
ホームページ >テクノロジー周辺機器 >AI >AI 業界への応用: データ ウィービングは AI アプリケーション トレーニングのブレークスルーを支援します
AI 業界への応用: データ ウィービングは AI アプリケーション トレーニングのブレークスルーを支援します

- PHPz転載
- 2023-06-08 11:38:451274ブラウズ
#この記事は、Everyone is a Product Manager の「オリジナル インセンティブ プラン」によって作成されました。
大規模な AI モデルは現在非常に人気があり、あらゆる企業がその一部を望んでいますが、このプロセスの実現に必要なアルゴリズムとデータを把握するのは簡単ではありません。中でもデータの送信と管理は大きな問題です。この記事では、AI アプリケーションのトレーニングのボトルネックに焦点を当て、AI トレーニングの難しさをまとめ、IDC 分析レポートと組み合わせて、「データ」が最大のボトルネックであると結論付け、この問題の解決策を検討します。

1. 製品の背景
「最近、再びAIについて議論する声が上がっています。ここ2年間のAIに対する様子見姿勢とは異なり、ChatGPTの応用で本格的にAI時代が到来したと言う人も多く、製品と運用の学生は忙しいです 私たちは ChatGPT が何であるか、安定拡散が何であるかなどを理解していますが、アルゴリズム エンジニアは頭がおかしくなり、狂ったように不平を言っています リーダーたちは彼らに、できるだけ早く大規模なモデルを構築し、アルゴリズム モデルの指標をできるだけ早く作成し、ビジネスに役立てるアルゴリズム チームの前を通りかかったとき、Zhang Gong と Hu の作業員の次のような会話が聞こえました。
Gong Zhang: 胡兄弟、モデルのトレーニングはどうですか?Hu Gong: ああ、一言で説明するのは難しいです。データがありません。最終的に事業部門にデータを提出しましたが、データが収集できなかったか、収集したデータがすべて異なっていて収集できませんでした。使われないの?
Zhang Gong: そうではないのは誰ですか? 私も同じです。最近、お客様の写真とビデオが合計 10 T を超えました。私たちはそれらを自分たちで送信するように求められました。私たちのチームは、データをインポートするだけで長い時間がかかりました。データ。
Hu Gong 氏は、データを迅速に取得して管理できるデータ プラットフォームを会社が構築できれば、日常業務でのデータの使用がさらに便利になると述べました。 「
上記の話を聞いて、私は最近、データウィービングの考え方に基づいて顧客向けに構築したデータ管理プラットフォームが顧客の課題を解決できると思い、すぐに詳細な製品紹介をして顧客に伝えました。 「データ ウィービング」の設計コンセプトは、ユーザーが AI アプリケーションのトレーニングにおけるデータのボトルネックを突破できるようにするデータ管理プラットフォームを構築します。
2. AI トレーニング アプリケーションの難しさ
AI活用研修の客観的な難しさを人事の主観的な問題を除いてまとめると、以下の3点に集約されます。

アルゴリズムのトレーニングで良い結果を達成するには、高品質なデータが第一条件ですが、高品質なデータを取得する方法には次のような困難があります。 データの多様性: さまざまな形式の構造化/非構造化データがあり、さまざまなシステムから提供されるデータには統一された標準がありません。
- データ分散: 多くのビジネス データは個別に保存されており、統合されたデータ管理プラットフォームが不足しているため、アプリケーションのトレーニング前にデータを取得するのは困難です。
- データ アノテーション: データは即座に取得できますが、適用する前に大量のビジネス データにアノテーションを付ける必要があり、アノテーションには時間と労力がかかります。
- 効率的な計算能力:
いつの時代でも、大規模なモデルが徐々に推進され、モデルのサイズはますます大きくなり、コンピューティング能力の需要も急速に増加しています。
データ ストレージが離散的であると、データへのアクセスが遅くなり、クラスターのコンピューティング能力があっても、並列処理が不可能な場合、コンピューティング能力は効率的に適用されません。- 成熟したフレームワーク: は、成熟した、安定した、拡張性の高いアルゴリズム フレームワークを必要とするアルゴリズム アプリケーションを指します
アプリケーション フレームワーク: 現在、国内外で多くの深層学習アルゴリズム フレームワークが存在しており、アルゴリズム研究 (Pytorch) と産業アプリケーション (Tensorflow) では、異なるフレームワークを選択する必要があります。
データ変換: 使用されるフレームワークや言語が異なるため、高品質のデータが用意されたとしても、異なる言語やトレーニング フレームワークに迅速に適応させる必要があります。- 要約: AI アプリケーション トレーニングの 3 つの困難を分析すると、それらはすべてデータに関連しているため、データの問題を解決できれば、AI アプリケーション トレーニングが困難を突破するのに効果的に役立ちます。ボトルネック。
3. AI アプリケーションのボトルネックはデータですか? AIアプリケーション学習のボトルネックはアプリケーション側からのデータ集約ですが、そう思っているユーザーはどれくらいいるでしょうか?説明するにはデータが必要です。
人工知能アプリケーションにおける主な課題のランキング

