
ビジネスは急激に成長していますが、ユーザビリティの構築はそれほど安定しているでしょうか?

- PHPz転載
- 2023-06-09 00:17:131022ブラウズ
1. 問題と課題
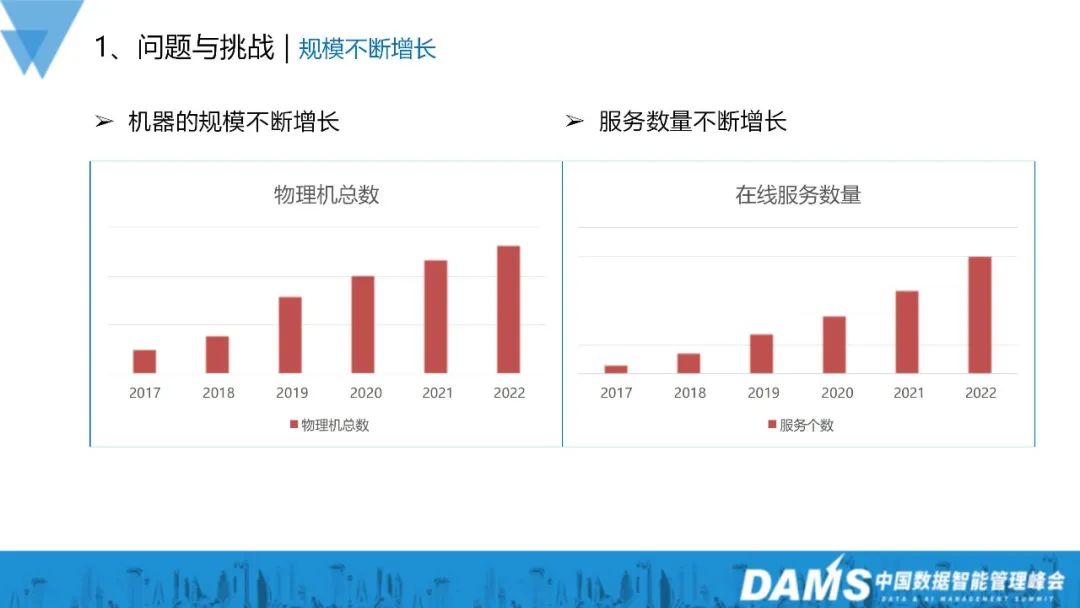

当社の 1 回のリリース期間は比較的長いです; 大規模なビジネス移行のシナリオは数多くあります; Google SRE には次のようなコンセプトがあります: 70%失敗は変化によって引き起こされます。この状況は生体内でも存在しており、変化はオンラインの安定性に大きな影響を与えます。 2. 障害の課題
- コンピューター室レベルの障害リスク (大企業でも中小企業でも遭遇する可能性があります)ファイバー マイニングの停止やコンピューター ルームの内部障害など);
- ビジネスの急速な成長により、必要な容量が大幅に増加しました。
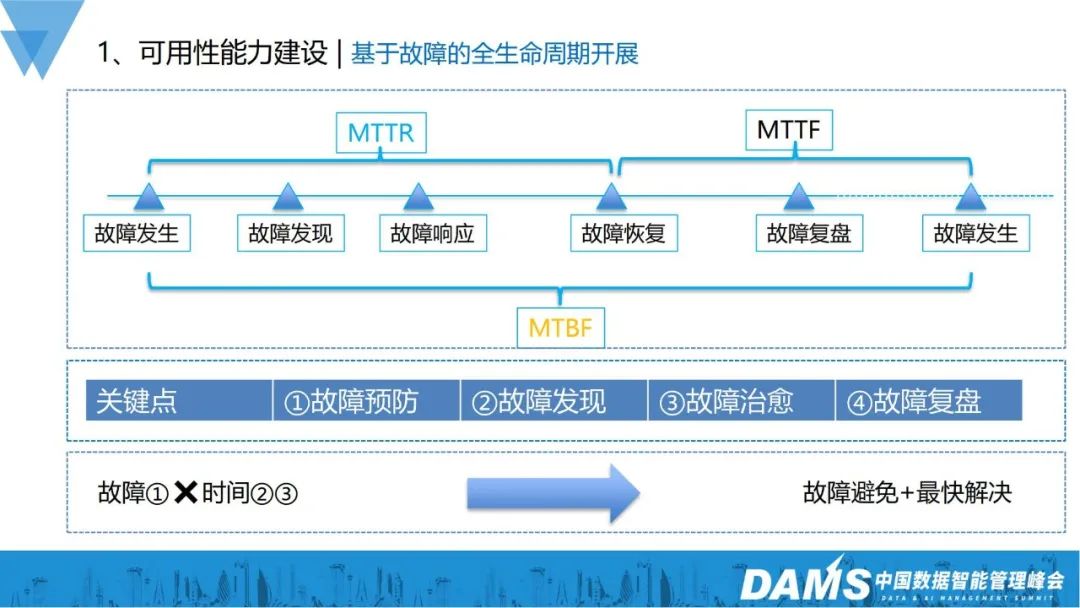
# 当社の可用性機能の構築は、障害の発生、発見、対応、回復をカバーするフルサイクルの障害管理に基づいています。 、見直しと予防策。障害発生から回復までの時間をMTTR、障害回復から発生までの安定から不安定までの時間をMTTF、障害発生から障害発生までの時間をMTBFといい、合計3つの指標があります。
障害管理とは次の 4 点にすぎません。
障害の発生をどう防ぐか。- 障害をできるだけ早く見つけるにはどうすればよいでしょうか?
