
ホームページ >テクノロジー周辺機器 >AI >NTU と上海 AI ラボが 300 以上の論文を編集: Transformer に基づくビジュアル セグメンテーションの最新レビューがリリース
NTU と上海 AI ラボが 300 以上の論文を編集: Transformer に基づくビジュアル セグメンテーションの最新レビューがリリース

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-07-04 12:25:081325ブラウズ
SAM (Segment Anything) は、基本的な視覚セグメンテーション モデルとして、わずか 3 か月で多くの研究者の注目を集め、フォローアップされました。 SAM の背後にあるテクノロジーを体系的に理解し、進化のペースに追いつき、独自の SAM モデルを作成できるようにしたい場合は、このトランスフォーマーベースのセグメンテーション調査をお見逃しなく。最近、南洋理工大学と上海人工知能研究所の数人の研究者が Transformer ベースのセグメンテーションに関するレビューを書き、近年の Transformer に基づくセグメンテーションおよび検出モデルを体系的にレビューし、研究を行っています。今年の6月から!同時に、このレビューには関連分野の最新の論文や多数の実験分析と比較も含まれており、幅広い展望を持つ将来の研究の方向性を多数明らかにしています。
ビジュアル セグメンテーションは、画像、ビデオ フレーム、または点群を複数のセグメントまたはグループにセグメント化することを目的としています。このテクノロジーは、自動運転、画像編集、ロボットの認識、医療分析など、多くの実世界で応用されています。過去 10 年間で、深層学習ベースの手法がこの分野で大きな進歩を遂げました。最近、Transformer は、もともと自然言語処理用に設計されたセルフ アテンション メカニズムに基づくニューラル ネットワークとなり、さまざまな視覚処理タスクにおける以前の畳み込みまたは再帰的手法を大幅に上回りました。具体的には、Vision Transformer は、さまざまなセグメンテーション タスクに対して、強力で統合されたさらにシンプルなソリューションを提供します。このレビューでは、Transformer ベースのビジュアル セグメンテーションの包括的な概要を提供し、最近の進歩を要約します。まず、この記事 では、問題定義、データ セット、以前の畳み込み手法などの背景 を確認します。