



近年、画像生成の分野、特にテキストから画像への生成において大きな進歩が見られます。テキストを使用して考えを説明する限り、AI は斬新でリアルな画像を生成できます。
しかし、実際にはさらに一歩進めることができます。心の中の考えをテキストに変換するステップを省略し、脳活動 (EEG (脳波) 記録など) を通じて直接制御することができます。 ) 画像の生成的作成。
この「思考からイメージへ」生成方法には、幅広い応用の可能性があります。たとえば、芸術創作の効率が大幅に向上し、人々が一瞬のインスピレーションを捉えるのに役立ち、夜間に人々の夢を視覚化することも可能になる可能性があり、自閉症の子供や言語障害の患者を助けるための心理療法にも使用される可能性があります。
最近、清華大学深セン国際大学院、テンセント AI 研究所、彭城研究所の研究者が共同で、訓練されたデータの強力な生成機能を使用して「イメージへの思考」に関する研究論文を発表しました。テキストから画像へのモデル (安定拡散など) は、EEG 信号から直接高品質の画像を生成します。
 写真
写真
論文アドレス: https://arxiv.org/pdf/2306.16934.pdf
プロジェクトのアドレス: https://github.com/bbaaii/DreamDiffusion
メソッドの概要
最近の関連研究(例: MinD-Vis) は、fMRI (機能的磁気共鳴画像信号) に基づいて視覚情報を再構築しようと試みます。彼らは、脳の活動を使用して高品質の結果を再構築する実現可能性を実証しました。しかし、これらの方法は、脳信号を迅速かつ効率的に作成するための理想的な利用にはまだ程遠いです。これは主に 2 つの理由によるものです:
第一に、fMRI 装置は持ち運びができず、それが必要です。専門家によって操作されているため、fMRI 信号を捕捉するのは困難です;
第 2 に、fMRI データ収集のコストが高く、実際の芸術作品制作でこの方法を使用するのに大きな障害となります。 . .
対照的に、EEG は脳の電気活動を記録する非侵襲的で低コストの方法であり、現在、EEG 信号を取得できるポータブルな市販製品が市販されています。
しかし、「思考からイメージへ」の生成を実現するには、依然として 2 つの主要な課題があります。
1) EEG 信号は、次の方法によって生成されます。非侵襲的な方法で捕獲するため、騒音が発生します。また、脳波データには限界があり、個人差も無視できません。では、非常に多くの制約の下で、EEG 信号から効果的で堅牢な意味表現を取得するにはどうすればよいでしょうか?
2) 安定拡散のテキストと画像の空間は、CLIP の使用と多数のテキストと画像のペアでのトレーニングにより、適切に位置合わせされています。しかし、脳波信号には独自の特性があり、その空間はテキストや画像とは大きく異なります。限られたノイズのある脳波と画像のペア上で脳波、テキスト、画像の空間をどのように調整するか?
