
ホームページ >テクノロジー周辺機器 >AI >AI の新たな出口?最初の高品質「Vinson Video」モデル Zeroscope がオープンソース戦争を引き起こす: 最小 8G ビデオ メモリで実行可能
AI の新たな出口?最初の高品質「Vinson Video」モデル Zeroscope がオープンソース戦争を引き起こす: 最小 8G ビデオ メモリで実行可能

- 王林転載
- 2023-07-09 23:17:201311ブラウズ
Stable Diffusion オープンソース グラフ モデルの後、「AI アート」は完全に民主化され、非常に美しい画像を作成するにはコンシューマー グレードのグラフィック カードのみを使用できます。
テキストからビデオへの変換の分野では、現在、オープンで競争できる唯一のモデルは、Runway が最近発売した高品質商用 Gen-2 モデルだけです。ソース業界。
最近、Huggingface の作者がテキストからビデオへの合成モデル Zeroscope_v2 をリリースしました。これは、17 億個のパラメーターを備えた ModelScope テキストからビデオへの合成モデルに基づいて開発されました。 。
 #写真
#写真
モデルリンク: https://huggingface.co/cerspense/zeroscope_v2_576w
オリジナル バージョンと比較して、Zeroscope によって生成されたビデオには透かしがなく、16:9 のアスペクト比に適応するために滑らかさと解像度が向上しました。
開発者のサースペンス氏は、オープンソースとして Gen-2 と競合することが目標だと述べました。つまり、モデルの品質を向上させながら、一般人が自由に使用できるようにすることです。 。
Zerscope_v2 には 2 つのバージョンがあり、そのうちの Zeroscope_v2 567w は、解像度 576x320 ピクセル、フレームレート 30 フレーム/秒のビデオを迅速に生成でき、迅速な検証に使用できます。ビデオのコンセプトを採用しており、7.9GB のビデオ メモリのみで実行できます。
Zeroscope_v2 XL を使用して、解像度 1024x576 の高解像度ビデオを生成し、約 15.3 GB のビデオ メモリを占有します。
Zeroscope を音楽生成ツール MusicGen と併用して、純粋にオリジナルのショート ビデオをすばやく作成することもできます。
Zeroscope モデルのトレーニングでは、9923 個のビデオ クリップ (クリップ) と 29769 個の注釈付きフレーム (各クリップには 24 フレームが含まれています) が使用されました。オフセット ノイズには、ビデオ フレーム内のオブジェクトのランダムなシフト、フレーム タイミングのわずかな変化、または小さな歪みが含まれます。
トレーニング中にノイズを導入すると、モデルによるデータ分布の理解が深まり、より多様でリアルなビデオを生成し、テキストの説明の変化をより効果的に考慮できるようになります。
利用方法安定拡散ウェブUIを使用
Huggingface内zs2_XL ディレクトリにあるウェイト ファイルをダウンロードし、stable-diffusion-webui\models\ModelScope\t2v ディレクトリに置きます。
ビデオを生成する場合、推奨されるノイズ リダクション強度の値は 0.66 ~ 0.85 です。
Colab を使用します
まず、ステップ 1 で [実行] ボタンをクリックし、インストールが完了するまで待ちます (約 3 分かかります);
図 
#画像
 #約のクリップをすばやく取得するには、インストールするモデルの近くにある実行ボタンをクリックします。 Colab で 3 秒 ビデオの場合は、低解像度の ZeroScope モデル (576 または 448) を使用することをお勧めします。
#約のクリップをすばやく取得するには、インストールするモデルの近くにある実行ボタンをクリックします。 Colab で 3 秒 ビデオの場合は、低解像度の ZeroScope モデル (576 または 448) を使用することをお勧めします。
写真
 Potat 1 や ZeroScope XL などの高解像度モデルを実行する場合、実行時間にはトレードオフがあります。より長いです。
Potat 1 や ZeroScope XL などの高解像度モデルを実行する場合、実行時間にはトレードオフがあります。より長いです。
チェック マークが再び表示されるまで待って、次の手順に進みます。
ステップ 2 でインストールしたモデルを選択し、それを使用します。高解像度のモデルの場合は、生成時間があまり長くかからない次の構成パラメーターをお勧めします。
画像
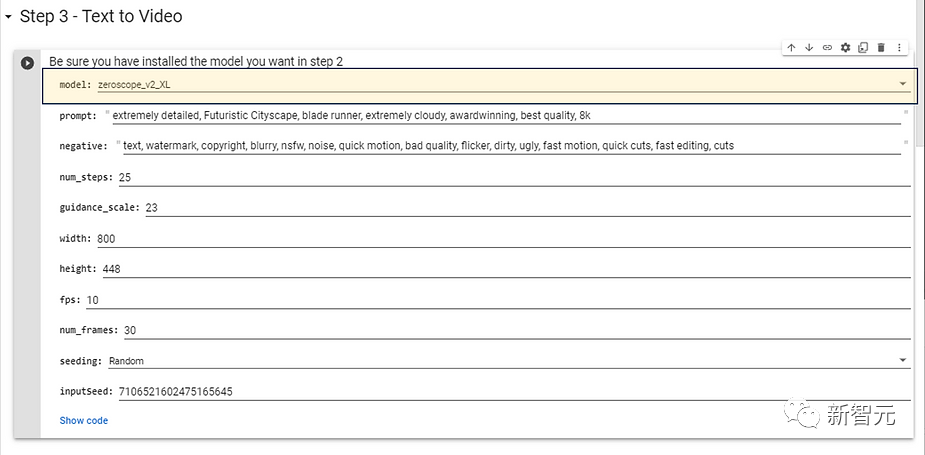 次に、ターゲットビデオのプロンプトワードを入力して効果を変更できます。また、次のように入力することもできます。否定的なプロンプトの単語 (否定的なプロンプト) を入力し、[実行] ボタンをクリックします。
次に、ターゲットビデオのプロンプトワードを入力して効果を変更できます。また、次のように入力することもできます。否定的なプロンプトの単語 (否定的なプロンプト) を入力し、[実行] ボタンをクリックします。
しばらく待つと、生成されたビデオが出力ディレクトリに配置されます。 ###############写真######
「文生動画」オープン ソース コンペティション
現在、Vincentian ビデオの分野はまだ初期段階にあります。最高のツールでも数秒のビデオしか生成できず、通常は比較的多くのビデオが生成されます。大 大きな視覚的欠陥。
しかし実際には、Vincentian モデルも当初は同様の問題に直面していましたが、わずか数か月後にはフォトリアリズムを実現しました。
ただし、ヴィンセント グラフ モデルとは異なり、ビデオ フィールドではトレーニングと生成中に画像よりも多くのリソースが必要になります。
Google は、高解像度で、より長く、論理的に一貫したビデオ クリップを生成できる Phenaki モデルと Imagen Video モデルを開発しましたが、これら 2 つのモデルは一般公開されていません。 a-Videoモデルも発売されていません。
現在利用可能なツールはまだ Runway の商用モデル Gen-2 のみです。Zeroscope のリリースは、Vincent ビデオ分野における最初の高品質のオープンソース モデルの出現も示しています。
以上がAI の新たな出口?最初の高品質「Vinson Video」モデル Zeroscope がオープンソース戦争を引き起こす: 最小 8G ビデオ メモリで実行可能の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。