- 障害を迅速に解決するにはどうすればよいですか?
- 障害が復旧した後のフォローアップ方法は?
主にビジネスの可用性を考慮し、障害の頻度とそれがビジネスに影響を与える時間に注意を払う必要があります。したがって、障害の頻度を減らし、障害を迅速に特定し、障害の期間を短縮し、迅速な障害修復を達成することが、当社の高可用性機能構築全体の一般的な考え方となります。
#2. 障害発生解析
まずは、当社の取り組みをご紹介します。障害を防ぐには、まず障害が発生する原因を理解する必要があります。これは、サービスの観点とフルリンクの観点から見ることができます。
#1) サービスの観点
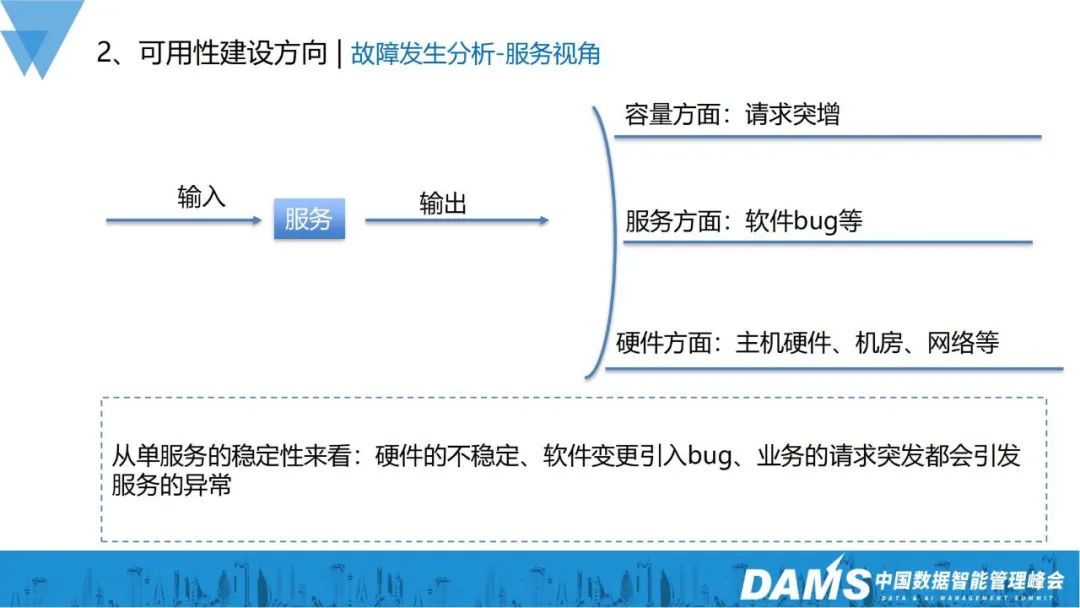
#キャパシティの観点: ビジネス リクエストの急激な増加は、単一サービスの異常な出力につながります。
サービス側: ソフトウェア自体にバグがあり、その結果サービスがクラッシュする;
- ハードウェア側: ホストのハードウェア、コンピューター室、ネットワークに起因する異常。
- #2) フルリンクの視点
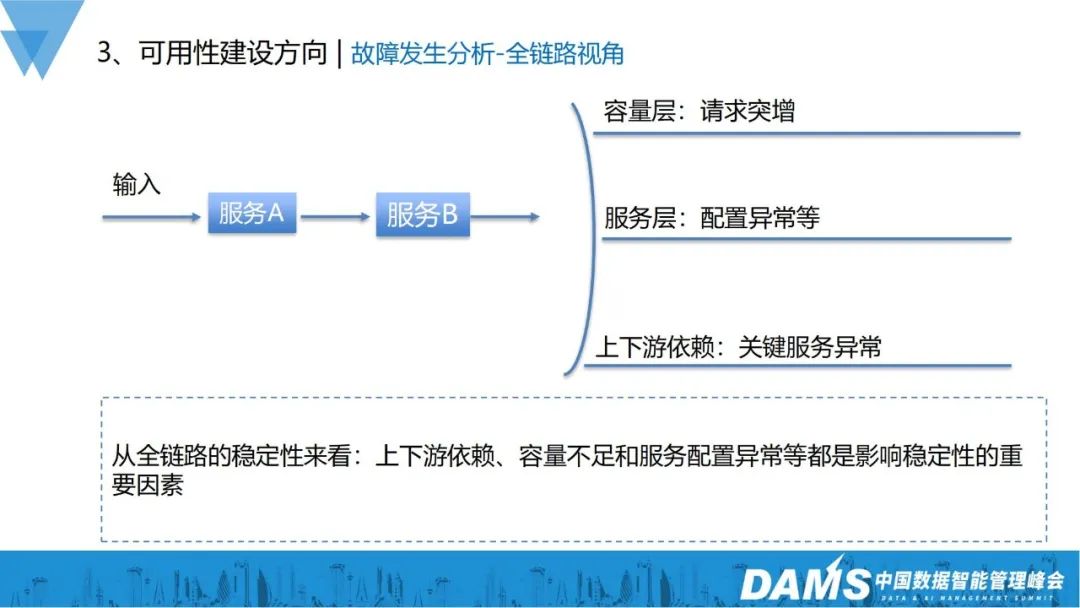
サービス レイヤー: サービス間で協調的な構成が必要です。不正解構成設定は、リンク全体の異常を引き起こす可能性もあります。
- アップストリームとダウンストリームの依存関係: 一部の主要なサービスの異常により、リンク全体に異常が発生する可能性があります。
