


Scrapy は、Web サイト上のデータを簡単にクロールできる強力な Python フレームワークです。ただし、クロールしたい Web サイトに確認コードがある場合、問題が発生します。 CAPTCHA の目的は、自動化されたクローラーによる Web サイトへの攻撃を防ぐことであるため、CAPTCHA は非常に複雑になり、解読が困難になる傾向があります。この投稿では、Scrapy フレームワークを使用して CAPTCHA を識別および処理し、クローラがこれらの防御を回避できるようにする方法について説明します。
確認コードとは何ですか?
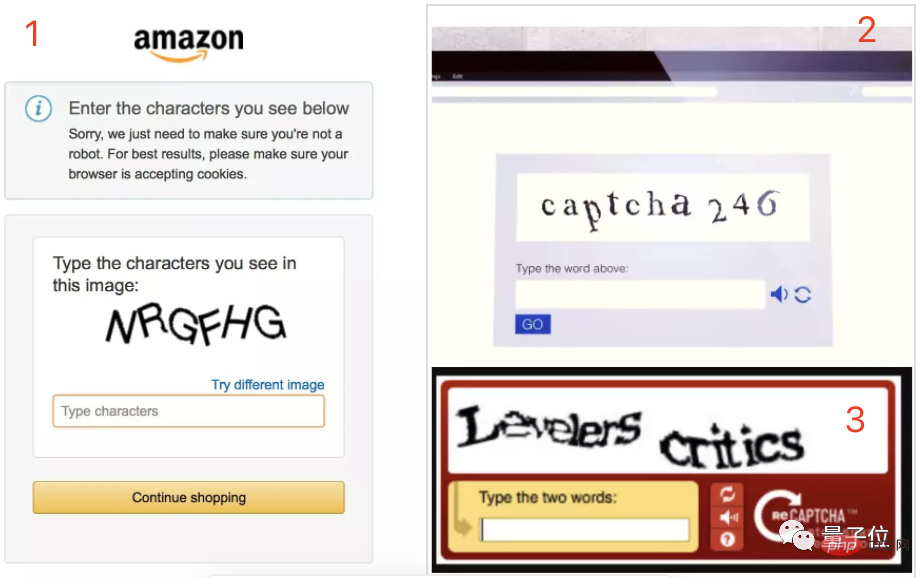
キャプチャは、ユーザーが機械ではなく本物の人間であることを証明するために使用されるテストです。通常、これは難読化されたテキスト文字列または判読不能な画像であり、ユーザーは表示内容を手動で入力または選択する必要があります。 CAPTCHA は、自動化されたボットやスクリプトを捕捉して、Web サイトを悪意のある攻撃や悪用から保護するように設計されています。
通常、CAPTCHA には次の 3 種類があります。
- テキスト CAPTCHA: ユーザーは、自分がボットではなく人間のユーザーであることを証明するために、テキスト文字列をコピーして貼り付ける必要があります。
- 番号確認コード: ユーザーは、表示された番号を入力ボックスに入力する必要があります。
- 画像検証コード: ユーザーは、表示された画像内の文字または数字を入力ボックスに入力する必要があります。これは、画像内の文字や数字が歪む可能性があるため、通常、解読が最も困難なタイプです。場所が間違っているか、その他の視覚的なノイズがあります。
なぜ確認コードを処理する必要があるのですか?
クローラーは大規模に自動化されることが多いため、簡単にロボットであると識別され、Web サイトからのデータ取得が禁止される可能性があります。これを防ぐために CAPTCHA が導入されました。 ep が検証コード段階に入ると、Scrapy クローラーはユーザー入力の待機を停止するため、データのクロールを続行できなくなり、クローラーの効率と整合性が低下します。
したがって、クローラーが自動的にタスクを通過してタスクを続行できるように、検証コードを処理する方法が必要です。通常、検証コードの認識を完了するにはサードパーティのツールまたは API を使用します。これらのツールと API は、機械学習と画像処理アルゴリズムを使用して画像と文字を認識し、結果をプログラムに返します。
Scrapy で検証コードを処理するにはどうすればよいですか?
Scrapy の settings.py ファイルを開き、DOWNLOADER_MIDDLEWARES フィールドを変更して次のプロキシを追加する必要があります:
DOWNLOADER_MIDDLEWARES = {'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 350、'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 400、
'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700、'scrapy.contrib. downloadermiddleware.httpproxy.HttpProxyMiddleware': 750,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400,'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550,
'scrapy.contrib.downloadermiddleware。 ajaxcrawl.AjaxCrawlMiddleware': 900,'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 800,
'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830,'scrapy.contrib.downloadermiddleware.stats.DownloaderSt ats ' : 850,
'tutorial.middlewares.CaptchaMiddleware': 999}
この例では、CaptchaMiddleware を使用して検証コードを処理します。 CaptchMiddleware は、ダウンロード リクエストを処理し、必要に応じて API を呼び出して検証コードを識別し、リクエストに検証コードを入力して戻って実行を継続するカスタム ミドルウェア クラスです。
コード例:
class CaptchaMiddleware(object):
def __init__(self):
self.client = CaptchaClient()
self.max_attempts = 5
def process_request(self, request, spider):
