
ホームページ >テクノロジー周辺機器 >AI >貧困は私を準備させてくれる
貧困は私を準備させてくれる

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-26 08:32:45859ブラウズ

##1. 事前トレーニングは必要ですか?

事前トレーニングの効果は直接的であり、必要なリソースは法外なものとなることがよくあります。この事前トレーニング方法が存在する場合、その起動に必要なコンピューティング能力、データ、人的リソースは非常に少なく、さらには 1 人の人物と 1 枚のカードの元のコーパスだけで済みます。教師なしデータ処理と事前トレーニングを独自のドメインに転送した後、ゼロサンプル NLG、NLG、およびベクトル表現の推論機能を取得できます。他のベクトル表現の再現能力は BM25 を超えています。試すことに興味がありますか?

# 何かをしたいですか? 測定して決定してください入出力。事前トレーニングは非常に重要であり、実装する前にいくつかの前提条件とリソース、および期待される十分なメリットが必要です。通常必要とされる条件は、十分なコーパス構築であること、一般に、量より質の方が稀であるため、コーパスの質は緩和できるが、量は十分でなければならないこと、第二に、相応の人材予備力と人的資源予算があることである。比較, , 小さなモデルはトレーニングが容易で障害が少ないですが、大きなモデルはより多くの問題に遭遇します。最後に重要なのはコンピューティング リソースです。シナリオと人材のマッチングによると、それは人材に依存します。大容量メモリのグラフィックカード。事前トレーニングによってもたらされるメリットも非常に直感的です モデルの移行により効果の向上に直結します 改善の度合いは事前トレーニングの投資と分野の違いに直接関係します 最終的なメリットはモデルの改善とビジネス規模によって得られます。
#今回のシナリオでは、データ分野は一般分野とは大きく異なり、語彙も大幅に置き換える必要があり、ビジネス規模は十分です。事前トレーニングされていない場合、モデルは下流のタスクごとに特別に微調整されます。事前トレーニングによって期待される効果は確実です。私たちのコーパスは質は劣りますが、量的には十分です。コンピューティング能力のリソースは非常に限られているため、対応する才能の予備量と一致させることで補うことができます。この時点で、事前トレーニングの条件はすでに満たされています。