人工知能モデルの開発中のデータ準備にどれだけの労力が費やされるか
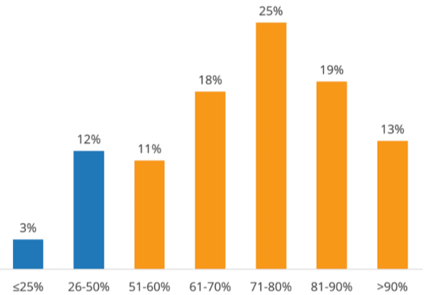
データは IDC 統計レポートから取得したものです
統計からわかるように、ユーザーの 29% は人工知能のアプリケーションにはトレーニング データとテスト データが不足していると考えており、ユーザーの 85% はワークロードの少なくとも半分がデータの準備に費やされていると考えています。 要約: データが AI アプリケーションのボトルネックであることが証明されているため、統一された標準と、可用性の高い大量のデータへの高速アクセスを提供するために、データからエントリ ポイントを探すことを検討できます。 ポジショニングを考慮した商品企画を実施します。
1. 製品アーキテクチャ
データウィービングの考え方に基づいたナレッジグラフ型のデータ管理プラットフォームを提供し、高品質なデータを必要とする顧客にサービスを提供します。 主な目的はAIアプリケーション学習におけるデータボトルネックの解決ですが、商品企画の観点からユーザーシナリオを拡大し、データサービスを必要とするあらゆるユーザーを対象としています。この商品の。
データ層から製品アプリケーション層まで、次の製品アーキテクチャを設計します:
ストレージ層: データの離散的な性質を考慮すると、さまざまな場所でのデータの保存をサポートし、クラウド データからローカル データへのアクセスをサポートする必要があります。 データ管理プラットフォーム: 今回設計するコア製品は主に 4 つの部分で構成されます。
イラスト: Tianyancha のスクリーンショットは学習の参考のみを目的としています 2.商品化 製品は発売されたら商品化できないため、商品企画段階で商品化の方向性を明確に検討する必要があり、次の 3 つの点を考慮する必要があります。
1) コンテンツの販売
2) 販売方法
3) 差別化の利点
データウィービングとナレッジグラフの概念に基づいて製品変革設計を実行し、「データ発見」のためのインテリジェントなデータ管理プラットフォームを製品のポジショニング、製品アーキテクチャ、アプリケーションシナリオなどの観点から詳細に紹介します。ビジネス推進のアイデアと構築パスは、AI トレーニング プラットフォーム、データ アノテーション プラットフォームなどのデータ アプリケーション シナリオ、さらには従来のデータ管理の変革とアップグレードが必要な顧客を支援します。製品。 将来的には、モデルの並列トレーニングの実際のプロセスにデータを組み込むことを拡張して、データ効率のさらなる実現可能性を追求するというアイデアをさらに検討していきます。 Eric_d、誰もがプロダクト マネージャーのコラムニストです。 AI、ビッグデータ、その他の分野に情熱を持っており、要件分析、製品プロセス、アーキテクチャ設計の優れたスキルを持っています。また、ハイキングも好きです。 この記事は、みんながプロダクトマネージャーの「オリジナルインセンティブプラン」によって作成されました。 タイトル画像は、CC0 契約に基づいて Unsplash から提供されたものです。 質問 1:
質問 1:
 データ レイヤー: 構造化データと非構造化データだけでなく、さまざまな種類のデータへのアクセスをサポート AI トレーニング、特に複数の種類のデータを必要とするマルチモーダル アプリケーションには多くの種類のデータがあります。
データ レイヤー: 構造化データと非構造化データだけでなく、さまざまな種類のデータへのアクセスをサポート AI トレーニング、特に複数の種類のデータを必要とするマルチモーダル アプリケーションには多くの種類のデータがあります。
注:
標準製品: データ管理プラットフォームを持たないユーザーの場合、標準製品を購入し、データにアクセスし、ビジネスに適用するだけで、すぐに使用できるようになります。
チャネル連携: 都道府県や市区町村のエージェントが現地で推進するチャネル連携と、ISVモデルで技術力のある集中エージェントを見つけ、データ管理プラットフォームと自社製品を統合するチャネル連携の2種類を選択お互いの利点を補完し、それを外部に宣伝することができます。
データ ウィービング: この製品は、データ管理にデータ ウィービングのアイデアを採用し、データ仮想化ストレージを使用してデータの物理ストレージ コストを削減すると同時に、データ キャッシュを使用してデータ取得のアクセス遅延を削減します。 AIアプリケーションのトレーニング中。
製品の成熟には継続的な構築パスも必要です この製品の構築プロセスでは、「プロジェクト磨き製品」に基づいて、大きく 2 つの段階で構築されます。 プロジェクトの実施、技術の析出: 1/2 民営化データプロジェクトを実施することにより、データの織り込みとナレッジグラフ構築のアイデアがプロジェクトに析出し、技術の析出が達成されます。
以上がAI 業界への応用: データ ウィービングは AI アプリケーション トレーニングのブレークスルーを支援しますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。