
ホームページ >テクノロジー周辺機器 >AI >大規模モデルのトレーニングにかかるコストがほぼ半分に削減されました。シンガポール国立大学の最新オプティマイザーが導入されました
大規模モデルのトレーニングにかかるコストがほぼ半分に削減されました。シンガポール国立大学の最新オプティマイザーが導入されました

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-07-17 22:13:171421ブラウズ
オプティマイザは、大規模な言語モデルのトレーニングにおいて大量のメモリ リソースを占有します。
パフォーマンスを維持しながらメモリ消費量を半分に削減する新しい最適化方法が登場しました。
この成果はシンガポール国立大学によって作成され、ACL会議で優秀論文賞を受賞し、実用化されました。
 図
図
大規模な言語モデルのパラメーターの数が増加し続けるにつれて、トレーニング中のメモリ消費の問題はさらに深刻になります。
研究チームは、メモリ消費量を削減しながら、Adam と同じパフォーマンスを実現する CAME オプティマイザーを提案しました。
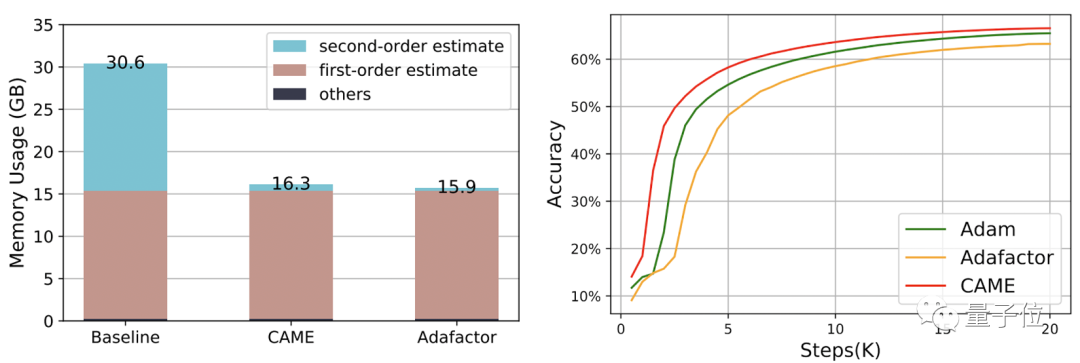 写真
写真
CAME オプティマイザーは、一般的に使用される複数の大規模なトレーニングの事前トレーニングにおいて、Adam オプティマイザーと同等またはそれ以上のトレーニング パフォーマンスを達成しました。また、大規模なバッチの事前トレーニング シナリオに対して、より強力な堅牢性を示します。
さらに、CAME オプティマイザーを使用して大規模な言語モデルをトレーニングすると、大規模なモデルのトレーニングのコストを大幅に削減できます。
実装方法
CAME オプティマイザーは、大規模な言語モデルの事前トレーニング タスクでトレーニング パフォーマンスの損失を引き起こすことが多い Adafactor オプティマイザーをベースに改良されています。
Adafactor の非負行列分解操作では、ディープ ニューラル ネットワークのトレーニングで必然的にエラーが発生し、これらのエラーの修正がパフォーマンス損失の原因となります。
比較すると、開始値 mt と現在の値 t の差が小さい場合、m の信頼度が高くなることがわかります。 t の方が高いです。
 写真
写真
これに触発されて、チームは新しい最適化アルゴリズムを提案しました。
下の図の青い部分は、Adafactor と比較して CAME が増加した部分です。
 図
図
CAME オプティマイザーは、モデル更新の信頼度に基づいて更新量の補正を実行し、同時に非負行列分解を実行します。導入された信頼行列に対する演算。
最終的に、CAMEはアダファクターの摂取によりアダムの効果を得る事に成功しました。
同じ効果でもリソースの半分しか消費しません
