
ホームページ >テクノロジー周辺機器 >AI >330 億もの大規模なパラメータ モデルを単一のコンシューマ グレード GPU に「投入」し、パフォーマンスを犠牲にすることなく 15% 高速化
330 億もの大規模なパラメータ モデルを単一のコンシューマ グレード GPU に「投入」し、パフォーマンスを犠牲にすることなく 15% 高速化

- PHPz転載
- 2023-06-07 22:33:211382ブラウズ
特定のタスクにおける事前トレーニングされた大規模言語モデル (LLM) のパフォーマンスは向上し続けています。その後、プロンプトの指示が適切であれば、より多くのタスクに汎用化することができます。多くの人がこの現象が原因であると考えられています。ただし、最近の傾向では、研究者はより小規模なモデルに注目しているものの、これらのモデルはより多くのデータでトレーニングされるため、推論が容易になります。
たとえば、パラメーター サイズ 7B の LLaMA は 1T トークンでトレーニングされました。平均パフォーマンスは GPT-3 よりわずかに低いものの、パラメーター サイズは GPT-3 の 1/25 です。 。それだけでなく、現在の圧縮テクノロジはこれらのモデルをさらに圧縮することができ、パフォーマンスを維持しながらメモリ要件を大幅に削減できます。このような改善により、優れたパフォーマンスのモデルをラップトップなどのエンドユーザー デバイスに展開できるようになります。
ただし、これは別の課題に直面しています。それは、生成品質を考慮しながら、これらのモデルをデバイスに適合するのに十分小さなサイズに圧縮する方法です。調査によると、圧縮モデルは許容可能な精度で応答を生成しますが、既存の 3 ~ 4 ビット量子化技術では依然として精度が低下します。 