
Go 言語メカニズムのスタックとポインター
- Go语言进阶学习転載
- 2023-07-24 16:10:54851ブラウズ
このシリーズには 4 つの記事が含まれており、主に Go 言語のポインター、スタック、ヒープ、エスケープ分析、および値/ポインターのセマンティクスの背後にあるメカニズムと設計概念を説明します。この記事はシリーズの最初の記事で、主にスタックとポインターについて説明します。
はじめに
ポインタを適切な言葉で表すつもりはありません。本当に理解するのが難しいのです。誤って使用すると、迷惑なバグやパフォーマンスの問題が発生する可能性があります。これは、同時実行ソフトウェアまたはマルチスレッド ソフトウェアを作成する場合に特に当てはまります。多くのプログラミング言語がプログラマのためにポインタの使用を避けようとするのも不思議ではありません。ただし、Go プログラミング言語を使用する場合、ポインタは避けられません。ポインタを深く理解することによってのみ、クリーンで簡潔かつ効率的なコードを書くことができます。
フレーム境界
フレーム境界は関数ごとに個別のメモリ空間を提供し、関数はフレーム境界内で実行されます。フレーム境界により、関数が独自のコンテキストで実行できるようになり、フロー制御も提供されます。関数はフレーム ポインターを介してフレーム内のメモリに直接アクセスできますが、フレーム外のメモリへのアクセスは間接的にのみ行うことができます。各関数でフレーム外のメモリにアクセスできるようにするには、このメモリを関数と共有する必要があります。共有実装を理解するには、まずフレーム境界を確立するためのメカニズムと制約を学び、理解する必要があります。
関数が呼び出されると、2 つのフレーム境界間でコンテキストの切り替えが発生します。呼び出し関数から呼び出される関数へ、関数の呼び出し時にパラメーターを渡す必要がある場合、これらのパラメーターも呼び出される関数のフレーム境界内で渡す必要があります。 Go 言語では、データは 2 つのフレーム間で値によって転送されます。
データを値で渡す利点は、読みやすさです。関数が呼び出されたときに表示される値は、関数の呼び出し元と呼び出し先の間でコピーおよび受信される値です。私が「値による受け渡し」を WYSIWYG と関連付けているのは、目に見えるものがそのまま得られるものであるためです。
整数データを値で渡すコードを見てみましょう:
リスト 1
