
ホームページ >テクノロジー周辺機器 >AI >サーバーは過密、北京大学の大規模法モデルChatLawは人気:張三がどのように判決されたかを直接教えてください
サーバーは過密、北京大学の大規模法モデルChatLawは人気:張三がどのように判決されたかを直接教えてください

- PHPz転載
- 2023-07-05 09:21:161479ブラウズ
大型模型が再び「爆発」した。
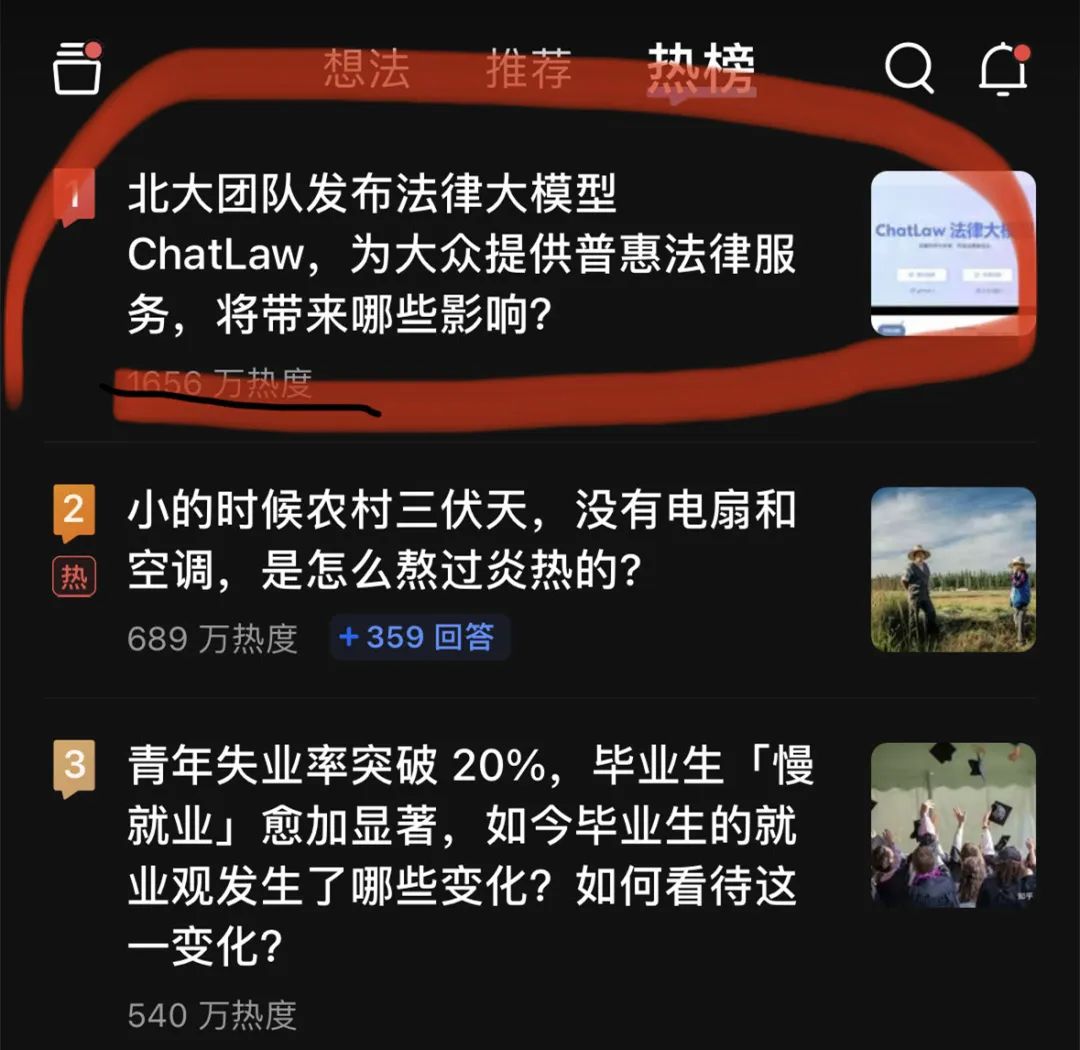
昨夜、大手法律モデル ChatLaw が Zhihu のホット検索リストのトップになりました。最盛期には人気は約2000万人に達した。
この ChatLaw は北京大学チームによってリリースされ、包括的な法律サービスを提供することに尽力しています。現在、全国的に弁護士が不足しており、その供給が法的需要をはるかに下回っている一方で、一般の人々は法律知識や法的規定において当然の格差があり、法律を活用することができません。自分を守るための合法的な武器。
最近の大規模な言語モデルの台頭により、一般の人々が法律関連の問題について会話形式で相談できる素晴らしい機会が提供されています。
#現在、ChatLaw には次の 3 つのバージョンがあります:
- ##ChatLaw-13Bはアカデミック デモ バージョンであり、Jiang Ziya Ziya-LLaMA-13B-v1 に基づいてトレーニングされており、中国語で非常に優れたパフォーマンスを発揮します。ただし、複雑な論理的法律問答の効果は良くなく、これを解決するにはより大きなパラメータを持つモデルを使用する必要があります;
- ChatLaw-33B (これも学術デモ版) 、 Anima-33B に基づいて訓練されており、論理的推論能力が大幅に向上します。ただし、Anima には中国語のコーパスが少なすぎるため、英語のデータが Q&A に頻繁に表示されます。
