
ホームページ >テクノロジー周辺機器 >AI >Byte チームは Lynx モデルを提案しました: マルチモーダル LLM が認知世代リスト SoTA を理解する
Byte チームは Lynx モデルを提案しました: マルチモーダル LLM が認知世代リスト SoTA を理解する

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-07-17 21:57:301481ブラウズ
GPT4 などの現在のラージ言語モデル (LLM) は、画像が与えられたオープンな命令に従う際に優れたマルチモーダル機能を示します。ただし、これらのモデルのパフォーマンスは、ネットワーク構造、トレーニング データ、トレーニング戦略の選択に大きく依存しますが、これらの選択については、以前の文献では広く議論されていませんでした。さらに、現在、これらのモデルを評価および比較するための適切なベンチマークが不足しているため、マルチモーダル LLM の開発が制限されています。
 写真
写真
- 論文: https://arxiv.org/abs/2307.02469
- ウェブサイト: https://lynx-llm.github.io/
- コード: https://github.com/bytedance/lynx-llm
この記事では、著者はそのようなモデルのトレーニングについて、定量的および定性的側面の両方から体系的かつ包括的な研究を実施します。 20 を超えるバリアントが設定されました。ネットワーク構造については、さまざまな LLM バックボーンとモデル設計が比較されました。トレーニング データについては、データとサンプリング戦略の影響が研究されました。命令に関しては、モデルに対する多様なプロンプトの影響が研究されました。指導に従う能力が探求されました。ベンチマークについては、 記事で最初に、画像タスクとビデオ タスクを含むオープン ビジュアル質問応答評価セット Open-VQA を提案しています。
実験結果に基づいて、著者は Lynx を提案しました。これは、既存のオープンソース GPT4 スタイルのモデル機能と比較して最も正確なマルチモーダルの理解を示します。最高のマルチモーダル生成機能を維持します。
評価スキーム
一般的なビジュアル言語タスクとは異なり、GPT4 スタイルのモデルを評価する際の主な課題はバランスにありますテキスト生成能力 と マルチモーダル理解精度 の 2 つの側面におけるパフォーマンス。この問題を解決するために、著者らはビデオおよび画像データを含む新しいベンチマーク Open-VQA を提案し、現在のオープンソース モデルの包括的な評価を実施します。
具体的には、次の 2 つの定量的評価スキームが採用されています。
- オープン ビジュアル質問応答 (Open-VQA) テスト セットを収集します。オブジェクト、OCR、計数、推論、動作認識、時間順序などに関するさまざまなカテゴリの質問が含まれています。標準的な回答がある VQA データ セットとは異なり、Open-VQA の回答は オープンエンド # です。 Open-VQA のパフォーマンスを評価するために、GPT4 が識別子として使用され、結果は人間の評価と 95% 一致します。
