
 テクノロジー周辺機器AI清華大学の壁に面したインテリジェントなオープンソース中国マルチモーダル大型モデル VisCPM: 対話テキストと画像の双方向生成をサポートし、驚くべき詩と絵画機能を備えています
テクノロジー周辺機器AI清華大学の壁に面したインテリジェントなオープンソース中国マルチモーダル大型モデル VisCPM: 対話テキストと画像の双方向生成をサポートし、驚くべき詩と絵画機能を備えています清華大学の壁に面したインテリジェントなオープンソース中国マルチモーダル大型モデル VisCPM: 対話テキストと画像の双方向生成をサポートし、驚くべき詩と絵画機能を備えています

2020年12月にリリースされたCPM-1は中国初の大型モデルで、2022年9月にリリースされたCPM-Antはパラメータの0.06%を微調整するだけでフルパラメータ微調整効果を超えることができます。 2023 年 5 月にリリースされた WebCPM は、中国初の検索ベースの質問と回答のオープンソース モデルです。 CPM-Bee数百億モデルは同チームがリリースした最新のベースモデルで、中国語能力は権威あるリストZeroCLUEで第1位、英語能力はLLaMAと同等。
大型モデルCPMシリーズは画期的な成果を重ね、国内大型モデルをトップに導き、このたびリリースされたVisCPMもまたその証しです。 VisCPM は、Wall-face Intelligence、清華大学 NLP 研究所、および OpenBMB の Zhihu が共同でオープンソース化したマルチモーダル大規模モデル シリーズです。VisCPM-Chat モデルは、中国語と英語のバイリンガル マルチモーダル対話機能と、VisCPM をサポートしています。 - ペイント モデルのサポート テキストから画像への生成機能に関しては、VisCPM が中国のマルチモーダル オープン ソース モデルの中で最高のレベルに達していることが評価されています。
VisCPM は、数百億のパラメータベースモデル CPM-Bee に基づいてトレーニングされ、ビジュアル エンコーダ (Q-Former とビジュアル デコーダ (Diffusion-UNet)) を統合しています。視覚信号の入出力をサポートします。CPM-Bee ベースの優れたバイリンガル機能のおかげで、VisCPM は英語のマルチモーダル データを通じてのみ事前トレーニングでき、優れた中国語のマルチモーダル機能を実現するように一般化できます。
 VisCPM の簡単なアーキテクチャ図
VisCPM の簡単なアーキテクチャ図
VisCPM-Chat と VisCPM-Paint がどこにあるのか詳しく見てみましょう。
 写真
写真
VisCPMリンク: https://github.com/OpenBMB/VisCPM
VisCPM-Chat は、中国語と英語での画像指向のバイリンガル マルチモーダル ダイアログをサポートします。 このモデルは、Q-Former をビジュアル エンコーダとして使用し、CPM-Bee (10B) をビジュアル エンコーダとして使用します。言語対話ベース モデルとパス 言語モデリング トレーニングの目標には、ビジュアル モデルと言語モデルが統合されます。モデル トレーニングには、事前トレーニングと指示の微調整の 2 つの段階が含まれます。
チームは約を使用します。 100M の高品質英語画像とテキストのペア データ VisCPM-Chat は事前トレーニングされており、データには CC3M、CC12M、COCO、Visual Genome、Laion などが含まれています。事前トレーニングの段階では、言語モデルのパラメーターは固定されたままで、大規模なビジョンをサポートするために Q-Former の一部のパラメーターのみが更新されます。言語表現の効率的な調整。
チームはその後、次の手順を微調整しました。 VisCPM-Chat、LLaVA-150K 英語コマンド微調整データ を採用し、対応する翻訳を混合しました。モデルのマルチモーダル基本機能をユーザーの意図に合わせるために、最新の中国語データを使用してモデルを微調整しました。微調整段階では、すべてのモデル パラメーターを更新して、微調整データの利用効率を向上させました。
興味深いことに、チームは、英語の指導データのみが使用された場合でも、命令の微調整のために、モデルは中国語の質問を理解できましたが、英語でしか答えることができませんでした。これは、モデルが 多言語モーダル機能が十分に一般化されていることを示しています。さらに少量の中国語翻訳データを追加することで、指示の微調整段階では、モデルの応答言語をユーザーの質問言語と一致させることができます。
チーム モデルは、LLaVA 英語テスト セットと翻訳された中国語テスト セットで評価されました。この評価ベンチマークは、オープン ドメインの対話、画像の詳細説明、および複雑な推論におけるモデルのパフォーマンスを検査し、スコアリングに GPT-4 を使用します。 VisCPM-Chat が最高の平均パフォーマンスを達成したことがわかります。中国語のマルチモーダル能力に関しては、一般領域の対話と複雑な推論で優れたパフォーマンスを発揮し、英語のマルチモーダル能力も優れていました。