- ChatLaw-Text2Vec は 930,000 件の判定ケースからなるデータセットを使用し、BERT に基づいて同様のモデルをトレーニングしました。学位照合モデルは、ユーザーの質問情報と対応する法的規定を照合できます。
#写真
 公式ウェブサイトアドレス: https://www.chatlaw.cloud/
公式ウェブサイトアドレス: https://www.chatlaw.cloud/
論文アドレス: https://arxiv.org/pdf/2306.16092.pdf
これは GitHub プロジェクトのリンクです: https://github.com/PKU-YuanGroup /ChatLaw
現在、ChatLaw プロジェクトの人気により、サーバーが一時的にクラッシュし、計算能力が上限に達しています。チームは修正に取り組んでおり、興味のある読者は GitHub でベータ モデルをデプロイできます。
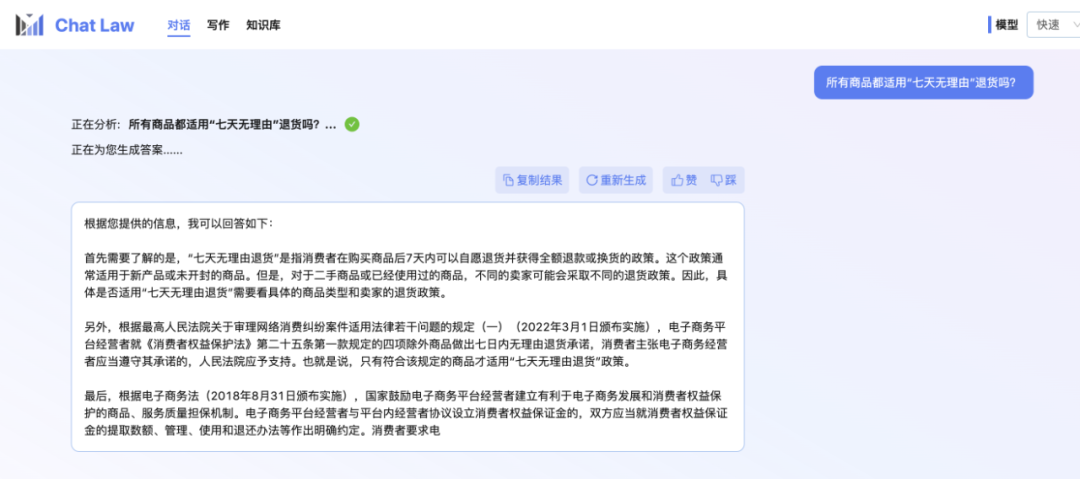
編集者自身はまだ内部テストの待機中です。そこで、オンラインショッピングで遭遇する可能性のある「7日間の理由なし返品」問題について、ChatLawチームが提供した公式の会話例を紹介します。 ChatLaw の回答は非常に包括的であると言わざるを得ません。
写真
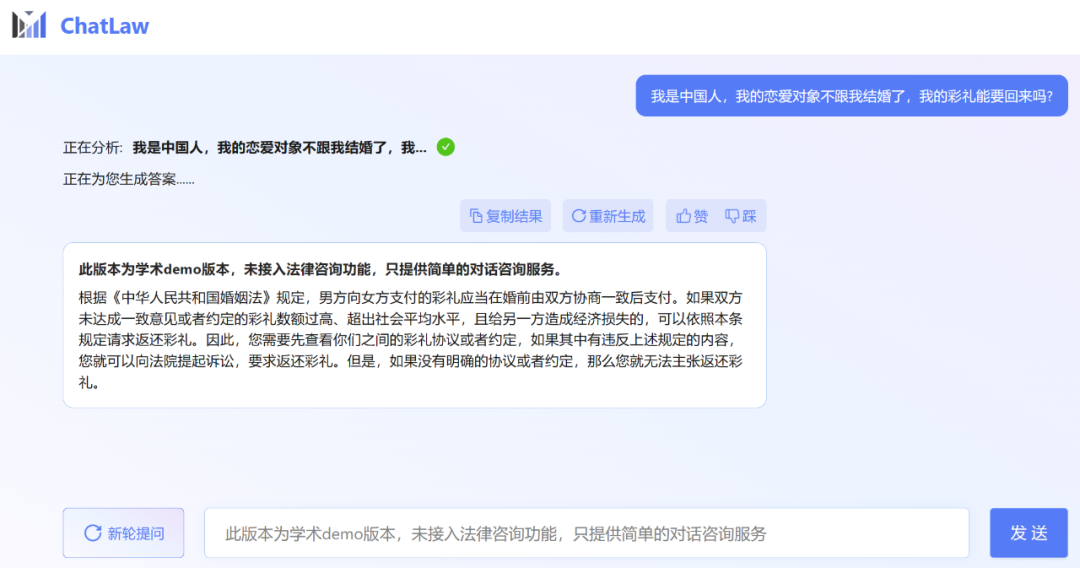
 ただし、編集者は、ChatLaw のアカデミック デモ バージョンを試用できることを発見しましたが、残念ながら試用できません。法律相談機能は利用できませんが、簡易な対話相談サービスのみを提供します。ここでいくつかの質問を試してみましょう。