事前トレーニングをどのように開始するかを直接決定する要因は、メンテナンスが必要な下流モデルが多すぎることです。これには特に機械と人間の負担がかかります。専用のモデルをトレーニングするために大量のデータを準備すると、モデル管理の複雑さが大幅に増加します。そこで私たちは事前トレーニングを検討し、すべての下流モデルに利益をもたらす統合された事前トレーニング タスクを構築したいと考えています。これを行う場合、一夜にして達成されるものではありません。維持する必要があるモデルが増えるほど、より多くのモデルの経験が必要になります。自己教師あり学習、対照学習、マルチタスク学習などを含む、以前の複数のプロジェクトの経験と組み合わせると、実験と反復を繰り返した後、Fusion が形成したモデル。
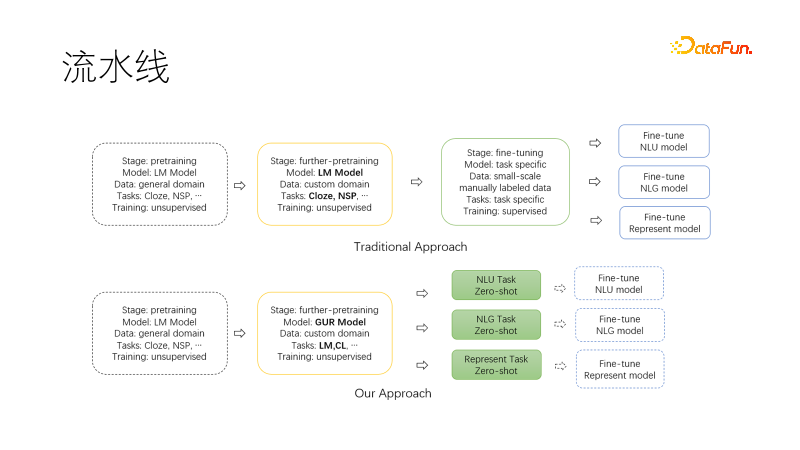
#次の図は、私たちが提案した新しいパラダイムです。私たちの分野に移行して事前トレーニングを続けるとき、共同言語モデリング タスクと対照学習タスクを使用して、モデルにはゼロサンプル NLU、NLG、およびベクトル表現機能があり、これらの機能はモデル化されており、オンデマンドで使用できます。このようにすることで、特にプロジェクトの開始時に維持する必要があるモデルが少なくなり、研究に直接使用でき、さらに微調整が必要な場合には、必要なデータ量も大幅に削減されます。
#2. 事前トレーニングの方法
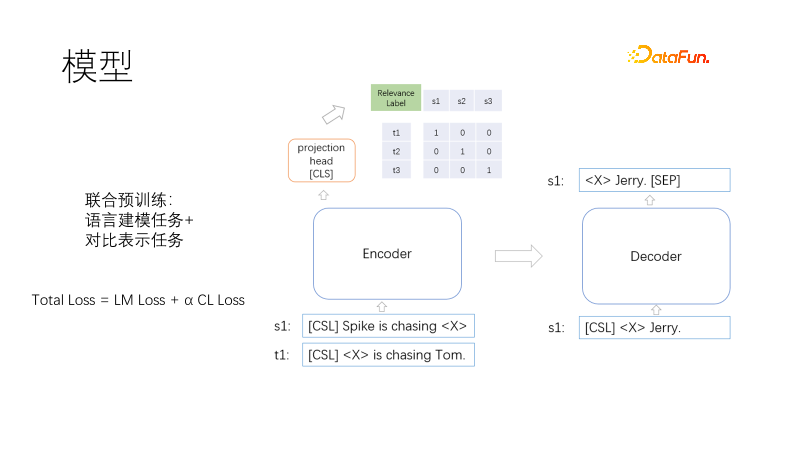 ##これは、Transformer のエンコーダー、デコーダー、ベクトル表現ヘッドを含む、事前トレーニングされたモデル アーキテクチャです。
##これは、Transformer のエンコーダー、デコーダー、ベクトル表現ヘッドを含む、事前トレーニングされたモデル アーキテクチャです。
事前トレーニングの目標には、言語モデリングと対比表現が含まれます。損失関数は、総損失 = LM 損失 α CL 損失です。言語モデリング タスクと対比表現タスクは共同でトレーニングされます。ここで、αは重み係数を表します。言語モデリングでは、マスク部分のみをデコードする T5 と同様のマスク モデルを使用します。対比表現タスクは CLIP に似ています。バッチ内には、関連するトレーニング陽性サンプルとその他の非陰性サンプルのペアがあります。各サンプル ペア (i, I) i には、陽性サンプル I とその他のサンプルがあります。は、負のサンプルです。対称クロスエントロピー損失を使用して、正のサンプルの表現を近づけ、負のサンプルの表現を遠くに強制します。 T5 デコードを使用すると、デコード長を短縮できます。非線形ベクトル表現は、ヘッド ローディング エンコーダーの上に配置されています。1 つは、シナリオ内でベクトル表現を高速化する必要があるためであり、もう 1 つは、示されている 2 つの関数がトレーニング ターゲットの競合を防ぐために遠くで動作するためです。ここで疑問が生じます。Cloze タスクは非常に一般的であり、サンプルは必要ありません。では、類似したサンプルのペアはどのようにして得られるのでしょうか?

