
ホームページ >テクノロジー周辺機器 >AI >Dubbo ロード バランシング戦略のコンシステント ハッシュ
Dubbo ロード バランシング戦略のコンシステント ハッシュ

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-26 15:39:181842ブラウズ
この記事では、主に整合性ハッシュ アルゴリズムの原理と既存のデータ スキュー問題について説明し、次にデータ スキュー問題を解決する方法を紹介し、最後に Dubbo での整合性ハッシュ アルゴリズムの使用法を分析します。この記事では、コンシステント ハッシュ アルゴリズムの仕組みと、このアルゴリズムが直面する問題と解決策について紹介します。
1. 負荷分散
これは dubbo の公式 Web サイトからの引用です——
LoadBalance は中国語で負荷分散を意味し、その役割はネットワーク リクエストやその他の形式を転送することです。負荷はさまざまなマシンに「均等に分散」されます。クラスター内の一部のサーバーが過剰な負荷にさらされている一方で、他のサーバーが比較的アイドル状態である状況を避けてください。負荷分散により、各サーバーは自身の処理能力に適した負荷を得ることができます。高負荷のサーバーをオフロードすると同時に、リソースの無駄も回避でき、一石二鳥です。負荷分散は、ソフトウェア負荷分散とハードウェア負荷分散に分類できます。私たちの日々の開発では、ハードウェアの負荷分散にアクセスするのは一般に困難です。ただし、Nginx などのソフトウェア負荷分散は引き続き利用できます。 Dubbo には、負荷分散の概念とそれに対応する実装もあります。
