
ホームページ >テクノロジー周辺機器 >AI >2時間で人間を超える! DeepMind の最新 AI が 26 の Atari ゲームをスピードランします
2時間で人間を超える! DeepMind の最新 AI が 26 の Atari ゲームをスピードランします

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-07-03 20:57:171477ブラウズ
DeepMind の AI エージェントが再び自分自身を騙そうとしています!
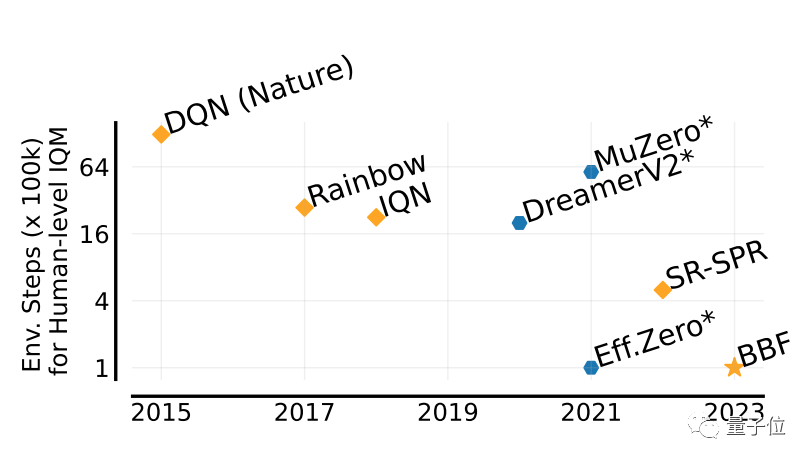
ほら、BBF という名前の男は、わずか 2 時間で 26 個の Atari ゲームをマスターしました。彼の効率は人間と同じくらい優れており、すべての先人を上回っています。
AI エージェントは強化学習を通じて問題を解決するのに常に効果的であることを知っておく必要がありますが、最大の問題は、この方法が非常に非効率であり、探索に長い時間がかかることです。
 写真
写真
BBF によってもたらされた画期的な進歩は、まさに効率の点にあります。
フルネームが Bigger、Better、Faster と呼ばれるのも不思議ではありません。
さらに、トレーニングは 1 枚のカードだけで完了でき、必要な計算能力も大幅に削減されます。
BBF は Google DeepMind とモントリオール大学によって共同提案されたもので、データとコードは現在オープンソースです。