- リンク全体の安定性の観点から見ると、上流と下流の依存関係、容量不足、異常なサービス構成はすべて、安定性に影響を与える重要な要素です。
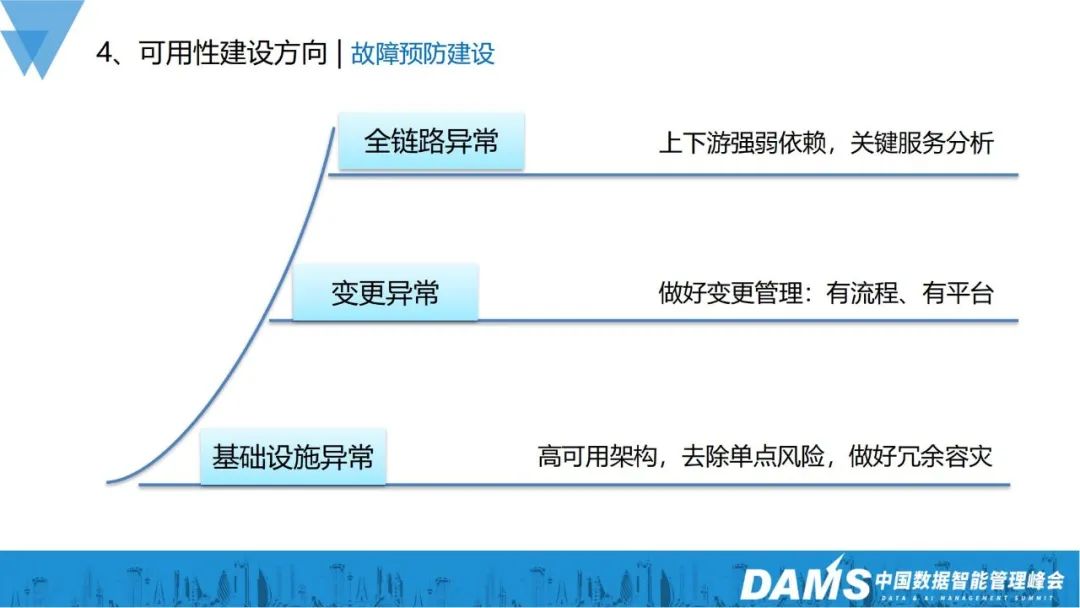
- #フルリンク異常: 上流と下流の強みと弱みを分析し、特別な保護を提供する必要がありますキー サーバーの場合、リンク全体の安定性を確保します;
- 変更の例外: 変更プロセスの仕様と変更管理プラットフォームを確立します;
- インフラストラクチャの例外: 高可用性アーキテクチャに依存し、単一ポイントを削除しますリスク、優れた冗長性と災害復旧。

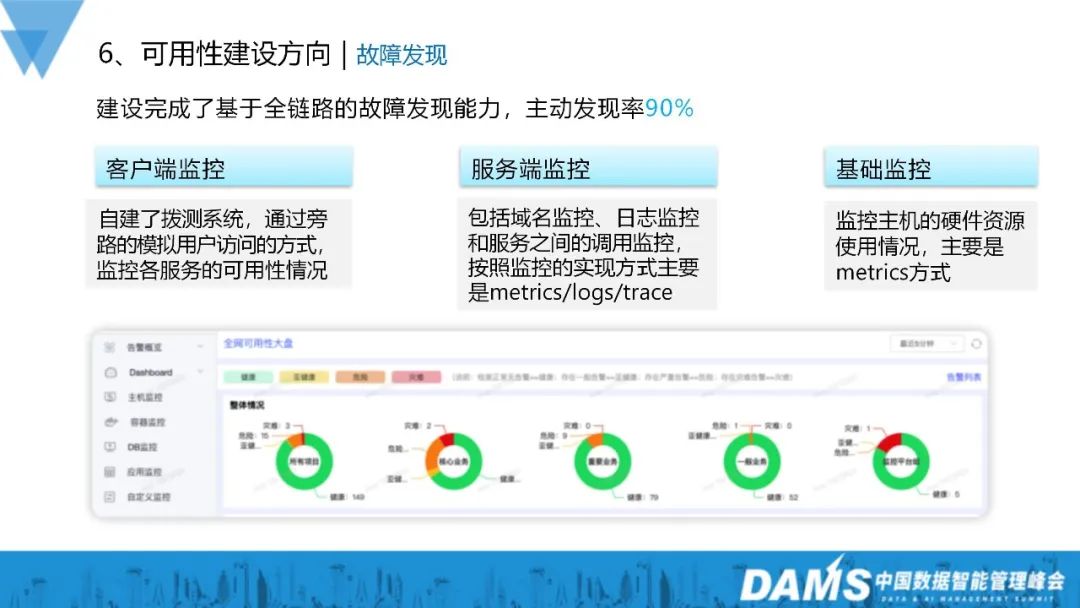
#1) クライアント監視: 自社構築のダイヤルアップ テスト システム、シミュレートされたユーザー アクセスをバイパスして各サービスの可用性を監視; 2) サーバー監視: ドメイン名監視を含む、ログ監視とサービス間の呼び出し監視監視実装方法によると、主にメトリクス/ログ/トレースです; 3) 基本監視: ホスト状況のハードウェア リソース使用状況を監視します、主にメトリクスの形式で。 #6. トラブルシューティング 主に障害解析と障害対応が含まれます。
 障害分析: 監視システムと連携し、基本的なサービス障害分析をサポートします。ドメイン名の可用性分析など;
障害分析: 監視システムと連携し、基本的なサービス障害分析をサポートします。ドメイン名の可用性分析など;
- 7. 障害回復