次に、このペーパーでは、最近の Transformer ベースのメソッドをすべて統合する メタ アーキテクチャ について概要を説明します。このメタ アーキテクチャに基づいて、 この記事では、このメタ アーキテクチャと関連アプリケーションの修正を含む、さまざまな方法の設計を検討します。 さらに、この記事では、3D 点群セグメンテーション、基本的なモデル調整、ドメイン適応セグメンテーション、効率的なセグメンテーション、医療セグメンテーションなど、いくつかの関連設定も紹介します。さらに、この論文では、いくつかの広く認識されているデータセットに基づいてこれらの手法を編集し、再評価します。最後に、この論文はこの分野における未解決の課題を特定し、将来の研究の方向性を提案しています。この記事では、Transformer ベースの最新のセグメンテーションおよび検出方法を継続して追跡します。
 写真
写真
プロジェクトアドレス: https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
論文アドレス: https://arxiv.org/pdf/2304.09854.pdf
研究動機
- ViT と DETR の出現により、セグメンテーションと検出の分野は完全に進歩し、現在、ほぼすべてのデータセット ベンチマークで上位にランクされる手法は、Transformer に基づいています。このため、この方向の手法や技術的特徴を体系的にまとめ、比較する必要がある。
- マルチモーダル モデルやセグメンテーション基本モデル (SAM) など、最近の大規模モデル アーキテクチャはすべて Transformer 構造に基づいており、さまざまな視覚タスクが統合モデル モデリングに近づいています。
- セグメンテーションと検出により、多くの関連する下流タスクが派生し、これらのタスクの多くも Transformer 構造を使用して解決されます。
概要機能
- 体系的で読みやすい。 この記事では、セグメンテーションの各タスク定義、および関連するタスク定義と評価指標を体系的にレビューします。そして、この記事ではコンボリューション手法から始まり、ViTとDETRに基づくメタアーキテクチャをまとめます。このレビューでは、このメタアーキテクチャに基づいて、関連する手法を整理してまとめ、最近の手法を体系的にレビューします。具体的な技術検討ルートを図1に示します。
