
ホームページ >テクノロジー周辺機器 >AI >データのラベル付け不要、「3D理解」マルチモーダル事前学習の時代へ! ULIPシリーズは完全にオープンソースであり、SOTAを更新します
データのラベル付け不要、「3D理解」マルチモーダル事前学習の時代へ! ULIPシリーズは完全にオープンソースであり、SOTAを更新します

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-20 17:33:061472ブラウズ
三次元形状、二次元画像、および対応する言語記述を調整することにより、マルチモーダル事前トレーニング方法は、3D 表現学習 の開発も促進します。
しかし、既存のマルチモーダル事前トレーニング フレームワークデータ収集方法にはスケーラビリティが欠けており、マルチモーダル学習の可能性が大幅に制限されています。最も大きなボトルネックは、言語モダリティの拡張性と包括性にあります。
最近、Salesforce AI はスタンフォード大学 大学およびテキサス大学オースティン校と提携して、新しいプロジェクトを主導する ULIP (CVP R2023) および ULIP-2 プロジェクトをリリースしました。 3Dで理解できる章です。

# 論文リンク: https://arxiv.org/pdf/2212.05171.pdf
#論文リンク: https://arxiv.org/pdf/2305.08275.pdfコードリンク: https: / /github.com/salesforce/ULIP
研究者らは、独自のアプローチを使用して、3D 点群、画像、テキストを使用してモデルを事前トレーニングし、統一された特徴に合わせて調整しました。空間。このアプローチにより、3D 分類タスクで最先端の結果が得られ、画像から 3D への検索などのクロスドメイン タスクの新たな可能性が開かれます。
