
ホームページ >テクノロジー周辺機器 >AI >コンテキスト長を 256k に拡張します。LongLLaMA の無制限コンテキスト バージョンは登場しますか?
コンテキスト長を 256k に拡張します。LongLLaMA の無制限コンテキスト バージョンは登場しますか?

- PHPz転載
- 2023-07-11 15:05:441292ブラウズ
今年 2 月、Meta は LLaMA 大規模言語モデル シリーズをリリースし、オープンソース チャット ロボットの開発を促進することに成功しました。 LLaMA は、以前にリリースされた多くの大規模モデル (パラメーターの数は 70 億から 650 億の範囲) よりもパラメーターが少ないですが、パフォーマンスが優れているためです。たとえば、650 億のパラメーターを持つ最大の LLaMA モデルは、Google の Chinchilla-70B および PaLM に匹敵します。 -540B. 、公開されると多くの研究者が興奮しました。
ただし、LLaMA は学術研究者による使用のみにライセンスされているため、モデルの商用利用は制限されています。
したがって、研究者は商業目的で使用できる LLaMA を探し始めました。カリフォルニア大学バークレー校の博士課程の学生 Hao Liu 氏が始めたプロジェクト OpenLLaMA は、最も人気のあるプロジェクトの 1 つです。 LLaMA のオープン ソース コピー。元の LLaMA とまったく同じ前処理とトレーニング ハイパーパラメータを使用することで、OpenLLaMA は LLaMA のトレーニング ステップに完全に従っていると言えます。最も重要なのは、このモデルが市販されているということです。
OpenLLaMA は Together によってリリースされた RedPajama データ セットでトレーニングされました。3 つのモデル バージョン、つまり 3B、7B、13B があります。これらのモデルは 1T トークンでトレーニングされています。結果は、OpenLLaMA のパフォーマンスが、複数のタスクにおいて元の LLaMA のパフォーマンスと同等かそれを上回ることを示しています。
研究者は、新しいモデルを継続的にリリースすることに加えて、トークンを処理するモデルの能力を常に調査しています。