- さらに、著者は、mPLUG-owl [1] が提供する OwlEval データセットを使用して、モデルのテキスト生成能力を評価しました。これには、50 枚の画像と 82 個の質問しか含まれていませんが、ストーリーの生成、広告生成、コード生成、その他のさまざまな問題をカバーし、さまざまなモデルのパフォーマンスを採点するヒューマン アノテーターを採用します。
#結論
マルチモーダル LLM のトレーニング戦略を深く研究するために、著者は主にネットワーク構造から始めます。 (プレフィックス微調整/クロスアテンションフォース)、トレーニングデータ (データ選択と結合比率)、命令 (単一命令/多様な命令)、LLMs モデル (LLaMA [5]/Vicuna [6])、画像ピクセル (420/ 224) およびその他の側面が設定されています。20 以上のバリエーションを使用して、実験を通じて次の主な結論が導き出されています:
- #マルチモーダル LLM は、LLM よりも命令に従う能力が劣ります。 たとえば、InstructBLIP [2] は入力命令に関係なく短い応答を生成する傾向がありますが、他のモデルは命令に関係なく長い文を生成する傾向がありますが、これは著者らの考えでは不足によるものです。高レベルの応答の質と多様なマルチモーダルな指導データから得られます。
- #トレーニング データの品質は、モデルのパフォーマンスにとって非常に重要です。 さまざまなデータの実験結果に基づいて、少量の高品質データを使用した方が、大規模なノイズの多いデータを使用した場合よりもパフォーマンスが向上することがわかりました。著者は、生成トレーニングはテキストと画像の類似性ではなく、単語の条件付き分布を直接学習するため、これが生成トレーニングと対照トレーニングの違いであると考えています。したがって、モデルのパフォーマンスを向上させるには、データに関して 2 つの条件を満たす必要があります: 1) 高品質で滑らかなテキストが含まれていること、2) テキストと画像のコンテンツが適切に配置されていること。
- クエストとプロンプトはゼロショット機能にとって重要です。 多様なタスクと命令を使用すると、未知のタスクに対するモデルのゼロショット生成能力を向上させることができ、これはプレーン テキスト モデルでの観察と一致します。
- 正しさと言語生成能力のバランスを取ることが重要です。 モデルが下流タスク (VQA など) でトレーニングされていない場合は、視覚入力と一致しない捏造されたコンテンツが生成される可能性が高くなりますが、モデルが下流タスクで過剰トレーニングされている場合は、短い回答では、ユーザーの指示に従って長い回答を生成することはできません。
- Prefix-finetuning (PT) は、現在、LLM のマルチモーダル適応に最適なソリューションです。 実験では、プレフィックス微調整構造を備えたモデルは、さまざまな命令に迅速に従う能力を向上させることができ、クロスアテンション (CA) モデル構造よりもトレーニングが容易です。 (プレフィックスチューニングとクロスアテンションは 2 つのモデル構造です。詳細については、Lynx モデルの紹介セクションを参照してください)
#Lynx モデル
著者は、Lynx(lynx) - 2 段階のトレーニングを備えたプレフィックス微調整 GPT4 スタイルのモデルを提案しました。第 1 段階では、約 120M の画像とテキストのペアがビジュアルと言語の埋め込みを調整するために使用されます。第 2 段階では、20 個の画像またはビデオがマルチモーダル タスクと自然言語処理 (NLP) に使用されます。データを使用してモデルの命令追従機能を調整します。
