
CTO の視点: 運用保守/SRE 機能を構築する方法

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWB転載
- 2023-06-09 12:37:08939ブラウズ

最近、運用保守職を維持するか維持するかという問題について議論する記事が数多くあります。私が主催する SRETalk 公開アカウントでは、多くの運用保守責任者の意見も投稿しました。また、業界の多くの人々と個人的にコミュニケーションを取りました。いくつかの小さな考えを、CTO/CIO の参考のために記録しました。 SRE の皆さん、混乱している場合は、この記事を注意深く読むことをお勧めします。
これは詳細な考え方であり、退屈かもしれませんが、キャリアの選択とチームの構築に役立つと思います。この記事は、根拠のある議論を歓迎しますが、傲慢は歓迎しません。また、多くのことは白黒つけられません。この記事の内容が皆さんにインスピレーションを与え、CXO の意思決定に新たな考え方をもたらすことができれば幸いです。
また、SRETalk の運用保守責任者へのインタビューは今後も継続し、参考としてさらにさまざまな見解が出力され続ける予定であり、私の見解が必ずしも正しいとは限りません。参考まで。
タイトルについて
まずはタイトルの「運用保守・SRE力の構築方法」についてお話しますが、ここではチームづくりではなく、チーム構築について書きます。目標が達成できない場合があるため、能力を強化する必要があります。独自のチームを構築する必要があります。コスト、結果の予測可能性、長期的な投資とメンテナンスの観点から、慎重な決定を下す必要があります。決定を誤ると、これについては後で説明します。
運用保守/SRE チームについて
もう 1 点、事前に明確にしておく必要がありますが、記事内で言及されている運用保守/SRE チームはすべてビジネスに貢献し、ビジネスの成功に役立ちます。が最優先です。運用保守チームによっては、製品を作って外部に輸出してビジネスとして成立させているところもありますが、それはまた別の話ですし、前職での経験から、運用保守・SREチームのアプローチ(社外)は、特に ToB 遺伝子を持たず、対応する ToB 組織構築を持たない企業では、商業化出力) はお勧めできません。
運用保守/SRE能力をどこで手に入れるか
すべてはビジネスの成功のためなので(ビジネスに関係なく、昇進できるか、上司を騙せるかは別問題)ビジネスがどのような運用保守能力を必要とするか(詳細は後述)、その運用保守能力をどこで取得する必要があるのかが焦点となり、代表的な取得方法は3つあります。
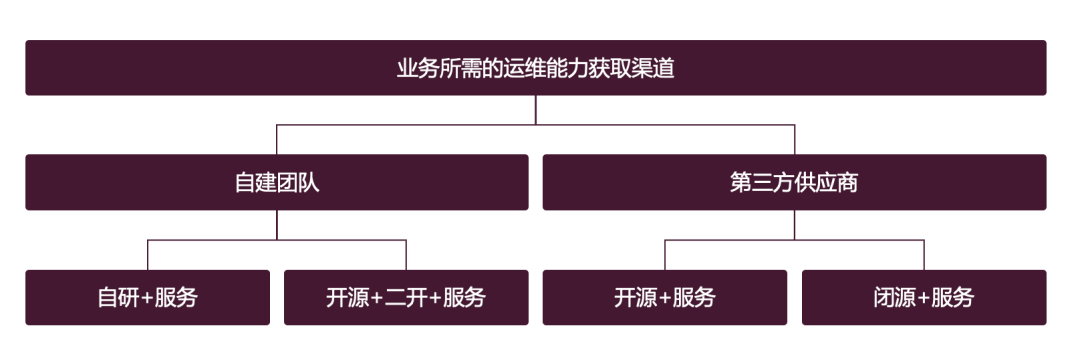
自社構築チーム
1 つ目は、自社構築チームを通じて関連機能を提供することです。この方法が最もよく知られています。自己構築チーム ビジネスへの成果物には、通常、製品とサービスという 2 つの部分が含まれます。まず製品について話しましょう:
- 製品のニーズが一般的なニーズである場合、製品は直接使用できるオープンソース プロジェクトになる可能性が高くなります。オープンソース プロジェクトの耐久性 (オープンソース プロジェクトの開発者が営利企業からの収入援助を受けているかどうか、個人のオープンソース プロジェクトのほとんどは収入がなければ消滅します)、活動 (プロジェクトは何年も更新されていませんか) を考慮する必要があります。 ? 問題や PR が提起されていますか? タイムリーな処理ですか? 通常 1 週間以内の処理はアクティブであると見なされます)、生態学的繁栄 (多くの人が寄付に参加していますか? 多くの企業がそれを使用していますか?)
