
ホームページ >テクノロジー周辺機器 >AI >LLaMAを倒す?史上最も強力な「ファルコン」のランキングには疑問があり、フー・ヤオは個人的に7行のコードをテストし、ルカンはそれを次のような人に転送した
LLaMAを倒す?史上最も強力な「ファルコン」のランキングには疑問があり、フー・ヤオは個人的に7行のコードをテストし、ルカンはそれを次のような人に転送した

- 王林転載
- 2023-06-10 19:46:581441ブラウズ
少し前、駆け出しの Falcon が LLM ランキングで LLaMA を破り、コミュニティ全体に波紋を巻き起こしました。
しかし、Falcon は本当に LLaMA よりも優れているのでしょうか?
# 短い答え: おそらくそうではありません。
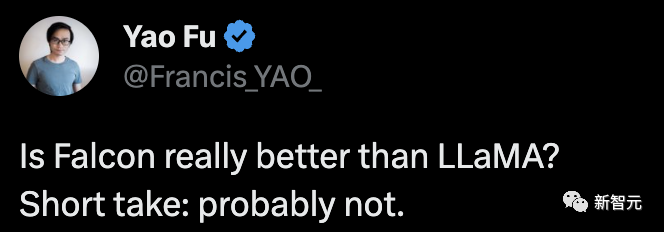
Fu Yao のチームは、モデルのより詳細な評価を実施しました:
「LLaMA 65B の評価を MMLU 上で再現すると、公式スコア (63.4) に近い 61.4 というスコアが得られ、Open LLM Leaderboard のスコア (48.8) よりもはるかに高く、Falcon よりも大幅に高かった ( 52.7)."
派手なプロンプト エンジニアリングや凝ったデコードは必要なく、すべてがデフォルト設定です。
現在、コードとテスト方法はGithubで公開されています。
ファルコンズが LLaMA を超えることについては疑問があり、ルカン氏は自身の立場とテスト スクリプトの問題を表明しました...
現在、OpenLLM ランキングでは、Falcon が LLaMA を上回って 1 位にランクされており、Thomas Wolf を含む研究者によって強く推奨されています。

まず、ネチズンは、これらの LLaMA の数値がどこから来たのかを質問しました。それらは論文の数値と矛盾しているようでした...