特定のサービス プロバイダーへの過度の負荷を回避するために、Dubbo はサービス コンシューマーからの呼び出しリクエストを割り当てる必要があります。サービスプロバイダーの負荷が大きすぎるため、一部のリクエストがタイムアウトする可能性があります。したがって、各サービスプロバイダーへの負荷を分散することが非常に必要です。 Dubbo は、加重ランダム アルゴリズムに基づく RandomLoadBalance、最小アクティブ呼び出しアルゴリズムに基づく LeastActiveLoadBalance、ハッシュ一貫性に基づく ConsistentHashLoadBalance、加重ポーリング アルゴリズムに基づく RoundRobinLoadBalance の 4 つの負荷分散実装を提供します。これらの負荷分散アルゴリズムのコードはそれほど長くありませんが、その原理を理解するには、ある程度の専門的な知識と理解が必要です。
2. ハッシュ アルゴリズム
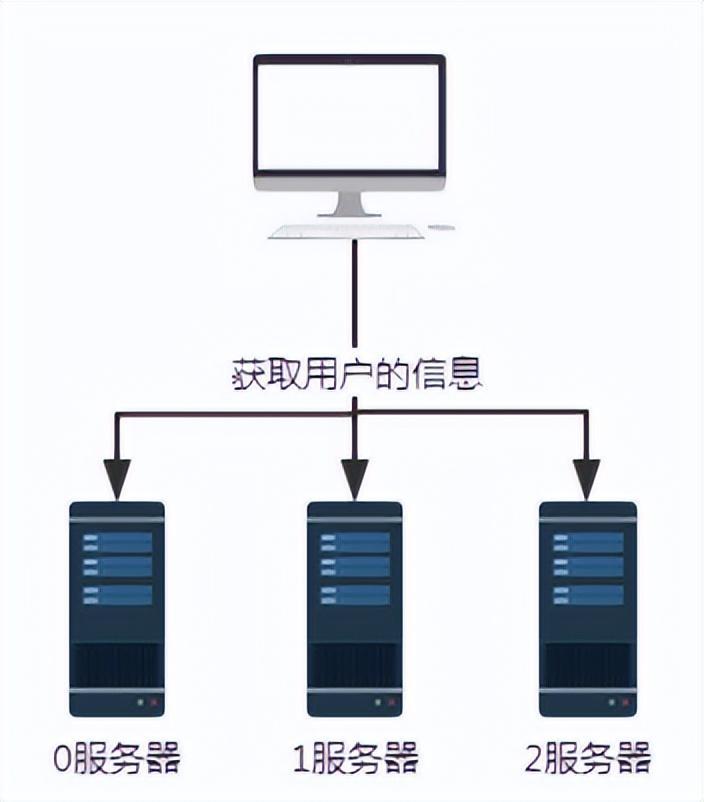
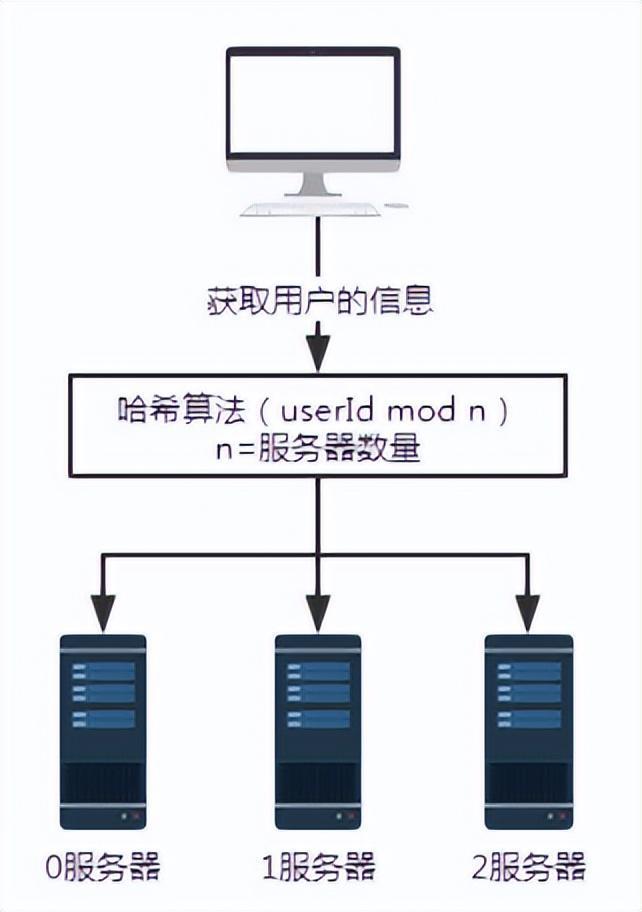 #図 2 ハッシュ アルゴリズム導入後のリクエスト
#図 2 ハッシュ アルゴリズム導入後のリクエスト
上記のシナリオでは、各サーバーが同じハッシュ アルゴリズムを使用してユーザー情報を保存すると想定しています。したがって、ユーザー情報を取得するときは、同じハッシュ アルゴリズムに従うだけです。
ユーザー番号 100 のユーザー情報をクエリするとします。ここでは userId mod n、つまり 100 mod 3 などの特定のハッシュ アルゴリズムを適用すると、結果は 1 になります。したがって、ユーザー番号 100 からのリクエストは、最終的にサーバー番号 1 によって受信され、処理されます。
これにより、無効なクエリの問題が解決されます。
しかし、そのような解決策はどのような問題を引き起こすのでしょうか?
