



誰もが独自の大規模モデルのアップグレードと反復を続けると、コンテキスト ウィンドウを処理する LLM (大規模言語モデル) の能力も重要な評価指標になります。
たとえば、スターラージモデル GPT-4 は、50 ページのテキストに相当する 32,000 個のトークンをサポートしています。OpenAI の元メンバーによって設立された Anthropic は、Claude のトークン処理能力を100k、約 75,000 1 単語は、「ハリー・ポッター」の最初の部分を 1 回クリックで要約するのにほぼ相当します。
Microsoft の最新の調査では、今回は Transformer を 10 億トークンまで直接拡張しました。これにより、コーパス全体やインターネット全体を 1 つのシーケンスとして扱うなど、非常に長いシーケンスをモデル化するための新しい可能性が開かれます。
比較のために、平均的な人は約 5 時間で 100,000 トークンを読み取ることができますが、情報を消化、記憶、分析するにはさらに時間がかかる可能性があります。クロードはこれを 1 分以内に実行できます。これを Microsoft の調査に換算すると、驚異的な数字になります。
 写真
写真
- 論文アドレス: https://arxiv.org/pdf/2307.02486.pdf
- プロジェクト アドレス: https://github.com/microsoft/unilm/tree/master
具体的には、この研究では LONGNET を提案しています。短いシーケンスのパフォーマンスを犠牲にすることなく、シーケンスの長さを 10 億トークンを超えるまで拡張できるトランスフォーマーのバリアント。この記事では、モデルの知覚範囲を指数関数的に拡大できる拡張注意も提案しています。
LONGNET には次の利点があります:
1) 線形計算の複雑さがあります;
2) より長いシーケンスの分散トレーナーとして使用できます;
3) 拡張された注意は標準の注意をシームレスに置き換えることができ、統合された既存の Transformer ベースの最適化手法とシームレスに連携できます。
実験結果は、LONGNET が長いシーケンス モデリングと一般的な言語タスクの両方で優れたパフォーマンスを発揮することを示しています。
研究動機について論文では、近年ニューラルネットワークの拡張がトレンドとなっており、性能の良いネットワークが数多く研究されていると述べています。その中で、ニューラル ネットワークの一部としてのシーケンスの長さは、理想的には無限である必要があります。しかし、現実はその逆であることが多いため、シーケンスの長さの制限を破ることは大きな利点をもたらします。
- 第一に、モデルに大容量のメモリと受容野が提供されます。 . 人間や世界と効果的に対話できるようにします。
- 第 2 に、より長いコンテキストには、モデルがトレーニング データで利用できるより複雑な因果関係と推論パスが含まれます。逆に、依存関係が短いと偽の相関が多くなり、モデルの一般化には役立ちません。
- 3 番目に、シーケンスの長さが長いと、モデルがより長いコンテキストを探索するのに役立ちます。また、非常に長いコンテキストは、モデルが壊滅的な忘却の問題を軽減するのにも役立ちます。
#ただし、シーケンスの長さを拡張する際の主な課題は、計算の複雑さとモデルの表現力の間の適切なバランスを見つけることです。
たとえば、RNN スタイル モデルは主にシーケンスの長さを増やすために使用されます。ただし、その逐次的な性質により、トレーニング中の並列化が制限されます。これは、長いシーケンスのモデリングでは重要です。
最近、状態空間モデルはシーケンス モデリングにとって非常に魅力的なものになっており、トレーニング中に CNN として実行でき、テスト時に効率的な RNN に変換できます。ただし、このタイプのモデルは、通常の長さではトランスフォーマーほどのパフォーマンスは得られません。
シーケンスの長さを拡張するもう 1 つの方法は、Transformer の複雑さ、つまり自己注意の 2 次複雑さを軽減することです。現段階では、低ランク アテンション、カーネル ベースの方法、ダウンサンプリング方法、検索ベースの方法など、いくつかの効率的な Transformer ベースのバリアントが提案されています。ただし、これらのアプローチでは、まだ Transformer を 10 億トークンの規模まで拡張することはできません (図 1 を参照)。
 図
図
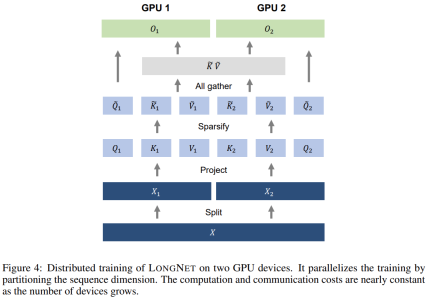