VisCPM-Chat には、VisCPM-Chat-balance と VisCPM-Chat-zhplus という 2 つのモデル バージョンが用意されています。 前者には英語と中国語の機能があり、よりバランスが取れており、後者は中国語の能力がさらに優れています。 2 つのモデルは、命令の微調整フェーズで同じデータを使用します。VisCPM-Chat-zhplus は、事前トレーニング フェーズで、さらに 2,000 万のクリーン化されたネイティブ中国語の画像とテキストのペア データと、1 億 2,000 万の翻訳された中国語の画像とテキストのペア データを追加します。 。 ###############写真###### 次は、VisCPM-Chat のマルチモーダル対話機能のデモです。特定の地域の地図を識別できるだけでなく、落書きや映画のポスターを理解し、スターバックスのロゴさえも認識できます。さらに、私は中国語と英語のバイリンガルです! 中国語と中国語のバイリンガルをサポートする VisCPM-Paint を見てみましょう。英語のテキストから画像への生成。 このモデルは、テキスト エンコーダーとして CPM-Bee (10B)、画像デコーダーとして UNet を使用し、拡散モデルを通じてターゲット融合言語とビジョン モデルをトレーニングします。 トレーニング プロセス中、言語モデルのパラメーターは常に固定されたままになります。 Stable Diffusion 2.1 の UNet パラメータを使用してビジュアル デコーダを初期化し、主要なブリッジング パラメータを段階的にフリーズ解除することで言語モデルと融合します。最初にテキスト表現マッピングの線形層をビジュアル モデルにトレーニングし、次にクロスアテンションをさらにフリーズ解除します。 UNet の層。モデルは、Laion 2B 英語の画像テキスト データでトレーニングされました。 VisCPM-Paint と同様に、基本モデル CPM-Bee のバイリンガル機能のおかげで、VisCPM-Paint は英語の画像とテキストのペアと一般化を通じてのみトレーニングできます。中国語のテキストから画像への生成機能は、中国語のオープン ソース モデルの最良の結果を実現します。 20M のクリーン化されたネイティブ中国語の画像とテキストのペア データと、中国語に翻訳された 120M の画像とテキストのペア データをさらに追加することにより、このモデルの中国語テキストから画像への生成機能がさらに向上しました。同様に、VisCPM-Paint には、balance と zhplus という 2 つの異なるバージョンがあります。標準画像生成テストセット MSCOCO で 30,000 枚の画像をサンプリングし、一般的に使用される評価画像生成指標 FID (Fréchet Inception Distance) を計算して、生成された画像の品質を評価しました。 VisCPM-Paintモデルにそれぞれ「明るい月が海に昇る、世界は今この瞬間、耽美的スタイル、抽象的スタイル」を入力」と「キンモクセイの花は、人々が怠けているときに散る。「浄月春の山空」の 2 つのプロンプトにより、次の 2 つの写真が生成されました。 (生成効果の安定性には改善の余地あり) なかなか素晴らしいもので、古詩の芸術的概念を正確に捉えていると言えます。将来的には、詩を理解するために直接画像を生成することができます。設計に応用すれば大幅な省力化が可能です。 VisCPM-Chat では「絵を描く」だけでなく「詩を朗読」することもできます : 写真から詩を逆引き検索できます。たとえば、李白の詩を使って黄河の情景を説明し、解釈することもできますし、蘇軾の「水条歌頭」を使って中秋の月夜に臨むときの感情を表現することもできます。 VisCPM は生成結果が優れているだけでなく、ダウンロード バージョンの設計も考慮されており、非常に簡単ですインストールして使用します。 VisCPM は中国語と英語の機能を備えたさまざまなバージョンを提供しますさまざまなバージョン 中国語と英語の機能を備えたモデル バージョンは、誰でもダウンロードして選択できます インストール手順は簡単です 使用中は、数行のコードでマルチモーダル ダイアログを実現できます 入力テキストと出力画像のセキュリティ チェックコードではデフォルトで有効になっています。 (具体的なチュートリアルについては README を参照してください) 将来的には、チームは VisCPM を ハグフェイス コード フレームワークにも統合し、引き続きセキュリティ モデルの改善、Web ページの迅速な展開のサポート、モデルの定量化機能のサポート、モデルの詳細なサポートを行う予定です。チューニングとその他の機能、更新を待ってください! VisCPM シリーズ モデルは、個人使用や研究目的での使用を歓迎します 。モデルを商用目的で使用したい場合は、cpm@modelbest.cn に連絡して商用ライセンスの問題について話し合うこともできます。 従来のモデルは、単一モーダル データの処理に重点を置いています。現実世界の情報は多くの場合、マルチモーダルです。マルチモーダルな大規模モデルは、人工知能システムの知覚インタラクション機能を向上させ、AI を提供します現実世界での複雑な認識と理解のタスクを解決すると、新たな機会がもたらされます。清華を拠点とする大規模モデル企業は強力な壁に面したインテリジェンスの研究開発能力を持っていると言わざるを得ません。共同でリリースされたマルチモーダル大型モデル VisCPM は強力で驚くべきパフォーマンスを発揮します。今後の結果のリリースが楽しみです! 