LLM の生成は順番に実行され、以前に生成されたトークンに依存するため、小さな相対エラーが蓄積し、深刻な出力の破損につながります。信頼性の高い品質を確保するには、16 ビット モデルと比較して予測パフォーマンスを低下させない、低ビット幅の量子化方法を設計することが重要です。
ただし、各パラメータを 3 ~ 4 ビットに量子化すると、多くの場合、中程度または高精度の損失が発生します。特に、エッジ展開に適した 1 ~ 10B の精度は、パラメータ範囲内のより小さいモデルに適しています。
精度の問題を解決するために、ワシントン大学、チューリッヒ工科大学、その他の機関の研究者は、新しい圧縮形式と量子化技術 SpQR (Sparse-Quantized Representation、スパース - 定量化) を提案しました。表現)、以前の方法と同様の圧縮レベルを達成しながら、モデル スケール全体での LLM のほぼ可逆圧縮を初めて達成しました。
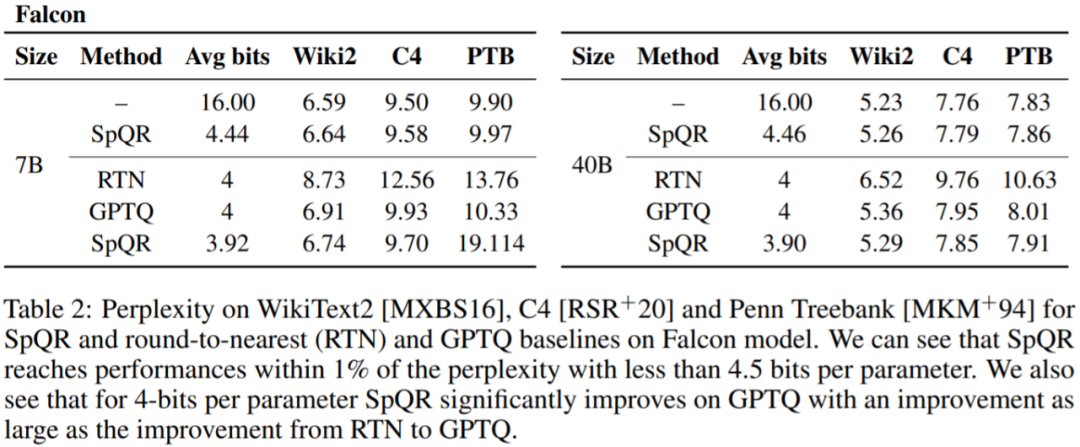
SpQR は、特に大きな量子化エラーを引き起こす異常な重みを特定して分離し、他のすべての重みを圧縮しながら、それらをより高精度で保存することによって機能します。 LLaMA および Falcon LLM では精度の低下が発生します。これにより、33B パラメータの LLM を 15% 高速化しながら、パフォーマンスを低下させることなく単一の 24GB コンシューマ GPU で実行できるようになります。
SpQR アルゴリズムは効率的で、重みを他の形式にエンコードしたり、実行時に効率的にデコードしたりできます。具体的には、この研究は、4 倍を超えるメモリ圧縮ゲインを達成しながら、16 ビットのベースライン モデルよりも高速に推論を実行できる効率的な GPU 推論アルゴリズムを SpQR に提供します。

