
ホームページ >テクノロジー周辺機器 >AI >DeepMind は AI でソート アルゴリズムを書き換え、33B の大規模モデルを単一のコンシューマ GPU に詰め込みます
DeepMind は AI でソート アルゴリズムを書き換え、33B の大規模モデルを単一のコンシューマ GPU に詰め込みます

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-12 18:49:571538ブラウズ
#ディレクトリ:
- #Video-LLaMA: ビデオ理解のための命令調整されたオーディオビジュアル言語モデル
- ##単一サンプルからのパッチベースの 3D 自然シーン生成
- 時空間拡散点プロセス
- SpQR: ほぼロスレスの LLM 重み圧縮のためのスパース量子化表現
- UniControl: 野外で制御可能なビジュアル生成のための統合拡散モデル
- FrugalGPT: コストを削減し、パフォーマンスを向上させながら大規模な言語モデルを使用する方法
- 論文 1: 深層強化学習を使用して発見された高速ソート アルゴリズム
##著者: Daniel J. Mankowitz 他
- #論文アドレス: https://www.nature.com/articles/s41586-023-06004-9
- 要約: 「AlphaDev は、スワッピングとコピー移動により、手順を 1 つスキップし、一見間違っているように見えますが、実際には近道となる方法でプロジェクトを接続します。」この前例のない直感に反する考えは、人々に次のようなことを思い出させます。 2016年の春。
7 年前、AlphaGo は囲碁で人間の世界チャンピオンを破りました。そして今、AI は私たちにプログラミングの新たな教訓を与えてくれました。 Google DeepMind CEO Hassabis の 2 つの文は、コンピュータ分野の始まりです。「AlphaDev は、新しくて高速な並べ替えアルゴリズムを発見し、開発者が使用できるようにそれをメインの C ライブラリにオープンソース化しました。これは、コード効率を向上させる単なる AI です。
推奨:
AI が並べ替えアルゴリズムを書き換え、70% 高速化 :DeepMind AlphaDevコンピューティングの基礎を革新し、毎日何兆回も呼び出されるライブラリが更新されます
論文 2: Video-LLaMA: ビデオ用の命令調整されたオーディオビジュアル言語モデル理解
著者: Hang Zhang 他
- 論文アドレス: https :/ /arxiv.org/abs/2306.02858
- 要約: 最近、大規模な言語モデルが優れた機能を実証しました。大型モデルに「目」と「耳」を持たせて、動画を理解してユーザーと対話できるようにすることはできないだろうか。
この問題から出発して、DAMO アカデミーの研究者は、包括的なオーディオビジュアル機能を備えた大規模モデルである Video-LLaMA を提案しました。 Video-LLaMA は、ビデオ内のビデオおよびオーディオ信号を認識して理解することができ、オーディオ/ビデオの説明、書き込み、質疑応答など、オーディオとビデオに基づく一連の複雑なタスクを完了するためのユーザー入力指示を理解できます。現在、論文、コード、インタラクティブなデモはすべて公開されています。さらに、研究チームは、Video-LLaMA プロジェクトのホームページで、中国のユーザーのエクスペリエンスをよりスムーズにするために、モデルの中国語版も提供しています。 次の 2 つの例は、Video-LLaMA の包括的な視聴覚認識機能を示しています。例内の会話はオーディオ ビデオを中心に展開されます。
推奨事項:
DAMO アカデミーのオープンソース Video-LLaMA に、包括的なオーディオビジュアル機能を大規模な言語モデルに追加します。
- 著者: Weiyu Li 他
- 論文アドレス: https://arxiv.org/abs/2304.12670
##要約: 北京大学のChen Baoquanチームは、山東大学およびTencent AI Labの研究者とともに、最初の単一サンプルシナリオを提案しました。 without トレーニングによってさまざまな高品質な 3D シーンを生成できる手法。

推奨: CVPR 2023 | 3D シーン生成: ニューラル ネットワークのトレーニングを行わずに、単一のサンプルから多様な結果を生成します。
#論文 4: 時空間拡散点プロセス
- ##著者: Yuan Yuan 他.