ただし、編集者は、ChatLaw のアカデミック デモ バージョンを試用できることを発見しましたが、残念ながら試用できません。法律相談機能は利用できませんが、簡易な対話相談サービスのみを提供します。ここでいくつかの質問を試してみましょう。
写真
##実は、最近リリースされたのは北京大学だけではありません。大型の法的モデル。先月末、Power Law IntelligenceとZhipu AIは、1000億パラメータレベルの法的垂直モデルPowerLawGLMをリリースした。このモデルは、中国の法的シナリオへの適用効果において独自の利点を示したと報告されています。 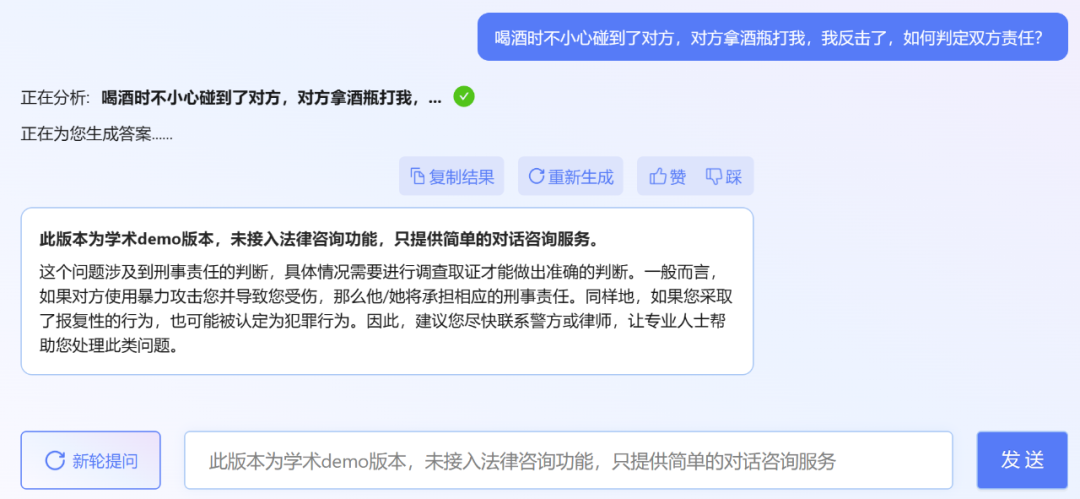
ChatLaw のデータ ソースとトレーニング フレームワーク
最初は データ構成
です。 ChatLawのデータは、主にフォーラム、ニュース、法律条文、司法解釈、法律相談、法律試験問題、判決文などから構成され、クリーニングやデータ強化などを経て会話データが構築されます。同時に、ChatLaw チームは、北京大学国際法学院や業界の著名な法律事務所と協力することで、データの専門性と信頼性を確保しながら、知識ベースをタイムリーに更新できるようにしています。以下に具体的な例を見てみましょう。法令および司法解釈に基づく施工例:
実際の法律相談データの取得例:

司法試験用の多肢選択問題の作成例:
 写真
写真
次にモデル レベルです。 ChatLAWをトレーニングするために、研究チームはZiya-LLaMA-13Bに基づく低ランク適応(LoRA)を使用してChatLAWを微調整しました。さらに、この研究では、モデル幻覚の問題を軽減するための自己暗示の役割も導入しています。トレーニング プロセスは複数の A100 GPU で実行され、ディープスピードによりトレーニング コストがさらに削減されます。