- 技術的な観点からの詳細な分類。 以前の Transformer レビューと比較して、この記事のメソッドの分類はより詳細になります。この記事では、同様のアイデアを持つ論文をまとめ、その類似点と相違点を比較します。たとえば、この記事では、メタ アーキテクチャのデコーダ側を同時に変更する手法を、画像ベースのクロス アテンションとビデオ ベースの時空間クロス アテンション モデリングに分類します。
- 研究課題の包括性。 この記事では、画像、ビデオ、点群のセグメンテーション タスクなど、セグメンテーションのあらゆる方向を体系的にレビューします。同時に、この記事では、オープンセットのセグメンテーションと検出モデル、教師なしセグメンテーション、弱教師セグメンテーションなどの関連する方向性についてもレビューします。
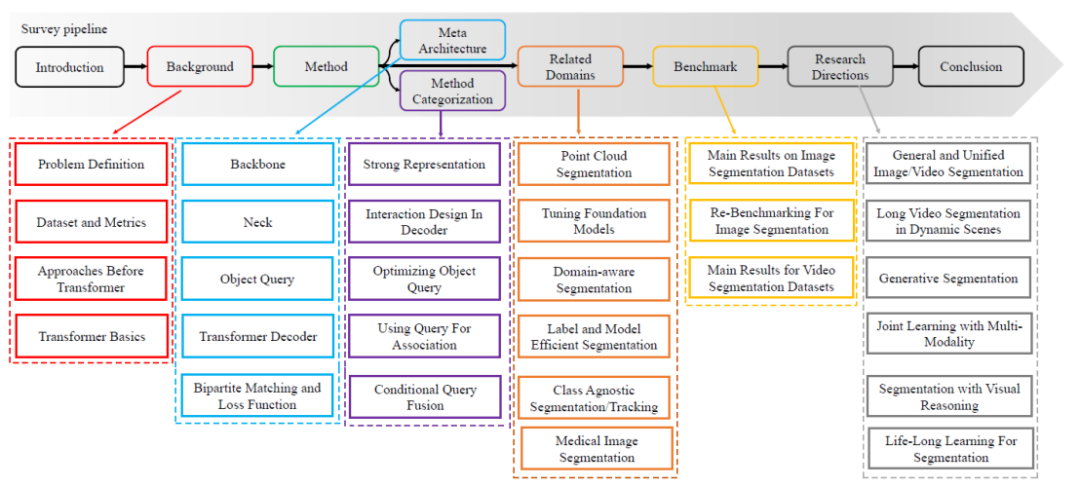 図
図
図 1. 調査内容のロードマップ
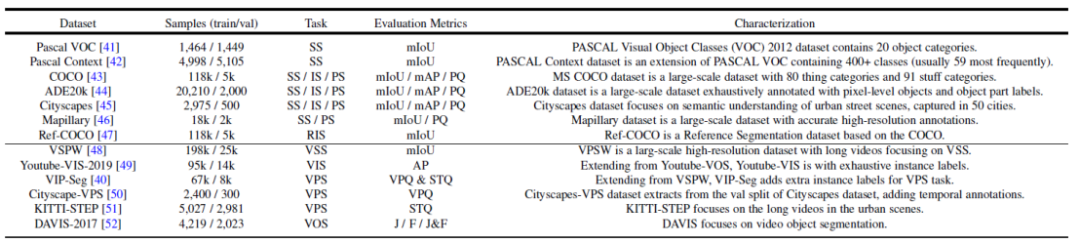
図 2. 一般的に使用されるデータ セットとセグメンテーション タスクの概要
トランスフォーマー ベースのセグメンテーションと検出の概要方法と比較
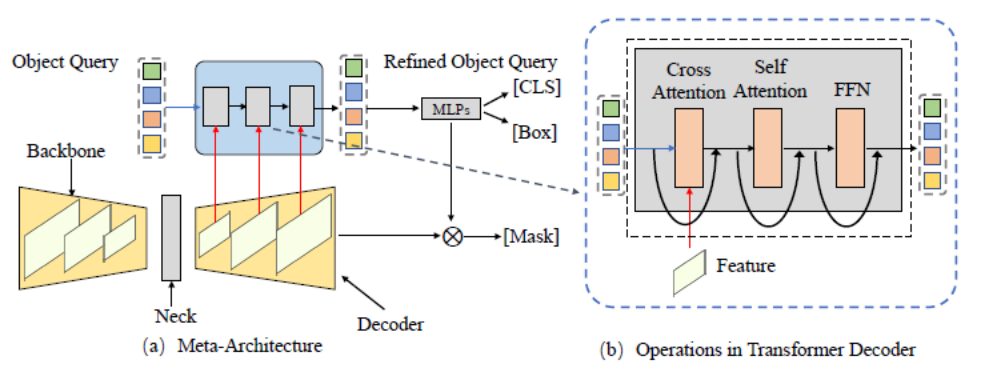
図 3. 一般的なメタ アーキテクチャ フレームワーク
## この記事では、まず概要を説明します。 DETR および MaskFormer フレームワークに基づくメタ アーキテクチャ。このモデルには、次のさまざまなモジュールが含まれています。
- バックボーン: 特徴抽出器。画像の特徴を抽出するために使用されます。
- ネック: マルチスケール オブジェクトを処理するためにマルチスケール フィーチャを構築します。
- オブジェクト クエリ: クエリ オブジェクト。前景オブジェクトや背景オブジェクトなど、シーン内の各エンティティを表すために使用されます。
- デコーダ: デコーダ。オブジェクト クエリと対応する機能を段階的に最適化するために使用されます。
- エンドツーエンドのトレーニング: オブジェクト クエリに基づく設計は、エンドツーエンドの最適化を実現できます。
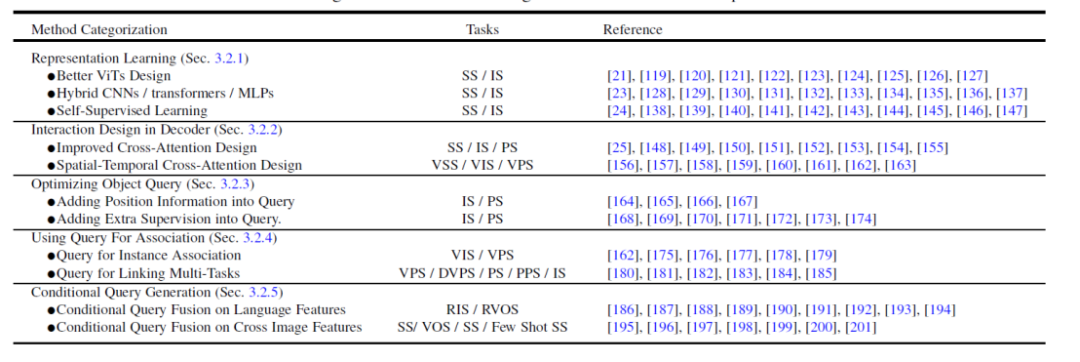