# 如果没有设置dont_filter则默认开启
if not request.meta.get('dont_filter', False):
request.meta['dont_filter'] = True
if 'captcha' in request.meta:
# 带有验证码信息
captcha = request.meta['captcha']
request.meta.pop('captcha')
else:
# 没有验证码则获取
captcha = self.get_captcha(request.url, logger=spider.logger)
if captcha:
# 如果有验证码则添加到请求头
request = request.replace(
headers={
'Captcha-Code': captcha,
'Captcha-Type': 'math',
}
)
spider.logger.debug(f'has captcha: {captcha}')
return request
def process_response(self, request, response, spider):
# 如果没有验证码或者验证码失败则不重试
need_retry = 'Captcha-Code' in request.headers.keys()
if not need_retry:
return response
# 如果已经尝试过,则不再重试
retry_times = request.meta.get('retry_times', 0)
if retry_times >= self.max_attempts:
return response
# 验证码校验失败则重试
result = self.client.check(request.url, request.headers['Captcha-Code'])
if not result:
spider.logger.warning(f'Captcha check fail: {request.url}')
return request.replace(
meta={
'captcha': self.get_captcha(request.url, logger=spider.logger),
'retry_times': retry_times + 1,
},
dont_filter=True,
)
# 验证码校验成功则继续执行
spider.logger.debug(f'Captcha check success: {request.url}')
return response
def get_captcha(self, url, logger=None):
captcha = self.client.solve(url)
if captcha:
if logger:
logger.debug(f'get captcha [0:4]: {captcha[0:4]}')
return captcha
return None
このミドルウェアでは、CaptchaClient オブジェクトをキャプチャ ソリューション ミドルウェアとして使用し、複数のキャプチャ ソリューションを使用できます。ミドルウェア。
注意事項
このミドルウェアを実装する場合は、次の点に注意してください。
- 検証コードの識別と処理には、サードパーティ ツールの使用が必要です。法的ライセンスを取得していることを確認し、メーカーの要件に従って使用する必要があります。
- このようなミドルウェアを追加した後は、リクエスト プロセスがより複雑になるため、開発者はプログラムが適切に動作することを確認するために慎重にテストとデバッグを行う必要があります。
結論
検証コードの認識と処理に Scrapy フレームワークとミドルウェアを使用することで、検証コード防御戦略を効果的に回避し、ターゲット Web サイトの効果的なクローリングを実現できます。この方法は通常、検証コードを手動で入力するよりも時間と労力を節約し、より効率的かつ正確です。ただし、サードパーティのツールや API を使用する前に、それらのライセンス契約と要件を読み、それらの要件に従うことに注意することが重要です。
以上がScrapy のパワー: 検証コードを認識して処理する方法?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 手机为什么收不到验证码Aug 17, 2023 pm 02:49 PM
手机为什么收不到验证码Aug 17, 2023 pm 02:49 PM手机收不到验证码是网络问题、手机设置问题、手机运营商问题和个人设置问题导致的。详情介绍:1、网络问题,手机所处的网络环境不稳定或者信号弱,就有可能导致验证码无法及时送达;2、手机设置问题,不小心将手机的短信或语音功能关闭,或者将验证码的发送号码加入到黑名单中,从而导致验证码无法正常收到;3、手机运营商问题,手机运营商可能会出现故障或者维护,导致验证码无法及时送达等等。
 PHP图片处理案例:如何实现图片的验证码功能Aug 17, 2023 pm 12:09 PM