- オープンですか?ソースプロジェクトには二次開発が必要ですか?二次開発コードをメイン トランクにマージして戻すことができる場合、通常、二次開発コードが汎用性があり、オープン ソース プロジェクト チームによって認識されていることを意味します。メイントランクにマージして戻せない場合、特にタレントが変わった後など、その後のメンテナンスが面倒になります。通常、オープン ソース プロジェクトの API に基づいてグルー コードを作成し、それを内部システムと統合することは可能です。結局のところ、オープン ソース コードは変更されておらず、その後のオープン ソース プロジェクトのアップグレードでも引き続き使用できます。 up.
- もちろん、オープン ソースを使用しない完全な自己研究もあります (オープン ソースの lib ライブラリをいくつか使用し、コア製品ロジックを自分で開発するだけです)。ソースコミュニティには関連する製品がないため、自分で開発するしかありませんが、自分で研究した後、長期的なメンテナンスの問題を考慮する必要があります 研究開発担当者 普段は0から1を作るのが好きです。規模が小さくて昇進も昇給もできないが、異動は簡単だ。運用保守トラックに関しては、オープンソース コミュニティには驚くほど多くの製品があり、自己開発が必要な製品はほんの一握りである可能性があるため、よく考えてください。
2 番目はサービスです。ここでのいわゆるサービスとは、ビジネス側にエクスポートされる専門家のエクスペリエンスを指します。たとえば、自社チームが監視製品を構築する場合、このチームは監視のベスト プラクティスを社内の「顧客」に出力する必要があり、監視製品に問題が発生した場合、このチームは迅速に問題を解決する必要があります。実際、社内のミドルエンドチームとバックエンドチームは、強いサービス精神を持ち、業界のベストプラクティスを理解している必要があり、そうでないと、簡単にビジネスに主導され、ベストプラクティスとは逆の方向に進んでしまいます。業界ではそれがすべて問題です。
サービスの中核は人に依存しています (もちろん、ベスト プラクティスを製品に定着させるのは素晴らしいことです)。マネージャーとして、このチームに良いサービスを提供したいのであれば、多くの人を考慮する必要があります。質問など関連する人材を採用できるかどうか、関連する人材(開発スペース、給与など)を維持できるかどうか、自社チームの各方向に少なくとも 2 人が相互に補完できるかどうか、およびコストを負担できるかどうかなどです。 。
サードパーティ サプライヤー
サードパーティ サプライヤーを通じて運用および保守機能を入手することも別の方法であり、サプライヤーの成果物には明らかに製品とサービスの 2 つの部分が含まれます。製品にはオープンソースとクローズドソースの2種類がありますが、どのような点に注意すればよいでしょうか?
