



本文に入る前に、MusicGen で生成された 2 つの音楽を聴いてみましょう。 「男が雨の中を歩き、美しい女の子に出会い、彼らは楽しそうに踊る」というテキストの説明を入力します。
そして、ジェイの歌詞の最初の 2 文を入力してみます。 Chou 氏の「Qili Xiang」「窓の外」 スズメが電柱の上でおしゃべりしています。あなたの言ったことで、夏のようです。」(中国語対応)
裁判用アドレス: https://huggingface.co/spaces /facebook/MusicGen
Text-to-music とは、「」などのテキスト説明が与えられた音楽作品を生成するタスクを指します。 90年代のギターリフロックソング。」音楽の生成には、長いシーケンスをモデリングするという困難な作業が含まれます。音声とは異なり、音楽は全スペクトルを使用する必要があります。これは、信号がより高いレートでサンプリングされることを意味します。つまり、音楽録音の標準サンプリング レートは 44.1 kHz または 48 kHz ですが、音声は 16 kHz でサンプリングされます。
さらに、音楽にはさまざまな楽器のハーモニーやメロディーが含まれており、音楽に複雑な構造を与えています。しかし、人間のリスナーは不協和音に非常に敏感であるため、生成された音楽のメロディーにはあまり寛容ではありません。もちろん、キー、楽器、メロディー、ジャンルなど、複数の方法で生成プロセスを制御する機能は音楽クリエイターにとって不可欠です。
自己教師付き音声表現学習、シーケンス モデリング、および音声合成における最近の進歩により、そのようなモデルを開発するための条件が提供されます。オーディオのモデリングを容易にするために、最近の研究では、オーディオ信号を「同じ信号を表す」個別のトークンのストリームとして表すことが提案されています。これにより、高品質のオーディオ生成と効率的なオーディオ モデリングが可能になります。ただし、これには複数の並列依存関係フローの共同モデリングが必要です。
Kharitonov et al. [2022]、Kreuk et al. [2022] は、音声トークンの複数のストリームを並行してモデル化するために遅延方法を使用すること、つまり、異なるストリーム間のオフセットを導入することを提案しました。ストリーム。 Agostinelli et al. [2023] は、異なる粒度の複数の離散トークン シーケンスを使用して音楽の断片を表現し、自己回帰モデルの階層を使用してそれらをモデル化することを提案しました。一方、Donahue et al. [2023] も同様のアプローチを採用しましたが、伴奏生成に合わせて歌うというタスクを対象としていました。最近、Wang et al. [2023] は、モデリングを最初のトークン ストリームに制限するという 2 段階でこの問題を解決することを提案しました。次に、ポストネットワークを適用して、非自己回帰的な方法で残りのフローを共同モデル化します。
この記事では、メタ AI 研究者が、テキストの説明が与えられた高品質の音楽を生成できる、シンプルで制御可能な音楽生成モデル MUSICGEN を提案します。

論文アドレス: https: / /arxiv.org/pdf/2306.05284.pdf
研究者らは、以前の研究の一般化として、複数の並列音響トークン ストリームをモデル化するための一般的なフレームワークを提案しました (以下の図 1 を参照)。 。生成されたサンプルの制御性を向上させるために、この論文では教師なしメロディー条件も導入し、モデルが与えられたハーモニーとメロディーに基づいて構造的に一致する音楽を生成できるようにします。この論文では MUSICGEN の広範な評価を実行し、提案された方法は評価ベースラインを大幅に上回っています。MUSICGEN の主観スコアは 100 点中 84.8 で、最高のベースラインでは 80.5 でした。さらに、この記事では、モデル全体のパフォーマンスに対する各コンポーネントの重要性を示すアブレーション研究を提供します。
最後に、人による評価では、MUSICGEN がテキストの説明に準拠し、メロディー的にも特定の倍音構造とよりよく一致する高品質のサンプルを生成することがわかりました。