- #論文アドレス: https://arxiv.org/pdf/2306.03078.pdf
- #プロジェクトアドレス: https://github.com/Vahe1994/SpQR メソッド
具体的には、この研究ではプロセス全体を 2 つのステップに分割しました。最初のステップは外れ値の検出です。この研究では、まず外れ値の重みを分離し、その量子化が高い誤差につながることを実証しています。外れ値の重みは高精度で維持されますが、他の重みは低精度で (たとえば 3 ビット形式で) 保存されます。次に、この研究では、非常に小さなグループ サイズでグループ化された量子化の変形を実装し、量子化スケール自体を 3 ビット表現に量子化できることを示しました。
SpQR は、精度を犠牲にすることなく LLM のメモリ フットプリントを大幅に削減し、16 ビット推論と比較して LLM を 20% ~ 30% 高速に生成します。
さらに、この研究では、重み行列内の敏感な重みの位置がランダムではなく、特定の構造を持っていることがわかりました。定量化中にその構造を強調するために、研究では各重量の感度を計算し、LLaMA-65B モデルのこれらの重量感度を視覚化しました。以下の図 2 は、LLaMA-65B の最後のセルフ アテンション層の出力投影を示しています。 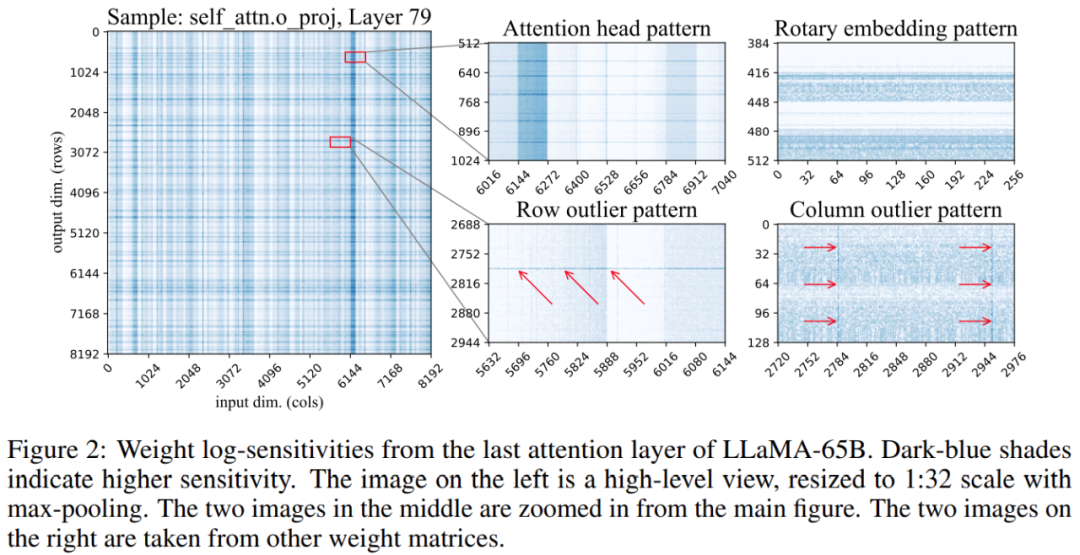
この研究では、定量化プロセスに 2 つの変更を加えました: 1 つは小さな敏感な重みグループをキャプチャするため、もう 1 つは個々の外れ値をキャプチャするために使用されます。以下の図 3 は、SpQR の全体的なアーキテクチャを示しています:
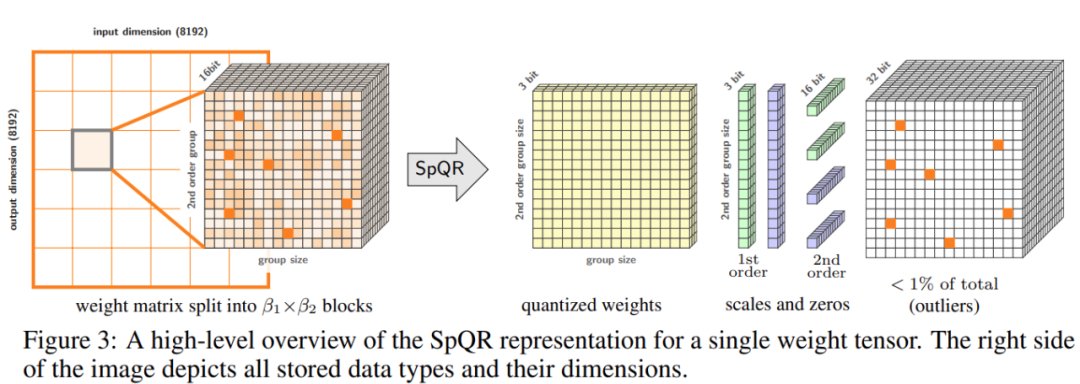