- オープンソース製品には通常、より多くのユーザーとより多くのシナリオを磨き上げる必要がありますが、一部のロングテール要件は通常、オープンソースではありません。その理由としては、オープンソース チームが有料アイテムとして、次のいずれかを行います。オープンソース チームは、これらのロングテール要件は一般的ではなく、製品に組み込む価値がないと考えています。
- 通常、クローズド ソース製品の利用者は少なく、製品の磨き上げに協力してくれるオープン ソース ユーザーは多くありません。商用顧客が長期間かけて磨き上げる必要があるか、クローズド ソース製品のサプライヤーが非常に強力な品質. 管理システム、製品の完全なテスト、これには大企業のサプライヤーを見つける必要があります. さらに、テスターとエンドユーザーは結局のところ別のグループであり、商用顧客による磨きが不可欠です. しかし、サプライヤーが販売者が持っている場合は、強力な品質保証チームにより、研磨プロセスが短縮されます。
- オープンソースであろうとクローズドソースであろうと、サプライヤーは製品に付属しています。当事者Aとして、それを直接テストして、製品がどのように適合するかを確認し、フィードバックを迅速に得ることができます。自己構築チームを構築する場合は、 , 開発には数カ月、場合によっては1~2年かかる場合もあり、企業側としてはそれを待つ余裕がない場合もあり、開発後に本当に期待に応えるかどうかはさまざまな要素によって決まり、結果は予測できません。
2 番目はサービスであり、通常、サプライヤーは自社で構築したチームよりも有利です。その理由は次のとおりです。
- サプライヤーはより多くの顧客シナリオと ToB 企業を見てきたため、業界のノウハウの長期蓄積がこの会社の核となる競争力であり、サプライヤーは今後も継続的に卓越性から学ぶ: 顧客から経験を学び、それを経験の浅い顧客にフィードバックすることで、すべての関係者にとって好循環と Win-Win の状況が生まれます。
- これは、サプライヤーがより多くのシナリオを認識し、製品をより適切に抽象化し、製品をより汎用性があり、より製品に近づけることができるためでもあります。自主構築チームによって作成された製品は、通常、よりツール指向です。攻撃を意図した、つまり通常は。
- サプライヤーが運用保守分野で事業を始める理由は、この分野で何らかの実績を上げていることが多いため、自社で構築したチームに比べて、トップレベルの知識を持っていることが多いです。本当に行く 人材を採用すると、最も才能のある人材が事業を始めているか、高すぎるか、来ようとしないかのいずれかであることがわかります。
さらに、コストの問題について話しましょう。サプライヤーの料金は、おそらく自分で人を採用するよりも費用対効果が高くなります (適切な人材が採用されている場合)。そうでない場合、ビジネス ロジックは機能しません。所有。この原則は明白であり、再度繰り返すことはありません。
サードパーティのサプライヤーから運用とメンテナンスの機能を得るのは、自作チームにとって圧倒的なようですが、それでも次の記事を読む必要がありますか?実際には、必ずしもそうとは限りません。ある運用保守能力において、より重要なのは製品能力かサービス能力です。最も必要なのは製品能力かサービス能力です。ケースバイケースで検討する必要があります。後ほどビジネス面から見ていきますが、運用と保守の機能はすべて個別に分解されます。
ビジネスにはどのようなテクニカル サポート能力が必要ですか?