そして ULIP-2 により、手動によるアノテーションなしでこのマルチモーダルな事前トレーニングが可能になり、大規模なスケーラビリティが可能になります。
ULIP-2 は、ModelNet40 のダウンストリーム ゼロショット分類で大幅なパフォーマンス向上を達成し、最高精度 74.0% に達しました。実際の ScanObjectNN ベンチマークでは、わずか 140 万を使用しました。たった 1 つのパラメーターで全体の精度 91.5% が達成され、人間による 3D アノテーションを必要としない、スケーラブルなマルチモーダル 3D 表現学習における画期的な成果となりました。
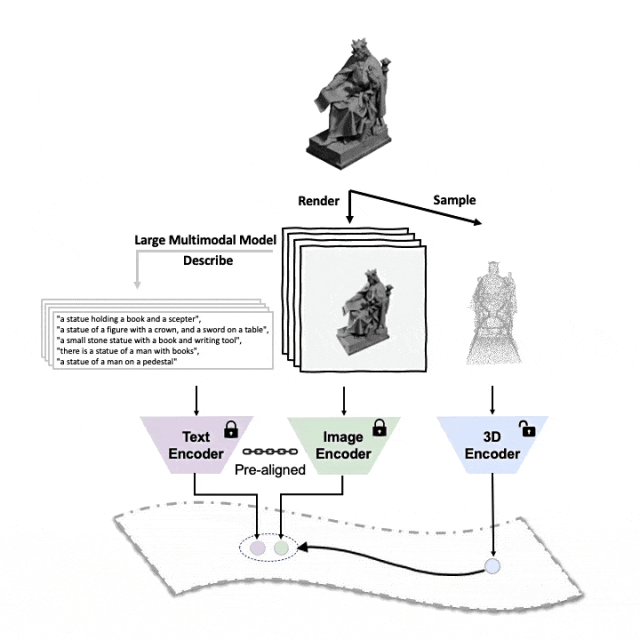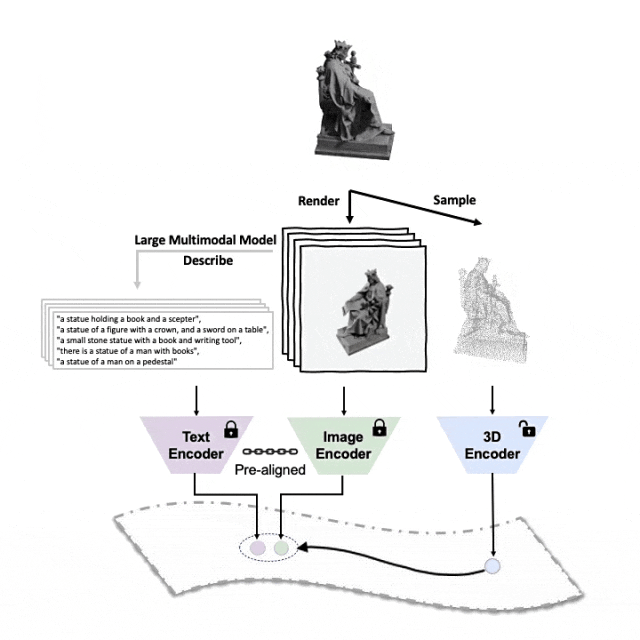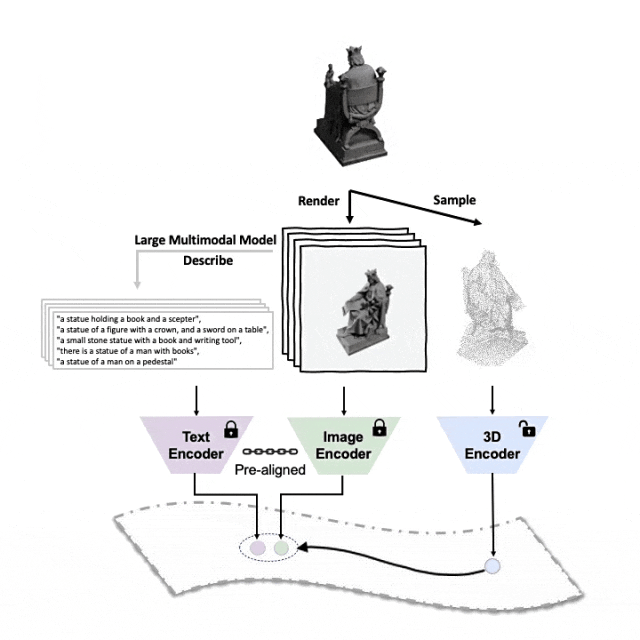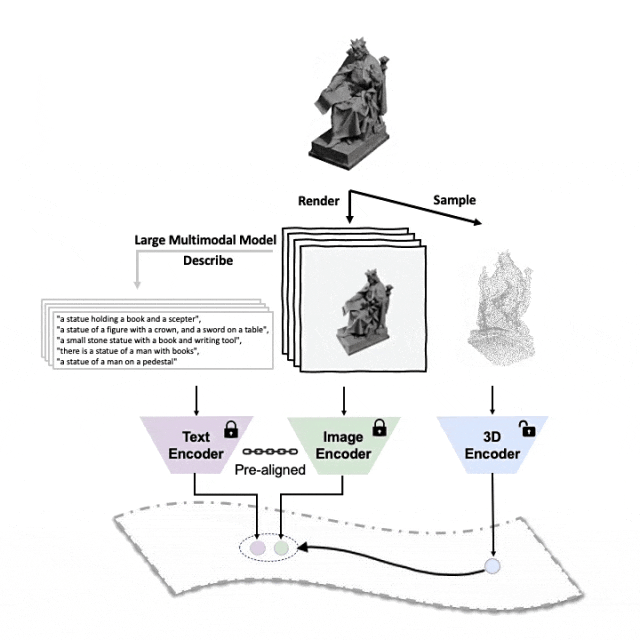
コードとリリースされた大規模な 3 峰性データ セット (「ULIP - Objaverse Triplets」および「ULIP - ShapeNet Triplets」) はオープン ソースです。 。
背景
3D 理解は人工知能の分野の重要な部分であり、これにより機械が人間と同じように 3 次元空間を認識し、対話できるようになります。この機能は、自動運転車、ロボット工学、仮想現実、拡張現実などの分野で重要な用途に使用されます。
しかし、3D データの処理と解釈の複雑さ、および 3D データの収集と注釈付けのコストにより、3D の理解は常に大きな課題に直面しています。
ULIP
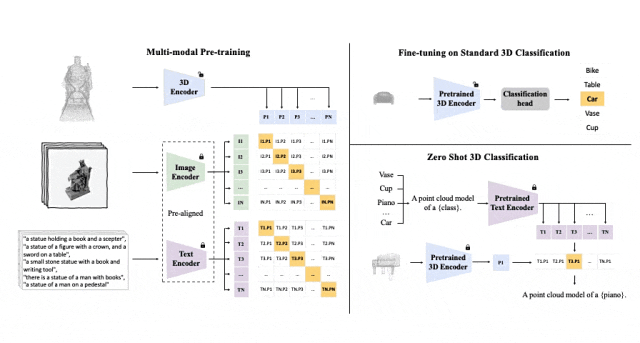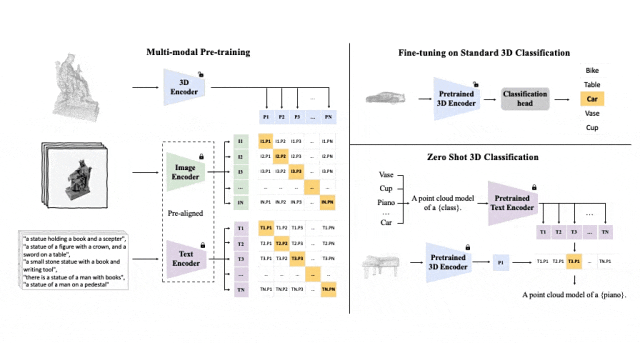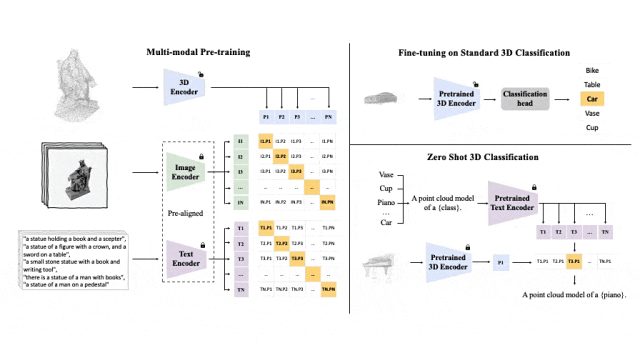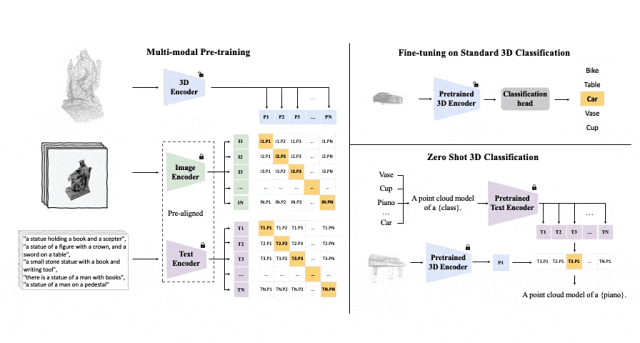