数日前、Tian Yuandong チームによる最新の研究により、1000 ステップ未満の微調整で LLaMA コンテキストが 32K まで拡張されました。さらに遡ると、GPT-4 は 32,000 のトークン (50 ページのテキストに相当) をサポートし、クロードは 100,000 のトークン (ワンクリックで「ハリー・ポッター」の最初の部分を要約するのにほぼ相当) を処理できます。
OpenLLaMA に基づく新しい大規模言語モデルが登場し、コンテキストの長さが 256,000 トークン以上に拡張されます。この研究は、IDEAS NCBR、ポーランド科学アカデミー、ワルシャワ大学、Google DeepMind によって共同で完了しました。
 写真
写真
LongLLaMA は OpenLLaMA をベースに完成しており、微調整方法には FOT (Focused Transformer) が使用されています。この論文では、FOT を使用して既存の大規模モデルを微調整し、コンテキストの長さを延長できることを示します。
この研究では、OpenLLaMA-3B モデルと OpenLLaMA-7B モデルを開始点として使用し、FOT を使用してそれらを微調整します。 LONGLLAMA と呼ばれる結果のモデルは、トレーニング コンテキストの長さを超えて (最大 256K まで) 外挿することができ、コンテキストの短いタスクでもパフォーマンスを維持できます。
- プロジェクト アドレス: https://github.com/CStanKonrad/long_llama
- 論文アドレス: https://arxiv. org/pdf/2307.03170.pdf
この研究を OpenLLaMA の無限コンテキスト バージョンと表現する人もいます。FOT を使用すると、モデルは次のようなより長いシーケンスに簡単に外挿できます。 8K トークンでトレーニングされたモデルは、256K ウィンドウ サイズに簡単に外挿できます。
 図
図
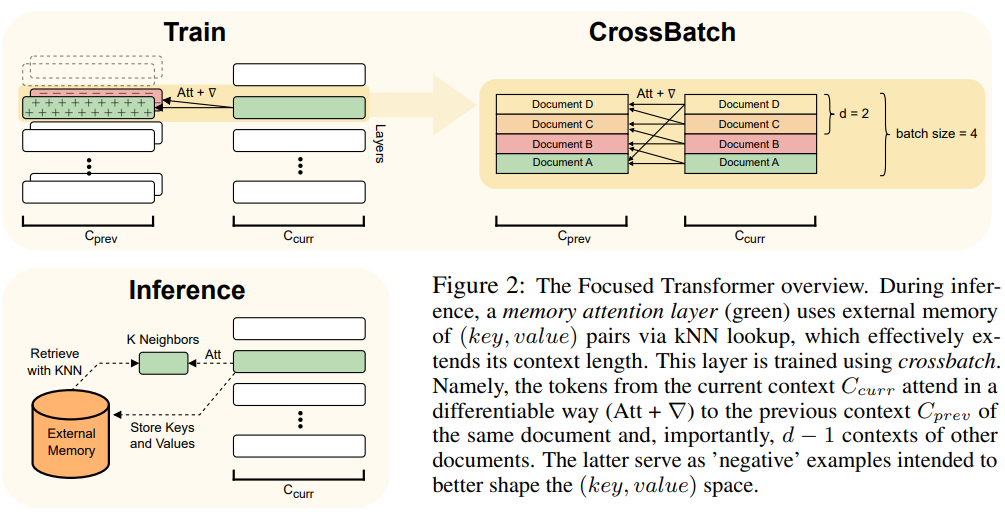
この記事では、Transformer モデルのプラグ アンド プレイ拡張機能である FOT メソッドを使用します。新しいモデルをトレーニングしたり、より長いコンテキストを使用して既存の大きなモデルを微調整したりできます。