障害回復は、高可用性構築サイクル全体において非常に重要です。一部。
当社はビジネスベースの SLA グレーディングを使用して、目標を絞った方法でビジネスの安定性を確保します。ビジネスのすべての障害を記録し、能力構築を改善および検証する: 
1) ビジネスの分類: 運用および保守のリソースは非常に限られており、すべてのビジネスが同じ SLA を持つようにするため、分類を保証します。ビジネスの評判と収益に基づいて、当社はビジネスをコア、重要、一般、その他の 4 つのビジネス レベルに分けます。これにより、運営および保守の人員が導き出され、各ビジネスに投資される労力が保証されます。
2) 障害記録: レビューの効率を向上させ、オンライン ビジネスの障害を追跡して後続の分析を行い、ビジネスの最適化を導きます;
3) 障害の改善: 逆方向検証を実施します。カオスエンジニアリングに基づいて、改善策が効果を上げているかどうかを判断します。
これは障害レビューにおける当社の実践であり、これらの機能と実践をプラットフォームに実装し、プラットフォームを通じて障害レビュー作業を管理しました。
8. キャパシティ管理
##オンライン障害の多くは、容量の問題が原因です。容量リソースが確保されれば、可用性はある程度保証されます。この点で、当社は主に、リソースの弾力的なスケーラビリティとリソース配信オペレーションの 2 つの側面で機能を改善しました。 . 管理能力。
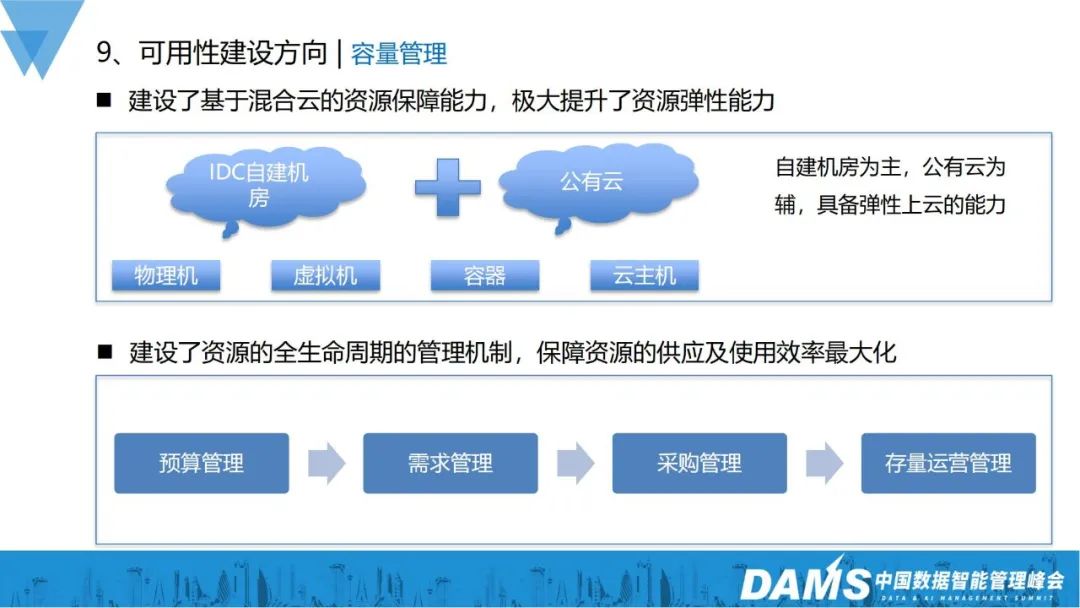