ULIP (すでに CVPR2023 で承認されています) は、3D 点群、画像、テキストを使用してモデルを事前トレーニングし、それらを統一された表現空間に配置する独自のアプローチを採用しています。
このアプローチは、3D 分類タスクで最先端の結果を達成し、画像から 3D への取得などのクロスドメイン タスクの新しい可能性を開きます。
ULIP の成功の鍵は、多数の画像とテキストのペアで事前トレーニングされた、CLIP などの事前調整された画像エンコーダーとテキスト エンコーダーの使用です。
これらのエンコーダーは、3 つのモダリティの機能を統一された表現空間に調整し、モデルが 3D オブジェクトをより効果的に理解して分類できるようにします。
この改善された 3D 表現学習により、3D データのモデルの理解が強化されるだけでなく、3D エンコーダーがマルチモーダル コンテキストを取得するため、ゼロショット 3D 分類や画像から 3D への取得などのクロスモーダル アプリケーションも可能になります。
ULIP の事前学習損失関数は次のとおりです。
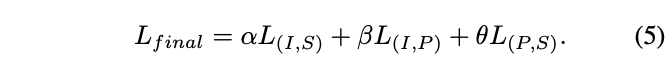
のデフォルト設定では、 ULIP、α は 0、β と θ は 1 に設定され、各 2 つのモード間の対比学習損失関数は次のように定義されます。ここで、M1 と M2 は 3 つのモードのうちの任意の 2 つのモードを指します。
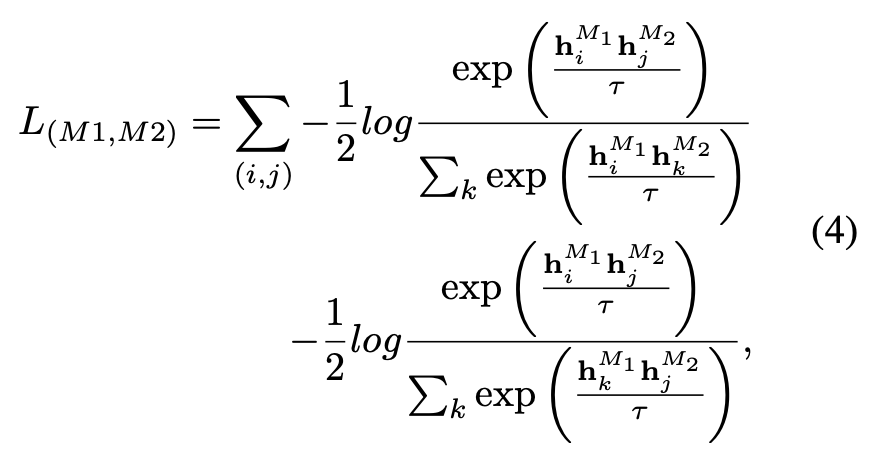
ULIP は画像から 3D への検索の実験も行いました。その結果は次のとおりです:

実験結果は、ULIP 事前トレーニング モデルが画像と 3D 点群の間で意味のあるマルチモーダル特徴を学習できたことを示しています。