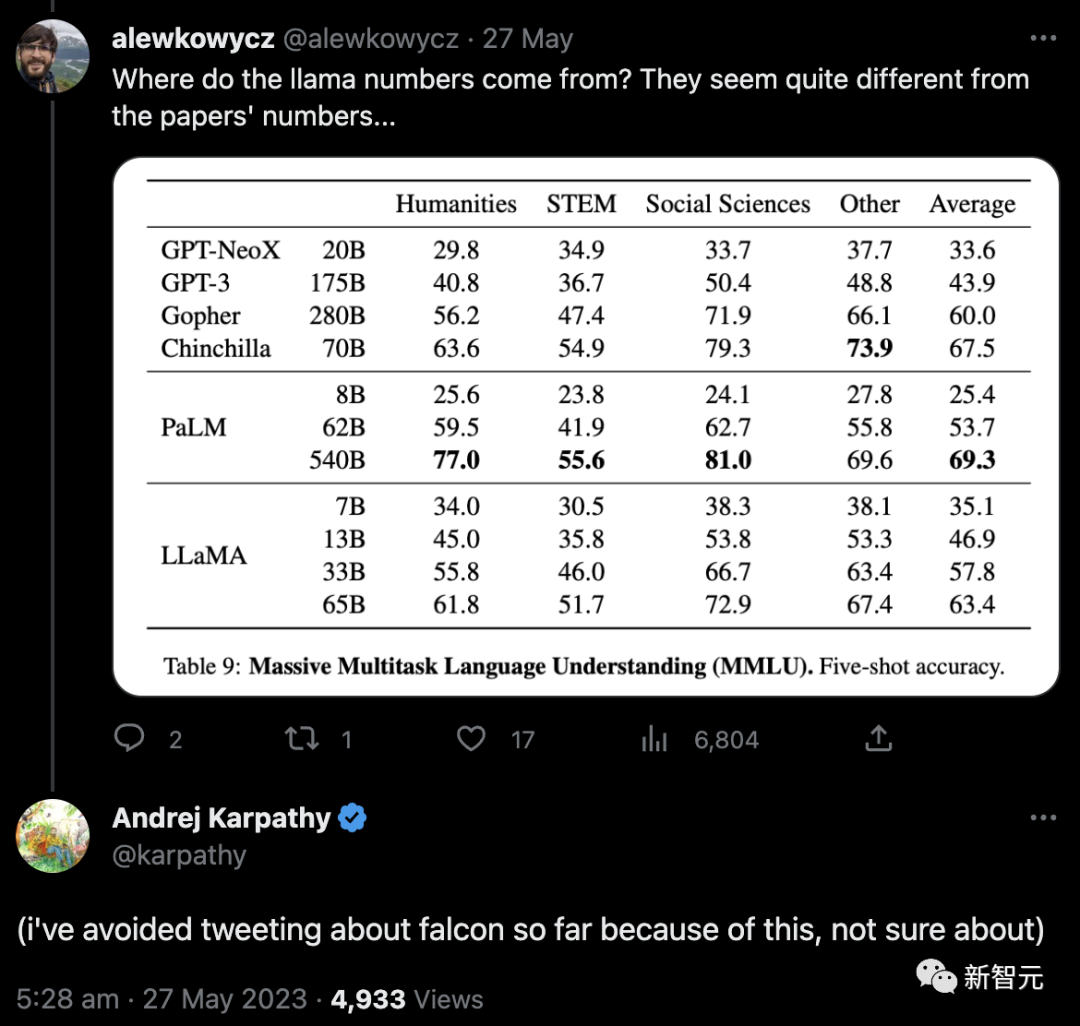
そして投稿しますが、これまでのところ、私はファルコンズについてツイートすることを避けてきました。これはわかりません。
この問題を明確にするために、Fu Yao とチームメンバーは LLaMA 65B の公開テストを実施することにしました。結果は 61.4 ポイントでした。
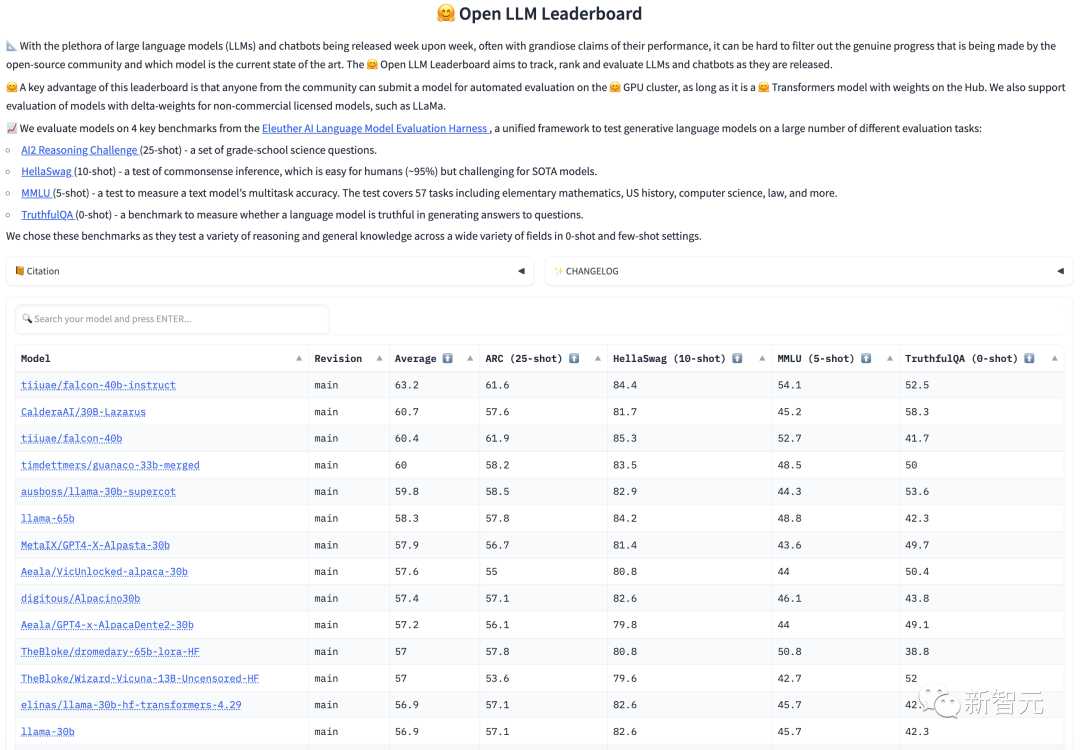
この結果は、モデルで GPT-3.5 に近いレベルを達成したい場合は、LLaMA 65B で RLHF を使用するのが最適であることを証明しています。
根拠は、フー・ヤオ氏のチームが最近発表した思考連鎖ハブの論文の調査結果です。

さらに、Falcon にはより便利なライセンスがあり、これにより大きな開発の可能性も得られます。
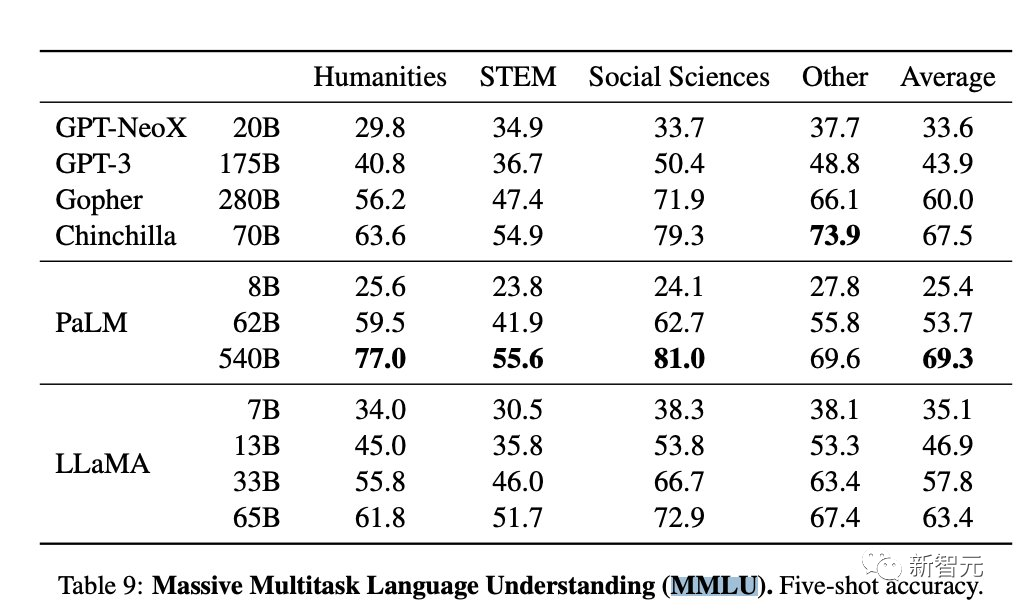
この最新のレビューについて、ネチズン BlancheMinerva は、公正な比較はデフォルト設定の MMLU 上で Falcon を実行することであるべきだと指摘しました。 これに関して、傅耀は、これは正しく、作業は進行中であり、結果は1日以内に得られる予定であると述べた。 最終結果がどのようなものであれ、GPT-4 の山がオープンソース コミュニティが本当に望んでいる目標であることを知っておく必要があります。追求する。 Meta の研究者は、LLaMa の結果をうまく再現した Fu Yao を賞賛し、OpenLLM ランキング リストの問題点を指摘しました。 同時に、彼は OpenLLM ランキングに関するいくつかの質問も共有しました。 まず、MMLU の結果です。LLaMa 65B MMLU の結果は、リーダーボードで 15 ポイントですが、7B モデルでも同じです。 13B モデルと 30B モデルの間には、パフォーマンスの小さな差もあります。 