jul 25, 2023 am 09:05 AM
PHP函数介绍—get_headers(): 获取URL的响应头信息Jul 25, 2023 am 09:05 AMPHP函数介绍—get_headers():获取URL的响应头信息概述:在PHP开发中,我们经常需要获取网页或远程资源的响应头信息。PHP函数get_headers()能够方便地获取目标URL的响应头信息,并以数组形式返回。本文将介绍get_headers()函数的用法,以及提供一些相关的代码示例。get_headers()函数的用法:get_header
 为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM
为什么NameResolutionError(self.host, self, e) from e,怎么解决Mar 01, 2024 pm 01:20 PM报错的原因NameResolutionError(self.host,self,e)frome是由urllib3库中的异常类型,这个错误的原因是DNS解析失败,也就是说,试图解析的主机名或IP地址无法找到。这可能是由于输入的URL地址不正确,或者DNS服务器暂时不可用导致的。如何解决解决此错误的方法可能有以下几种:检查输入的URL地址是否正确,确保它是可访问的确保DNS服务器可用,您可以尝试在命令行中使用"ping"命令来测试DNS服务器是否可用尝试使用IP地址而不是主机名来访问网站如果是在代理
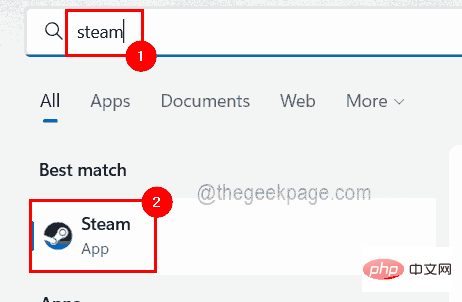 怎样透过几个步骤获取您的 Steam ID?May 08, 2023 pm 11:43 PM
怎样透过几个步骤获取您的 Steam ID?May 08, 2023 pm 11:43 PM现在很多热爱游戏的windows用户都进入了Steam客户端,可以搜索、下载和玩任何好游戏。但是,许多用户的个人资料可能具有完全相同的名称,这使得查找个人资料或什至将Steam个人资料链接到其他第三方帐户或加入Steam论坛以共享内容变得困难。为配置文件分配了一个唯一的17位id,它保持不变,用户无法随时更改,而用户名或自定义URL可以更改。无论如何,一些用户并不知道他们的Steamid,这对于了解这一点非常重要。如果您也不知道如何找到您帐户的Steamid,请不要惊慌。在这篇文
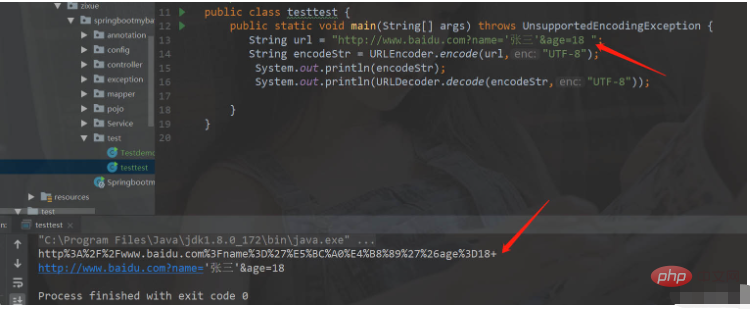 如何在Java中使用URL编码和解码May 08, 2023 pm 05:46 PM
如何在Java中使用URL编码和解码May 08, 2023 pm 05:46 PM使用url进行编码和解码编码和解码的类java.net.URLDecoder.decode(url,解码格式)解码器.解码方法。转化成普通字符串,URLEncoder.decode(url,编码格式)将普通字符串变成指定格式的字符串packagecom.zixue.springbootmybatis.test;importjava.io.UnsupportedEncodingException;importjava.net.URLDecoder;importjava.net.URLEncoder
 html和url的区别是什么Mar 06, 2024 pm 03:06 PM
html和url的区别是什么Mar 06, 2024 pm 03:06 PM区别:1、定义不同,url是是统一资源定位符,而html是超文本标记语言;2、一个html中可以有很多个url,而一个url中只能存在一个html页面;3、html指的是网页,而url指的是网站地址。
 Scrapy优化技巧:如何减少重复URL的爬取,提高效率Jun 22, 2023 pm 01:57 PM
Scrapy优化技巧:如何减少重复URL的爬取,提高效率Jun 22, 2023 pm 01:57 PMScrapy是一个功能强大的Python爬虫框架,可以用于从互联网上获取大量的数据。但是,在进行Scrapy开发时,经常会遇到重复URL的爬取问题,这会浪费大量的时间和资源,影响效率。本文将介绍一些Scrapy优化技巧,以减少重复URL的爬取,提高Scrapy爬虫的效率。一、使用start_urls和allowed_domains属性在Scrapy爬虫中,可
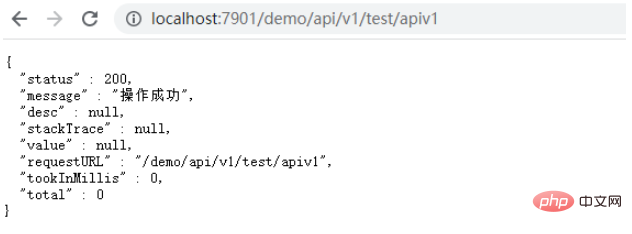 SpringBoot多controller如何添加URL前缀May 12, 2023 pm 06:37 PM
SpringBoot多controller如何添加URL前缀May 12, 2023 pm 06:37 PM前言在某些情况下,服务的controller中前缀是一致的,例如所有URL的前缀都为/context-path/api/v1,需要为某些URL添加统一的前缀。能想到的处理办法为修改服务的context-path,在context-path中添加api/v1,这样修改全局的前缀能够解决上面的问题,但存在弊端,如果URL存在多个前缀,例如有些URL需要前缀为api/v2,就无法区分了,如果服务中的一些静态资源不想添加api/v1,也无法区分。下面通过自定义注解的方式实现某些URL前缀的统一添加。一、
 url是啥意思Aug 04, 2023 am 11:43 AM
url是啥意思Aug 04, 2023 am 11:43 AMurl是“Uniform Resource Locator”的缩写,中文意为“统一资源定位符”。URL是通过互联网来定位和访问特定资源的地址,常见于网页浏览和HTTP请求中。URL的主要作用是定位和访问互联网上的资源,这些资源可以是网页、图片、视频、文档或其他文件。


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SublimeText3 中国語版
中国語版、とても使いやすい

PhpStorm Mac バージョン
最新(2018.2.1)のプロフェッショナル向けPHP統合開発ツール

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。
ホットトピック
 7441
7441 15137152
15137152