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
// Pass the "value of" the count.
increment(count)
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc int) {
// Increment the "value of" inc.
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
}Go プログラムを開始すると、ランタイムは main() 関数内のコードを含むすべての初期化コードを実行するメイン コルーチンを作成します。 Goroutine はオペレーティング システムのスレッド上に配置された実行パスであり、最終的には特定のコア上で実行されます。 Go 1.8 以降、各ゴルーチンはスタック スペースとして 2048 バイトの連続メモリ ブロックを割り当てます。初期スタック領域のサイズは長年にわたって変化しており、将来的には再び変化する可能性があります。
スタックは、個々の関数のフレーム境界に物理メモリ空間を提供するため、非常に重要です。リスト 1 によると、メイン コルーチンが main() 関数を実行すると、スタック領域は次のように分配されます。
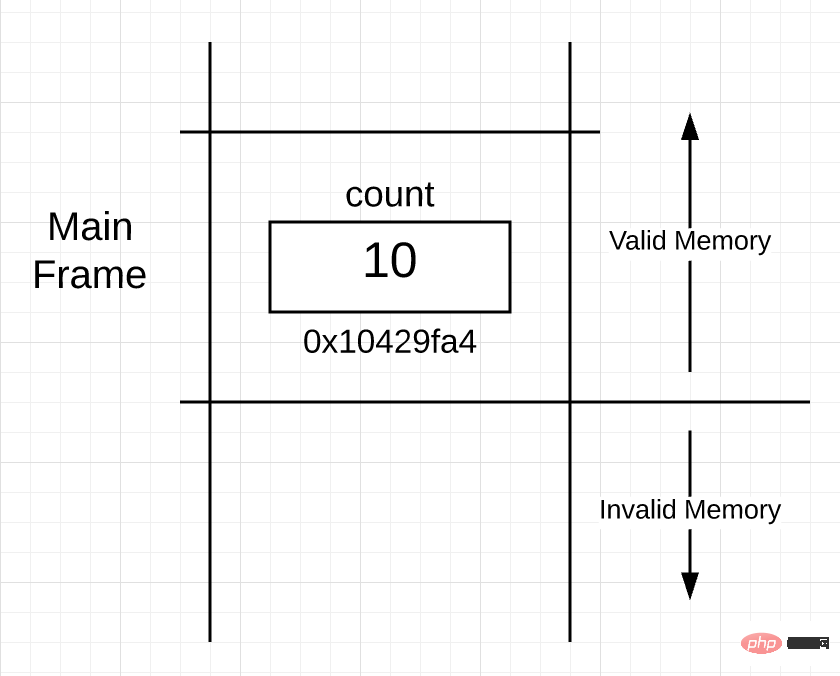
図 1
図 1 では、main 関数のスタックの一部がフレーム化されていることがわかります。この部分を「スタックフレーム」と呼び、このフレームがスタック上のmain関数の境界を表します。呼び出された関数が実行されるとフレームが作成され、変数 count が main() 関数フレームのメモリ アドレス 0x10429fa4 に配置されていることがわかります。
図 1 には、もう 1 つの興味深い点も示されています。アクティブ フレームより下のスタック メモリはすべて使用できず、アクティブ フレームより上のスタック メモリのみが使用可能です。使用可能なスタック領域と使用できないスタック領域の境界を明確にする必要があります。
アドレス
変数の目的は、特定のメモリ アドレスに名前を割り当てることで、コードを読みやすくし、処理しているデータの分析に役立てることです。変数があり、メモリに格納されたその値を取得できる場合、メモリ アドレス内にこの値を格納するアドレスが存在する必要があります。コードの 9 行目で、main() 関数は組み込み関数 println() を呼び出し、変数 count の値とアドレスを表示します。