OpenLLM は、どのモデルが最適であるかを発表する前に、これを検討する必要があります。 #ベンチマーク: これらのベンチマークはどのように選択されますか? ARC 25 ショットと Hellaswag 10 ショットは、LLM には特に関連していないようです。いくつかの生成ベンチマークを含めることができればより良いでしょう。生成ベンチマークには制限がありますが、それでも役立つ可能性があります。 単一の平均スコア: 結果を単一のスコアに落とし込みたくなるのが常ですが、平均スコアが最も簡単です。 しかしこの場合、4 つのベンチマークの平均は本当に役に立つのでしょうか? MMLU で 1 ポイントを獲得することは、HellaSwag で 1 ポイントを獲得することと同じですか? LLM が迅速に反復される世界では、このようなランキング リストを作成することには間違いなく一定の価値があります。 Google の研究者であるルーカス ベイヤー氏も次のように意見を述べています。 クレイジー イエス、 NLP 研究者は同じベンチマークに対して異なる理解を持っているため、まったく異なる結果が得られます。同時に、同僚の誰かがメトリクスを実装するたびに、私はすぐに彼らに公式コードの完全な再現を実際にチェックしているかどうか尋ね、そうでない場合は結果を破棄します。 また、私の知る限り、モデルに関係なく、実際には元のベンチマークの結果を再現しないとも彼は言いました。
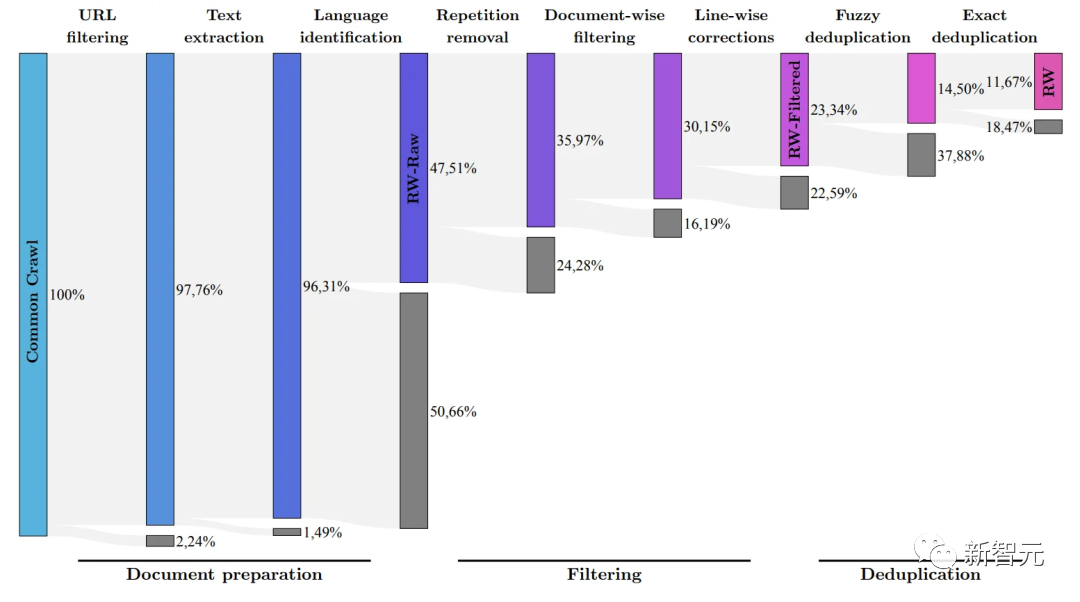
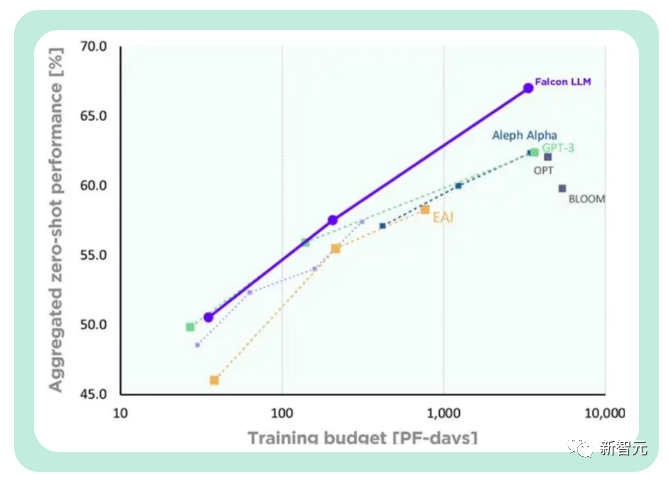
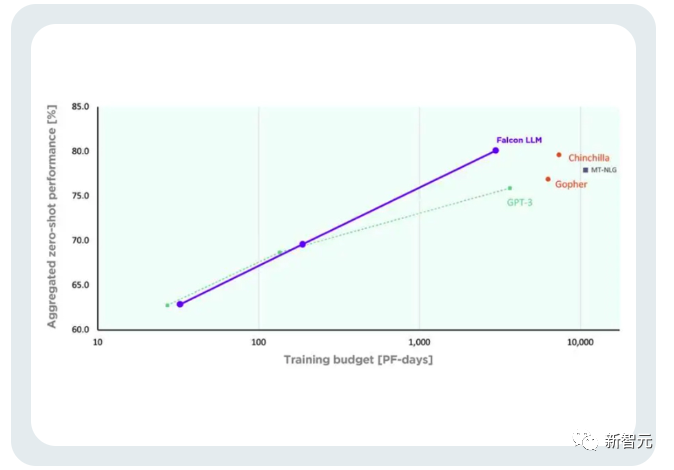