運用とメンテナンスの本質は、一種のテクニカル サポート能力であり、インフラストラクチャ チームとよく似ています。運用保守チームに入れてもインフラに入れてもいい チームの問題は大きくない 企業によってはそのような人を直接業務開発チームに入れているところもある とりあえず分業は無視してまず整理しようビジネスが必要とする技術サポート能力の種類。
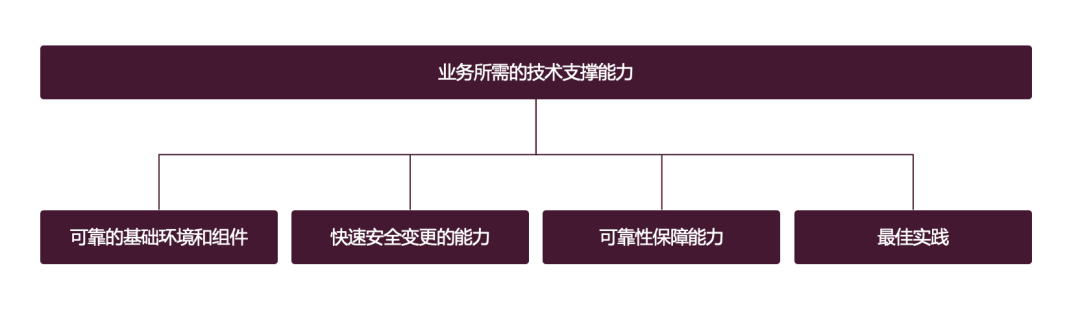
この図は問題を非常によく説明しています。もう少し詳しく説明します:
- 信頼性の高い基本環境とコンポーネント: ビジネス プログラムを実行するには、基本的なネットワーク、ハードウェア、オペレーティング システム、データベース、ミドルウェアなどが必要です。これらの環境とコンポーネントは、安定性と信頼性が高くなければなりません
- 高速能力: 迅速な変更を行う能力は、誰にとっても簡単に理解できます。開発者として、機能を作成したりバグ修正を行ったりするときは、間違いなくそれを迅速に提供したいと考えますが、変更は簡単に失敗につながる可能性があるため、変更が必要です。
- 信頼性保証機能: ソフトウェアを本番環境に導入した後、さまざまな問題が発生する可能性があります。リスクを事前に定量化する方法、迅速にリスクを定量化する方法問題を発見し、問題を特定し、損失を迅速に阻止する必要があります。これはビジネス側の問題である可能性があります。運用および保守側の最も重要な要件は
- ベスト プラクティスです。ビジネスは多くの基本的なサポート機能に依存しています。これらの機能はどのように使用されますか?それは業界のベストプラクティスですか?それは社内の他のほとんどの業務にとってベストプラクティスですか?ビジネスにフィードバックするための基本的なサポート チームが必要です
各能力の取得方法
上記の 4 つの能力はどのように取得すればよいでしょうか?では、それを分解して話してみましょう。
信頼性の高い基本環境とコンポーネント
まず、基本的なハードウェア環境について説明します。当然のことながら、クラウドかセルフビルドの 2 つのオプションがあります。ポリシーで変更が必要な場合は、どちらかを選択する必要があります。自分でやる、方法はありません。ポリシーが優先されます。自分で選べるのであれば、今の時代はクラウドの方が向いている可能性が高く、よほどの規模で大量のマシンを持っている会社でない限り、自分で構築する方が有利かもしれません。ここで言うことはあくまで可能性のある であることに注意してください。コストを計算するときは、ハードウェアのコストだけでなく、人件費も含めることを忘れないでください。
キャリアの選択について: システム運用保守エンジニアやネットワーク運用保守エンジニアにとっては良いニュースではないようです。クラウドの出現により、一部の企業にとっては確かにスペースが奪われています。時代の歯車は前に進み、誰もが歴史の塵となる。
MySQL、Redis、MongoDB、Kafka、ElasticSearch、Nginx、Kubernetes などのコンポーネントについて話しましょう。明らかに 3 つのオプションがあります。クラウド PaaS 製品を使用するか、独自に作成するか、独自のハードウェアを製造し、サプライヤーがソリューションとサービスを提供します。それぞれの選択肢について、それぞれコメントを付けます。- クラウド PaaS 製品: 規模が小さく、関連する人材の予備がない場合は、クラウド PaaS 製品を使用する方が適切です。構築中に、クラウド上で PaaS 製品を使用することを選択した当事者 A は、通常、既にクラウド上で仮想マシンと Kubernetes のようなランタイム環境を使用しています ちなみに、PaaS 製品の購入は比較的スムーズであり、新しいサプライヤーを必要としません。