拡張または縮小すると、大量のデータが移行されます。データの少なくとも 50% が影響を受けます。
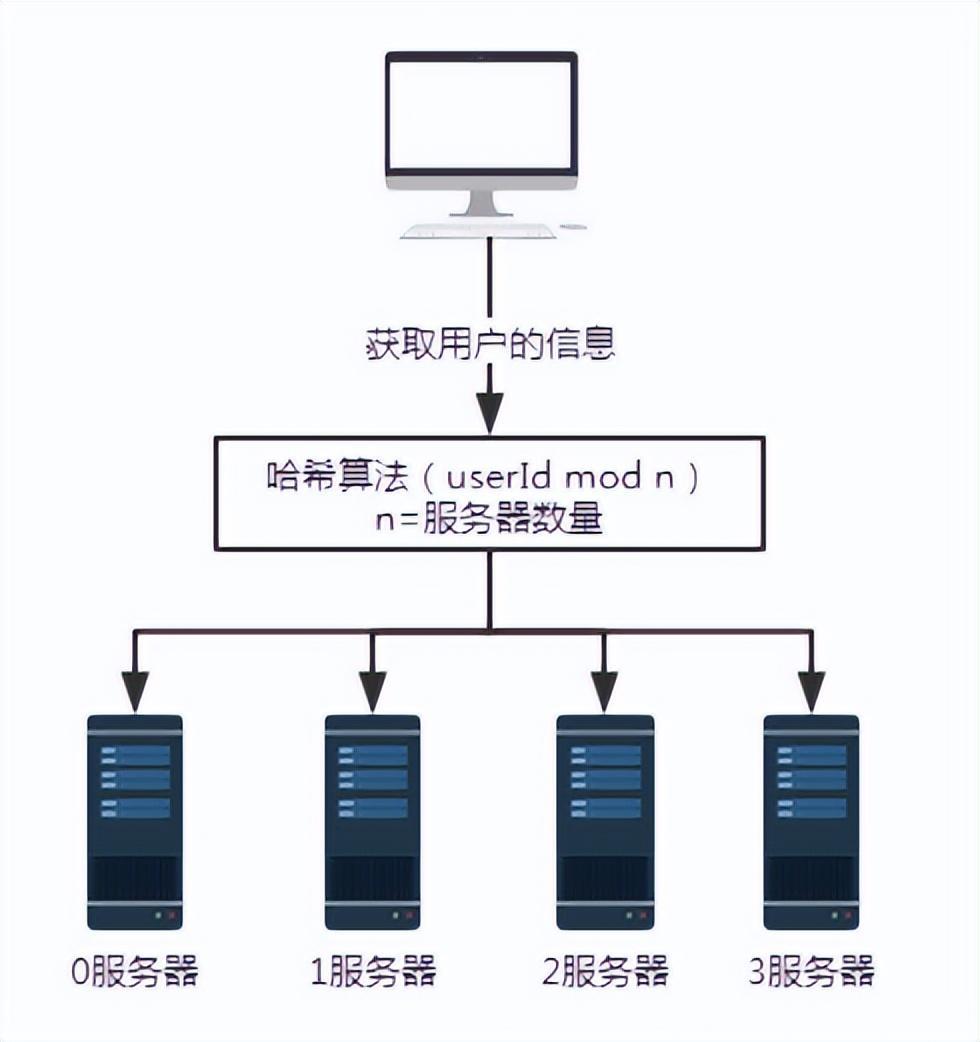 図 3 サーバーの追加
図 3 サーバーの追加
問題を説明するために、サーバー 3 を追加します。サーバーの数 n が 3 から 4 に変更されます。ユーザー番号100のユーザー情報を問い合わせた場合、100を4で割った余りは0となります。このとき、リクエストはサーバー 0 で受信されます。
サーバ台数が 3 台の場合、ユーザ番号 100 のリクエストはサーバ 1 で処理されます。- サーバー数が 4 の場合、ユーザー番号 100 のリクエストはサーバー 0 で処理されます。
- したがって、サーバーの数が増減すると、必ず大量のデータの移行が発生します。
このハッシュ アルゴリズムの利点はそのシンプルさと使いやすさにあるため、ほとんどのシャーディング ルールでこれが採用されています。一般に、パーティションの数はデータ量に基づいて事前に見積もられます。
このテクノロジーの欠点は、ネットワーク内のノードの数が拡大または縮小すると、ノードのマッピング関係を再計算する必要があり、その結果、データの移行が必要になることです。したがって、容量を拡張するときは、すべてのデータ マッピングが中断されて完全な移行が発生することを避けるために、通常、容量を 2 倍にすることが使用され、データの 50% のみが移行されます。
3. 一貫性のあるハッシュ アルゴリズム
** 一貫性のあるハッシュ アルゴリズムは、1997 年に MIT の Karger とその共同研究者によって提案されました。 ** その動作プロセスは次のとおりです. まず、IP またはその他の情報に基づいてキャッシュ ノードのハッシュが生成され、このハッシュが [0, 232 - 1] のリングに投影されます。クエリまたは書き込みリクエストがあるたびに、キャッシュ アイテムのキーのハッシュ値が生成されます。次に、指定された値以上のハッシュ値を持つキャッシュ ノード内の最初のノードを見つけて、このノードに対してキャッシュ クエリまたは書き込み操作を実行する必要があります。現在のノードの有効期限が切れると、次のキャッシュ クエリまたは書き込み時に、現在のキャッシュ エントリより大きいハッシュを持つ別のキャッシュ ノードを検索できます。一般的な効果は次の図に示すように、各キャッシュ ノードはリング上の位置を占めます。キャッシュ項目のキーのハッシュ値がキャッシュ ノードのハッシュ値より小さい場合、キャッシュ項目はキャッシュ ノードに保存されるか、キャッシュ ノードから読み取られます。以下の緑色のマークに対応するキャッシュ アイテムは、ノード キャッシュ 2 に格納されます。キャッシュ アイテムは当初、キャッシュ 3 ノードに格納される予定でしたが、このノードのダウンタイムにより、最終的にキャッシュ 4 ノードに格納されました。
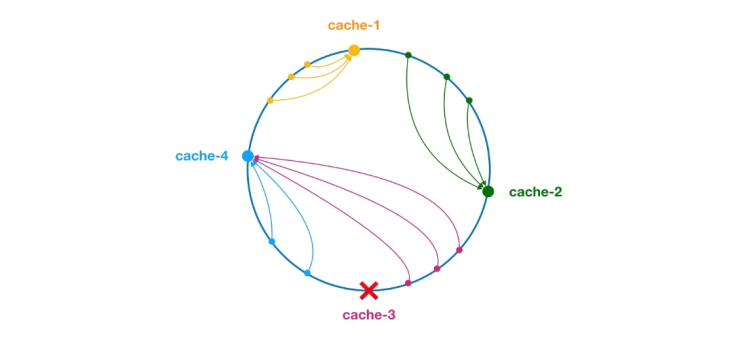
