


昨日、データベースのエラー情報をより正確に診断できるCHATGLM-6Bの対話モデルを微調整する220時間の微調整訓練が終了しました。

# しかし、10 日近く待ったこのトレーニングの最終結果は残念なものでした。サンプル カバレッジを小さくして行った前回のトレーニングと比較すると、その差は依然としてかなり大きいです。
最近の微調整トレーニングの失敗例から判断すると、微調整トレーニングを完了するのは簡単ではありません。異なるタスク目標がトレーニング用に混合されます。異なるタスク目標には異なるトレーニング パラメータが必要になる場合があり、最終的なトレーニング セットが特定のタスクのニーズを満たすことができなくなります。したがって、PTUNING は非常に特定のタスクにのみ適しており、混合タスクには必ずしも適しているわけではありません。混合タスクを目的としたモデルでは FINETUNE を使用する必要がある場合があります。これは、数日前に友人とコミュニケーションをとっているときにみんなが言ったことと似ています。
実際、モデルのトレーニングが難しいため、自分でモデルをトレーニングすることを諦め、代わりにローカルのナレッジ ベースをベクトル化してより正確に取得してから使用する人もいます。 AUTOPROMPT を使用してそれを取得します。 最終結果では、音声モデルに質問するための自動プロンプトが生成されます。この目標は、langchain を使用すると簡単に達成できます。
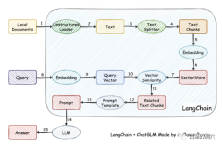
この作業にはもう 1 つの重要なポイントがあります。1 つは、ローカル知識ベース内の知識をより正確に検索することです。これは、検索におけるベクトル ストレージによって実現されます。現在、ターゲットとされています。中国語と英語のローカル ナレッジ ベースでは、ナレッジ ベースのベクトル化と検索のためのソリューションが多数あり、ナレッジ ベースにより適したソリューションを選択できます。

私たちは最近踏んだ落とし穴から経験を積むことができます。まず、ptuning の難易度は思ったよりも高く、finetune よりも必要な装備は少ないものの、訓練難易度は決して低くありません。次に、LLM 機能を向上させるために、Langchain と自動プロンプトを介してローカルのナレッジ ベースを使用することをお勧めします。ほとんどのエンタープライズ アプリケーションでは、ローカルのナレッジ ベースが整理され、適切なベクトル化ソリューションが選択されている限り、次のような結果が得られるはずです。 PTUNING/FINETUNE よりも劣りません。 3 番目に、これも前回述べたように、LLM の能力が非常に重要です。使用する基本モデルとして強力な LLM を選択する必要があります。組み込みモデルは機能を部分的に向上させることしかできず、決定的な役割を果たすことはできません。 4 番目に、データベース関連の知識に関しては、vicuna-13b は非常に優れた能力を持っています。 今朝早くクライアントに連絡しに行かなければなりません。朝は時間が限られているので、少しだけ文章を書きます。これについて何かご意見がございましたら、ディスカッション用にメッセージを残してください (ディスカッションはあなたと私にのみ表示されます)。私もこの道を一人で歩いています。アドバイスをくれる仲間がいることを願っています。
以上がローカルナレッジベースを使用してLLMのパフォーマンスを最適化する方法に関する記事の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SublimeText3 中国語版
中国語版、とても使いやすい

MantisBT
Mantis は、製品の欠陥追跡を支援するために設計された、導入が簡単な Web ベースの欠陥追跡ツールです。 PHP、MySQL、Web サーバーが必要です。デモおよびホスティング サービスをチェックしてください。

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。

mPDF
mPDF は、UTF-8 でエンコードされた HTML から PDF ファイルを生成できる PHP ライブラリです。オリジナルの作者である Ian Back は、Web サイトから「オンザフライ」で PDF ファイルを出力し、さまざまな言語を処理するために mPDF を作成しました。 HTML2FPDF などのオリジナルのスクリプトよりも遅く、Unicode フォントを使用すると生成されるファイルが大きくなりますが、CSS スタイルなどをサポートし、多くの機能強化が施されています。 RTL (アラビア語とヘブライ語) や CJK (中国語、日本語、韓国語) を含むほぼすべての言語をサポートします。ネストされたブロックレベル要素 (P、DIV など) をサポートします。

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター
ホットトピック
 7934
7934 15165214141252130325125029
15165214141252130325125029