
ホームページ >テクノロジー周辺機器 >AI >Meta、わずか 2 秒で実際の人間の音声をシミュレートするオーディオ AI モデルをリリース
Meta、わずか 2 秒で実際の人間の音声をシミュレートするオーディオ AI モデルをリリース

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-21 15:20:171754ブラウズ
最近、Meta は、オーディオ シミュレーションにおいて大きな利点を持つ Voicebox AI モデルをリリースしました。
Voicebox が音声の詳細と音色を正確に識別し、テキスト結果に基づいて音声出力に変換するには、2 秒の音声サンプルのみが必要であると報告されています。

Voicebox は、オーディオの編集、サンプリング、スタイリングに役立つ生成 AI モデルです。
このテクノロジーは、将来クリエイターがオーディオ トラックを簡単に編集できるようにするために使用できると同時に、声帯を損傷した人々を支援し、再び「聞こえる」ようにすることもできます。視覚障害者が友人の書いたメッセージを音で聞くことができるようにするとともに、自分の声で外国語を話せるようにします。
同時に、音声クリップの前後の内容に基づいて、不足している内容を自動的に埋めることもできます。
Meta によると、Voicebox は将来のメタバースの AI アシスタントや NPC に自然でリアルな音声効果を提供し、使用時のユーザーの没入感を大幅に向上させることができます。
Voicebox の多用途性により、次のようなさまざまなタスクがサポートされます。
コンテキストに応じたテキスト読み上げ合成: わずか 2 秒のオーディオ サンプルを使用して、Voicebox はオーディオ スタイルを照合し、テキスト読み上げの生成に使用できます。
音声編集とノイズリダクション: Voicebox は、音声全体を再録音することなく、ノイズによって中断された音声の一部を再作成したり、言い間違えた単語を置き換えたりすることができます。たとえば、犬の吠えによって中断された音声のセグメントを特定し、切り取って、オーディオ編集用の消しゴムのように、Voicebox にそのセグメントを再生成するように指示できます。
言語間変換: 誰かのスピーチのサンプルと、英語、フランス語、ドイツ語、スペイン語、ポーランド語、またはポルトガル語のテキストが与えられると、Voicebox は、サンプルが異なる場合でも、これらの言語のいずれかでテキストの読みを生成できます。音声とテキストは別の言語です。将来的には、言語が理解できなくても、人々はこの機能を使用して、より自然かつ本物の方法でコミュニケーションできるようになるでしょう。
フロー マッチングは、Voicebox で使用される方法で、拡散モデルのパフォーマンスを向上させることが証明されています。 Voicebox は、現在の最先端の英語モデルである VALL-E よりも、明瞭度 (単語誤り率 5.9% 対 1.9%) と音声の類似性 (0.580 対 0.681) で優れており、20 倍高速です。言語間のスタイル転送に関しては、Voicebox は YourTTS よりも優れており、平均単語誤り率が 10.9% から 5.2% に減少し、音声の類似性が 0.335 から 0.481 に向上しました。
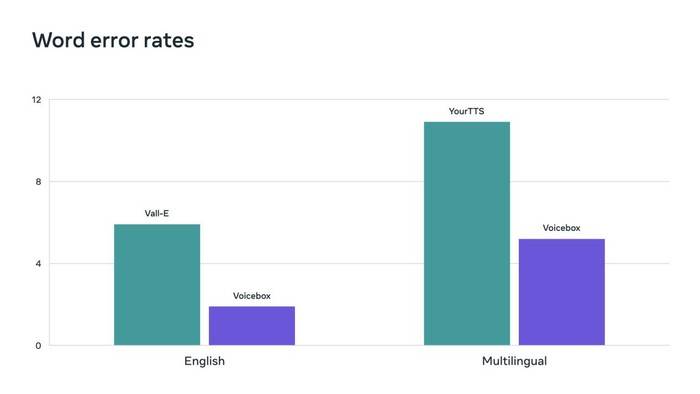
Voicebox は、単語エラー率において Vall-E や YourTTS を上回る、新しい最先端の結果を実現します。
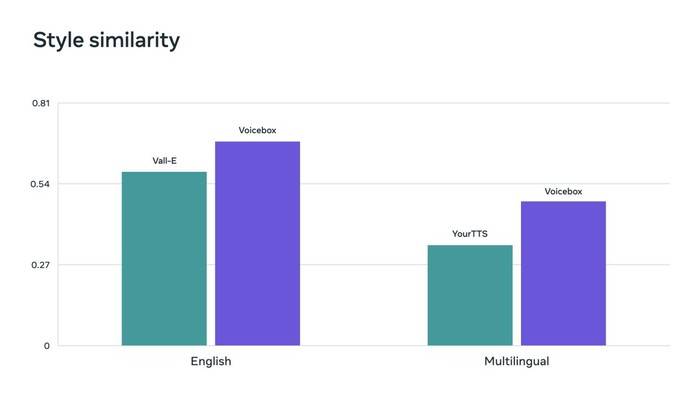
Voicebox は、英語と多言語のベンチマークにおけるオーディオ スタイルの類似性メトリックに関しても、それぞれ最先端の結果を達成しています。
Meta は現在、Voicebox が偽造の分野で使用される場合に存在する潜在的な害を認識しているため、実際の音声と Voicebox で生成された音声を区別する方法を模索していることは言及する価値があります。
解決策が見つかるまで、Meta は不必要な損害を避けるために Voicebox AI モデルを一般公開しません。
編集者のコメント: AIは現在さまざまな分野で応用されていますが、Voiceboxはタスクの汎化に成功した最初の多機能かつ効率的なモデルとして、音声生成AIの新時代を築くことができると信じています。 Meta が音声詐欺に効果的に対処できない場合、Voicebox テクノロジーが無効になる可能性があります。
以上がMeta、わずか 2 秒で実際の人間の音声をシミュレートするオーディオ AI モデルをリリースの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。