図 4 一貫性のあるハッシュ アルゴリズム
一貫性のあるハッシュ アルゴリズムでは、ノードの追加であってもノードのダウンタイムであっても、影響を受ける間隔は増加するかクラッシュするだけです。ハッシュリング空間内で反時計回りに最初に遭遇したサーバー間の間隔であり、他の間隔は影響を受けません。
しかし、コンシステント ハッシュにも問題があります。
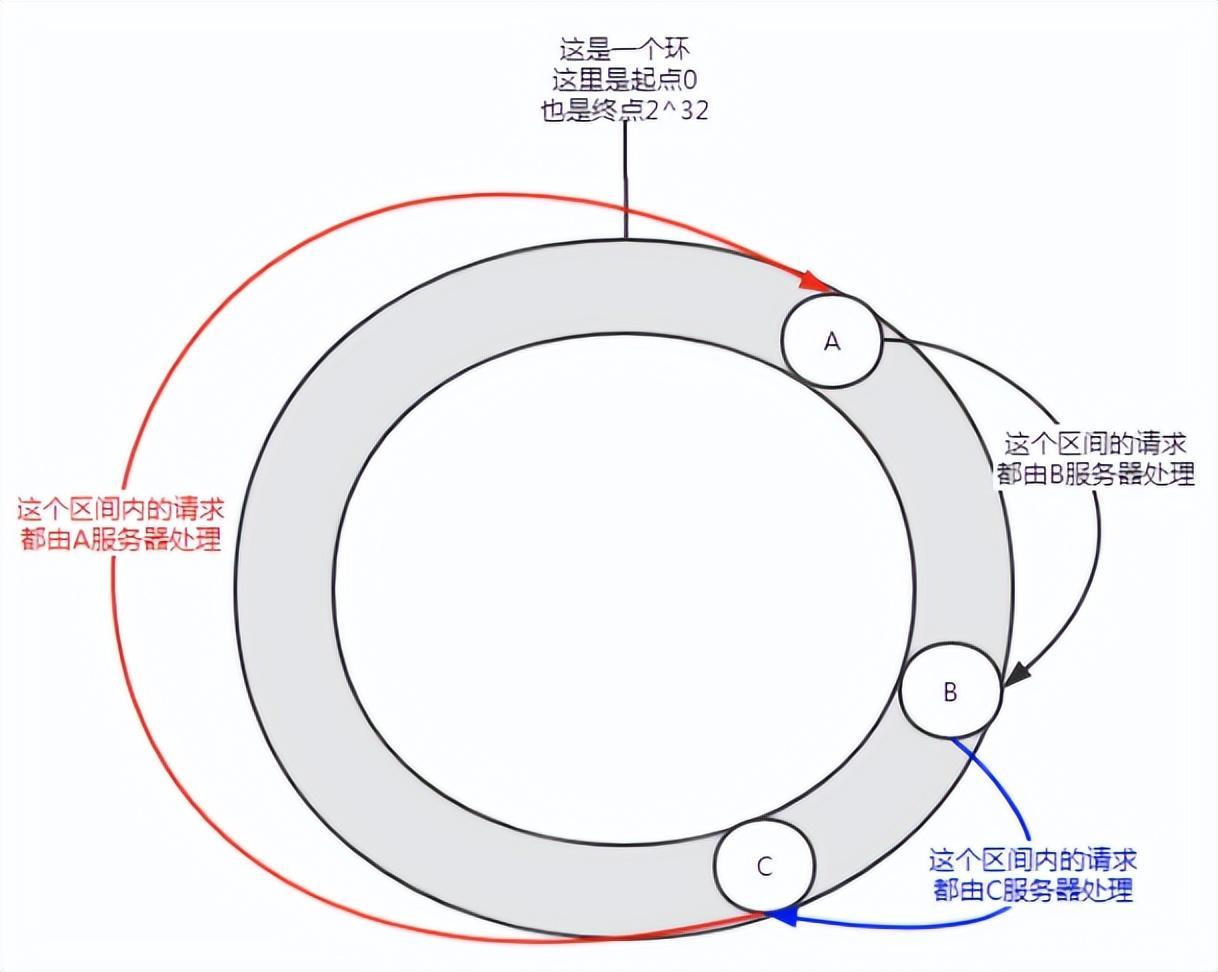
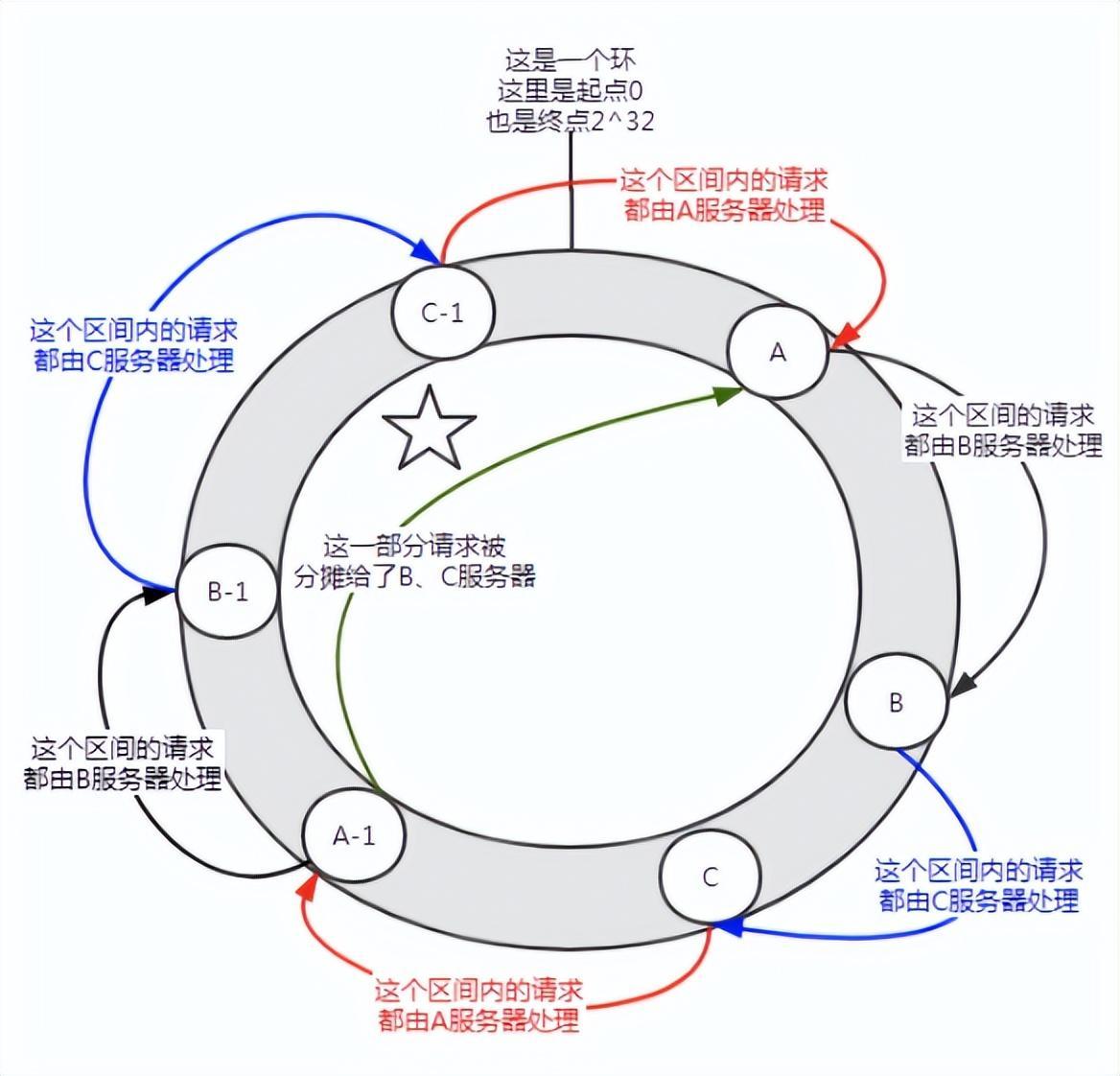
図 5 データ スキュー
この分散状況では、ノードが少ない場合に発生する可能性があります。サービス A はほとんどのリクエストを処理します。この状況はデータ スキューと呼ばれます。
それでは、データの偏りの問題を解決するにはどうすればよいでしょうか?
仮想ノードに参加します。
まず第一に、サーバーは必要に応じて複数の仮想ノードを持つことができます。サーバーに n 個の仮想ノードがあるとします。ハッシュ計算では、IP アドレス、ポート番号、番号の組み合わせを使用してハッシュ値を計算できます。番号は0からnまでの数字です。これらの n 個のノードはすべて、同じ IP アドレスとポート番号を共有するため、同じマシンを指します。
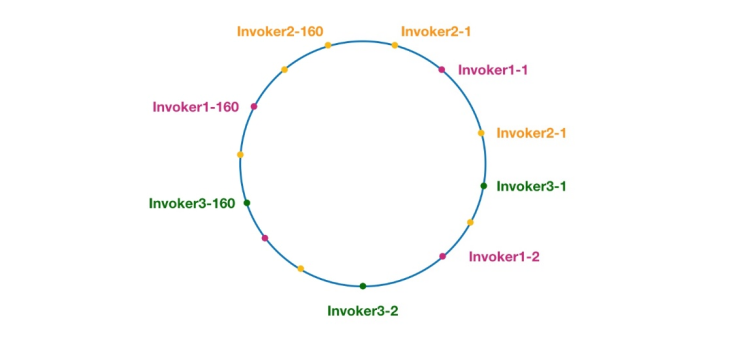
public class ConsistentHashLoadBalance extends AbstractLoadBalance {private final ConcurrentMap<String, ConsistentHashSelector<?>> selectors = new ConcurrentHashMap<String, ConsistentHashSelector<?>>();@Overrideprotected <T> Invoker<T> doSelect(List<Invoker<T>> invokers, URL url, Invocation invocation) {String methodName = RpcUtils.getMethodName(invocation);String key = invokers.get(0).getUrl().getServiceKey() + "." + methodName;// 获取 invokers 原始的 hashcodeint identityHashCode = System.identityHashCode(invokers);ConsistentHashSelector<T> selector = (ConsistentHashSelector<T>) selectors.get(key);// 如果 invokers 是一个新的 List 对象,意味着服务提供者数量发生了变化,可能新增也可能减少了。// 此时 selector.identityHashCode != identityHashCode 条件成立if (selector == null || selector.identityHashCode != identityHashCode) {// 创建新的 ConsistentHashSelectorselectors.put(key, new ConsistentHashSelector<T>(invokers, methodName, identityHashCode));selector = (ConsistentHashSelector<T>) selectors.get(key);}// 调用 ConsistentHashSelector 的 select 方法选择 Invokerreturn selector.select(invocation);}private static final class ConsistentHashSelector<T> {...}}上記のように、doSelect メソッドは主に、呼び出し元リストが変更されたかどうかの検出や ConsistentHashSelector の作成など、いくつかの準備作業を実行します。これらのタスクが完了すると、ConsistentHashSelector の select メソッドが呼び出され、負荷分散ロジックが実行されます。 select メソッドを分析する前に、まず、次のように一貫性のあるハッシュ セレクター ConsistentHashSelector の初期化プロセスを見てみましょう。private static final class ConsistentHashSelector<T> {// 使用 TreeMap 存储 Invoker 虚拟节点private final TreeMap<Long, Invoker<T>> virtualInvokers;private final int replicaNumber;private final