この記事の主な貢献は次のとおりです:
- シンプルで効率的なモデルを提案: 32khzで高品質の音楽を生成できます。 MUSICGEN は、効果的なコードブック インターリーブ戦略を通じて、単一ステージの言語モデルで一貫した音楽を生成できます。
- は、テキストとメロディーの条件付き生成のための単一モデルを提案し、生成されたオーディオは、提供されるメロディーは、テキストの条件情報と一貫性があり、一致しています。
- 提案されたアプローチの主要な設計選択について、広範な客観的かつ手動による評価が実行されました。
メソッドの概要
MUSICGEN には、自己回帰トランスフォーマーに基づくデコーダが含まれており、テキストまたはメロディ表現に条件付けされます。 (言語) モデルは、EnCodec オーディオ トークナイザーの量子化単位に基づいており、低フレームの離散表現から忠実度の高い再構築を実現します。さらに、残差ベクトル量子化 (RVQ) を導入した圧縮モデルは、複数の並列ストリームを生成します。この設定では、各ストリームは、学習されたさまざまなコードブックからの個別のトークンで構成されます。
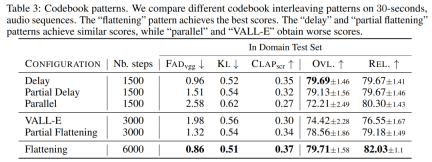
以前の研究では、この問題を解決するためにいくつかのモデリング戦略を提案しました。研究者らは、さまざまなコードブック インターリーブ モードに一般化できる新しいモデリング フレームワークを提案しました。このフレームワークにはいくつかのバリエーションもあります。パターンに基づいて、量子化されたオーディオ トークンの内部構造を利用できます。最後に、MUSICGEN はテキストまたはメロディーに基づく条件付き生成をサポートします。
音声トークン化
研究者らは、RVQ の定量化された潜在空間と敵対性を使用する畳み込み自動エンコーダーである EnCodec を使用しました。復興の損失。基準オーディオ確率変数 X ∈ R^d・f_s が与えられるとします。ここで、d はオーディオ継続時間を表し、f_s はサンプリング レートを表します。 EnCodec は、この変数をフレーム レート f_r ≪ f_s の連続テンソルにエンコードし、その表現は Q ∈ {1, . . . , N}^K×d・f_r として量子化されます。ここで、K は RVQ Quantity で使用されるコードブックを表します。 N はコードブックのサイズを表します。
コードブック インターリーブ モード
正確な平坦化された自己回帰分解。自己回帰モデルには、離散ランダム シーケンス U ∈ {1, ..., N}^S とシーケンス長 S が必要です。慣例により、研究者はシーケンスの始まりを表す決定的な特別なトークンである U_0 = 0 を使用します。その後、分布をモデル化できます。
不正確な自己回帰分解。もう 1 つの可能性は、一部のコードブックでは並列予測が必要な場合に、自己回帰分解を考慮することです。たとえば、別のシーケンス V_0 = 0、および t∈ {1, ..., N}、k ∈ {1, ..., K}、V_t,k = Q_t,k を定義します。コードブック インデックス k が削除されると (V_t など)、これは時間 t におけるすべてのコードブックの連結を表します。
任意のコードブック インターリーブ モード。このような分解を実験し、不正確な分解を使用した場合の影響を正確に測定するために、研究者らはコードブック インターリーブ モードを導入しました。まず、すべてのタイム ステップとコードブック インデックスのペアの集合である Ω = {(t, k) : {1, . . . , d・f_r}, k ∈ {1, . . . , K}} を考えます。コードブック パターンはシーケンス P=(P_0, P_1, P_2, ..., P_S) であり、P_0 = ∅、0
#モデルの条件付け
テキストの条件付け。入力音声と一致するテキストによる説明が与えられた場合
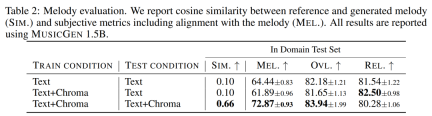
メロディコンディショニング。現在、条件付き生成モデルではテキストが主流のアプローチですが、音楽に対するより自然なアプローチは、別のオーディオ トラック、あるいは口笛やハミングのメロディー構造に基づいて条件を付けることです。このアプローチでは、モデル出力の反復的な最適化も可能になります。これをサポートするために、入力クロマトグラムとテキストの説明を共同で変調することでメロディー構造を制御することを試みました。初期の実験では、元のクロマトグラムでのコンディショニングにより元のサンプルが再構築されることが多く、オーバーフィッティングにつながることが観察されました。この目的を達成するために、研究者は各時間ステップで主要な時間-周波数ビンを選択し、情報のボトルネックを導入します。
モデル アーキテクチャ