人間の最大 5 倍のパフォーマンスを実現可能
BBF ゲームのパフォーマンスを評価するために使用される値は IQM と呼ばれます。
IQM は、多面的なゲーム パフォーマンスの総合的なスコアです。この記事の IQM スコアは人間に基づいて正規化されています。
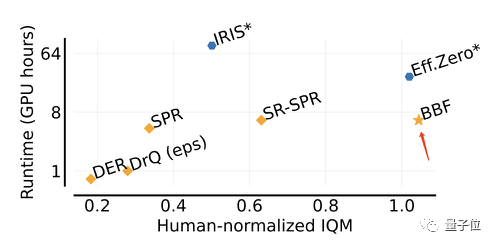
以前の複数の結果と比較して、BBF は 26 の Atari ゲームを含む Atari 100K テスト データ セットで最高の IQM スコアを達成しました。
さらに、訓練された 26 試合で、BBF のパフォーマンスは人間のパフォーマンスを上回りました。
同様に動作する Eff.Zero と比較すると、BBF は GPU 時間を半分近く消費します。
SPR と SR-SPR のパフォーマンスは、同様の GPU 時間を消費しますが、BBF とは大きく異なります。
 写真
写真
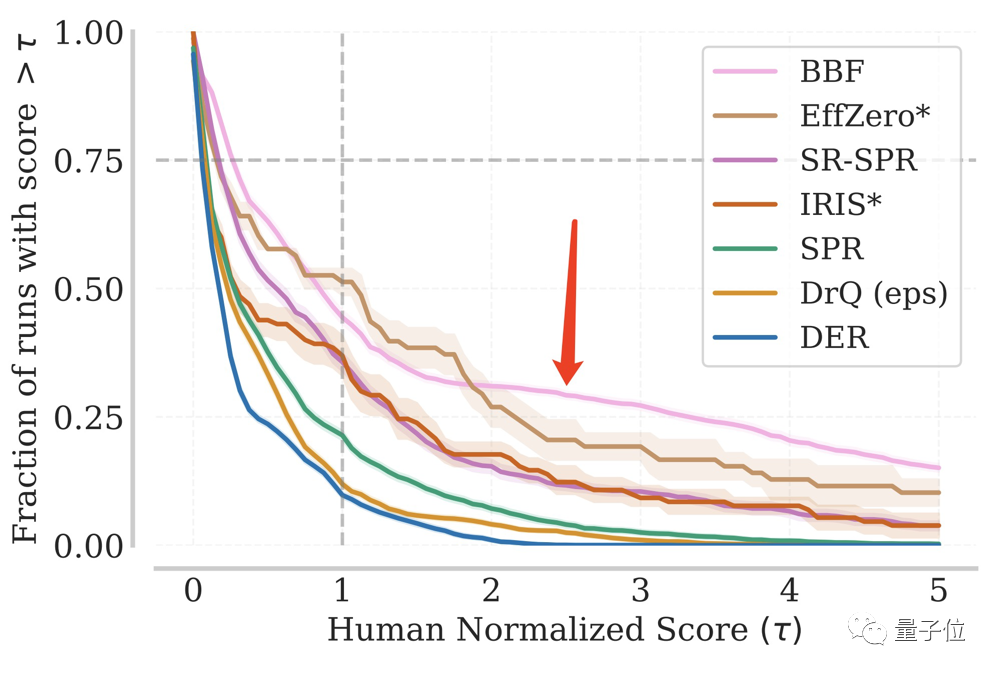
繰り返しのテストにおいて、特定の IQM スコアに達する BBF の割合は常に高いレベルを維持しています。
総テスト数の 1/8 以上でも、人間の 5 倍のパフォーマンスを達成しました。
 写真
写真
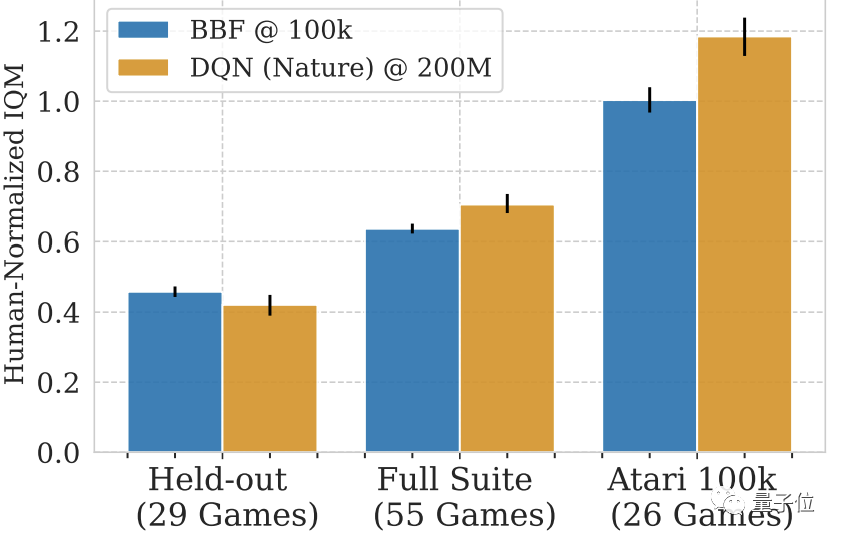
トレーニングなしで他の Atari ゲームを使用した場合でも、BBF は人間の IQM スコアの半分以上を達成できます。