もちろん、事前トレーニング方法として、サンプル ペアを次のようにマイニングする必要があります。教師なしアルゴリズム。通常、情報検索の分野で肯定的なサンプルをマイニングするために使用される基本的な方法は、文書内の複数の断片をマイニングし、それらが関連していると想定する逆クローズです。ここでは、文書を文に分割し、文のペアを列挙します。最長の共通部分文字列を使用して、2 つの文に関連性があるかどうかを判断します。図に示すように、正負の文のペアを2つとり、その最長共通部分文字列がある程度長ければ似ていると判断し、そうでなければ似ていないと判断します。閾値は自分で決めることができ、例えば長文の場合は漢字が 3 文字、英語の文字数が 3 文字必要になりますが、短文の場合はよりリラックスできます。
#2 つの目標は矛盾するため、意味的等価性ではなく相関性をサンプル ペアとして使用します。上の図にあるように、猫がネズミを捕まえるのと、ネズミが猫を捕まえるのは、意味は逆ですが関連しています。私たちのシナリオ検索は主に関連性に焦点を当てています。さらに、相関関係は意味的等価性よりも範囲が広く、相関性に基づいて継続的に微調整を行うには意味的等価性の方が適しています。
#複数回フィルタリングされる文もあれば、フィルタリングされない文もあります。選択される文の頻度を制限します。失敗した文については、肯定的なサンプルとしてコピーしたり、選択した文につなぎ合わせたり、逆クローゼを肯定的なサンプルとして使用したりできます。
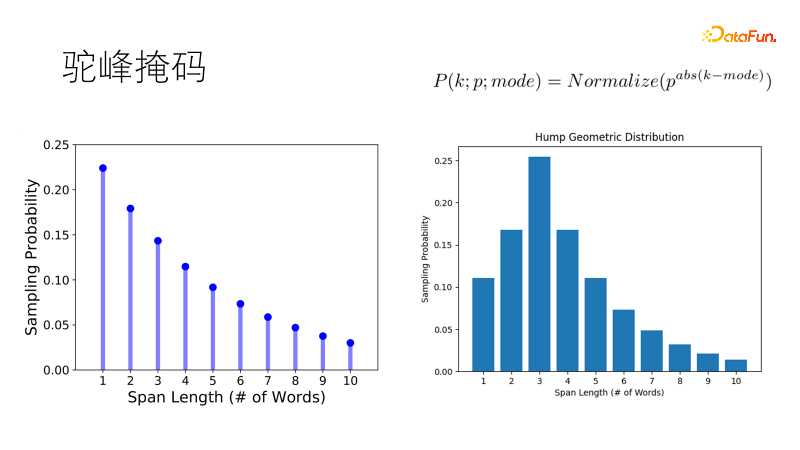
SpanBert などの従来のマスキング手法では、幾何学的分布を使用してマスク長をサンプリングします。マスクが短いほど確率が高く、マスクが長いほど長くなります。マスクの確率が高く、マスクの確率が低く、長い文章に適しています。しかし、コーパスは断片化されており、1 ~ 20 単語の短い文に直面した場合、従来の傾向として 1 つの二重単語ではなく 2 つの単一単語をマスクする傾向があり、これは私たちの期待に応えません。そこで、最適な長さをサンプリングする確率が最も高くなるようにこの分布を改良し、他の長さの確率はラクダのこぶのように徐々に減少し、ラクダのこぶの幾何学的分布になり、短い文ではより堅牢になりました。豊富なシナリオ。
3. 実験結果
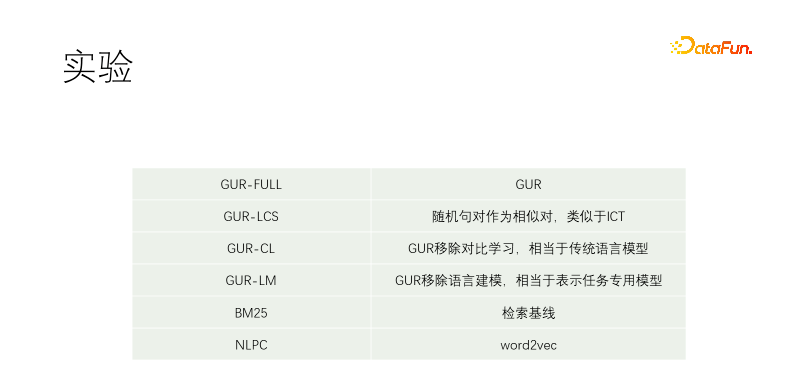