- リソースの弾力的なスケーラビリティ: ハイブリッド クラウド ベースのリソース保証機能を構築して、リソースの弾力性を大幅に向上させます。
- リソースの配信、運用、および管理の機能:予算管理、需要管理、調達管理、在庫運用管理など、資源の供給・利用効率を最大限に高めるため、資源のライフサイクル全体にわたる管理の仕組みを確立します。
3. ユーザビリティフェーズの構築
ユーザビリティ機能を構築した後、それを 3 つのステージに分けてユーザビリティを構築します。プロセス段階とプラットフォーム段階。
1. 標準化段階
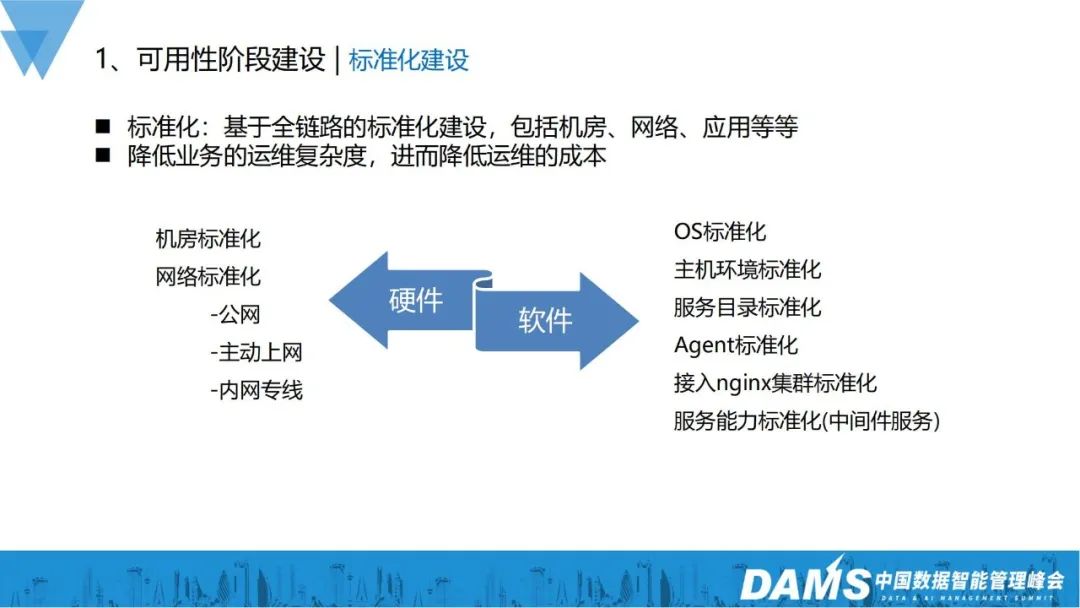
##なぜ標準化を構築する必要があるのでしょうか? 標準化により、ビジネスの運用と保守の複雑さが大幅に軽減され、運用と保守のコストが削減されます。私たちはハードウェアとソフトウェアの両方のレベルで多くの標準化作業を行ってきました。
- ハードウェア レベル: コンピュータ ルームの標準化、ネットワークの標準化 (公衆ネットワーク、アクティブなインターネット アクセス、イントラネットの専用線);
- ソフトウェア レベル: OS の標準化、ホスト環境の標準化、サービス カタログの標準化、エージェントの標準化、nginx クラスターへのアクセスの標準化、およびサービス機能の標準化 (ミドルウェア サービス)。

##まず第一に、運用と保守の軍事規制を含め、ビジネスの安定性が秩序正しく管理可能であることを保証するために、運用と保守のプロセスにおけるベスト プラクティスと手法をプロセスのメカニズムと仕様に凝縮します。対応メカニズム、広報仕様、大規模イベント保証仕様など