トレーニングされていない 29 試合だけで見ると、BBF のスコアは人間の 40 ~ 50% です。
 写真
写真
SR-SPRに基づいて修正
BBF研究を促進する問題は、サンプルサイズが小さい場合にそれをどのように使用するかです。 sparse 深層強化学習ネットワークのスケーリング。
この問題を研究するために、DeepMind は Atari 100K ベンチマークに注目しました。
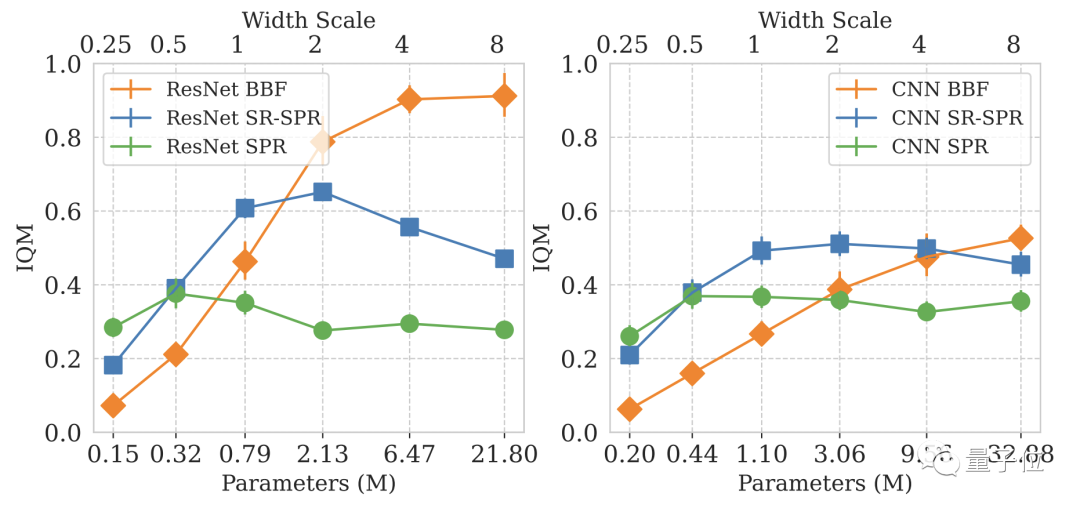
しかし、DeepMind はすぐに、モデルのサイズを増やすだけではパフォーマンスが向上しないことに気づきました。
 図
図
深層学習モデルの設計では、ステップごとの更新数 (再生率、RR) が重要なパラメーターです。
特に Atari ゲームの場合、RR 値が大きいほど、ゲーム内でのモデルのパフォーマンスが高くなります。
最終的に、DeepMind は基本エンジンとして SR-SPR を使用し、SR-SPR の RR 値は最大 16 に達します。
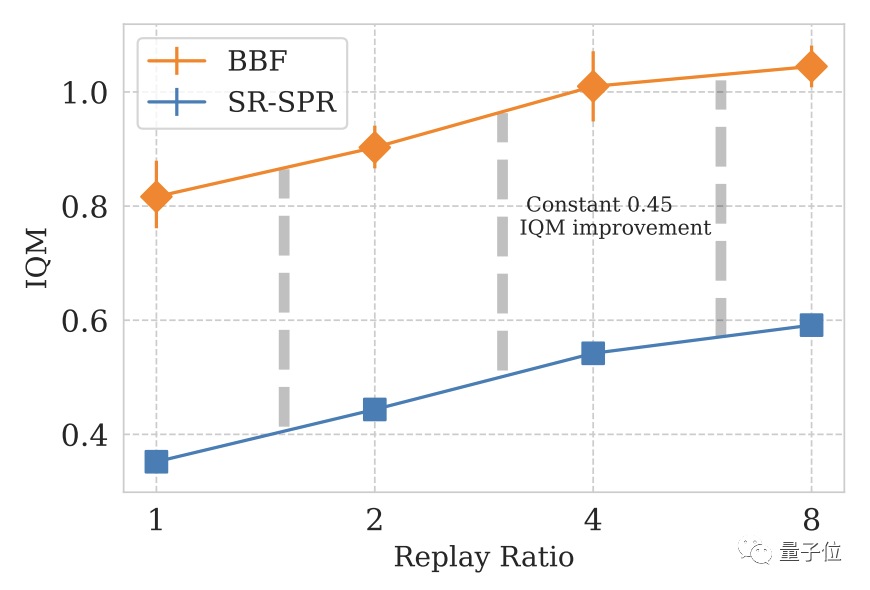
総合的な検討の結果、DeepMind は BBF の RR 値として 8 を選択しました。
一部のユーザーが RR=8 のコンピューティング コストを費やすことを望まないことを考慮して、DeepMind は RR=2 バージョンの BBF
 Picture## も開発しました。