コードブックの投影と位置の埋め込み。コードブック パターンが与えられると、各パターン ステップ P_s にはいくつかのコードブックのみが存在します。研究者は、P_s のインデックスに対応する値を Q から取得します。各コードブックは P_s に最大 1 回出現するか、まったく出現しません。
トランスデコーダ。入力は L 層と D 次元のトランスフォーマーに供給され、各層は因果的セルフアテンション ブロックで構成されます。次に、調整信号 C によって提供されるクロスアテンション ブロックが使用されます。メロディック コンディショニングを使用する場合、研究者はトランスフォーマーの入力に条件付きテンソル C を接頭辞として付けます。
#ロジッツの予測。パターン ステップ P_s では、トランス デコーダの出力が Q 値のロジット予測に変換されます。各コードブックは P_s 1 に最大 1 回出現します。コードブックが存在する場合、コードブック固有の線形層が D チャネルから N に適用され、ロジット予測が取得されます。
実験結果オーディオトークン化モデル。 この研究では、ストライド 640、フレーム レート 50 Hz、初期隠れサイズ 64 の 32 kHz モノラル オーディオの非因果的 5 層 EnCodec モデルを使用します。これは、5 つの層ごとに 2 倍になります。モデル。
トランスフォーマー モデル、 は、さまざまなサイズ (300M、1.5B、3.3B パラメーター) の自己回帰トランスフォーマー モデルを研究およびトレーニングしました。
#トレーニング データ セット。 20,000 時間のライセンスされた音楽を使用して MUSICGEN をトレーニングします。詳細には、この研究では、10,000 の高品質トラックを含む社内データセットと、それぞれ 25,000 および 365,000 のインストゥルメンタルのみのトラックを含む ShutterStock および Pond5 音楽データセットを使用しました。
評価データセット。 この研究では、提案された手法を MusicCaps ベンチマークで評価し、以前の研究と比較します。 MusicCaps は、専門のミュージシャンによって準備された 5.5K のサンプル (長さ 10 秒) と、ジャンル間でバランスがとれた 1K のサブセットで構成されています。
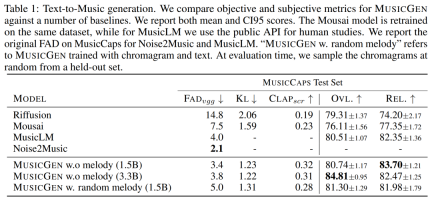
以下の表 1 は、提案された方法と Mousai、Riffusion、MusicLM、および Noise2Music との比較を示しています。結果は、MUSICGEN が、オーディオ品質と提供されたテキスト説明との一貫性の点で、人間のリスナーによって評価されたベースラインよりも優れていることを示しています。 Noise2Music は MusicCaps の FAD で最高のパフォーマンスを発揮し、テキスト条件でトレーニングされた MUSICGEN がそれに続きます。興味深いことに、メロディ条件を追加すると客観的な指標は低下しましたが、人間の評価には大きな影響はなく、評価されたベースラインよりも優れていました。
以上がメタオープンソーステキストから大規模な音楽モデルを生成 「Qilixiang」の歌詞で試してみたの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM
AIのスキルギャップは、サプライチェーンのダウンを遅くしていますApr 26, 2025 am 11:13 AM「AI-Ready労働力」という用語は頻繁に使用されますが、サプライチェーン業界ではどういう意味ですか? サプライチェーン管理協会(ASCM)のCEOであるAbe Eshkenaziによると、批評家ができる専門家を意味します
 1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM
1つの会社がAIを永遠に変えるために静かに取り組んでいる方法Apr 26, 2025 am 11:12 AM分散型AI革命は静かに勢いを増しています。 今週の金曜日、テキサス州オースティンでは、ビテンサーのエンドゲームサミットは極めて重要な瞬間を示し、理論から実用的な応用に分散したAI(DEAI)を移行します。 派手なコマーシャルとは異なり
 Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AM
Nvidiaは、AIエージェント開発を合理化するためにNEMOマイクロサービスをリリースしますApr 26, 2025 am 11:11 AMエンタープライズAIはデータ統合の課題に直面しています エンタープライズAIの適用は、ビジネスデータを継続的に学習することで正確性と実用性を維持できるシステムを構築する大きな課題に直面しています。 NEMOマイクロサービスは、NVIDIAが「データフライホイール」と呼んでいるものを作成することにより、この問題を解決し、AIシステムがエンタープライズ情報とユーザーインタラクションへの継続的な露出を通じて関連性を維持できるようにします。 この新しく発売されたツールキットには、5つの重要なマイクロサービスが含まれています。 NEMOカスタマイザーは、より高いトレーニングスループットを備えた大規模な言語モデルの微調整を処理します。 NEMO評価者は、カスタムベンチマークのAIモデルの簡素化された評価を提供します。 Nemo Guardrailsは、コンプライアンスと適切性を維持するためにセキュリティ管理を実装しています
 aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AM
aiは芸術とデザインの未来のために新しい絵を描きますApr 26, 2025 am 11:10 AMAI:芸術とデザインの未来 人工知能(AI)は、前例のない方法で芸術とデザインの分野を変えており、その影響はもはやアマチュアに限定されませんが、より深く影響を与えています。 AIによって生成されたアートワークとデザインスキームは、広告、ソーシャルメディアの画像生成、Webデザインなど、多くのトランザクションデザインアクティビティで従来の素材画像とデザイナーに迅速に置き換えられています。 ただし、プロのアーティストやデザイナーもAIの実用的な価値を見つけています。 AIを補助ツールとして使用して、新しい美的可能性を探求し、さまざまなスタイルをブレンドし、新しい視覚効果を作成します。 AIは、アーティストやデザイナーが繰り返しタスクを自動化し、さまざまなデザイン要素を提案し、創造的な入力を提供するのを支援します。 AIはスタイル転送をサポートします。これは、画像のスタイルを適用することです
 エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM
エージェントAIとのズームがどのように革命を起こしているか:会議からマイルストーンまでApr 26, 2025 am 11:09 AM最初はビデオ会議プラットフォームで知られていたZoomは、エージェントAIの革新的な使用で職場革命をリードしています。 ZoomのCTOであるXD Huangとの最近の会話は、同社の野心的なビジョンを明らかにしました。 エージェントAIの定義 huang d
 大学に対する実存的な脅威Apr 26, 2025 am 11:08 AM
大学に対する実存的な脅威Apr 26, 2025 am 11:08 AMAIは教育に革命をもたらしますか? この質問は、教育者と利害関係者の間で深刻な反省を促しています。 AIの教育への統合は、機会と課題の両方をもたらします。 Tech Edvocate NotesのMatthew Lynch、Universitとして
 プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM
プロトタイプ:アメリカの科学者は海外の仕事を探していますApr 26, 2025 am 11:07 AM米国における科学的研究と技術の開発は、おそらく予算削減のために課題に直面する可能性があります。 Natureによると、海外の雇用を申請するアメリカの科学者の数は、2024年の同じ期間と比較して、2025年1月から3月まで32%増加しました。以前の世論調査では、調査した研究者の75%がヨーロッパとカナダでの仕事の検索を検討していることが示されました。 NIHとNSFの助成金は過去数か月で終了し、NIHの新しい助成金は今年約23億ドル減少し、3分の1近く減少しました。リークされた予算の提案は、トランプ政権が科学機関の予算を急激に削減していることを検討しており、最大50%の削減の可能性があることを示しています。 基礎研究の分野での混乱は、米国の主要な利点の1つである海外の才能を引き付けることにも影響を与えています。 35
 オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AM
オープンAIの最新のGPT 4.1ファミリ - 分析VidhyaApr 26, 2025 am 10:19 AMOpenaiは、強力なGPT-4.1シリーズを発表しました。実際のアプリケーション向けに設計された3つの高度な言語モデルのファミリー。 この大幅な飛躍は、より速い応答時間、理解の強化、およびTと比較した大幅に削減されたコストを提供します


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 Linux 新バージョン
SublimeText3 Linux 最新バージョン

SAP NetWeaver Server Adapter for Eclipse
Eclipse を SAP NetWeaver アプリケーション サーバーと統合します。

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

SublimeText3 中国語版
中国語版、とても使いやすい
ホットトピック
 7747
7747 15164314139752129125123429
15164314139752129125123429