驚くべきことに、他の取得された 3D モデルと比較して、最初に取得された 3D モデルの外観がクエリ画像に最も似ています。
たとえば、さまざまな種類の航空機 (戦闘機と旅客機) の画像を取得 (2 行目と 3 行目) に使用する場合、取得された最も近い 3D 点群は依然としてクエリ画像の微妙な違いです。保存されています。
#ULIP-2
##マルチアングルのテキスト説明を生成する 3D オブジェクトは次のとおりです。例。まず、一連のビューから 3D オブジェクトを 2D 画像にレンダリングし、次に大規模なマルチモーダル モデルを使用して、生成されたすべての画像の説明を生成します。
ULIP の ULIP-2基本的に、大規模なマルチモーダル モデルを使用して、3D オブジェクトに対応する包括的な言語記述を生成します。これにより、手動のアノテーションなしでスケーラブルなマルチモーダル事前トレーニング データを収集し、事前トレーニング プロセスとトレーニング済みモデルをより効率的にし、適応力を高めました。ULIP-2 のメソッドには、各 3D オブジェクトに対してマルチアングルおよび異なる言語の説明を生成し、これらの説明を使用してモデルをトレーニングすることが含まれています。これにより、3D オブジェクト、2D 画像、および言語が説明を組み合わせることができます。 特徴空間の位置合わせは一貫しています。
このフレームワークを使用すると、手動アノテーションなしで大規模な 3 モーダル データセットを作成できるため、マルチモーダル事前トレーニングの可能性を最大限に活用できます。
ULIP-2 は、生成された大規模な 3 つのモーダル データ セット「ULIP - Objaverse Triplets」および「ULIP - ShapeNet Triplets」もリリースしました。

実験結果
ULIP シリーズは、マルチモーダルな下流タスクや 3D 表現の微調整実験で驚くべき結果を達成しました。特に ULIP-2 の事前学習は、手動によるアノテーションなしで達成できます。
