
ホームページ >テクノロジー周辺機器 >AI >NVIDIA H100 が権威ある AI パフォーマンス テストで優位に立ち、GPT-3 に基づく大規模モデルのトレーニングを 11 分で完了
NVIDIA H100 が権威ある AI パフォーマンス テストで優位に立ち、GPT-3 に基づく大規模モデルのトレーニングを 11 分で完了

- 王林転載
- 2023-06-28 20:00:20927ブラウズ
現地時間火曜日、機械学習と人工知能の分野におけるオープン業界アライアンスである MLCommons は、2 つの MLPerf ベンチマークからの最新データを公開しました。その中で、NVIDIA H100 チップセットは、テストのすべてのカテゴリで新記録を樹立しました。人工知能コンピューティングのパワー パフォーマンスすべてのテストを実行できる唯一のハードウェア プラットフォームでもあります。
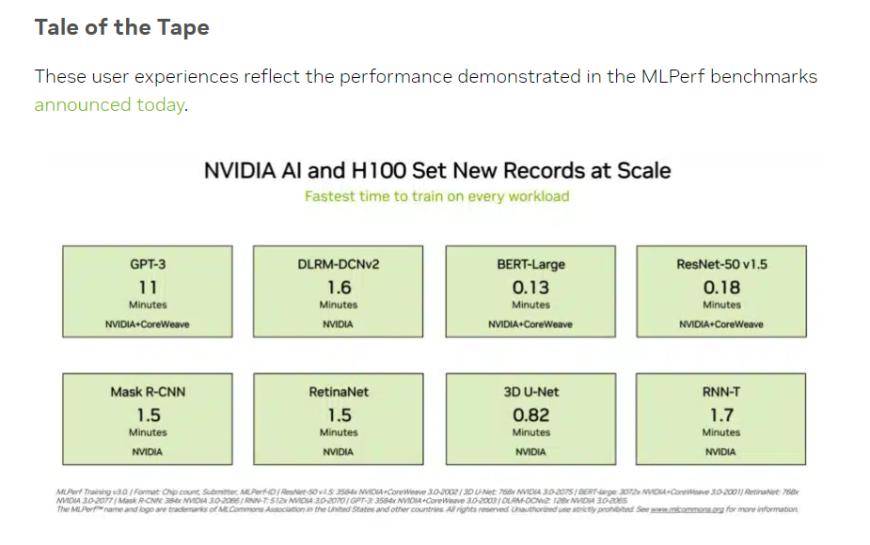
(出典: NVIDIA、MLCommons)
MLPerf は、学界、研究所、産業界で構成される人工知能リーダーシップ アライアンスであり、現在、国際的に認められ、権威ある AI パフォーマンス評価ベンチマークです。トレーニング v3.0 には、視覚 (画像分類、生物医学的画像セグメンテーション、2 つのロードの物体検出)、言語 (音声認識、大規模言語モデル、自然言語処理)、推奨システムを含む 8 つの異なるロードが含まれています。つまり、機器ベンダーが異なれば、ベンチマーク タスクを完了するまでにかかる時間も異なります。
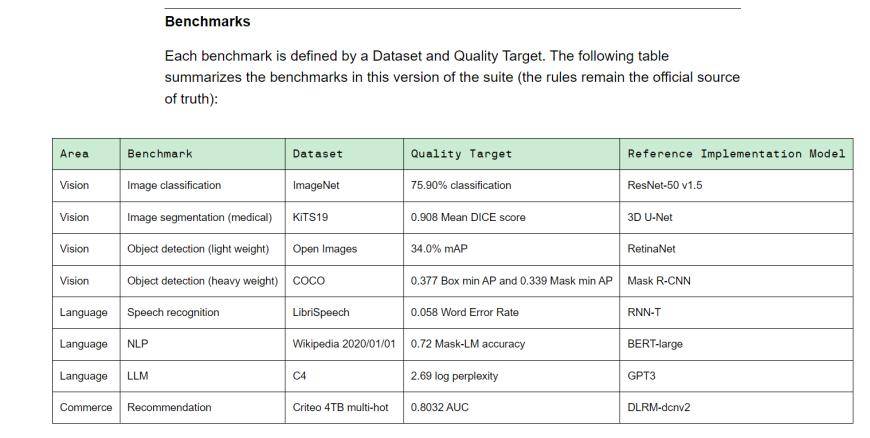
(トレーニング v3.0 トレーニング ベンチマーク、出典: MLCommons)
投資家がより懸念している「ビッグ言語モデル」トレーニング テストでは、NVIDIA と GPU クラウド コンピューティング プラットフォーム CoreWeave が提出したデータが、このテストの残酷な業界標準を設定しました。 896 個の Intel Xeon 8462Y プロセッサと 3584 個の NVIDIA H100 チップの協調的な取り組みにより、GPT-3 に基づく大規模な言語モデルのトレーニング タスクを完了するのにわずか 10.94 分しかかかりませんでした。