# 図 5 は、これら 5 つの異なる方向における代表的な作業の比較を示しています。より具体的な手法の詳細と比較については、論文の内容を参照してください。 #図 #関連研究分野の手法の概要と比較 #写真 さまざまな方法の実験結果の比較
図 8. パノラマ セグメンテーション データ セットのベンチマーク実験 この記事では、同じ実験計画条件を一律に使用して、複数のデータセットに対するパノラマ セグメンテーションとセマンティック セグメンテーションに関するいくつかの代表的な研究の結果を比較します。同じトレーニング戦略とエンコーダーを使用すると、メソッドのパフォーマンスの差が縮まることがわかりました。 さらに、この記事では、複数の異なるデータ セットおよびタスクに対する最近の Transformer ベースのセグメンテーション手法の結果も比較します。 (セマンティック セグメンテーション、インスタンス セグメンテーション、パノラマ セグメンテーション、および対応するビデオ セグメンテーション タスク) さらに、この記事では次のようなことも示しています。将来の研究の方向性についての分析。ここでは例として 3 つの異なる方向を示します。 研究の方向性の詳細については、元の論文を参照してください。
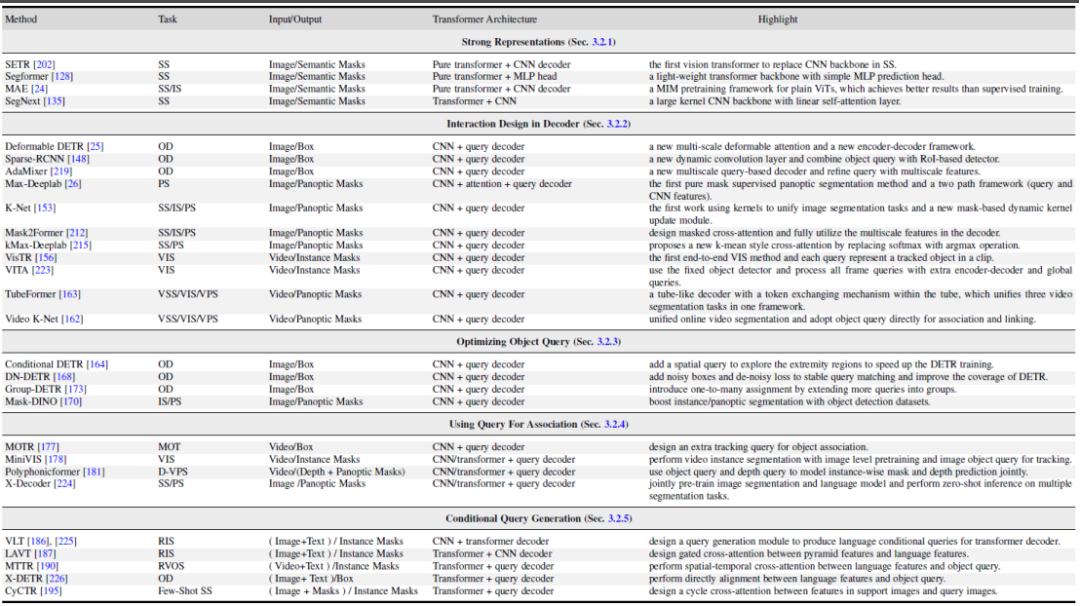
##この記事では、いくつかの関連分野についても説明します。 1. Transformer に基づく点群セグメンテーション手法。 2. ビジョンとマルチモーダル大規模モデルのチューニング。 3. ドメイン転移学習やドメイン汎化学習など、ドメイン関連のセグメンテーション モデルの研究。 4. 効率的なセマンティック セグメンテーション: 教師なしセグメンテーション モデルと弱く教師ありセグメンテーション モデル。 5. クラスに依存しないセグメンテーションと追跡。 6. 医療画像のセグメンテーション。
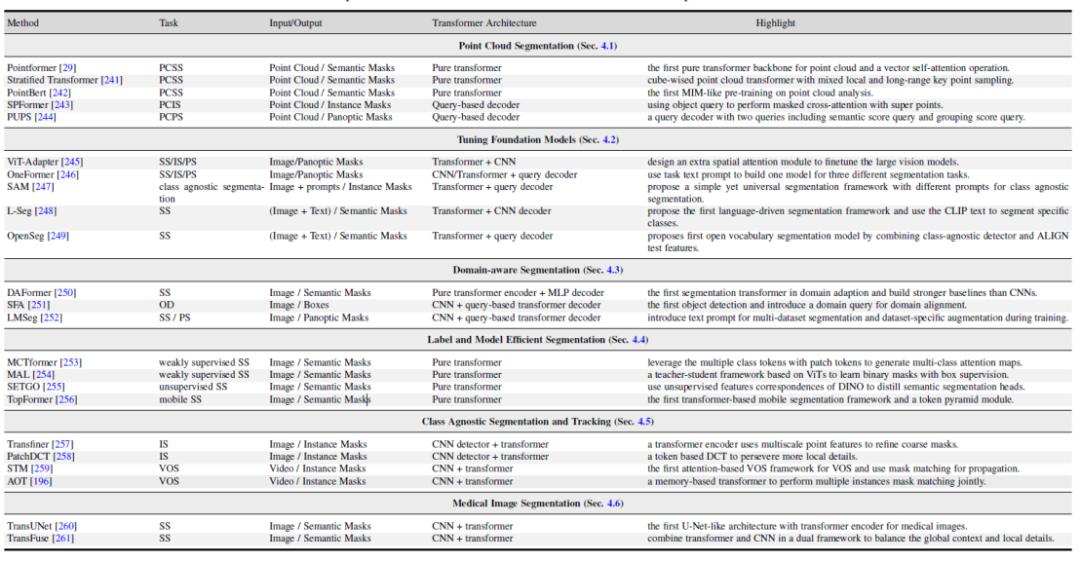 図 6. 関連研究分野における Transformer ベースの手法の概要と比較
図 6. 関連研究分野における Transformer ベースの手法の概要と比較図 7. セマンティック セグメンテーション データ セットのベンチマーク実験
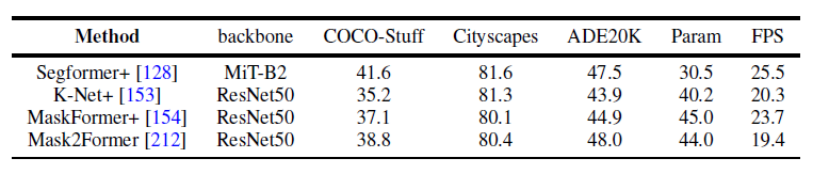
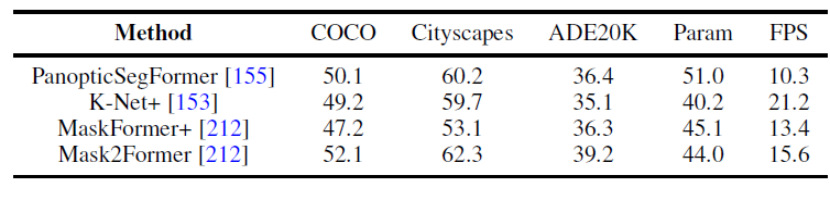
将来の方向
以上がNTU と上海 AI ラボが 300 以上の論文を編集: Transformer に基づくビジュアル セグメンテーションの最新レビューがリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。