ULIP-2 は、ModelNet40 の下流ゼロショット分類タスクで大幅な向上 (トップ 1 精度 74.0%) を達成しました。実際の ScanObjectNN ベンチマークでは、全体的な精度を達成しました。わずか 140 万のパラメータで 91.5% が達成され、手動の 3D アノテーションを必要としないスケーラブルなマルチモーダル 3D 表現学習における画期的な成果となりました。
アブレーション実験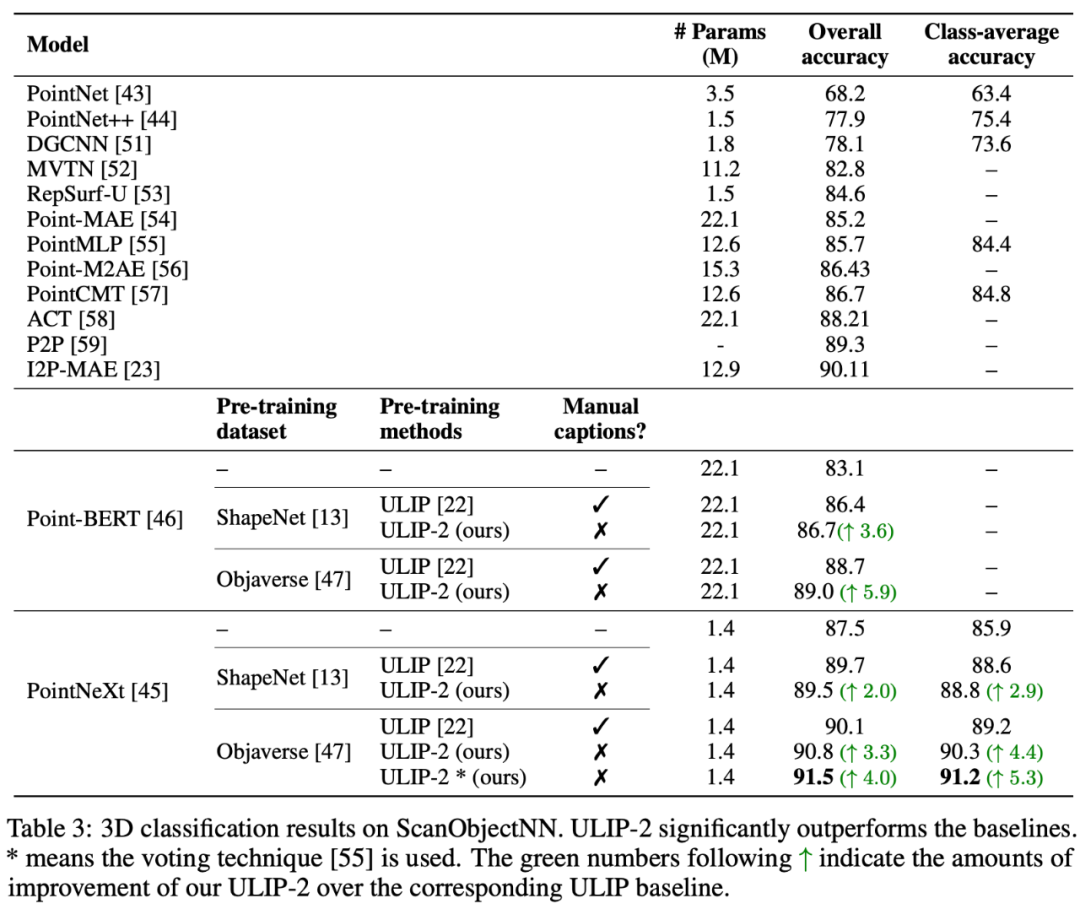
どちらの論文も詳細なアブレーション実験を実施しました。
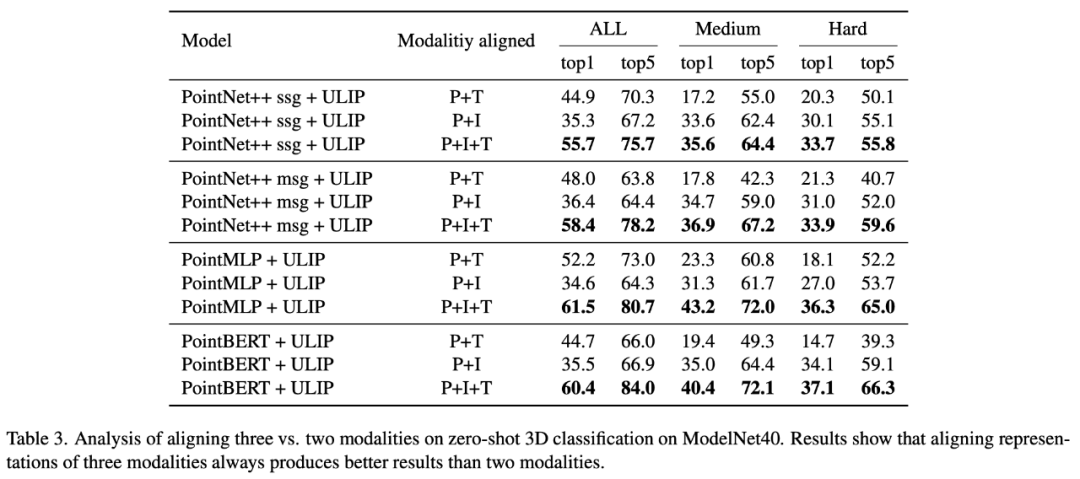
「ULIP: Learning a Unified Representation of Language, Images, and Point Clouds for 3D Understanding」では、ULIP の事前トレーニング フレームワークには 3 つのモダリティの参加が含まれるため、著者は実験を使用して2 つのモードを揃えるのが良いのか、それとも 3 つのモードをすべて揃えるのが良いのか? 実験結果は次のとおりです。実験結果から、異なる 3D バックボーンでは、2 つのモダリティのみを整列させるよりも 3 つのモダリティを整列させる方が優れており、これは ULIP の事前トレーニング フレームワークの合理性も証明しています。
 「ULIP-2: 3D 理解のためのスケーラブルなマルチモーダル事前トレーニングに向けて」では、著者は事前トレーニング フレームワークに対するさまざまな大規模マルチモーダル モデルの影響を調査しています。
「ULIP-2: 3D 理解のためのスケーラブルなマルチモーダル事前トレーニングに向けて」では、著者は事前トレーニング フレームワークに対するさまざまな大規模マルチモーダル モデルの影響を調査しています。