- 自分でやる: 特定のコンポーネントが非常に大きい場合、Kafka など、自分でビルドする必要がある場合があります。自分でやる、メインとバックアップの 2 人を雇います。レベルは悪くありません。 、何か問題が発生した場合でもすべてを確信できます。北京の年間コストは約 100 万ですが、ハードウェアとコンポーネントからこのお金を節約する規模はどれくらいですか?もちろん、低コストの運用保守エンジニアを採用することもできます (
- 強調、ここでは運用保守エンジニアが必要になる可能性がありますが、そのランクは高くありません)。日常的な問題と高度な問題を解決する いいえ、高度な問題については外部プロバイダーの専門サービスを利用できます。 独自のハードウェア サプライヤーにソリューションとサービスを提供する: クラウド ベンダーの PaaS 製品と比較して、サードパーティのサプライヤーは通常、コスト効率が高く、応答が速いですが、コンポーネントが非常に多いため、各サプライヤーは入手できるアイテムの数には限りがありますが、甲としては複数のサプライヤーと同時に取引しなければならない場合があり、少し面倒です。統合モニタリング、障害位置特定、FinOps 関連製品など、クラウド間のコラボレーションが必要な製品の場合、企業が複数のクラウドまたはハイブリッド クラウド アーキテクチャを使用している場合、サードパーティ サプライヤーの方が適している可能性が高くなります。
キャリアの選択について: さまざまなコンポーネントの経験豊富なベテランの場合、最初の選択肢はクラウド ベンダーで働くか、経験をエクスポートするために起業することであり、2 番目の選択肢は自社部品を製造する大手メーカーに依頼する 一般的に、中小規模の工場では給与が高いことが難しいため、サードパーティの専門家によるサービスは費用対効果が非常に高くなります。
迅速かつ安全に変更できる機能ビジネスの研究開発で行われる最も一般的な変更は、バイナリ変更と構成変更です。基本的な環境とコンポーネント。 まずバイナリと構成の変更について話しましょう。どうすれば迅速かつ安全に反復できるのでしょうか?段階的に行うこともでき、会社がまだ比較的小さい場合は、ツールの構築にそれほど注意を払う必要はなく、仕様とプロセスを設定するだけで済みます。標準的な側面: どのアカウントがどのディレクトリにデプロイされるか、ログの保存方法、プロセスのホスト方法、変更はロール可能でなければならないなど。プロセスに関しては、変更通知メカニズム、オンラインでのマルチモジュールの共同作業など。承認メカニズムなどが必要です。 次に、過去の四半期に特定のチームが行った変更の数、ロールバック率、失敗率など、過去の変更に関する定量的なデータが必要になります。比較して、成績が良くなかったチームは次の四半期には改善されるでしょう。企業が成長を続けると、変革プラットフォームの構築、プラットフォーム上での標準化されたシステムの実装、および定量的なデータの生成に人的資源を投資できます。従来の物理マシンと仮想マシンの時代では、企業ごとに状況が異なるため、商業的な変更システムを見ることはほとんどありません。もちろん、Kubernetes の台頭後、根本的な違いの多くは隠蔽され、Kubernetes に基づいて変更を加えるためのプラットフォームははるかに汎用性が高く、関連製品も登場し始めています。
実稼働環境への変更は、テスト環境や共同デバッグ環境への変更と同じではありません。実稼働環境にはより厳しい安定性要件がありますが、テスト環境と共同デバッグ環境の要件は比較的低いです。いわゆる CI/CD システムは、テスト環境や共同デバッグ環境向けに設計されたものが多く、本番環境に CD を導入できる企業は限られています。
焦点: テストおよび共同デバッグ環境用の CI/CD システムは、研究開発効率の向上に重点を置き、運用環境の変更システムは安定性と実装の確保に重点を置いています。 。初期段階では会社が小さいため、規定や規定に頼るだけで十分ですが、その後は規定や規定の変更、プラットフォームの変更による協業が必要になります。
この規制制度は誰が決めるのでしょうか?変革プラットフォームを開発するのは誰ですか?