これを実現するために、FOT はメモリ アテンション レイヤーとクロスバッチ トレーニング プロセスを使用します。
- メモリ アテンション レイヤーにより、次のことが可能になります。モデルは推論時に外部メモリから情報を取得し、コンテキストを効果的に拡張します。
- クロスバッチ トレーニング プロセスにより、モデルは (key, value ) 表現、これらの表現を学習する傾向があります。メモリ アテンション レイヤーとしては非常に使いやすいです。
#FOT アーキテクチャの概要については、図 2 を参照してください:
 図
図
次の表は、LongLLaMA のモデル情報の一部を示しています:
 写真
写真
最後に、このプロジェクトは LongLLaMA も提供します。元の OpenLLaMA モデルの比較結果。
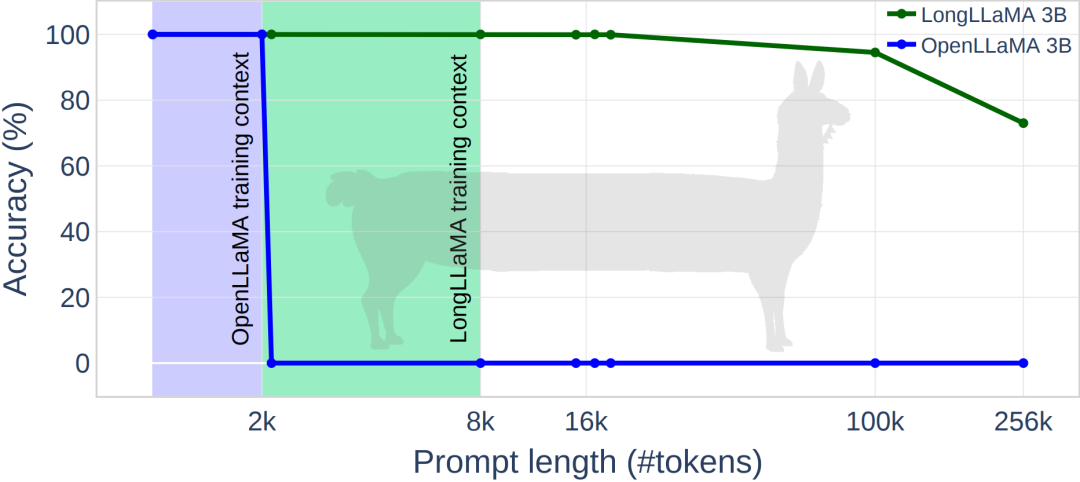
次の図は、LongLLaMA の実験結果を示しています。パスワード検索タスクでは、LongLLaMA は良好なパフォーマンスを達成しました。具体的には、LongLLaMA 3B モデルはトレーニング コンテキストの長さ 8K をはるかに超え、100k トークンに対して 94.5% の精度、256k トークンに対して 73% の精度を達成しました。
 図
図
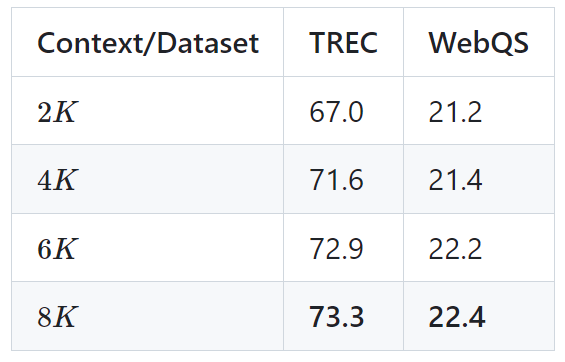
次の表は、2 つの下流タスク (TREC 質問分類と WebQS 質問) における LongLLaMA 3B モデルのパフォーマンスを示しています。回答)その結果、長いコンテキストを使用すると LongLLaMA のパフォーマンスが大幅に向上することがわかりました。
 図
図
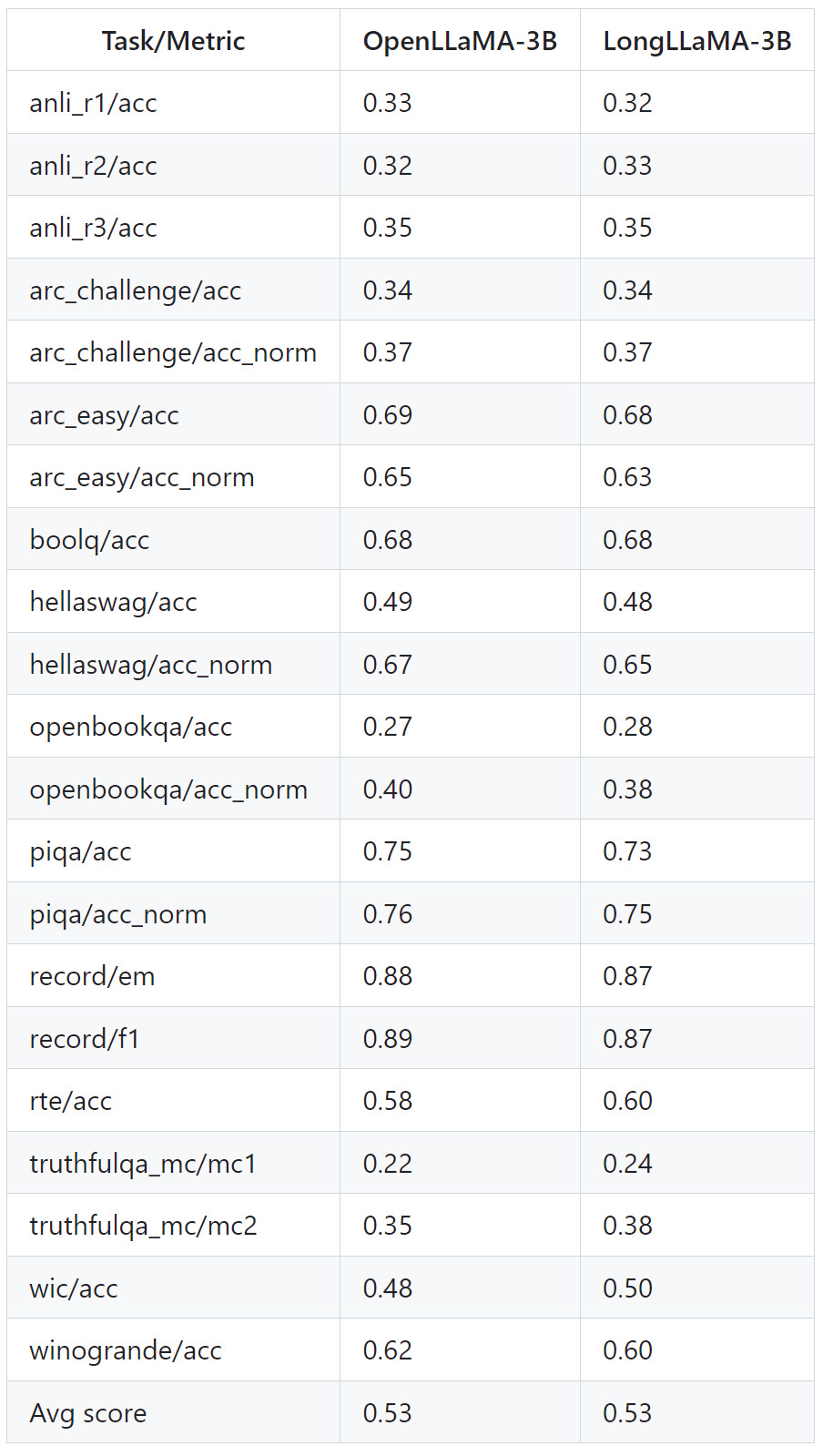
下の表は、長いコンテキストを必要としないタスクでも LongLLaMA が良好にパフォーマンスすることを示しています。実験では、ゼロサンプル設定で LongLLaMA と OpenLLaMA を比較します。
 写真
写真
詳細については、元の論文とプロジェクトを参照してください。
以上がコンテキスト長を 256k に拡張します。LongLLaMA の無制限コンテキスト バージョンは登場しますか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。