チームは CAME を使用して BERT、GPT-2、および T5 モデルをそれぞれトレーニングしました。
これまで一般的に使用されていた Adam (より良い効果) と Adafactor (より低い消費量) は、CAME パフォーマンスを測定するための基準です。
その中で、BERT の学習過程において、CAME はわずか半分のステップ数で Adafaactor と同等の精度を達成しました。
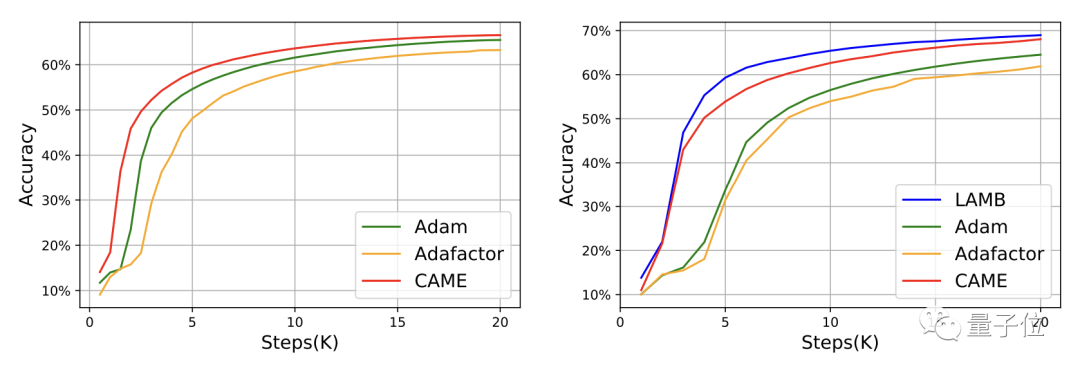 △左側が 8K スケール、右側が 32K スケール
△左側が 8K スケール、右側が 32K スケール
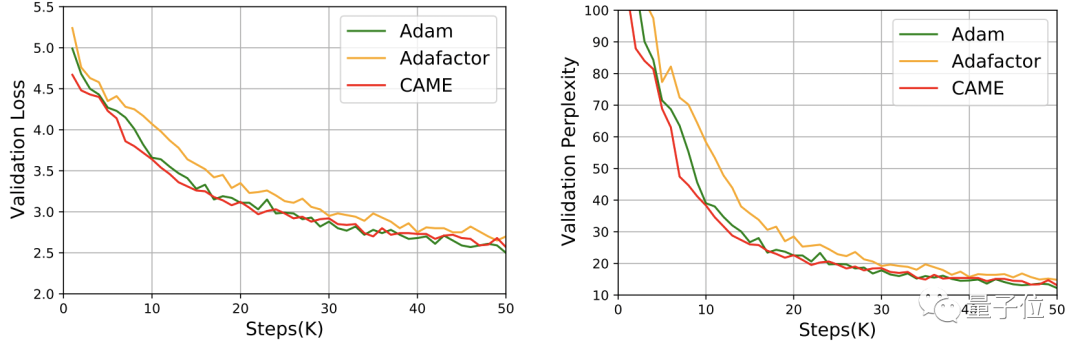
GPT-2 については、損失と混乱の観点から、CAME のパフォーマンスはアダムに非常に近いです。

T5 モデルのトレーニングでも、CAME は同様の結果を示しました。
モデルの微調整に関しては、CAME の精度のパフォーマンスはベンチマークに劣りません。
リソース消費量に関しては、PyTorch を使用して 4B データ量で BERT をトレーニングした場合、CAME によって消費されるメモリ リソースはベースラインと比較してほぼ半分に削減されました。
チームプロフィール
シンガポール国立大学の HPC-AI 研究室は、You Yang 教授が率いるハイパフォーマンス コンピューティングおよび人工知能の研究室です。
この研究室は、ハイパフォーマンス コンピューティング、機械学習システム、分散並列コンピューティングの研究と革新に取り組んでおり、大規模言語モデルなどの分野での応用を推進しています。
研究室長の You Yang は、シンガポール国立大学コンピューター サイエンス学部のプレジデンシャル ヤング プロフェッサー (プレジデンシャル ヤング プロフェッサー) です。
You Yang は、2021 年に Forbes Under 30 Elite List (Asia) に選ばれ、IEEE-CS スーパーコンピューティング優秀新人賞を受賞しました。彼の現在の研究の焦点は、大規模な深層学習トレーニング アルゴリズムの分散最適化です。 。
この記事の筆頭著者である Luo Yang は研究室の修士課程の学生で、現在は大規模モデルのトレーニングの安定性と効率的なトレーニングに重点を置いて研究しています。
紙のアドレス: https://arxiv.org/abs/2307.02047
GitHub の項目:https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/CAME
以上が大規模モデルのトレーニングにかかるコストがほぼ半分に削減されました。シンガポール国立大学の最新オプティマイザーが導入されましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。