仕様策定は実は初期段階にありますが、運用保守チームが存在する前に仕様が決まっている可能性もありますので、CTOやその下位のコアチームが策定する可能性が高いです。それらを定式化します。まだ策定されていない場合は、運用保守責任者(運用保守責任者はこちら)が主導して策定し、CTO以下のコアチームが検討します。 (全員が参加し)最終的には CTO が決定し、(トップダウンで)公開し、全員が実行します。
変更プラットフォームの開発は運用保守チームが行うのが比較的適切であり、その後、他のプラットフォームを導入し、専任の運用保守チームを設置する予定です(両者に違いはありません)。ここで言う運用保守と SRE (このチームを SRE チームと呼ぶこともできます) が適切です。プラットフォームを変えるには自社の仕様を実装する必要があるため、アウトソーシングするケースは比較的少なく、企業がある程度の規模になると、オープンソースのものをベースに自社で研究・蓄積していく選択になる可能性が高いです。
キャリアの選択について: 変更管理は企業の重要な部分であり、システムの安定性にも役立ちます。これは典型的な DevOps のポジションであり、上限は約 P7 レベルです (完全に個人的な意見であり、参考までに)。
もう 1 つは、基本的なコンポーネントと環境の変更です。通常は、MySQL テーブル構造、Nginx 構成、DNS、VIP などです。このような変更は、コンポーネントの管理と制御に組み込まれます。これにより、コンポーネント機能プロバイダーは、変更入力機能と管理制御機能を提供します。
信頼性保証機能
この機能は非常に重要で、SREとはSite Reliability Engineeringの略で、サイト信頼性エンジニアリングのことです。 CTOの観点からすると、ソフトウェアを本番環境に導入する際には、将来的にさまざまな問題が発生する可能性があり、信頼性を確保するためのエンジニアリング体制を整えておきたいと考えています。これは大きなテーマですが、この記事では詳しくは説明しません。何が原因で、誰が責任を負うのかを明確にするだけです。
いわゆる信頼性は、障害と戦うプロセスです。したがって、私たちは依然として障害のライフ サイクルを、ライフ サイクルの各リンクから開始して、障害を打ち負かすか、直接破壊するために調べます。 . ゆりかごの中。
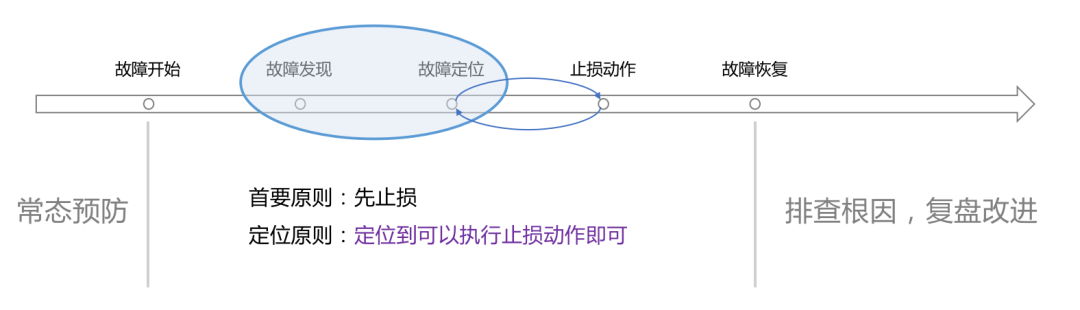
#障害が発生する前に、予防とリスク管理でやるべきことがたくさんあります。
例えば、アラーム完備基準の策定と各事業ラインの定量的評価、ポジショニングの原則とプロセス、障害の等級付けと責任の基準の策定、各事業のコア機能とサービスモジュールの対応関係を事前に整理し、グローバル安定性ビューまたはウォー ルームは、障害のあるモジュールやインターフェイスを迅速に特定するため、アーキテクチャを最適化するため、障害計画を整理し、定期的な訓練を実施して最新の状態に保つために使用されますが、これはカオス エンジニアリングの混乱です。 ここには、アーキテクチャの最適化など、ビジネスの研究開発が必要なものがいくつかありますが、残りについては、私の提案は次のとおりです:運用保守チームが主導権を握り、研究開発に協力する。例えば、CTO直下のコアチームは、事業ごとに運用保守職と技術職を兼任することが多く、名目上CTOが意思決定し、運用保守職が主導権を握ることになります。各事業が連携する研究開発職 もちろん、実際の運用に関しては、No.1の運用保守職に将来実際の運用を任せられる有能な人材が見つかるかもしれないし、各事業ラインにも頼れる人材がいるかもしれないインターフェースサポートを提供するNo.1の技術的地位にあります。