リスト 2
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")& 演算子を使用して、変数が配置されているメモリ位置のアドレスを取得するのは驚くべきことではありません。他の言語でもこの演算子が使用されます。コードが go playground などの 32 ビット コンピューターで実行されている場合、出力は次のようになります。
清单3
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
函数调用
接下来的第 12 行代码,main() 函数调用 increment() 函数。
清单4
increment(count)
调用函数意味着协程需要在栈上构建出一块新的栈帧。但是,事情有点复杂。要想成功地调用函数,在发生上下文切换时,数据需要跨越帧边界传递到新的帧范围内。具体一点来说,函数调用的时候,整型值会被复制和传递。通过第 18 行代码、increment() 函数的声明,你就可以知道。
清单5
func increment(inc int) {如果你回过头来再次看第 12 行代码函数 increment() 的调用,你会发现 count 变量是传值的。这个值会被拷贝、传递,最后存储在 increment() 函数的栈中。记住,increment() 函数只能在自己的栈内读写内存,因此,它需要 inc 变量来接收、存储和访问传递的 count 变量的副本。
就在 increment() 函数内部代码开始执行之前,协程的栈(站在一个非常高的角度)应该是像下图这样的:
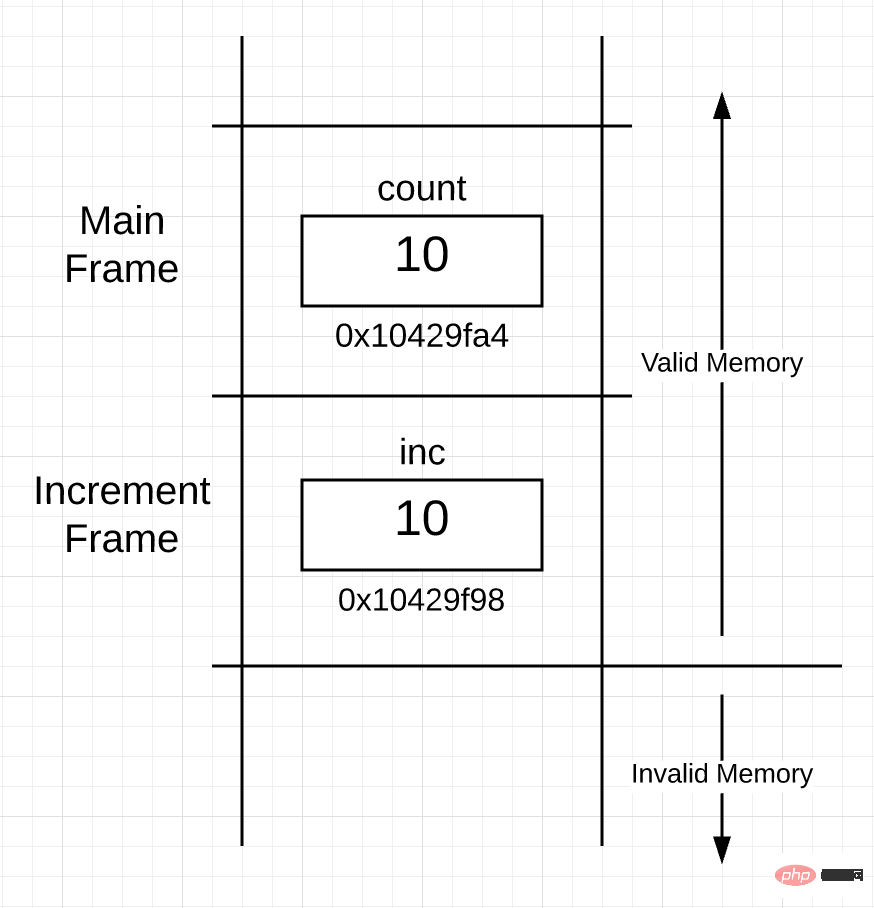
图 2
你可以看到栈上现在有两个帧,一个属于 main() 函数,另一个属于 increment() 函数。在 increment() 函数的帧里面,你可以看到 inc 变量,它的值 10,是函数调用时拷贝、传递进来的。变量 inc 的地址是 0x10429f98,因为栈帧是从上至下使用栈空间的,所以它的内存地址较小,这只是具体的实现细节,并没任何意义。重要的是,协程从 main() 的栈帧里获取变量 count 的值,并使用 inc 变量将该值的副本放置在 increment() 函数的栈帧里。
increment() 函数的剩余代码显示 inc 变量的值和地址。