LeCun 氏によると、大規模モデルの時代においては、オープンソースが最も重要です。 Meta の LLaMA コードが漏洩した後、あらゆる分野の開発者がそれを試してみたいと熱望し始めました。 ファルコンは、アラブ首長国連邦、アブダビのテクノロジーイノベーション研究所(TII)によって開発された奇襲兵器です。 最初にリリースされたときのパフォーマンスの点では、Falcon は LLaMA よりも優れたパフォーマンスを示しました。 現在、「Falcon」には 1B、7B、40B の 3 つのバージョンがあります。 TII は、Falcon はこれまでで最も強力なオープンソース言語モデルであると述べました。その最大のバージョンである Falcon 40B には 400 億のパラメータがありますが、それでも 650 億のパラメータを持つ LLaMA よりも規模が若干小さいです。 ただし、TII は以前、Falcon は小規模であるにもかかわらず、優れたパフォーマンスを発揮すると述べています。 先進技術研究評議会 (ATRC) の事務局長であるファイサル・アル・バンナイ氏は、「ファルコン」のリリースにより LLM 取得の道が開かれ、研究者や起業家が提案できるようになると考えています。最良のソリューション、最も革新的な使用例。 FalconLM の 2 つのバージョン、Falcon 40B Instruct と Falcon 40B は、Hugging Face OpenLLM ランキングで上位 2 位にランクされていますが、Meta の LLaMA は3位に。 上記のランキングの問題点はまさにこれです。 「Falcon」論文はまだ公開されていませんが、Falcon 40B は慎重に選別された 1 兆のトークン ネットワーク データセットで広範囲にトレーニングされています。 研究者らは、「Falcon」がトレーニングプロセス中に大規模なデータで高いパフォーマンスを達成することの重要性を非常に重視していることを明らかにしました。 誰もが知っていることは、LLM はトレーニング データの品質に非常に敏感であるということです。