- #論文アドレス: https://arxiv.org/abs/2305.12403
- #要約:
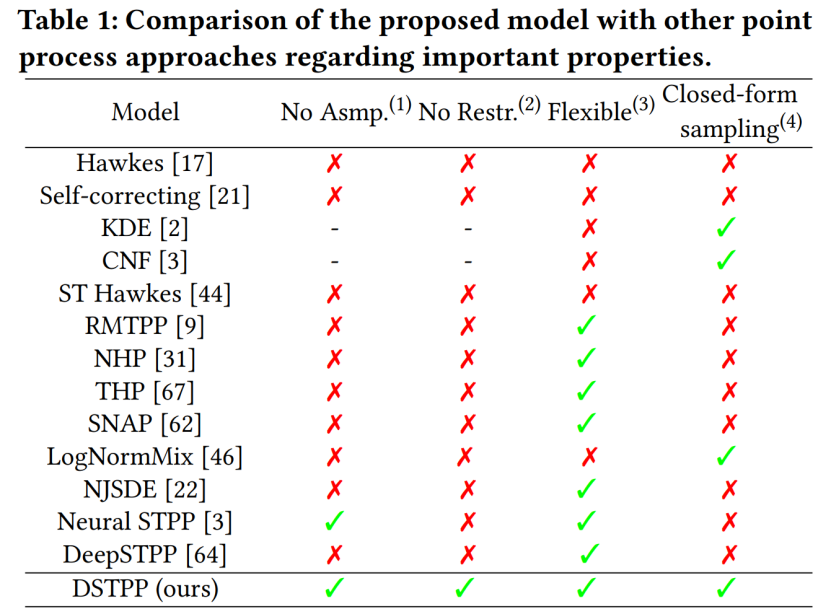 推奨事項:
推奨事項:
論文 5: SpQR: ほぼ損失のない LLM 重み圧縮のためのスパース量子化表現
著者: Tim Dettmers 他
- 論文アドレス: https://arxiv.org/pdf/2306.03078.pdf
- 要約:
SpQR は、特に大きな量子化エラーを引き起こす異常な重みを特定して分離し、他のすべての重みを圧縮しながら、それらをより高精度で保存することによって機能します。 LLaMA および Falcon LLM では精度の低下が発生します。単一の 24GB コンシューマ GPU で 33B パラメータの LLM を実行すると、パフォーマンスが低下することなく、15% 高速になります。以下の図 3 は、SpQR の全体的なアーキテクチャを示しています。
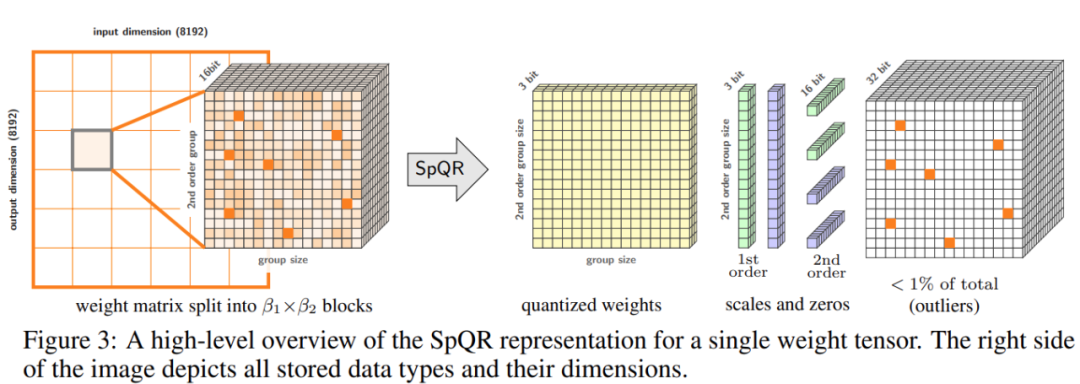
論文 6: UniControl: 野外での制御可能なビジュアル生成のための統合拡散モデル
##要約: この記事では、Salesforce AI、ノースイースタン大学、スタンフォード大学の研究者が MOE スタイルのアダプターとタスク認識を提案しました。 HyperNet UniControl でマルチモーダル条件生成機能を実現します。 UniControl は 9 つの異なる C2I タスクでトレーニングされ、強力なビジュアル生成機能とゼロショット汎化機能を実証します。 UniControl モデルは、複数の事前トレーニング タスクとゼロショット タスクで構成されます。 推奨: マルチモーダルで制御可能な画像生成のための統合モデルがここにあります。