次の表は、さまざまな計算方法の計算の複雑さを比較しています。 N はシーケンスの長さ、d は隠れ次元です。 ###############写真###### 研究のソリューションである LONGNET は、シーケンスの長さを 10 億トークンまで拡張することに成功しました。具体的には、本研究は、拡張された注意と呼ばれる新しいコンポーネントを提案し、バニラトランスフォーマーの注意メカニズムを拡張された注意に置き換えます。一般的な設計原則は、トークン間の距離が増加するにつれて、注意の割り当てが指数関数的に減少するというものです。この研究は、この設計アプローチにより線形の計算複雑さとトークン間の対数依存性が得られることを示しています。これにより、限られた注意リソースとすべてのトークンへのアクセスの間の競合が解決されます。 実装プロセス中に、LONGNET を高密度の Transformer に変換して、既存の Transformer 固有の機能をシームレスにサポートできます。最適化手法 (カーネル融合、量子化、分散トレーニングなど)。線形複雑性を利用して、分散アルゴリズムを使用してコンピューティングとメモリの制約を打ち破り、LONGNET をノード間で並行してトレーニングできます。 最終的に、次の図に示すように、研究によりシーケンス長が 1B トークンまで効果的に拡張され、実行時間はほぼ一定になりました。対照的に、バニラの Transformer のランタイムは 2 次の複雑さの影響を受けます。 #この研究では、多頭拡張型注意メカニズムをさらに紹介します。以下の図 3 に示すように、この研究では、クエリ-キー-値のペアのさまざまな部分をスパース化することで、さまざまなヘッドにわたってさまざまな計算を実行します。 #写真 分散トレーニング##拡張された注意の計算の複雑さは大幅に軽減されましたが、コンピューティングとメモリの制限により、単一の GPU でシーケンスの長さを数百万レベルに拡張することは現実的ではありません。のデバイス。大規模モデルのトレーニングには、モデル並列 [SPP 19]、シーケンス並列 [LXLY21、KCL 22]、パイプライン並列 [HCB 19] などの分散トレーニング アルゴリズムがいくつかありますが、これらの手法は LONGNET にとって十分ではありません。シーケンスの次元が非常に大きい場合。 この研究では、LONGNET の線形計算の複雑さをシーケンス次元の分散トレーニングに利用しています。以下の図 4 は、2 つの GPU 上の分散アルゴリズムを示しています。これは、任意の数のデバイスにさらに拡張できます。 ##実験 さらに、この研究では絶対位置エンコーディングを削除しました。まず、結果は、トレーニング中にシーケンスの長さを増加させると、一般的により良い言語モデルが得られることを示しています。第 2 に、長さがモデルがサポートするよりもはるかに大きい場合、推論におけるシーケンス長の外挿方法は適用されません。最後に、LONGNET は常にベースライン モデルを上回るパフォーマンスを示し、言語モデリングにおけるその有効性を示しています。
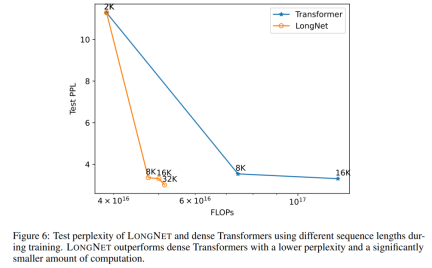
#配列長の展開曲線 図 6 は、バニラ トランスフォーマーと LONGNET のシーケンス長拡張曲線をプロットしています。この研究では、行列乗算の合計フロップ数をカウントすることで計算量を推定します。結果は、バニラ トランスフォーマーと LONGNET の両方がトレーニングからより長いコンテキスト長を達成していることを示しています。ただし、LONGNET はコンテキストの長さをより効率的に拡張できるため、より少ない計算量でより低いテスト損失を実現できます。これは、外挿よりも長いトレーニング入力の利点を示しています。実験によれば、LONGNET は言語モデルのコンテキスト長を拡張するより効率的な方法です。これは、LONGNET がより長い依存関係をより効率的に学習できるためです。 ##モデル サイズの拡張 大規模な言語モデルの重要な特性は、計算量が増加するにつれて損失がべき乗則で拡大することです。 LONGNET が依然として同様のスケーリング ルールに従っているかどうかを検証するために、この研究では、異なるモデル サイズ (1 億 2,500 万から 27 億のパラメーター) で一連のモデルをトレーニングしました。 27 億のモデルは 3,000 億のトークンでトレーニングされ、残りのモデルは約 4,000 億のトークンを使用しました。図 7 (a) は、計算に対する LONGNET の展開曲線をプロットしています。この研究では、同じテストセットの複雑さを計算しました。これは、LONGNET が依然としてべき乗則に従うことができることを証明しています。これは、高密度 Transformer が言語モデルを拡張するための前提条件ではないことも意味します。さらに、LONGNET によりスケーラビリティと効率が向上します。 ##長いコンテキスト プロンプト この研究では、プレフィックス (prefixes) をプロンプトとして保持し、そのサフィックス (suffixes) の複雑さをテストします。さらに、調査の過程で、プロンプトは 2K から 32K まで徐々に拡張されました。公平に比較するために、接尾辞の長さは一定に保たれますが、接頭辞の長さはモデルの最大長まで増加します。図 7(b) は、テスト セットの結果を示しています。コンテキスト ウィンドウが増加するにつれて、LONGNET のテスト損失が徐々に減少することがわかります。これは、言語モデルを改善するために長いコンテキストを最大限に活用する点で LONGNET の優位性を証明しています。 方法
 図
図