例えば、大規模な運営活動や春節の紅包配布活動など、大規模イベントの保証仕様が確立されていない場合、 2018年以降 大規模イベントの保証基準を定めた上で、春節などの厚い保険を適用することでスムーズな運営を保証します。
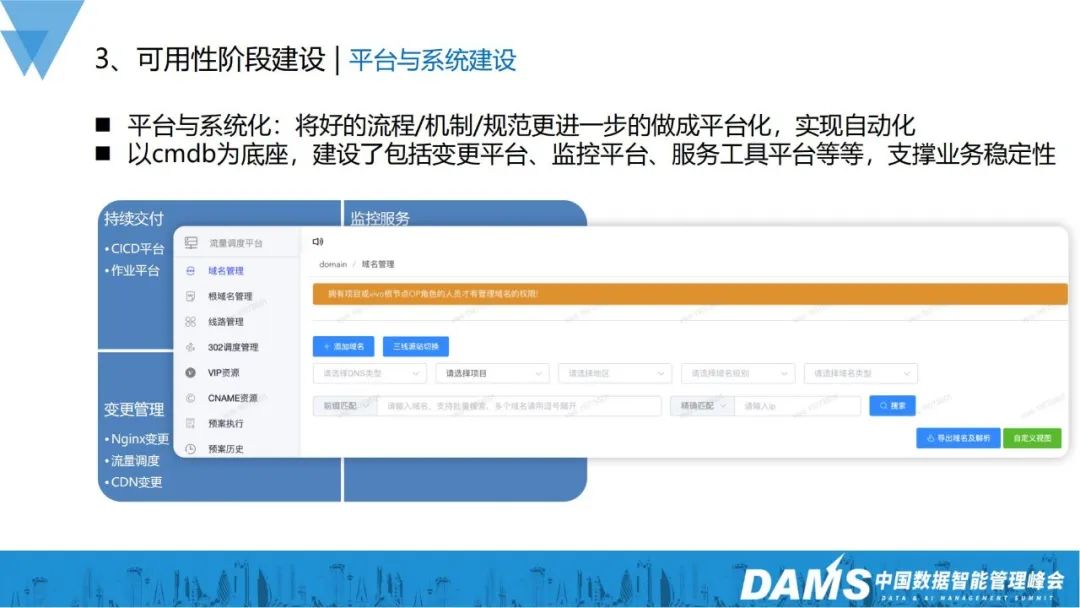
#3. プラットフォームとシステム構築
4. 可用性の結果と見通し
2022 年までに、全体的なビジネス安定性の運用と維持が秩序正しく効率的になり、ビジネスの可用性が向上します。スリーナインはフォーナインに増加し、基準を満たす事業所も従来の8社から24社に増加しました。
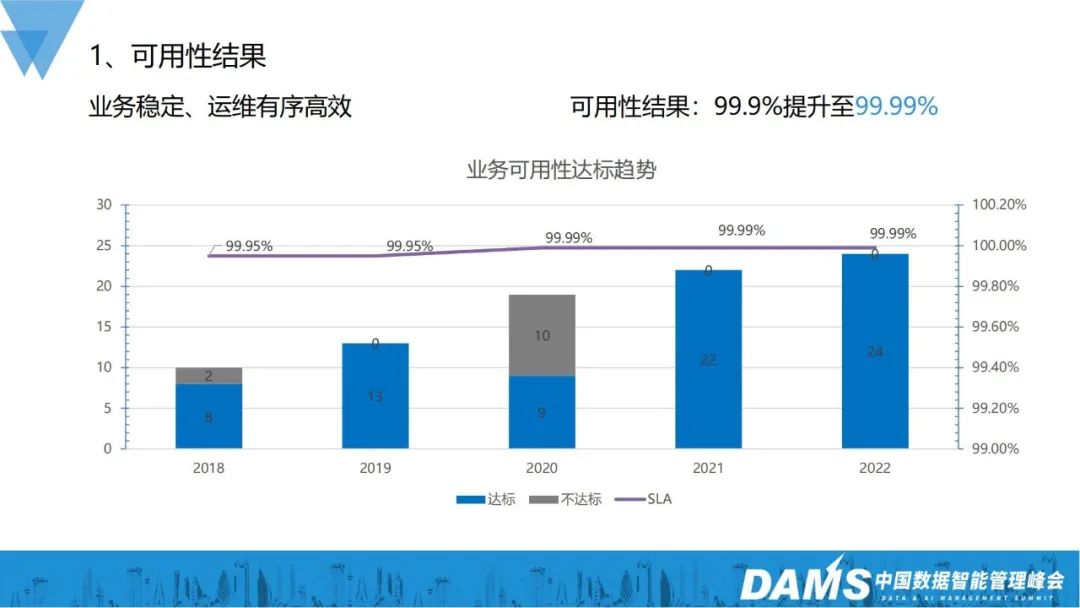 #このユーザビリティの結果を達成するには、主にユーザビリティ機能の構築とユーザビリティ フェーズの構築を通じて行います。
#このユーザビリティの結果を達成するには、主にユーザビリティ機能の構築とユーザビリティ フェーズの構築を通じて行います。
可用性機能の構築: 障害の予防、障害の発見、障害の修復、障害のレビュー
可用性フェーズの構築: 標準化、プロセス/標準化、プラットフォーム/自動化