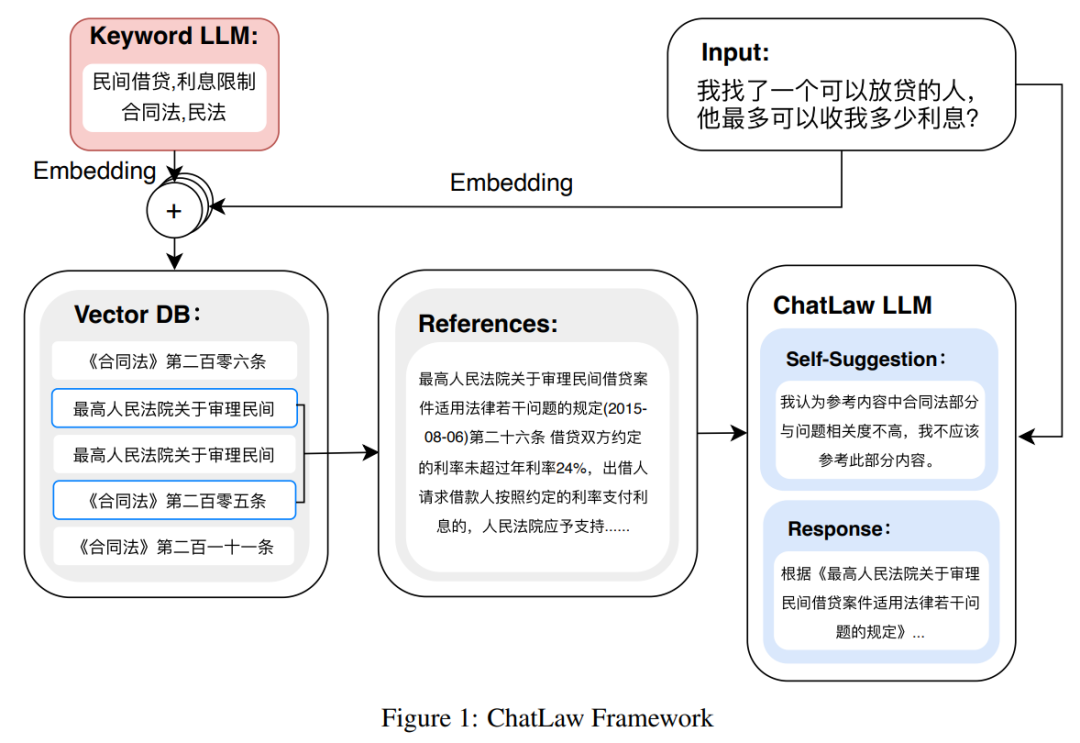
次の図は ChatLAW のアーキテクチャ図です。この研究では、モデルに法律データを注入し、特別な処理を実行して知識を強化すると同時に、複数のモジュールも導入しています。推論中に、一般モデル、専門モデル、知識ベースを統合します。
この研究では、モデルが正しい法則を生成し、モデルの錯覚を可能な限り減らすことができるように、推論中にモデルにも制約を加えました。
 写真
写真
当初、研究チームは、検索に MySQL や Elasticsearch を使用するなど、従来のソフトウェア開発方法を試しましたが、結果は一貫性がありませんでした。予想通りでした。そこで、この研究では、埋め込み用の BERT モデルを事前トレーニングし、Faiss などの手法を使用してコサイン類似度を計算し、ユーザー クエリに関連する上位 k 件の法規制を抽出することから始めました。
ユーザーの質問が不明瞭な場合、このアプローチでは最適とはいえない結果が生じることがよくあります。したがって、研究者はユーザーのクエリから重要な情報を抽出し、この情報のベクトル埋め込みを使用してアルゴリズムを設計して、マッチングの精度を向上させます。
大規模なモデルはユーザー クエリを理解する上で大きな利点があるため、この研究ではユーザー クエリからキーワードを抽出するために LLM を微調整しました。複数のキーワードを取得した後、研究ではアルゴリズム 1 を使用して関連する法的条項を検索しました。
 写真
写真
実験結果
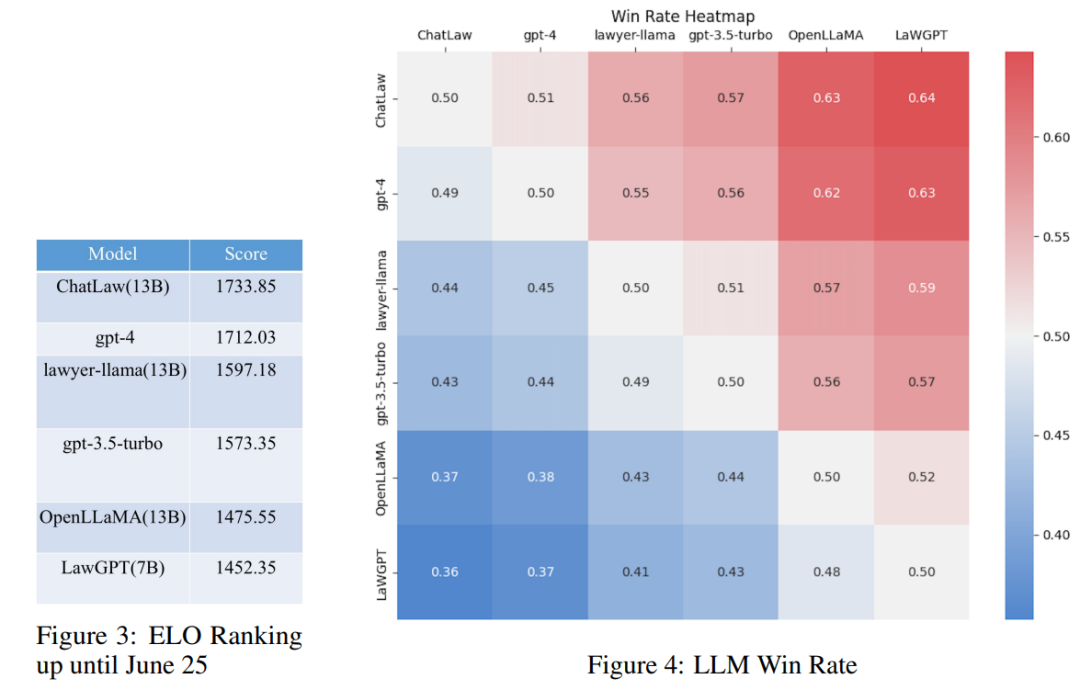
この研究では、10 年以上にわたる研究結果が収集されました。司法国家試験の問題については、法的な多肢選択問題を処理するモデルの能力を測定するために、2,000 の質問とその標準解答を含むテスト データ セットが編集されました。