清单6
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")第 22 行代码输出类似下面这样:
清单7
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
执行这些代码之后,栈就会像下面这样:
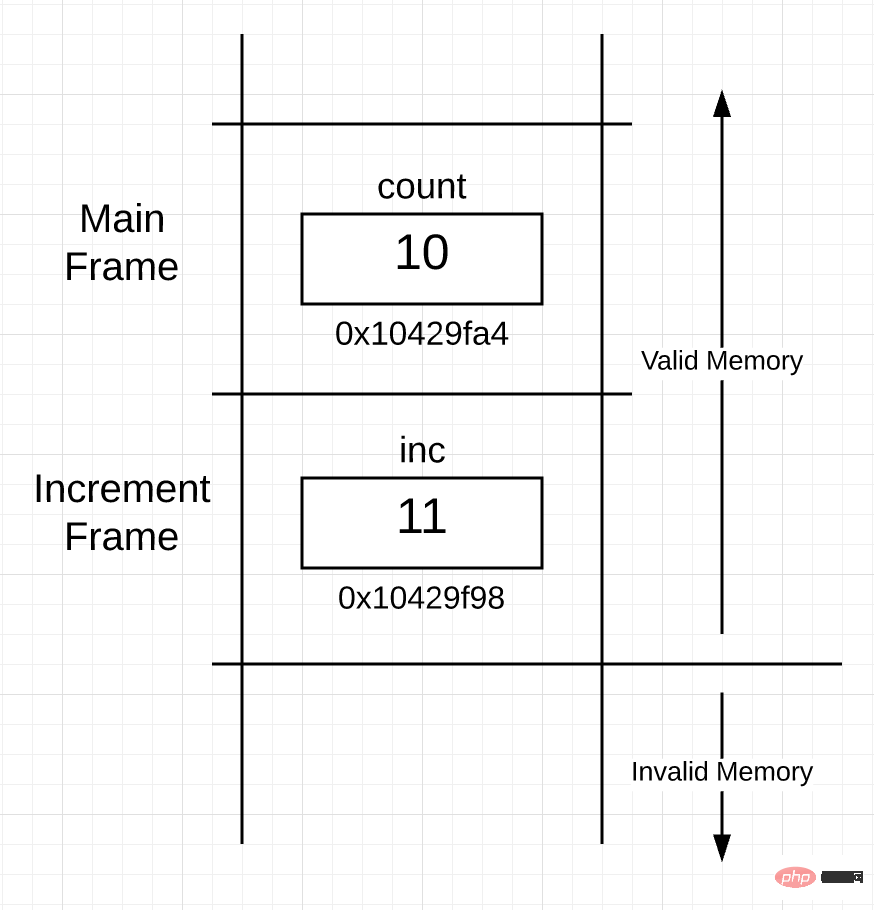
图 3
第 21、22 行代码执行之后,increment() 函数返回并且 CPU 控制权交还给 main() 函数。第 14 行代码,main() 函数会再次显示 count 变量的值和地址。
清单8
println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")上面例子完整的输出会像下面这样:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ] inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ] count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
main() 函数栈帧里,变量 count 的值在调用 increment() 函数前后是相同的。
函数返回
当函数返回并且控制权交还给调用函数时,栈上的内存实际上会发生什么?回答是:不会发生任何事情。当 increment() 函数返回时,栈上的空间看起来像下面这样:
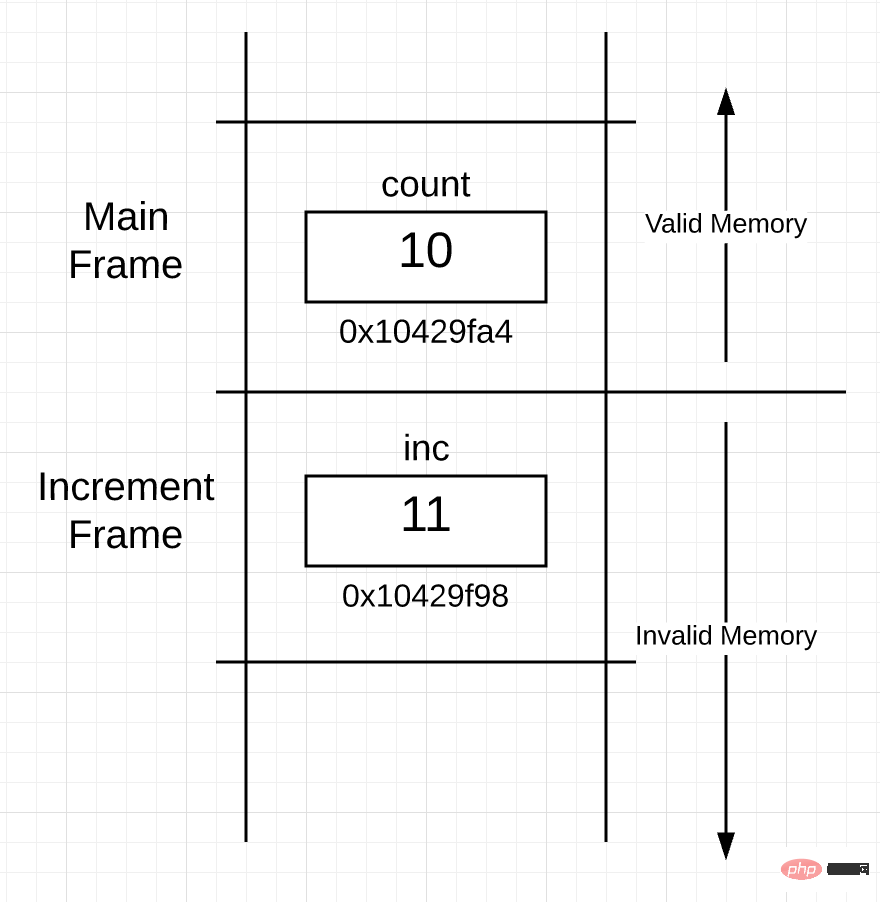
図 4
スタックの配布は基本的に図 3 と同じですが、increment() 関数用に作成されたスタック フレームが使用できなくなる点が異なります。これは、main() 関数のフレームがアクティブ フレームになるためです。 increment() 関数のスタック フレームでは処理は行われません。
関数が戻ったときに、このメモリが再び使用されるかどうかわからないため、関数のフレームをクリーンアップすると時間が無駄になります。したがって、このメモリでは何も処理されません。関数が呼び出されるたびに、フレームが必要になると、スタックに割り当てられたフレームがクリアされます。これは、フレームに格納されている変数を初期化するときに行われます。すべての値は対応するゼロ値に初期化されるため、関数が呼び出されるたびにスタックは正しくクリーンアップされます。