アーキテクチャの最適化を除いて、これらの他のことはすべて水平的な問題です。全員を集め、これらの方法論とベスト プラクティスを共有するのに役立ついくつかの方法論とベスト プラクティスが存在する可能性があります。もちろん、「このような安定した仮想組織を形成し、この問題を共同で推進してくれる人を研究開発チームから直接見つけられるだろうか?」という疑問を持つ人もいるでしょう。実際に試してみることもできます。ただし、いくつかの問題が発生します:- 各ビジネス ラインには通常、インターフェイス担当者が 1 人か 2 人しかいません。人員が減り、仕事が増えると、この担当者はビジネス コードの開発と安定化作業のバランスを取るのが困難になる可能性が高くなります。この担当者が安定性をフルに発揮する場合、 SREについて
- SREの場合、実は事業の研究開発担当者とは評価制度が異なりますが、KPIはどうやって決めるのですか?そして、この人は良い帰属意識を持っていない可能性があります。
- この人が安定性とビジネスの研究開発という 2 つのことを同時に担当すると、人々の惰性が生じる可能性があります。安定性の仕事で問題が発生すると、彼らはビジネスの研究開発で問題が発生すると、彼らは怠けて安定した作業をしたいと思うでしょう。事前の予防とリスク管理 制御については、CXOが運用保守責任者に結果を求めますが、上から下まで多大な協力をして推進する必要があります。この問題を解決するSREエンジニアの役割には、非常に専門性の高いハイレベルな人材が必要と思われますが、入社5年以内に認知能力が追いつかない可能性が高いと考えられます。 CXO は、ぜひ試してみてください。
#障害発生後の影響を軽減する障害が発生した場合、私たちの主な目標は影響を軽減することになります。関連チームは直ちに協力して直接原因を迅速に特定し、損失を迅速に阻止し、その後根本原因をゆっくりと調査しました。ここでは、次の作業内容が関係します:
障害の定義: 通常、ビジネス指標に問題がある場合、注文量の減少、注文量の減少など、障害が始まっていることを意味します。配車サービスの通話量が増加し、支払額が減少すると、上司はこのタイプの指標に特に注意を払うでしょう。マシンの CPU が急増したり、ディスクがいっぱいになったりしても、それはチームによって内部的に問題が解決されているだけである可能性があります。 K8s のようなシステムはドリフトを自動的に解決しますが、通常、これは顧客のメインプロセスに影響を与えず、上司は注意を払いません。混同しないように、障害と問題の定義を区別する必要があります。事業分野が異なれば指標も異なりますが、全体的な方法論は同じです。
障害への対応: 障害アラームの受信者はビジネスの研究開発ですか?それともSRE?それともオンコールセンターでしょうか?企業によってそのやり方は大きく異なりますが、私の個人的な考えは、「対応できる人に直接送ってください!」です。白か黒かはありません。アラームが異なれば処理メカニズムも異なります。たとえば、基本的なネットワークに問題があれば、当然ネットワーク エンジニアに送信されます。特定のビジネスに問題がある場合は、ネットワーク エンジニアに送信されます。対応する運用保守および研究開発に送信してください。途中で再転送しないようにしてください。Zhang San に送信してください。Zhang San が処理できずに Li Si に連絡した場合、時間の無駄です。トラブルシューティングは必要があります。時間との勝負で行われます。 迅速な位置特定: 効果的な障害位置特定システムは非常に重要です。障害位置特定システムは通常、可観測性データに基づいて構築され、コックピット レベルの製品とみなすことができます。可観測性データは膨大であり、これらの膨大なデータを整理して活用しなければ価値のある情報に変えることはできません。