次の表は、SpQR 定量化アルゴリズムを示しています。左側はプロセス全体を説明し、右側のコード スニペットには二次定量化と外れ値の検出のためのサブルーチンが含まれています:

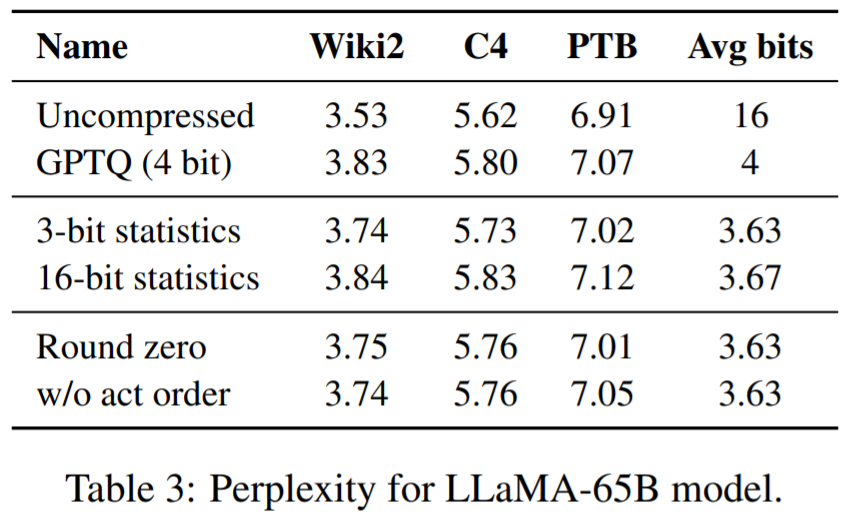
この研究では、SpQR を他の 2 つの量子化スキーム、GPTQ、RTN (最近似への丸め) と比較し、2 つのメトリクスを使用して量子化モデルのパフォーマンスを評価します。 1 つ目は、WikiText2、Penn Treebank、C4 などのデータセットを使用したパープレキシティの測定で、2 つ目は、WinoGrande、PiQA、HellaSwag、ARC-easy、ARC-challenge の 5 つのタスクにおけるゼロサンプル精度です。
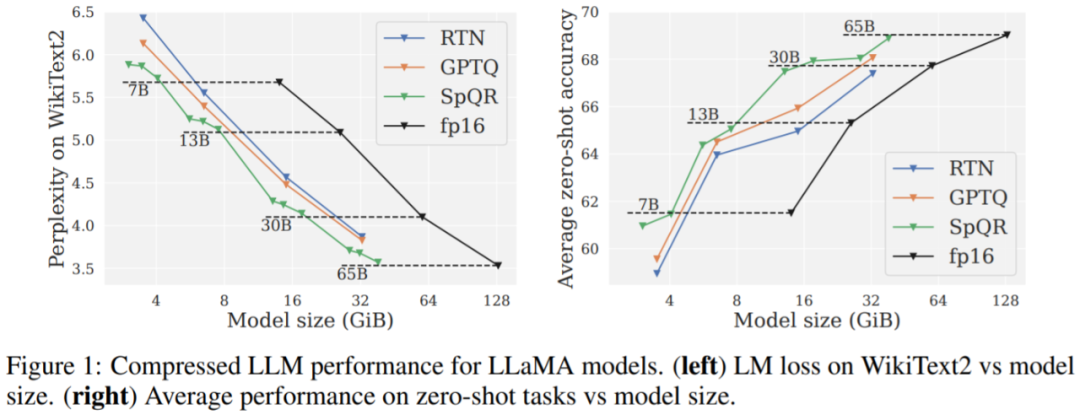
主な結果。図 1 の結果は、同様のモデル サイズで、特に小規模なモデルで、SpQR が GPTQ (および対応する RTN) よりも大幅に優れたパフォーマンスを発揮することを示しています。この改善は、SpQR が損失の劣化を軽減しながら、より多くの圧縮を達成したことによるものです。
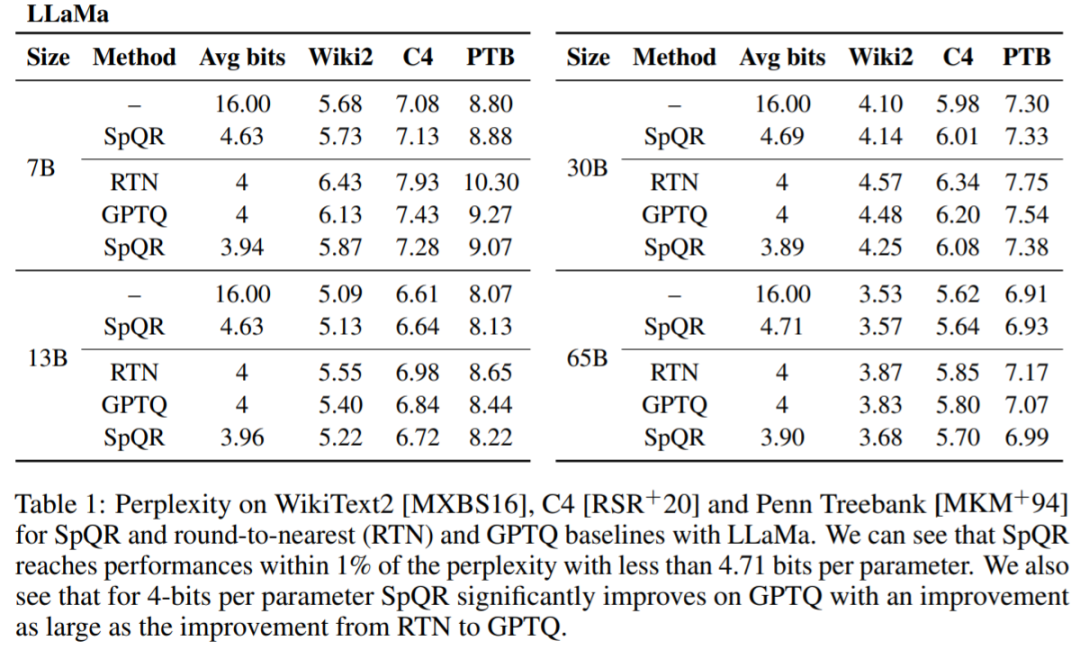
#表 1、表 2 結果は、4 ビット量子化の場合、16 ビット ベースラインに対する SpQR の誤差が半分になることを示しています。 GPTQに。

以上が330 億もの大規模なパラメータ モデルを単一のコンシューマ グレード GPU に「投入」し、パフォーマンスを犠牲にすることなく 15% 高速化の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。