実験結果は、ULIP-2 フレームワークの事前トレーニングの効果が、大規模なメソッドを使用することでアップグレードできることがわかります。 -スケールマルチモーダルモデル、そしてプロモーションにはある程度の成長があります。
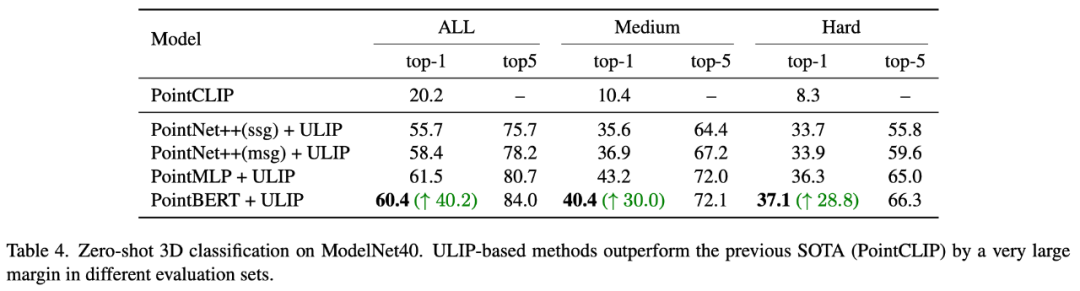 ULIP-2 では、著者は、異なる数のビューを使用して三峰性データセットを生成することが、全体的な事前トレーニングのパフォーマンスにどのような影響を与えるかを調査しました。実験結果は次のとおりです。 :
ULIP-2 では、著者は、異なる数のビューを使用して三峰性データセットを生成することが、全体的な事前トレーニングのパフォーマンスにどのような影響を与えるかを調査しました。実験結果は次のとおりです。 :
#実験結果は、使用される視点の数が増加するにつれて、事前トレーニングされたモデルのゼロショット分類の効果が低下することを示しています。も増えます。
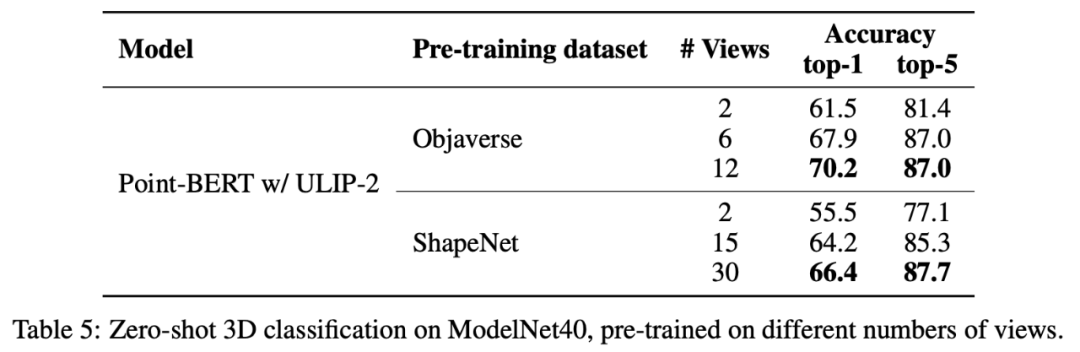 これは、より包括的で多様な言語記述がマルチモーダル事前トレーニングにプラスの効果をもたらすという ULIP-2 の点も裏付けています。
これは、より包括的で多様な言語記述がマルチモーダル事前トレーニングにプラスの効果をもたらすという ULIP-2 の点も裏付けています。
さらに、ULIP-2 では、CLIP によってソートされたさまざまな topk の言語記述がマルチモーダル事前トレーニングに及ぼす影響も調査しました。実験結果は次のとおりです。
##実験結果は、ULIP-2 フレームワークがさまざまな topk に対してある程度の堅牢性を持っていることを示しています。論文では上位 5 がデフォルト設定として使用されています。
結論