モデル パラメーターと推論コードは次のとおりです。すべてオープンソース。 論文 7: FrugalGPT: コストを削減し、パフォーマンスを向上させながら大規模な言語モデルを使用する方法 要約: コストと精度のバランスは、特に新しいテクノロジーを採用する場合、意思決定における重要な要素です。 LLM を効果的かつ効率的に利用する方法は、実務者にとって重要な課題です。タスクが比較的単純であれば、GPT-J (GPT-3 の 30 分の 1 である) からの複数の応答を集約することで、GPT-3 と同様のパフォーマンスを達成できます。コストと環境のトレードオフを実現します。ただし、より困難なタスクでは、GPT-J のパフォーマンスが大幅に低下する可能性があります。したがって、LLM をコスト効率よく使用するには、新しいアプローチが必要です。 最近の研究では、このコスト問題の解決策を提案しようとしました。研究者らは、FrugalGPT が最高の個別 LLM (GPT-4 など) のパフォーマンスと競合できることを実験的に示しました。コストが最大 98% 削減されるか、同じコストで最適な個別 LLM の精度が 4% 向上します。この研究では、即時適応、LLM 近似、LLM カスケードという 3 つのコスト削減戦略について説明します。

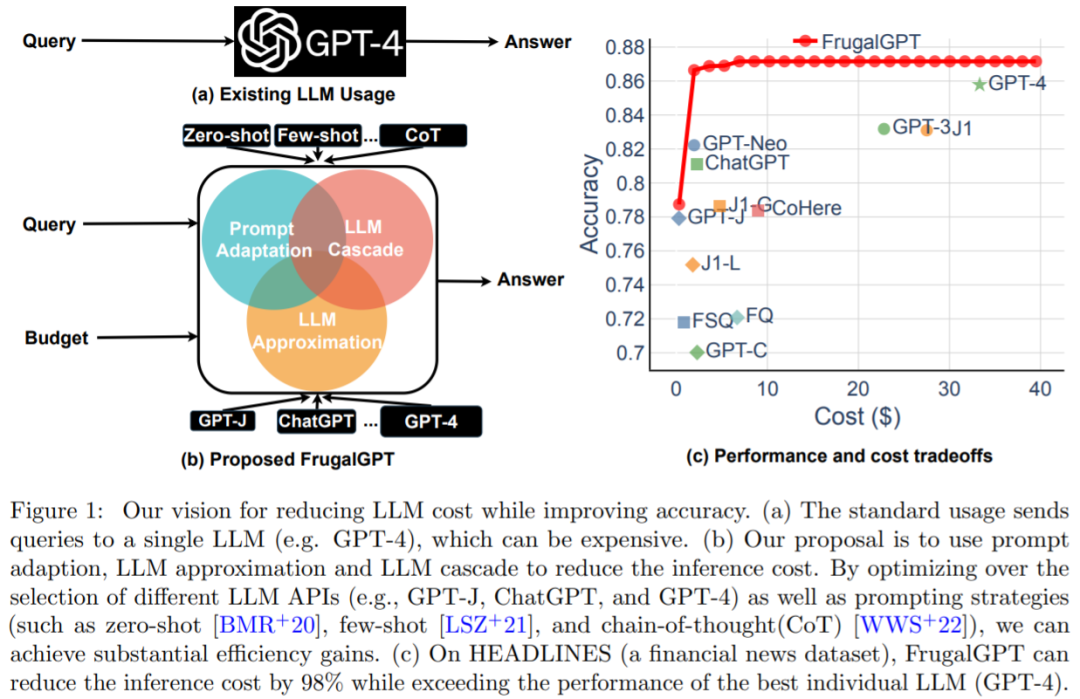
推奨: GPT-4 API の代替?パフォーマンスは同等で、コストは 98% 削減されます。スタンフォード大学は FrugalGPT を提案しましたが、この研究は物議を醸しました。
以上がDeepMind は AI でソート アルゴリズムを書き換え、33B の大規模モデルを単一のコンシューマ GPU に詰め込みますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。