PHP图片处理案例:如何实现图片的验证码功能Aug 17, 2023 pm 12:09 PMPHP图片处理案例:如何实现图片的验证码功能随着互联网的快速发展,验证码成为了保护网站安全的重要手段之一。验证码是一种通过图像识别技术来确定用户是否为真实用户的验证方式。本文将介绍如何使用PHP来实现图片的验证码功能,并附带代码示例。简介验证码是一张包含随机字符的图片,用户需要输入图片中的字符才能通过验证。实现验证码的主要过程包括生成随机字符、绘制字符到图片
 验证码拦不住机器人了!谷歌AI已能精准识别模糊文字,GPT-4则装瞎求人帮忙Apr 12, 2023 am 09:46 AM
验证码拦不住机器人了!谷歌AI已能精准识别模糊文字,GPT-4则装瞎求人帮忙Apr 12, 2023 am 09:46 AM“最烦登网站时各种奇奇怪怪(甚至变态)的验证码了。”现在,有一个好消息和一个坏消息。好消息就是:AI可以帮你代劳这件事了。不信你瞧,以下是三张识别难度依次递增的真实案例:而这些是一个名为“Pix2Struct”的模型给出的答案:全部准确无误、一字不差有没有?有网友感叹:确定,准确性比我强。所以可不可以做成浏览器插件??不错,有人表示:别看这几个案例相比还算简单,但凡微调一下,我都不敢想象其效果有多厉害了。所以,坏消息就是——验证码马上就要拦不住机器人了!(危险危险危险……)如何做到?Pix2St
 PHP开发指南:实现验证码登录Jul 01, 2023 am 09:27 AM
PHP开发指南:实现验证码登录Jul 01, 2023 am 09:27 AM随着互联网的发展和智能手机的普及,验证码登录功能被越来越多的网站和应用程序采用。验证码登录是一种通过输入正确的验证码来验证用户身份的登录方式,以提高安全性和防止恶意攻击。在PHP开发中,实现简单的验证码登录功能并不复杂,可以通过以下步骤来完成。创建数据库表首先,我们需要在数据库中创建一个用于存储验证码信息的表。表结构可以包含以下字段:id:自增主键phon
 用OCR技术,自动识别各种验证码,工具已开源May 25, 2023 am 10:07 AM
用OCR技术,自动识别各种验证码,工具已开源May 25, 2023 am 10:07 AM今天我在给大家分享一个OCR应用——ddddocr自动识别验证码。前面4个d是“带带弟弟”的首拼音。[/笑哭]。项目地址:https://github.com/sml2h3/ddddocr。使用的时候用pip命令直接安装即可pipinstallddddocr。OCR的核心技术包含两方面,一是目标检测模型检测图片中的文字,二是文字识别模型,将图片中的文字转成文本文字。第一类验证码最简单,它们没有复杂的背景图片,所以目标检测模型可以省略,直接将图片送入文字识别模型即可。识别代码如下:impor
 如何使用PHP创建验证码图片?Sep 13, 2023 am 11:40 AM
如何使用PHP创建验证码图片?Sep 13, 2023 am 11:40 AM如何使用PHP创建验证码图片?验证码(CAPTCHA)是一种常用的验证用户是否为人而不是机器的方法。在网站上,我们经常会看到验证码图片,要求用户输入图片上显示的随机字符或数字,以完成登录、注册、评论等操作。本文将介绍如何使用PHP创建验证码图片,并提供具体的代码示例。一、PHPGD库要创建验证码图片,我们需要使用PHP的GD库。GD库是一个用于处理图像的扩
 react怎么实现手机验证码Jan 04, 2023 am 10:17 AM
react怎么实现手机验证码Jan 04, 2023 am 10:17 AMreact实现手机验证码的方法:1、下载antd button和input组件;2、通过“<Input className={`apiMobileInput`} disabled value={this.props.phoneNumber} />”获取客户的手机号;3、通过“await this.props.sendCode({...})”实现获取验证码即可。
 如何使用 JavaScript 实现验证码功能?Oct 19, 2023 am 10:46 AM
如何使用 JavaScript 实现验证码功能?Oct 19, 2023 am 10:46 AM如何使用JavaScript实现验证码功能?随着网络的发展,验证码已经成为了网站和应用程序中不可或缺的安全机制之一。验证码(VerificationCode)是一种用于判断用户是否为人类而不是机器的技术。通过验证码,网站和应用程序可以防止垃圾信息提交、恶意攻击、机器人爬虫等问题。本文将介绍如何使用JavaScript实现验证码功能,并提供具体的代码


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

AI Hentai Generator
AIヘンタイを無料で生成します。

人気の記事
ホットツール

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター

Dreamweaver Mac版
ビジュアル Web 開発ツール

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません
ホットトピック
 7422
7422 15135952
15135952