共有値
increment() 関数が main() 関数フレームに格納されている count 変数を直接操作することが非常に重要である場合はどうすればよいでしょうか?これにはポインタを使用する必要があります。ポインタの目的は関数間で値を共有することであり、値が自分の関数の枠内になくても関数は読み書きできます。
共有という概念が頭の中にない場合は、おそらくポインタを使用しないでしょう。ポインタを学習するときは、単に演算子や構文を覚えるのではなく、明確な語彙を使用することが重要です。したがって、ポインタは共有されることを目的としており、コードを読むときに「共有」について考えるときは & 演算子を思い浮かべる必要があることを覚えておいてください。
ポインタ型
自分でカスタマイズしたものでも、Go 言語に付属しているものでも、宣言された型ごとに、これらの型に基づいて対応するポインタ型を取得して共有できます。たとえば、組み込み型 int の場合、対応するポインター型は *int です。 User 型を自分で宣言した場合、対応するポインター型は *User になります。
すべてのポインター型は同じ特性を持っています。第一に、これらは * 記号で始まり、第二に、同じメモリ空間を占有し、両方とも 4 バイトまたは 8 バイトの長さを使用してアドレスを表します。 32 ビット マシン (プレイグラウンドなど) では、ポインターには 4 バイトのメモリが必要ですが、64 ビット マシン (コンピュータなど) では、8 バイトのメモリが必要です。
规范里有说明,指针类型可以看成是类型字面量,这意味着它们是有现有类型组成的未命名类型。
间接访问内存
让我们来看一段代码,这段代码展示了函数调用时按值传递地址。main() 和 increment() 函数的栈帧会共享 count 变量:
清单10
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
// Pass the "address of" count.
increment(&count)
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc *int) {
// Increment the "value of" count that the "pointer points to". (dereferencing)
*inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
}基于原来的代码有三处改动的地方,第 12 行是第一处改动:
清单11
increment(&count)
现在,第 12 行代码拷贝、传递的并非 count 变量的值,而是变量的地址。可以认为,main() 函数与 increment() 函数是共享 count 变量的。这是 & 操作符起的作用。
重点理解,现在依旧是传值,唯一不同的是现在传递的是地址而不是一个整型数据。地址也是一个值,是函数调用时会跨帧边界发生拷贝和传递的内容。
因为地址会发生拷贝和传递,在 increment() 函数里面需要一个变量接收和存储该地址值。所以在第 18 行声明了整型的指针变量。
清单12
func increment(inc *int) {如果你传递的是 User 类型值的地址,变量就应该声明成 *User。尽管指针变量存储的是地址,也不能传递任何类型的地址,只能传递与指针类型相一致的地址。关键在于,共享值的原因是因为接收函数能够对值进行读写操作。只有知道值的类型信息才能够进行读写操作。编译器会保证只有与指针类型相一致的值才能够实现函数间共享。
调用 increment() 函数时候,栈空间就像下面这样:
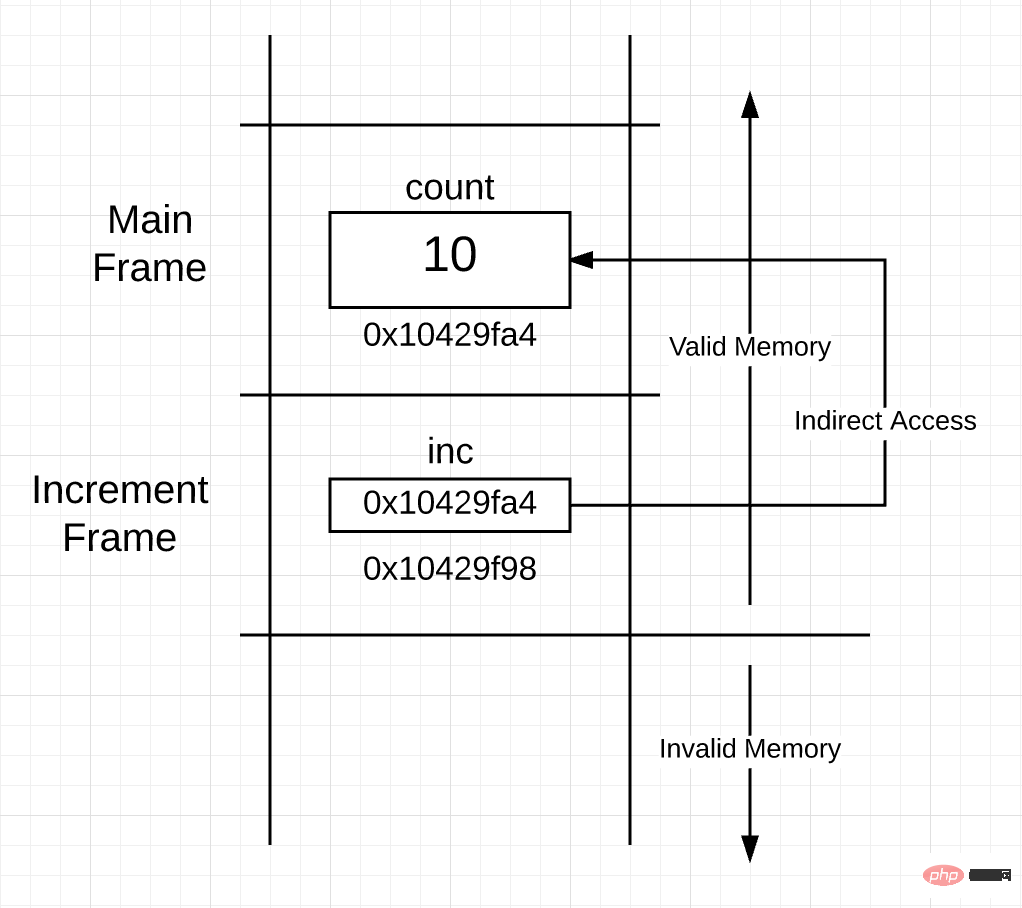
图 5
当一个地址作为值执行按值传递之后,你可以从图 5 看出栈是如何分布的。现在,increment() 函数帧空间里面的指针变量指向 count 变量,该变量在 main() 函数的帧空间里。
通过使用指针变量,increment() 函数可以间接对 count 变量执行读写操作。
清单 13
*inc++
这一次,字符 * 充当操作符,与指针变量搭配使用。使用 * 操作符是“获取指针指向的值”的意思。指针变量允许在帧外对函数帧内的内存进行间接访问。有时候,间接的读写操作也称为解引用。increment() 函数必须有指针变量,才能够对其他函数帧空间执行间接访问。
执行第 21 行代码之后,栈空间分布如图 6 所示。
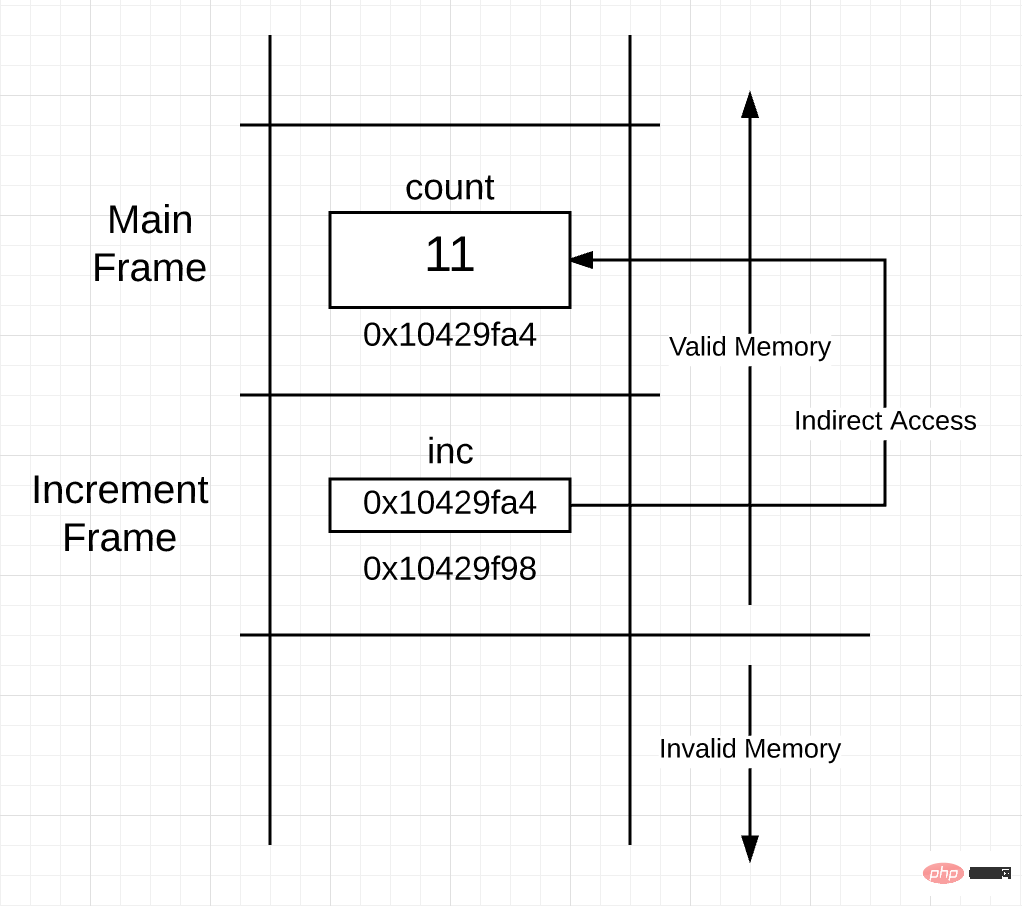
图 6
程序最后输出:
清单 14