測位の観点から、通常必要なのは、可観測性システム、障害位置、継続的な運用です。ここで説明するには内容が多すぎます。詳しく話したい場合は、私に連絡してください。連絡方法がわかりませんか? SRETalk 公式アカウント、詳細をご覧ください。- 迅速なストップロス: ロスを迅速にストップするには、完全な計画を立てる必要があります。各障害をレビューするとき、CTO と運用保守ディレクターは計画の有効性に注意を払うことをお勧めします。 、失敗の原因が、既存の計画が損失をストップするために使用されるか、解決策が保存されるかどうかです。今保存されている場合は、計画が十分に完了していないことを意味します。
- OK、上記は雄弁ですが、質問に戻りますが、この作業内容の場合、CTO は誰に結果を求めるべきでしょうか?私の提案は次のとおりです: SRE チーム (この記事では運用保守と SRE という言葉が何度も出てきますが、この記事では基本的に同じ意味です。ここでの運用保守は運用だけではありません)。明らかに、SRE がすべての障害を解決できるわけではありません。ほとんどの障害は他のチームの人材に頼らなければなりませんが、CTO は常にチーム A とチーム B に行くことができるわけではありません。したがって、
- SRE は、CTO の「上方の剣」を担い、全体の安定構築を主導する必要があります。各事業は、輸出インターフェースの最善の協力を必要とします。いわゆる安定構築には、事前の予防的リスク管理と全体的なリスク管理が含まれます。イベント中の企画や調整を行い、その後のレビューを促進することが、企業にとってのSREの最大の価値でもあります。
ベスト プラクティスこれには、どのモデル パッケージがより適しているか、どのネットワーキング方法がより適しているか、企業がどのコンポーネントをより適切に管理できるかなど、多くのコンテンツが含まれています。 、より良いサポートは受けられますか (社内チームかサードパーティのサプライヤーか)、企業が推奨または要求しているプログラミング言語とフレームワークは何ですか、業界が推奨するアクセス層ソリューションは何ですか?変更計画とは何ですか?可観測性をどのように実現するか?などなど 優れたビジネス研究開発チームのこれらの実践的な方法が明確であることは否定できませんが、ビジネスラインが増えるとレベルが混在し、レベルの低いチームには必然的に次のような人材が必要になることも否定できません。コーチングの役割(常に実現できるわけではない) 何でも CTO に相談する 水平的な技術チームとして、SRE チームはこの問題を担当するのに特に適しています。しかし、明らかに、これは新人が埋めることのできないハイエンドのポジションです。BP としてビジネスを行うためにハイレベルの人材を採用することは、テクノロジー スタックの統合を促進する効果的な手段です。CTO がこの出発点をうまく活用しないと、テクノロジーはシステムを開花させますが、その背後にはさまざまなガバナンスのジレンマが存在します。 上記の4つのサポート力、ビジネス側はどうやって獲得するか、CTOはどう調整するか、各チームはどう連携するか、これだけです。以下にさらに 2 つの要約をしてみましょう。 運用保守監視システム実践ノート #」の著者##"、パブリック アカウント SRETalk のマネージャーであり、Kuaimao Nebula の起業家パートナーです。起業家の方向性は安定性を確保することです。何かご要望がございましたら、お気軽にご連絡ください。
以上がCTO の視点: 運用保守/SRE 機能を構築する方法の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。