 VisCPM は中国語と英語の機能を備えたさまざまなバージョンを提供します
VisCPM は中国語と英語の機能を備えたさまざまなバージョンを提供します
以上が清華大学の壁に面したインテリジェントなオープンソース中国マルチモーダル大型モデル VisCPM: 対話テキストと画像の双方向生成をサポートし、驚くべき詩と絵画機能を備えていますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 Langchainテキストスプリッターを使用してデータを分割する7つの方法-AnalyticsVidhyaApr 19, 2025 am 10:11 AM
Langchainテキストスプリッターを使用してデータを分割する7つの方法-AnalyticsVidhyaApr 19, 2025 am 10:11 AMLangchainテキストスプリッター:効率と精度のためにLLM入力を最適化する 以前の記事では、Langchainのドキュメントローダーについて説明しました。 ただし、LLMにはコンテキストウィンドウサイズの制限(トークンで測定)があります。 この制限を超えると、データが切り捨てられます
 無料生成AIコース:イノベーションの未来を先駆けてApr 19, 2025 am 10:01 AM
無料生成AIコース:イノベーションの未来を先駆けてApr 19, 2025 am 10:01 AM生成AI:創造性と革新の革命 生成的AIは、ボタンに触れるだけでテキスト、画像、音楽、仮想世界を作成することにより、産業を変革しています。 その影響は、ビデオ編集、音楽制作、アート、エンターテイメント、HEAに及びます
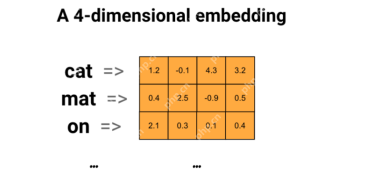 ユニバーサルセンテンスエンコーダーとwikiqaを使用してQAモデルを作成するApr 19, 2025 am 10:00 AM
ユニバーサルセンテンスエンコーダーとwikiqaを使用してQAモデルを作成するApr 19, 2025 am 10:00 AM高度な質問応答のための埋め込みモデルの力を活用する 今日の情報が豊富な世界では、正確な答えを即座に得る能力が最重要です。 この記事では、堅牢な質問回答(QA)モデルの構築を示しています
 トップ10は機械学習の研究論文を読む必要がありますApr 19, 2025 am 09:53 AM
トップ10は機械学習の研究論文を読む必要がありますApr 19, 2025 am 09:53 AMこの記事では、人工知能(AI)と機械学習(ML)に革命をもたらした10の独創的な出版物を探ります。 ニューラルネットワークとアルゴリズムの最近のブレークスルーを調べ、現代のAIを駆動するコア概念を説明します。 th
 SEO代理店を置き換えるためのトップ11のAIツール - 分析VidhyaApr 19, 2025 am 09:49 AM
SEO代理店を置き換えるためのトップ11のAIツール - 分析VidhyaApr 19, 2025 am 09:49 AMAIのSEOの台頭:SEO代理店を上回るトップ11ツール AIの急速な進歩は、SEOの景観を深く再形成しました。 トップ検索エンジンのランキングを目指している企業は、オンライン戦略を最適化するAIの力を活用しています。 auから
 2025年に試してみるためのトップ10の無料AI遊び場 - 分析vidhyaApr 19, 2025 am 09:45 AM
2025年に試してみるためのトップ10の無料AI遊び場 - 分析vidhyaApr 19, 2025 am 09:45 AM2024年に最高の無料AI遊び場を探索:包括的なガイド 適切なツールとプラットフォームへのアクセスは、人工知能(AI)の進化し続ける分野での学習と革新の鍵です。 AIプレイグラウンドは素晴らしい機会を提供します
 ベクトルデータベースのインデックスアルゴリズムに関する詳細なガイドApr 19, 2025 am 09:41 AM
ベクトルデータベースのインデックスアルゴリズムに関する詳細なガイドApr 19, 2025 am 09:41 AM導入 ベクトルデータベースは、高次元ベクトルデータを効率的に保存および取得するように設計された特殊なデータベースです。 これらのベクトルは、データポイントの機能または属性を表します。
 逆拡散プロセスとは何ですか? - 分析VidhyaApr 19, 2025 am 09:40 AM
逆拡散プロセスとは何ですか? - 分析VidhyaApr 19, 2025 am 09:40 AM安定した拡散:逆拡散の魔法を明らかにする 安定した拡散は、ノイズから高品質の画像を生成できる強力な生成モデルです。このプロセスには、2つの重要なステップが含まれます。フォワード拡散プロセス(以前のaで詳述されています


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

SublimeText3 中国語版
中国語版、とても使いやすい

Dreamweaver Mac版
ビジュアル Web 開発ツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