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ] inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ] count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
你可以看到,指针变量 inc 的值和 count 变量的地址是相同的。这将建立起共享关系,允许在帧外执行内存的间接访问。在 increment() 函数里,一旦通过指针执行了写操作,改变也会体现在 main() 函数里。
指针变量并不特别
指针变量并不特别,它们和其他变量一样也是变量,有内存地址和值。正巧的是,无论指针变量指向的值的类型如何,所有的指针变量都有同样的大小和表现形式。唯一困惑的是使用 * 字符充当操作符,用来声明指针类型。如果你能分清指针类型声明和指针操作,你就没有那么困惑了。
总结
这篇文章描述了设计指针背后的目的和 Go 语言中栈和指针的工作机制。这是理解 Go 语言机制、设计哲学的第一步,也对编写一致性且可读性的代码提供一些指导作用。
总结一下,通过这篇文章你能学习到的知识:
1.フレーム境界は関数ごとに個別のメモリ空間を提供し、関数はフレーム範囲内で実行されます; 2.関数が呼び出されるとき、コンテキスト環境は 2 つのフレーム間で切り替わります;3.値渡しの利点は読みやすさです; 4.スタックは、各関数のフレーム境界にアクセス可能な物理メモリ空間を提供するため重要です。5.アクティブなフレームより下のすべてのスタック メモリはアクセスできません。使用のみです。アクティブなフレームとその上のスタック メモリが便利です。6.関数を呼び出すと、コルーチンがスタック メモリ上に新しいスタック フレームを開きます。 7.関数が呼び出されるたびに、フレームが使用されると、対応するスタック メモリが初期化されます; 8.デザイン ポインタの目的は、関数間での値の共有。値が関数自身のスタック フレームにない場合でも、読み取りと書き込みは可能です。9.型ごとに、それが独自のものであるかどうか定義は Go 言語に組み込まれており、対応するポインター型を持ちます。10. ポインター変数を使用すると、関数フレームの外で間接的なメモリ アクセスが許可されます。 11.他の変数と比較すると、ポインタ変数はメモリ アドレスと値を持つ変数であるため、特別なことは何もありません。
以上がGo 言語メカニズムのスタックとポインターの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。