最初の課題に対処するために、この研究では、まれな EEG 画像ペアだけではなく、大量の EEG データを使用して EEG 表現をトレーニングすることを提案します。この研究では、マスクされた信号モデリング手法を使用して、文脈上の手がかりに基づいて欠落トークンを予測します。
入力を 2 次元画像として扱い、空間情報をマスクする MAE や MinD-Vis とは異なり、この研究では脳波信号の時間的特性を考慮し、EEG 信号の時間特性をより深く掘り下げます。人間の脳の意味論の時間的変化。この研究では、トークンの一部をランダムにブロックし、ブロックされたトークンを時間領域で再構築しました。このようにして、事前トレーニングされたエンコーダーは、さまざまな個人およびさまざまな脳活動からの EEG データを深く理解することができます。
2 番目の課題については、以前のソリューションでは通常、トレーニングに少数のノイズの多いデータ ペアを使用して、安定拡散モデルを直接微調整していました。ただし、最終的な画像再構成損失を考慮して SD をエンドツーエンドで微調整するだけでは、脳信号 (EEG や fMRI など) とテキスト空間の間の正確な位置合わせを学習することは困難です。したがって、研究チームは、EEG、テキスト、および画像空間の位置合わせを実現するために、追加の CLIP 監視を使用することを提案しました。
具体的には、SD 自体は CLIP のテキスト エンコーダーを使用してテキスト エンコーダを生成します。これは、前段階のマスクされた事前トレーニングされた EEG エンベディングとは大きく異なります。 CLIP の画像エンコーダを活用して、CLIP のテキスト埋め込みと適切に調整された豊富な画像埋め込みを抽出します。これらの CLIP 画像埋め込みは、EEG 埋め込み表現をさらに改良するために使用されました。したがって、改良された EEG 特徴埋め込みは CLIP の画像およびテキスト埋め込みとよく調整でき、SD 画像生成により適しており、それによって生成される画像の品質が向上します。
上記の 2 つの慎重に設計されたソリューションに基づいて、この研究では新しい手法 DreamDiffusion を提案します。 DreamDiffusion は、脳波 (EEG) 信号から高品質でリアルな画像を生成します。
 写真
写真
具体的には、DreamDiffusion は主に 3 つの部分で構成されます。
1 ) 信号の事前トレーニングをマスクして、効果的で堅牢な EEG エンコーダを実現します。
#2) 微調整には、事前トレーニングされた安定拡散と限定された EEG 画像ペアを使用します。
3) CLIP エンコーダを使用して、EEG、テキスト、画像スペースを調整します。
まず、研究者らはノイズの多いEEGデータを使用し、マスク信号モデリングを使用し、EEGエンコーダーをトレーニングして、文脈上の知識を抽出しました。結果として得られる EEG エンコーダは、クロスアテンション メカニズムを介して安定拡散の条件付き機能を提供するために使用されます。
 写真
写真
#EEG 機能と安定拡散の互換性を強化するために、研究者らは、EEG の埋め込みをさらに削減しました。微調整プロセス CLIP 画像埋め込みからの距離により、EEG、テキスト、画像の埋め込みスペースがさらに調整されます。
実験と分析
Brain2Imageとの比較
研究者による比較Brain2Image を使用したこの記事の方法。 Brain2Image は、EEG から画像への変換に、従来の生成モデル、つまり変分オートエンコーダー (VAE) と敵対的生成ネットワーク (GAN) を使用します。ただし、Brain2Image はいくつかのカテゴリの結果のみを提供し、リファレンス実装は提供しません。
これを念頭に置いて、この研究では、Brain2Image 論文に示されているいくつかのカテゴリ (つまり、飛行機、ジャック・オ・ランタン、パンダ) の定性的比較を実行しました。公平な比較を確保するために、研究者らは Brain2Image 論文で説明されているのと同じ評価戦略を使用し、さまざまな方法で生成された結果を以下の図 5 に示しています。
以下の図の最初の行は Brain2Image によって生成された結果を示し、最後の行は研究者が提案した手法である DreamDiffusion によって生成された結果を示しています。 DreamDiffusion によって生成された画像品質は、Brain2Image によって生成された画像品質よりも大幅に高いことがわかり、この方法の有効性も検証されています。
 #写真
#写真
アブレーション実験
# #事前トレーニングの役割: 大規模なEEGデータの事前トレーニングの有効性を証明するために、この研究では未訓練のエンコーダーを使用して検証用に複数のモデルをトレーニングしました。モデルの 1 つは完全なモデルと同一でしたが、もう 1 つのモデルにはデータの過剰適合を避けるために 2 つの EEG コーディング層しかありませんでした。トレーニング プロセス中、2 つのモデルは CLIP 監視の有無にかかわらずトレーニングされ、その結果が表 1 のモデルの列 1 ~ 4 に示されています。事前トレーニングなしのモデルの精度が低下していることがわかります。
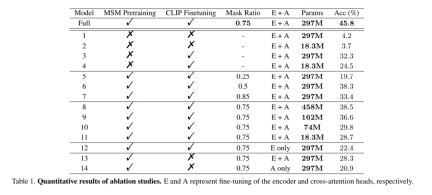