そのため、研究者は、数万のデータに対して効率的な処理を実行できるデータの構築に多大な労力を費やしています。 CPU コアのデータ パイプライン。 目的は、フィルタリングと重複排除に基づいてインターネットから高品質のコンテンツを抽出することです。 現在、TII は、慎重にフィルタリングされ重複排除されたデータ セットである、洗練されたネットワーク データ セットをリリースしました。実践すると、それが非常に効果的であることが証明されました。 このデータセットのみを使用してトレーニングされたモデルは、パフォーマンスにおいて他の LLM と同等か、それを上回る可能性があります。これは「ファルコン」の優れた品質と影響力を示しています。 さらに、Falcon モデルには多言語機能もあります。 英語、ドイツ語、スペイン語、フランス語、そしてオランダ語、イタリア語、ルーマニア語、ポルトガル語、チェコ語、ポーランド語、スウェーデン語などのいくつかのヨーロッパの小さな言語も理解できます。それ。 Falcon 40B は、H2O.ai モデルのリリースに続く 2 番目の真のオープンソース モデルです。 さらに、非常に重要な点がもう 1 つあります。Falcon は、現在無料で商用利用できる唯一のオープンソース モデルです。 TII は当初、Falcon が商業目的で使用され、帰属所得が 100 万ドルを超える場合、10% の「使用税」を課すことを要求していました。 しかし、中東の裕福な実業家たちがこの制限を解除するのに時間はかかりませんでした。 少なくとも今のところ、Falcon の商用利用と微調整はすべて無料です。 富裕層は当面このモデルでお金を稼ぐ必要はないと言っています。 また、TIIでは世界各国から事業化プランを募集しております。 潜在的な科学研究および商業化ソリューションについては、さらに多くの「トレーニング コンピューティング能力サポート」を提供したり、さらなる商業化の機会を提供したりする予定です。 これは簡単に言えば、プロジェクトが優れている限り、モデルは無料です。