int identityHashCode;private final int[] argumentIndex;ConsistentHashSelector(List<Invoker<T>> invokers, String methodName, int identityHashCode) {this.virtualInvokers = new TreeMap<Long, Invoker<T>>();this.identityHashCode = identityHashCode;URL url = invokers.get(0).getUrl();// 获取虚拟节点数,默认为160this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160);// 获取参与 hash 计算的参数下标值,默认对第一个参数进行 hash 运算String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0"));argumentIndex = new int[index.length];for (int i = 0; i < index.length; i++) {argumentIndex[i] = Integer.parseInt(index[i]);}for (Invoker<T> invoker : invokers) {String address = invoker.getUrl().getAddress();for (int i = 0; i < replicaNumber / 4; i++) {// 对 address + i 进行 md5 运算,得到一个长度为16的字节数组byte[] digest = md5(address + i);// 对 digest 部分字节进行4次 hash 运算,得到四个不同的 long 型正整数for (int h = 0; h < 4; h++) {// h = 0 时,取 digest 中下标为 0 ~ 3 的4个字节进行位运算// h = 1 时,取 digest 中下标为 4 ~ 7 的4个字节进行位运算// h = 2, h = 3 时过程同上long m = hash(digest, h);// 将 hash 到 invoker 的映射关系存储到 virtualInvokers 中,// virtualInvokers 需要提供高效的查询操作,因此选用 TreeMap 作为存储结构virtualInvokers.put(m, invoker);}}}}}