Nvidia を除き、このプロジェクトの評価データを受け取ったのは Intel の製品ポートフォリオだけです。 96 個の Xeon 8380 プロセッサーと 96 個の Habana Gaudi2 AI チップで構築されたシステムでは、同じテストを完了するのにかかる時間は 311.94 分でした。 768 個の H100 チップを搭載したプラットフォームを使用すると、水平比較テストにかかる時間はわずか 45.6 分になります。
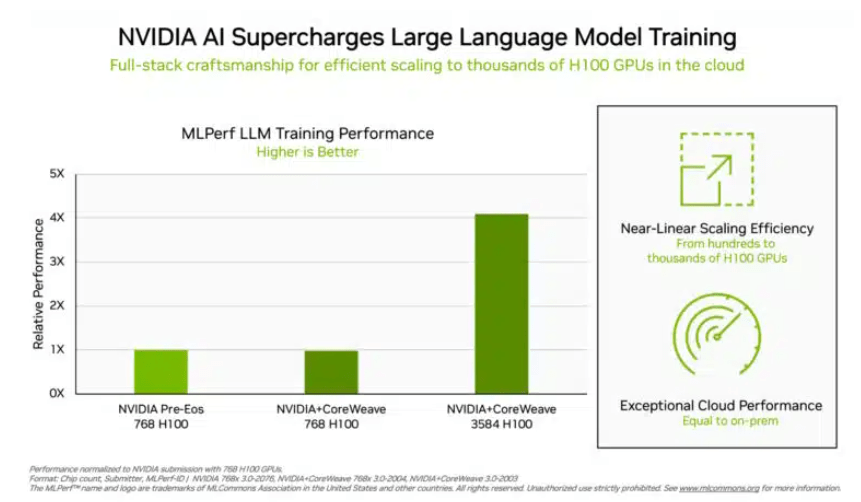
(チップの数が多いほど、データの質が向上します。出典: NVIDIA)
この結果について、インテルはまだ改善の余地があるとも述べています。理論的には、より多くのチップを積層すればするほど、計算結果は当然速くなります。 IntelのAI製品担当シニアディレクターであるJordan Plawner氏はメディアに対し、Habanaのコンピューティング結果は1.5倍から2倍向上すると語った。 Plawner 氏は、Habana Gaudi2 の具体的な価格の開示を拒否し、業界には AI トレーニング チップを提供する第 2 のメーカーが必要であり、MLPerf データは Intel がこの需要を満たす能力があることを示しているとだけ述べました。
中国の投資家にとって馴染みのある BERT-Large モデルのトレーニングでは、NVIDIA と CoreWeave がデータを 0.13 分という極端な値まで押し上げ、64 枚のカードの場合、テスト データも 0.89 分に達しました。現在の主流の大規模モデルのインフラストラクチャは、BERT モデルの Transformer 構造です。
出典: Financial AP通信
以上がNVIDIA H100 が権威ある AI パフォーマンス テストで優位に立ち、GPT-3 に基づく大規模モデルのトレーニングを 11 分で完了の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。