マスク率: この記事では、最適な MSM を決定するための EEG データの使用についても研究します。トレーニング前のマスク率。表 1 のモデルの列 5 ~ 7 に示されているように、マスク率が高すぎるか低すぎると、モデルのパフォーマンスに悪影響を及ぼす可能性があります。マスク率が 0.75 の場合、総合精度が最も高くなります。この発見は、通常低いマスク比を使用する自然言語処理とは異なり、EEG で MSM を実行する場合は高いマスク比がより良い選択であることを示唆しているため、非常に重要です。
CLIP アライメント: このアプローチの鍵の 1 つは、CLIP エンコーダを介した画像に対する EEG 表現のアライメントです。本研究では、この手法の有効性を検証するために実験を行ったので、その結果を表1に示します。 CLIP 監視が使用されていない場合、モデルのパフォーマンスが大幅に低下することがわかります。実際、図 6 の右下隅に示すように、CLIP を使用して EEG 特徴を位置合わせすると、事前トレーニングがなくても妥当な結果が得られます。このことは、この方法における CLIP 監視の重要性を強調しています。 ###############写真######
以上が脳内の映像を高解像度で復元できるようになりましたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM
迅速なエンジニアリングにおける思考のグラフは何ですかApr 13, 2025 am 11:53 AM導入 迅速なエンジニアリングでは、「思考のグラフ」とは、グラフ理論を使用してAIの推論プロセスを構造化および導く新しいアプローチを指します。しばしば線形sを含む従来の方法とは異なります
 Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM
Genaiエージェントとの電子メールマーケティングを組織に最適化しますApr 13, 2025 am 11:44 AM導入 おめでとう!あなたは成功したビジネスを運営しています。ウェブページ、ソーシャルメディアキャンペーン、ウェビナー、会議、無料リソース、その他のソースを通じて、毎日5000の電子メールIDを収集します。次の明白なステップはです
 Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM
Apache Pinotによるリアルタイムアプリのパフォーマンス監視Apr 13, 2025 am 11:40 AM導入 今日のペースの速いソフトウェア開発環境では、最適なアプリケーションパフォーマンスが重要です。応答時間、エラーレート、リソース利用などのリアルタイムメトリックを監視することで、メインに役立ちます
 ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM
ChatGptは10億人のユーザーにヒットしますか? 「わずか数週間で2倍になりました」とOpenai CEOは言いますApr 13, 2025 am 11:23 AM「ユーザーは何人いますか?」彼は突き出した。 「私たちが最後に言ったのは毎週5億人のアクティブであり、非常に急速に成長していると思います」とアルトマンは答えました。 「わずか数週間で2倍になったと言った」とアンダーソンは続けた。 「私はそのprivと言いました
 PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM
PIXTRAL -12B:Mistral AI'の最初のマルチモーダルモデル-Analytics VidhyaApr 13, 2025 am 11:20 AM導入 Mistralは、最初のマルチモーダルモデル、つまりPixtral-12B-2409をリリースしました。このモデルは、Mistralの120億個のパラメーターであるNemo 12bに基づいて構築されています。このモデルを際立たせるものは何ですか?これで、画像とTexの両方を採用できます
 生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AM
生成AIアプリケーションのエージェントフレームワーク - 分析VidhyaApr 13, 2025 am 11:13 AMクエリに応答するだけでなく、情報を自律的に収集し、タスクを実行し、テキスト、画像、コードなどの複数のタイプのデータを処理するAIを搭載したアシスタントがいることを想像してください。未来的に聞こえますか?これでa
 金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM
金融セクターにおける生成AIの応用Apr 13, 2025 am 11:12 AM導入 金融業界は、効率的な取引と信用の可用性を促進することにより経済成長を促進するため、あらゆる国の発展の基礎となっています。取引の容易さとクレジット
 オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM
オンライン学習とパッシブアグレッシブアルゴリズムのガイドApr 13, 2025 am 11:09 AM導入 データは、ソーシャルメディア、金融取引、eコマースプラットフォームなどのソースから前例のないレートで生成されています。この連続的な情報ストリームを処理することは課題ですが、


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

メモ帳++7.3.1
使いやすく無料のコードエディター

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

