
ホームページ >テクノロジー周辺機器 >AI >GPT-4 モデル アーキテクチャが流出: ハイブリッド エキスパート モデルを使用した 1.8 兆のパラメーターが含まれています
GPT-4 モデル アーキテクチャが流出: ハイブリッド エキスパート モデルを使用した 1.8 兆のパラメーターが含まれています

- WBOY転載
- 2023-07-16 11:53:22843ブラウズ

7月13日のニュースによると、海外メディアのセミアナリシスは最近、OpenAIが今年3月にリリースしたGPT-4大規模モデルを明らかにしました。これにはGPT-4モデルのアーキテクチャ、トレーニング、および特定のパラメータと情報(推論インフラストラクチャ、パラメータ量、トレーニング データセット、トークン数、コスト、専門家の混合モデル)。
▲ 画像ソース 半分析
外国メディアは、GPT-4 には 120 層で合計 1 兆 8000 億のパラメーターが含まれているのに対し、GPT-3 にはパラメータは約 1,750 億個しかありません。コストを合理的に保つために、OpenAI はハイブリッド エキスパート モデルを使用して を構築します。
IT ホーム 注: 専門家の混合は一種のニューラル ネットワークです。システムは、データに基づいて複数のモデルを分離してトレーニングします。各モデルの出力後、システムはこれらのモデルを 1 つの別個のタスクに統合して出力します。 。
▲ 画像ソース 半分析
GPT-4 は、それぞれ 1110 100 の 16 個の混合エキスパート モデル (専門家の混合) を使用すると報告されています。百万パラメータの場合、各フォワード パス ルートは 2 つのエキスパート モデル を通過します。
さらに、550 億の共有注意パラメーターがあり、13 兆のトークンを含むデータセットを使用してトレーニングされました。トークンは一意ではなく、反復回数に基づいてさらに多くのトークンとして計算されます。
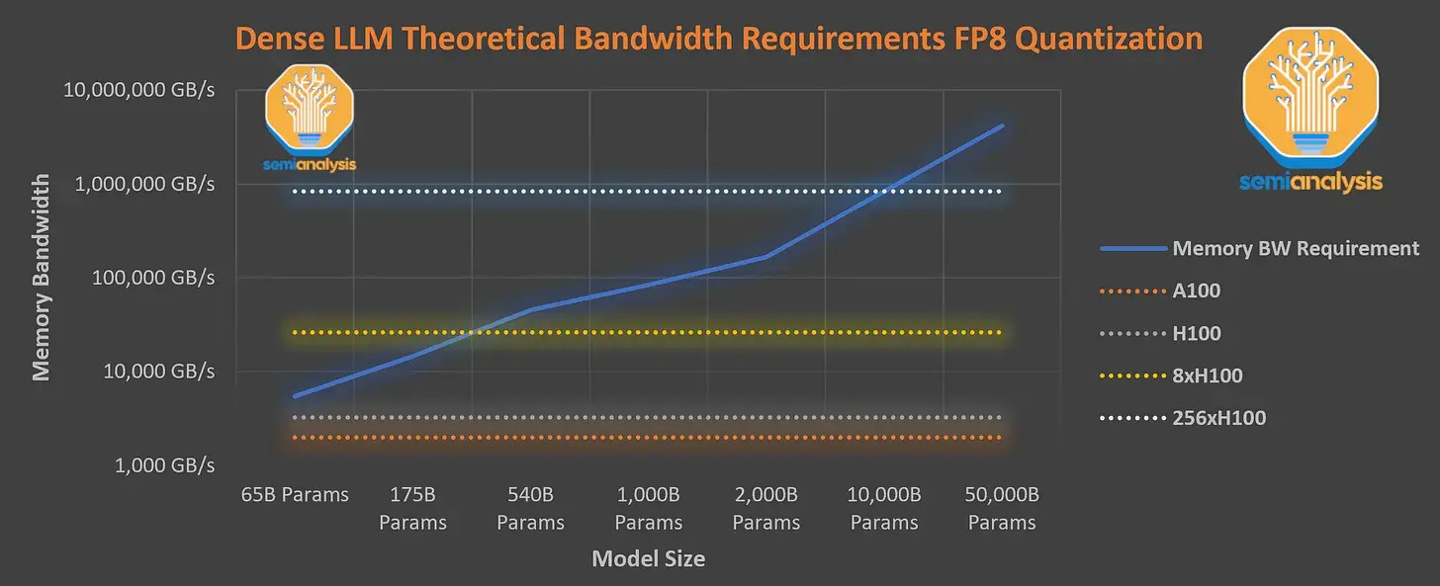
GPT-4 事前トレーニング フェーズのコンテキスト長は 8k で、32k バージョンは 8k を微調整した結果です。トレーニング コストは非常に高くなります。海外メディアは、8x H100 では不可能であると述べています。 1 秒あたり 33.33 トークンを達成します。この速度により、必要な高密度パラメーター モデル が提供されるため、モデルのトレーニングには非常に高い推論コストが必要になります。H100 物理マシンの場合、1 時間あたり 1 米ドルと計算すると、1 回のトレーニングのコストは 1 米ドルと同じくらい高くなります6,300万ドル(約4億5,100万元))。
これに関して、OpenAI は、モデルのトレーニングにクラウドの A100 GPU を使用することを選択し、少し長い時間をかけて最終的なトレーニング コストを約 2,150 万米ドル (約 1 億 5,400 万元) に削減しました。トレーニングコストを削減します。コスト。
以上がGPT-4 モデル アーキテクチャが流出: ハイブリッド エキスパート モデルを使用した 1.8 兆のパラメーターが含まれていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。