 Salesforce AI、スタンフォード大学、テキサス大学オースティン校が共同でリリースした ULIP プロジェクト (CVPR2023) と ULIP-2 は、医療分野を変えています。 3Dの理解。
Salesforce AI、スタンフォード大学、テキサス大学オースティン校が共同でリリースした ULIP プロジェクト (CVPR2023) と ULIP-2 は、医療分野を変えています。 3Dの理解。
ULIP は、さまざまなモダリティを統一空間に統合し、3D 機能の学習を強化し、クロスモーダル アプリケーションを可能にします。
ULIP-2 は、3D オブジェクトの総合的な言語記述を生成し、多数の 3 モーダル データ セットを作成してオープンソースにするためにさらに開発されており、このプロセスには手動の注釈は必要ありません。 。
これらのプロジェクトは、3D 理解における新たなベンチマークを設定し、機械が 3 次元の世界を真に理解する未来への道を切り開きます。
チームSalesforce AI:
Le Xue (Xue Le)、Mingfei Gao (Gao Mingfei)、Chen Xing (Xingchen)、Ning Yu (Yu Ning)、Shu Zhang (张捍)、Junnan Li (李俊 Nan)、Caiming Xiong (Xiong Caiming)、Ran Xu (Xu Ran)、Juan Carlos niebles、Silvio Savarese。
スタンフォード大学:
シルビオ・サバレーゼ教授、フアン・カルロス・ニーブルズ教授、ジャジュン・ウー教授(ウー・ジアジュン)。
UT オースティン:
ロベルト マルティン マルティン教授。
以上がデータのラベル付け不要、「3D理解」マルチモーダル事前学習の時代へ! ULIPシリーズは完全にオープンソースであり、SOTAを更新しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。