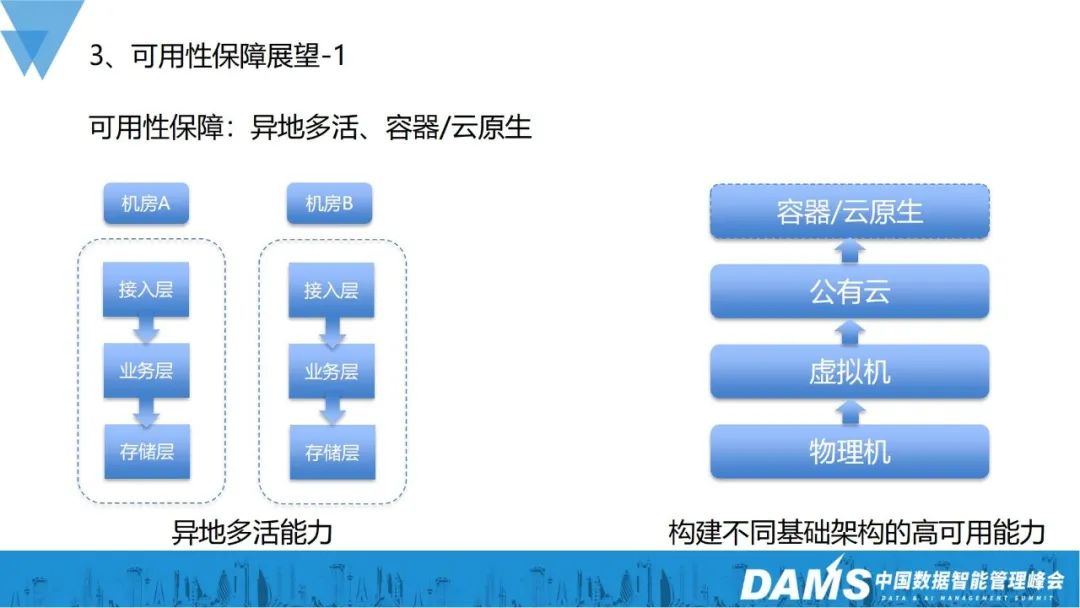 # コンテナとクラウド ネイティブの可用性保証を例に挙げると、さらに多くの IT が提供されます。は純粋な物理マシンですが、その後、仮想マシンが追加され、さらにパブリッククラウドが追加され、基盤となるインフラへの直接依存がさらに軽減されるとともに、リソースをユニット化し、柔軟に対応するためのコンテナやクラウドネイティブにも取り組んでいます。物理ハードウェア リソースに直接依存するため、さまざまなインフラストラクチャ向けの高可用性機能を構築する必要があります。
# コンテナとクラウド ネイティブの可用性保証を例に挙げると、さらに多くの IT が提供されます。は純粋な物理マシンですが、その後、仮想マシンが追加され、さらにパブリッククラウドが追加され、基盤となるインフラへの直接依存がさらに軽減されるとともに、リソースをユニット化し、柔軟に対応するためのコンテナやクラウドネイティブにも取り組んでいます。物理ハードウェア リソースに直接依存するため、さまざまなインフラストラクチャ向けの高可用性機能を構築する必要があります。
個人的には、可用性、ビジネス品質、運用コストだけを考慮する必要はないと考えています。これらはすべてです。事業の運用保守保証は、さらに洗練された運用保証の段階に入ります。 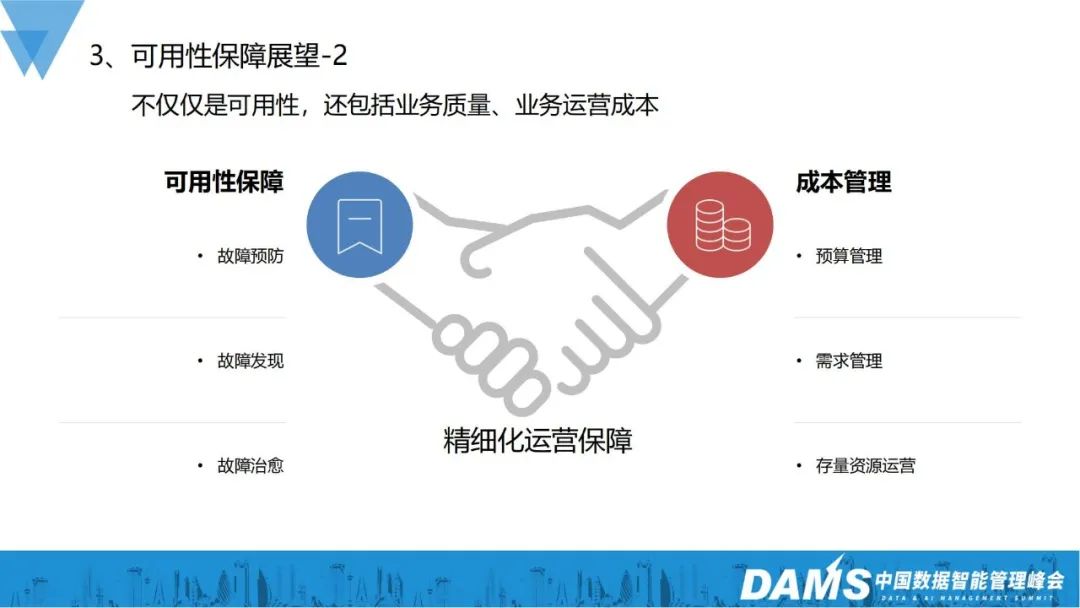
Q&A
Q1: ユーザビリティ構築の実装中に遭遇する最大の困難は何ですか?
A1: 1点目は、その基礎となる技術力の構築仕様であり、この仕様を遵守できない場合、ビジネスの可用性結果に大きな不確実性が生じるため、一定のルールを策定する必要がある。