この調査では LONGNET の比較を行います。バニラトランスフォーマーとスパーストランスフォーマーで作成されました。アーキテクチャ間の違いは注目層ですが、他の層は同じです。研究者らは、これらのモデルのシーケンス長を 2K から 32K に拡張しながら、各バッチ内のトークンの数が変わらないようにバッチ サイズを削減しました。 表 2 は、スタック データセットでのこれらのモデルの結果をまとめたものです。研究では評価指標として複雑さを使用します。モデルは、2k から 32k の範囲のさまざまなシーケンス長を使用してテストされました。入力の長さがモデルでサポートされる最大長を超える場合、研究では言語モデル推論のための最先端の外挿方法であるブロックごとの因果的注意 (BCA) [SDP 22] が実装されます。


以上がMicrosoft の新しいホット ペーパー: Transformer が 10 億トークンに拡大の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングの一連の質問とは何ですか? - 分析VidhyaApr 17, 2025 am 11:06 AM
迅速なエンジニアリングの一連の質問とは何ですか? - 分析VidhyaApr 17, 2025 am 11:06 AM質問の連鎖:迅速なエンジニアリングの革命 各質問が前の質問に基づいているAIとの会話を想像して、ますます洞察に満ちた答えにつながります。これは、プロンプトエンジニアリングにおける一連の質問の力(COQ)です
 ミストラルNEMOへのアクセス:機能、アプリケーション、および意味Apr 17, 2025 am 11:04 AM
ミストラルNEMOへのアクセス:機能、アプリケーション、および意味Apr 17, 2025 am 11:04 AMMistral Nemo:強力でオープンソース多言語LLM Mistral AIとNvidiaの共同作業であるMistral Nemoは、最先端の自然言語処理を提供する最先端のオープンソースの大規模な言語モデル(LLM)です。 この120億パー
 Excelの丸い関数は何ですか? - 分析VidhyaApr 17, 2025 am 10:56 AM
Excelの丸い関数は何ですか? - 分析VidhyaApr 17, 2025 am 10:56 AM正確な数値データのためのMicrosoft Excelのラウンド関数のマスター 数字はスプレッドシートの基本ですが、精度と読みやすさを達成するには、生データだけではありません。 Microsoft Excelのラウンド機能は、TRAの強力なツールです
 Llamaindexを使用した反射エージェントのガイドApr 17, 2025 am 10:41 AM
Llamaindexを使用した反射エージェントのガイドApr 17, 2025 am 10:41 AMAI Intelligenceの強化:LlamainDexを使用して反射性AIエージェントに深く飛び込む 問題を解決するだけでなく、改善する独自の思考プロセスを反映しているAIを想像してください。これは反射性AIエージェントの領域であり、この記事では
 ラングチェーンでベクトル埋め込みを計算して保存する方法は?Apr 17, 2025 am 10:37 AM
ラングチェーンでベクトル埋め込みを計算して保存する方法は?Apr 17, 2025 am 10:37 AM強化されたコンテンツの取得のためのラングチェーンとベクトルの埋め込みを活用します 以前の記事では、クエリ関連のコンテンツ抽出のためのデータの読み込みと分割技術をカバーしました。 この記事は、ベクトル埋め込みを使用して高度なデータ検索を掘り下げています
 2025年にデータサイエンスフレッシュを雇用する上位13社Apr 17, 2025 am 10:30 AM
2025年にデータサイエンスフレッシュを雇用する上位13社Apr 17, 2025 am 10:30 AMデータサイエンスキャリア:2024年の成功のためのトップ企業とヒント 最近のデータサイエンス卒業生と多国籍企業(MNC)を目指している最終年のエンジニアリング学生には、多くの選択肢があります。 このガイドは、データを採用する大手企業を強調しています
 Genaiで魅力的な顧客体験を作成する方法は?Apr 17, 2025 am 10:27 AM
Genaiで魅力的な顧客体験を作成する方法は?Apr 17, 2025 am 10:27 AM生成AIでの顧客体験の強化:戦略的アプローチ 顧客満足度は最重要であり、企業は並外れた体験を提供する必要性をますます認識しています。 顧客の70%以上がパーソナライズされたサービスを望んでいます
 Flux.1、Gemma 2、Sam 2などをフィーチャーしたAIブレークスルーApr 17, 2025 am 10:26 AM
Flux.1、Gemma 2、Sam 2などをフィーチャーしたAIブレークスルーApr 17, 2025 am 10:26 AMAI週刊ダイジェスト:画期的な革新と倫理的考慮事項 AV BYTESへようこそ、最もエキサイティングなAIの進歩の毎週のまとめ!今週のハイライトは、テキストからイメージの生成、モデルエフィシーの驚くべき進歩を披露します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

WebStorm Mac版
便利なJavaScript開発ツール

メモ帳++7.3.1
使いやすく無料のコードエディター

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

SublimeText3 中国語版
中国語版、とても使いやすい

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