ConsistentHashSelector 的构造方法执行了一系列的初始化逻辑,比如从配置中获取虚拟节点数以及参与 hash 计算的参数下标,默认情况下只使用第一个参数进行 hash。需要特别说明的是,ConsistentHashLoadBalance 的负载均衡逻辑只受参数值影响,具有相同参数值的请求将会被分配给同一个服务提供者。注意到 ConsistentHashLoadBalance 无需考虑权重的影响。
在获取虚拟节点数和参数下标配置后,接下来要做的事情是计算虚拟节点 hash 值,并将虚拟节点存储到 TreeMap 中。ConsistentHashSelector的初始化工作在此完成。接下来,我们来看看 select 方法的逻辑。
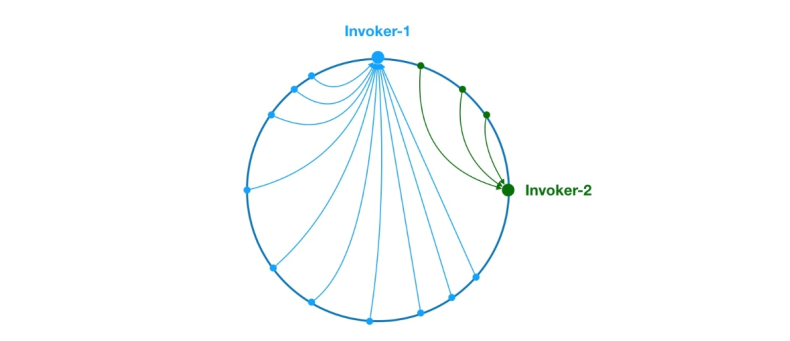
public Invoker<T> select(Invocation invocation) {// 将参数转为 keyString key = toKey(invocation.getArguments());// 对参数 key 进行 md5 运算byte[] digest = md5(key);// 取 digest 数组的前四个字节进行 hash 运算,再将 hash 值传给 selectForKey 方法,// 寻找合适的 Invokerreturn selectForKey(hash(digest, 0));}private Invoker<T> selectForKey(long hash) {// 到 TreeMap 中查找第一个节点值大于或等于当前 hash 的 InvokerMap.Entry<Long, Invoker<T>> entry = virtualInvokers.tailMap(hash, true).firstEntry();// 如果 hash 大于 Invoker 在圆环上最大的位置,此时 entry = null,// 需要将 TreeMap 的头节点赋值给 entryif (entry == null) {entry = virtualInvokers.firstEntry();}// 返回 Invokerreturn entry.getValue();}
如上,选择的过程相对比较简单了。首先,需要对参数进行 md5 和 hash 运算,以生成一个哈希值。接着使用这个值去 TreeMap 中查找需要的 Invoker。
到此关于 ConsistentHashLoadBalance 就分析完了。
在阅读 ConsistentHashLoadBalance 源码之前,建议读者先补充背景知识,不然看懂代码逻辑会有很大难度。
五、应用场景