十分な計算能力!お金が足りない場合でも、私たちがお金を集めることができます! スタートアップ企業にとって、これは中東の大物企業による「AI 大規模モデル起業家精神のためのワンストップ ソリューション」にすぎません。 開発チームによると、FalconLM の競争上の優位性の重要な側面はトレーニング データの選択です。 研究チームは、クロールされた公開データセットから高品質のデータを抽出し、重複データを削除するプロセスを開発しました。 冗長で重複したコンテンツを徹底的に除去した結果、強力な言語モデルをトレーニングするのに十分な 5 兆個のトークンが保持されました。 40B Falcon LM はトレーニングに 1 兆トークンを使用し、モデルの 7B バージョンはトレーニングに 1.5 兆トークンを使用します。 (研究チームの目標は、RefinedWeb データセットを使用して共通クロールから最高品質の生データのみをフィルタリングすることです) さらに、Falcon のトレーニング コストは比較的管理しやすくなっています。 TII は、GPT-3 と比較して、Falcon はトレーニング コンピューティング予算の 75% のみを使用しながら大幅なパフォーマンスの向上を達成したと述べました。 推論中に必要な計算時間は 20% のみで、実装に成功しました。コンピューティングの効率的な利用リソース。 
OpenLLM ランキングの問題




 ##Falcon—オープンソース、商用利用可能、強力なパフォーマンス
##Falcon—オープンソース、商用利用可能、強力なパフォーマンス



以上がLLaMAを倒す?史上最も強力な「ファルコン」のランキングには疑問があり、フー・ヤオは個人的に7行のコードをテストし、ルカンはそれを次のような人に転送したの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。