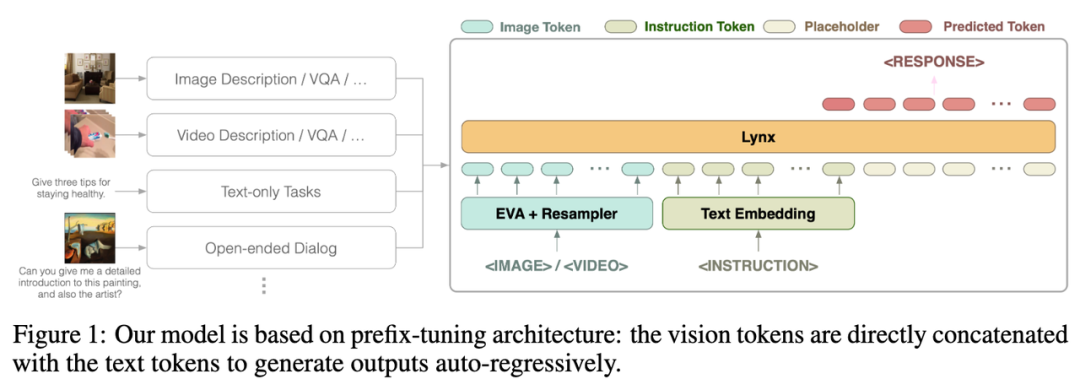 図
図
Lynx モデルの全体構造を上の図 1 に示します。
ビジュアル入力はビジュアル エンコーダーによって処理され、ビジュアル トークン (トークン) $$W_v$$ が取得され、マッピング後、命令トークン $$W_l$ と結合されます。 $ は LLM の入力として使用されます。この構造は、Flamingo [3] で使用される cross-attention 構造と区別するために、この記事では "prefix-finetuning" と呼ばれます。
さらに、著者は、凍結された LLM の特定の層の後に Adapter (アダプター) を追加することで、トレーニング コストをさらに削減できることを発見しました。
モデル効果
著者は、 Open-VQA、Mme [4] で既存のオープンソース マルチモーダル LLM モデルを評価しました。そして、OwlEval 手動評価でのパフォーマンス (結果は下のグラフに示されており、評価の詳細は論文に記載されています)。 Lynx モデルは、Open-VQA 画像およびビデオ理解タスク、OwlEval 手動評価、および Mme Perception タスクで最高のパフォーマンスを達成していることがわかります。 その中で、InstructBLIP もほとんどのタスクで高いパフォーマンスを実現しますが、その応答は短すぎます。それに比べて、Lynx モデルは、ほとんどの場合、正しい答えをサポートする簡潔な理由を提供します。 (一部のケースについては、以下の「ケース表示」セクションを参照してください)。
1. Open-VQA イメージ テスト セットのインジケーターの結果を以下の表 1 に示します。
#2. Open-VQA ビデオ テスト セットのインジケーターの結果を以下の表 2 に示します。 ###############写真######3. Open-VQA で最高スコアのモデルを選択し、OwlEval 評価セットに対して手動効果評価を実行します。結果は上の図 4 に示されています。手動評価の結果から、Lynx モデルが最高の言語生成パフォーマンスを備えていることがわかります。
 写真
写真
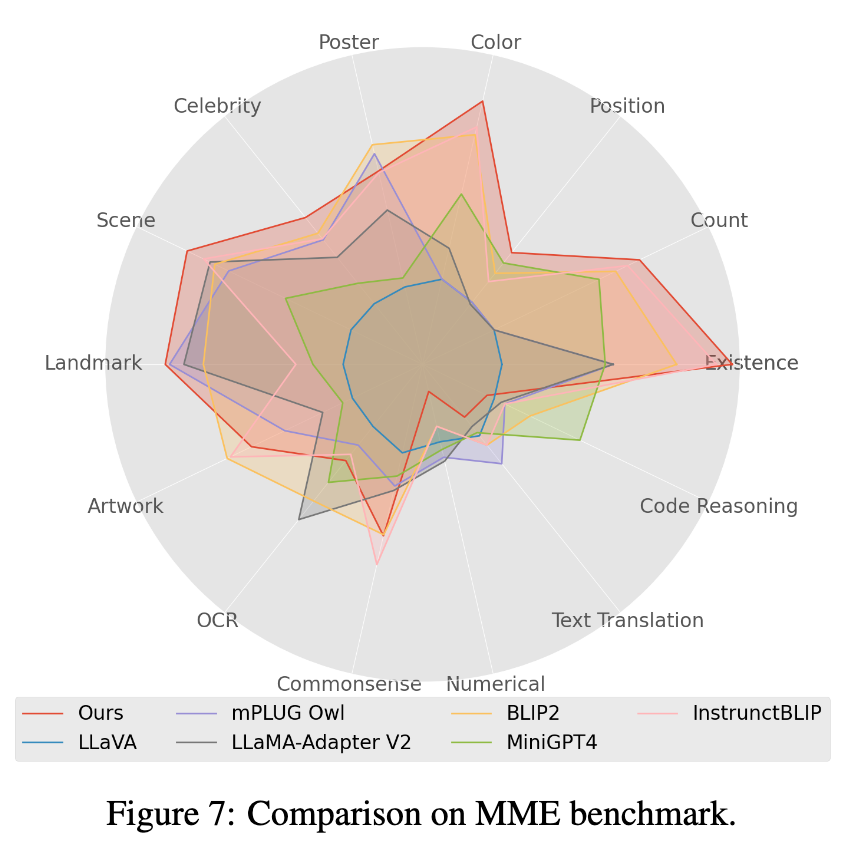
4. Mme ベンチマーク テストでは、Perception クラス タスクが最高のパフォーマンスを達成しました。 、そのうち 14 種類のサブタスクのうち 7 種類のサブタスクが最高のパフォーマンスを発揮します。 (詳細な結果については、論文の付録を参照してください)
ケースの表示
Open-VQA 画像ケース

OwlEval ケース

Open-VQA ビデオ ケース

##概要
この記事では、著者は、主な構造の Open-VQA 評価計画としてプレフィックス微調整を決定しました。 Lynx モデルと自由回答。実験結果は、Lynx モデルが最高のマルチモーダル生成機能を維持しながら、最も正確なマルチモーダル理解精度を実行することを示しています。
以上がByte チームは Lynx モデルを提案しました: マルチモーダル LLM が認知世代リスト SoTA を理解するの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。