対照実験を実施しました。言語モデリングとベクトル対比表現を使用する GUR-FULL が含まれます。UR-LCS サンプル ペアは LCS によってフィルタリングされません。UR-CL には従来の言語モデルと同等の対比表現学習がありません。GUR-LM にはベクトルのみがあります。言語モデリング学習を行わない対照表現学習は、特に下流タスクの微調整に相当します。NLPC は、Baidu の word2vec 演算子です。
#実験は T5-small から開始され、事前トレーニングが継続されます。トレーニング コーパスには、Wikipedia、Wikisource、CSL、および独自のコーパスが含まれます。私たち自身のコーパスはマテリアル ライブラリからキャプチャされたもので、品質は非常に低く、最高品質の部分はマテリアル ライブラリのタイトルです。したがって、他の文書で肯定的なサンプルを探す場合、ほぼすべてのテキストのペアがスクリーニングされますが、私たちのコーパスでは、テキストのすべての文と一致するためにタイトルが使用されます。 GUR-LCS は LCS によって選択されていません。このようにしないとサンプルペアが悪すぎます。このようにすると、GUR-FULL との差がさらに小さくなります。
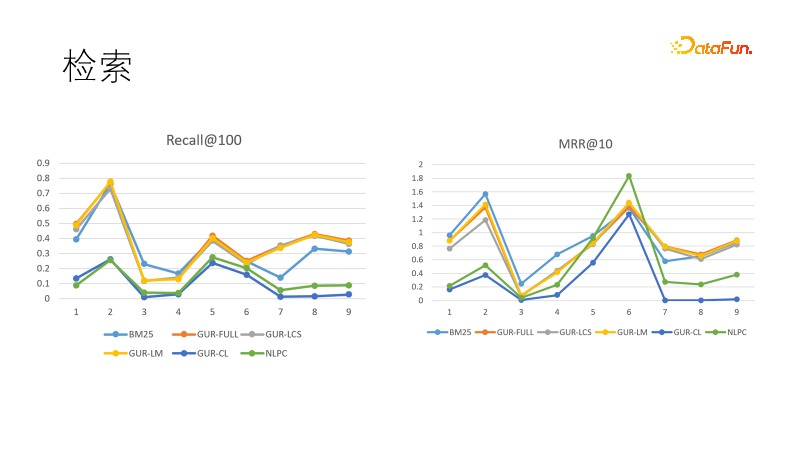
いくつかの検索タスクに対するモデルのベクトル表現の効果を評価します。左の図は、いくつかのモデルの再現パフォーマンスを示しており、ベクトル表現を通じて学習したモデルが最も優れたパフォーマンスを示し、BM25 を上回っていることがわかりました。順位目標も比較しましたが、今回はBM25が逆転優勝しました。これは、密モデルが強い一般化能力を持ち、疎モデルが強い決定論を持ち、この 2 つが相互に補完できることを示しています。実際、情報検索分野の下流タスクでは、密モデルと疎モデルが併用されることがよくあります。
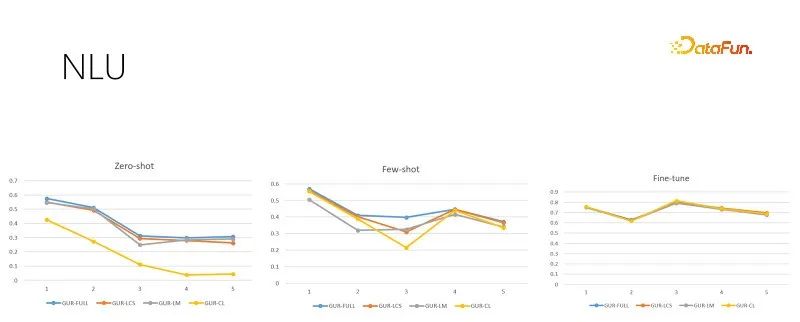
#上の図は、さまざまなトレーニング サンプル サイズでの NLU 評価タスクを示しています。カテゴリは数十から数百あり、その効果はACCスコアによって評価されます。また、GUR モデルは、分類ラベルをベクトルに変換して、各文に最も近いラベルを見つけます。上の図は、左から右に、トレーニング サンプル サイズの増加に応じて、ゼロ サンプル、小さなサンプル、および十分な微調整評価を示しています。右側の図は、十分な微調整後のモデルのパフォーマンスです。これは、各サブタスクの難易度を示しており、ゼロサンプルおよび小規模サンプルのパフォーマンスの上限でもあります。 GUR モデルは、ベクトル表現に依存することにより、一部の分類タスクでゼロサンプル推論を達成できることがわかります。そして、GUR モデルの小規模サンプル能力は最も優れています。