Picture## も開発しました。
- 畳み込み層のリセット強度の向上: 畳み込み層のリセット強度を増加すると、ランダム ターゲットの摂動振幅が増加し、モデルのパフォーマンスが向上し、損失が減少します。BBF のリセット強度が増加すると、摂動振幅が増加します。 SR-SPR の 20% から 50% へ
- #ネットワーク規模の拡大: ニューラル ネットワーク層の数を 3 層から 15 層に増加し、幅を 4 倍に増加
- 更新範囲の縮小 ( n): モデルのパフォーマンスを向上させたい場合は、非固定の n 値を使用する必要があります。 BBF は 40,000 勾配ステップごとにリセットされます。各リセットの最初の 10,000 勾配ステップでは、n は 10 から 3 に指数関数的に減少します。減衰フェーズは BBF トレーニング プロセスの 25% を占めます
- Update 大きな減衰係数 (γ ): 一部の人々は、学習プロセス中に γ 値を増やすとモデルのパフォーマンスが向上することを発見しました。BBF の γ 値は、従来の 0.97 から 0.997 に増加します。
- 重みの減衰: 過学習の発生を回避します。 BBF は約 0.1
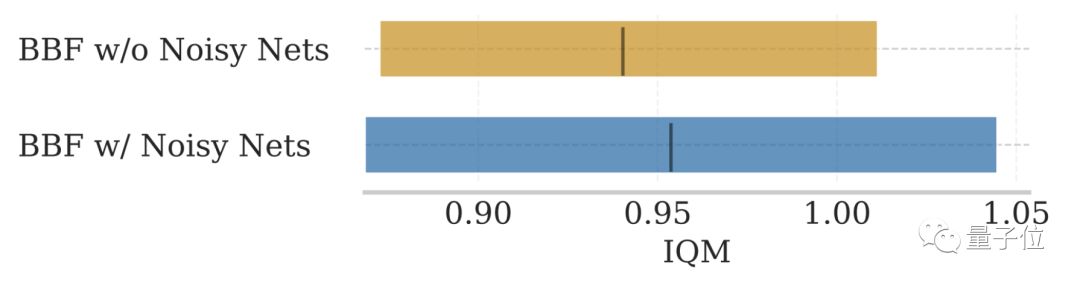
- NoisyNet の削除: 元の SR-SPR に含まれている NoisyNet ではモデルのパフォーマンスを向上させることはできません