- DNS 负载均衡最早的负载均衡技术是通过 DNS 来实现的,在 DNS 中为多个地址配置同一个名字,因而查询这个名字的客户机将得到其中一个地址,从而使得不同的客户访问不同的服务器,达到负载均衡的目的。DNS 负载均衡是一种简单而有效的方法,但是它不能区分服务器的差异,也不能反映服务器的当前运行状态。
- 代理服务器负载均衡使用代理服务器,可以将请求转发给内部的服务器,使用这种加速模式显然可以提升静态网页的访问速度。然而,也可以考虑这样一种技术,使用代理服务器将请求均匀转发给多台服务器,从而达到负载均衡的目的。
- 地址转换网关负载均衡支持负载均衡的地址转换网关,可以将一个外部 IP 地址映射为多个内部 IP 地址,对每次 TCP 连接请求动态使用其中一个内部地址,达到负载均衡的目的。
- 协议内部支持负载均衡除了这三种负载均衡方式之外,有的协议内部支持与负载均衡相关的功能,例如 HTTP 协议中的重定向能力等,HTTP 运行于 TCP 连接的最高层。
- NAT 负载均衡 NAT(Network Address Translation 网络地址转换)简单地说就是将一个 IP 地址转换为另一个 IP 地址,一般用于未经注册的内部地址与合法的、已获注册的 Internet IP 地址间进行转换。适用于解决 Internet IP 地址紧张、不想让网络外部知道内部网络结构等的场合下。
- 反向代理负载均衡普通代理方式是代理内部网络用户访问 internet 上服务器的连接请求,客户端必须指定代理服务器,并将本来要直接发送到 internet 上服务器的连接请求发送给代理服务器处理。反向代理(Reverse Proxy)方式是指以代理服务器来接受 internet 上的连接请求,然后将请求转发给内部网络上的服务器,并将从服务器上得到的结果返回给 internet 上请求连接的客户端,此时代理服务器对外就表现为一个服务器。反向代理负载均衡技术是把将来自 internet 上的连接请求以反向代理的方式动态地转发给内部网络上的多台服务器进行处理,从而达到负载均衡的目的。
- 混合型负载均衡在有些大型网络,由于多个服务器群内硬件设备、各自的规模、提供的服务等的差异,可以考虑给每个服务器群采用最合适的负载均衡方式,然后又在这多个服务器群间再一次负载均衡或群集起来以一个整体向外界提供服务(即把这多个服务器群当做一个新的服务器群),从而达到最佳的性能。将这种方式称之为混合型负载均衡。此种方式有时也用于单台均衡设备的性能不能满足大量连接请求的情况下。
作者:京东物流 乔杰
来源:京东云开发者社区
以上がDubbo ロード バランシング戦略のコンシステント ハッシュの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。