2 番目のポイントは、上層部からの承認です。各ビジネスにはさまざまな要求があります。段階が違えば安定性も異なりますが、ビジネス、評判、収益に影響しますし、上層部に認められるとユーザビリティ構築が推進しやすくなります。
Q2: CMDB を導入する際、開発担当者やホストなどの情報以外に、実際のプロセスではどのような情報を関連付けましたか?例えばミドルウェア情報に関係するものでしょうか?
A2: 現在、当社のシステムの多くはCMDBをベースとしており、運用保守システムだけでなく、多くのシステムがCMDBをベースに構築されており、ミドルウェアサービスもCMDBと統合される予定です。マイクロサービスのダボなどの関連付けの構築も、サービスの検出とガバナンスのために CMDB に基づいています。
講師紹介
Zhou Jiali は現在、vivo の運用および保守ディレクターとして、vivo のインターネット ビジネスの運用および保守を担当しています。 Baidu と Tencent で働いていたこの人物は、クライアント、国際化、ビッグデータ アルゴリズムなどのオフライン ビジネスの運用と保守の経験があります。 vivo 入社後はビジネス高可用性の構築を主導し、ビジネス可用性を 99.99% レベルまで向上させました。
以上がビジネスは急激に成長していますが、ユーザビリティの構築はそれほど安定しているでしょうか?の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。