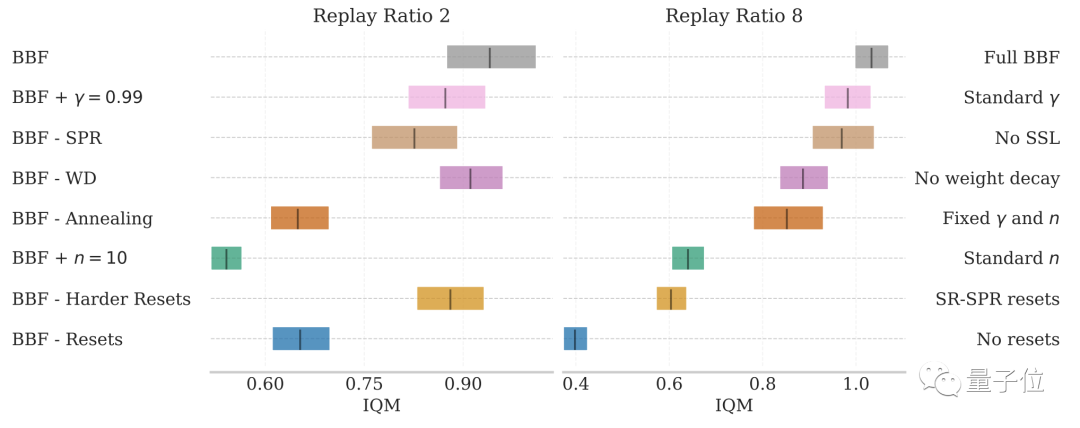
アブレーションの実験結果は、ステップごとの更新数が 2 以下であることを示しています。 8 の条件では、上記の要因が BBF のパフォーマンスにさまざまな程度の影響を与えます。
 写真
写真
その中でも、ハード リセットと更新範囲の縮小の影響が最も大きくなります。
 図
図
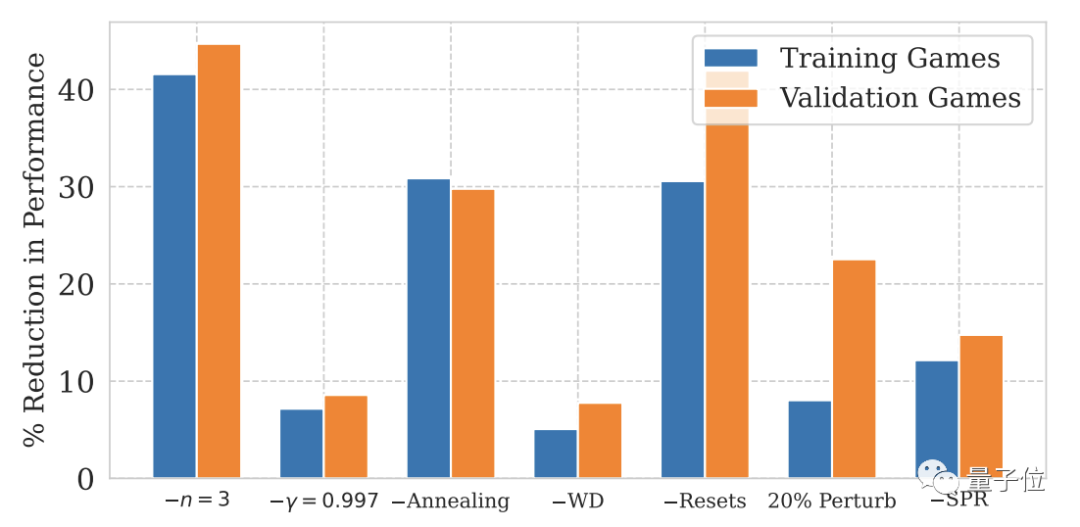
NoisyNet については、上の 2 つの図には記載されていませんが、モデルのパフォーマンスへの影響は大きくありません。
 写真
写真
参考リンク: [1]https://www.php.cn/link/69b4fa3be19bdf400df34e41b93636a4
[2]https://www.marktechpost.com/2023/06/12/superhuman-performance-on-the-atari-100k-benchmark-the-power-of-bbf-a-new-value -based-rl-agent-from-google-deepmind-mila-and-universite-de-montreal/
#— 終了 —以上が2時間で人間を超える! DeepMind の最新 AI が 26 の Atari ゲームをスピードランしますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。