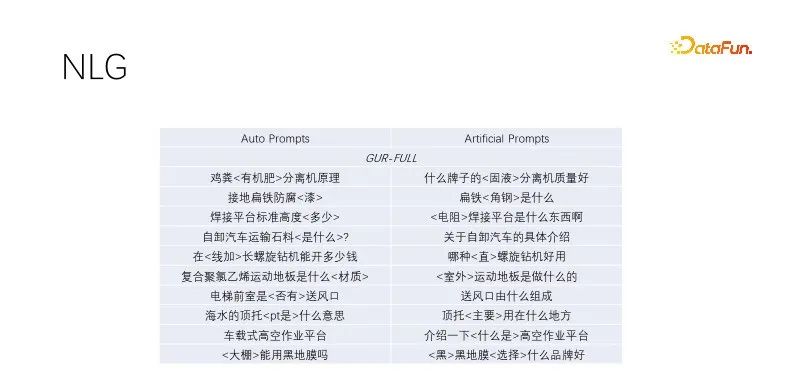
#これは、NLG でのゼロサンプルのパフォーマンスです。タイトルの生成とクエリ拡張を行うとき、高品質のトラフィックでタイトルをマイニングし、キーワードを保持し、キーワード以外をランダムにマスクします。言語モデリングによってトレーニングされたモデルは良好に機能します。この自動プロンプト効果は、手動で構築されたターゲット効果に似ており、より多様性があり、大量生産に対応できます。言語モデリング タスクを実行したいくつかのモデルは同様に動作します。上の図は GUR モデルの例を使用しています。
4. 結論
この記事では、新しい事前トレーニング パラダイムを提案します。上記の対照実験は、次のことを示しています。共同訓練では目的の衝突は生じません。 GUR モデルの事前トレーニングを続けると、言語モデリング機能を維持しながらベクトル表現機能を向上させることができます。事前トレーニングは 1 回で、元のサンプルがどこにもない状態で推論します。事業部門向けの低コストの事前研修に最適です。

#上記のリンクにはトレーニングの詳細が記録されています。参考詳細については、論文の引用を参照してください。とコード バージョンは論文よりわずかに新しいです。 AIの民主化に少しでも貢献できればと思っています。大規模モデルと小規模モデルにはそれぞれ独自のアプリケーション シナリオがあり、GUR モデルは下流のタスクに直接使用できるだけでなく、大規模モデルと組み合わせて使用することもできます。パイプラインでは、最初に小さなモデルを認識に使用し、次に大きなモデルを使用してタスクを指示します。大きなモデルは小さなモデルのサンプルを生成することもでき、GUR の小さなモデルは大きなモデルのベクトル検索を提供することもできます。
この論文のモデルは、複数の実験を調査するために選択された小規模なモデルですが、実際には、より大きなモデルを選択した場合のゲインは明らかです。私たちの探索は十分ではなく、さらなる作業が必要です。もしよろしければ、laohur@gmail.com までご連絡ください。皆さんと一緒に進歩することを楽しみにしています。
以上が貧困は私を準備させてくれるの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。