ただし、調査によると、各モデルの精度は一般的に低いことがわかっています。この場合、精度だけを比較することはあまり意味がありません。したがって、この研究では、リーグ・オブ・レジェンドの ELO マッチング メカニズムを利用し、法的な多肢選択問題を処理する各モデルの能力をより効果的に評価するために、モデルと対決する ELO メカニズムを作成します。以下はそれぞれ ELO スコアと勝率グラフです:
 写真
写真
上記の実験結果の分析を通じて、次のことがわかります。次の観察結果を描画します。
(1) 法律関連の質問と回答および規制規定からのデータを導入すると、多肢選択式質問におけるモデルのパフォーマンスをある程度向上させることができます。
(2) トレーニング用に特定のタイプのタスクのデータを追加すると、このタイプのタスクにおけるモデルのパフォーマンスが大幅に向上します。たとえば、ChatLaw モデルが GPT-4 よりも優れている理由は、記事内で多数の多肢選択式質問がトレーニング データとして使用されているためです。多肢選択式の質問には複雑な論理的推論が必要なため、通常はパラメーターの数が多いモデルの方がパフォーマンスが高くなります。
参照 Zhihu リンク:
https://www.zhihu.com/question/610072848
その他の参考リンク:
https://mp.weixin.qq.com/s/bXAFALFY6GQkL30j1sYCEQ
以上がサーバーは過密、北京大学の大規模法モデルChatLawは人気:張三がどのように判決されたかを直接教えてくださいの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。