
ホームページ >テクノロジー周辺機器 >AI >OpenAIが上位2位を独占!大規模モデルのコード生成ランキング リストが公開され、70 億 LLaMA がそれを上回り、2 億 5,000 万の Codex に敗れました。
OpenAIが上位2位を独占!大規模モデルのコード生成ランキング リストが公開され、70 億 LLaMA がそれを上回り、2 億 5,000 万の Codex に敗れました。

- 王林転載
- 2023-06-07 19:37:44724ブラウズ
最近、Matthias Prappert 氏のツイートが LLM サークル内で広範な議論を引き起こしました。
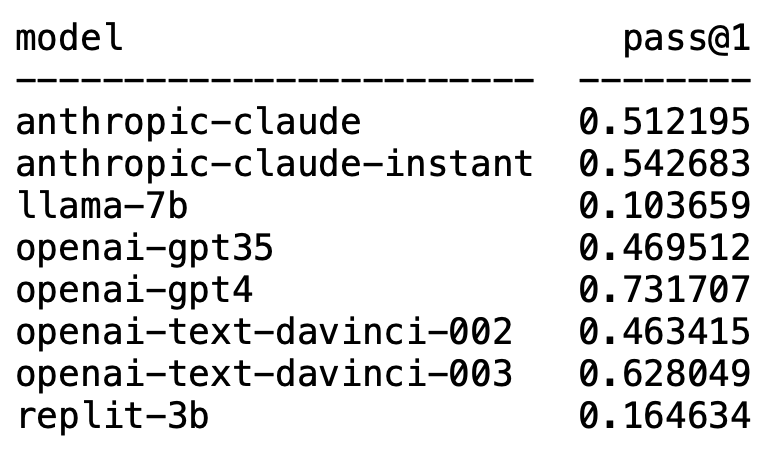
Plappert は著名なコンピューター科学者であり、AI 界隈で主流の LLM に関するベンチマーク テストの結果を HumanEval で公開しました。 。
彼のテストはコード生成に偏っています。
結果は衝撃的で衝撃的でもあります。

予想外なことに、GPT-4 は間違いなくリストを独占し、1 位になりました。
意外なことに、OpenAI の text-davinci-003 が突然浮上し、2 位になりました。
Plappert 氏は、text-davinci-003 は「宝」モデルと呼ぶことができると述べました。
おなじみの LLaMA はコード生成が苦手です。
OpenAI がリストを独占
Plappert 氏は、GPT-4 のパフォーマンスは文献データよりもさらに優れていると述べました。
論文にある GPT-4 ラウンドのテスト データの合格率は 67% ですが、Prappert のテストは 73% に達しました。

原因を分析すると、データに不一致が生じる可能性が多くあるとのこと。その 1 つは、彼が GPT-4 に与えたプロンプトが、論文の著者が GPT-4 をテストしたときよりもわずかに優れていたことです。
もう 1 つの理由は、論文が GPT-4 をテストしたときにモデルの温度が 0 ではないと推測したことです。
「温度」は、モデルによって生成されるテキストの創造性と多様性を調整するために使用されるパラメーターです。 「温度」は 0 より大きい値で、通常は 0 ~ 1 の間です。モデルがテキストを生成するときに、サンプリングされた予測単語の確率分布に影響します。
モデルの「温度」が高い場合 (0.8、1 以上など)、モデルはより多様で異なる単語から選択する傾向が高くなります。生成されたテキストはリスクが高く、より創造的ですが、より多くのエラーや矛盾が生じる可能性もあります。
「温度」が低い場合 (0.2、0.3 など)、モデルは主に確率の高い単語から選択するため、より滑らかで一貫性のあるテキストが生成されます。
ただし、この時点では、生成されたテキストは保守的で繰り返しが多すぎるように見えるかもしれません。
したがって、実際のアプリケーションでは、特定のニーズに基づいて適切な「温度」値を比較検討して選択する必要があります。
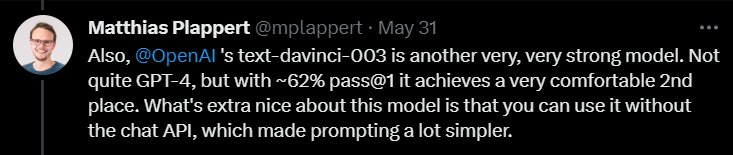
次に、text-davinci-003 についてコメントしたときに、Prappert 氏は、これも OpenAI の下で非常に有能なモデルであると述べました。
GPT-4 ほどではありませんが、1 回のテストで 62% の合格率を達成すれば、それでも確実に 2 位を獲得できます。
Plappert 氏は、text-davinci-003 の最も優れた点は、ユーザーが ChatGPT の API を使用する必要がないことであると強調しました。これは、プロンプトの表示がより簡単になることを意味します。
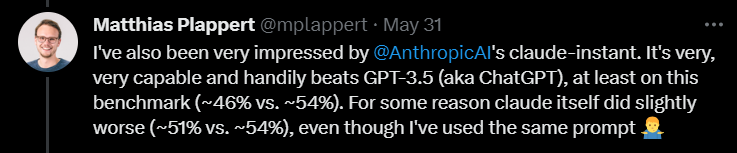
さらに、プラパート氏は、Anthropic AI のクロードインスタント モデルにも比較的高い評価を与えました。
彼は、このモデルのパフォーマンスは優れており、GPT-3.5 を上回ることができると信じています。 GPT-3.5 の合格率は 46% ですが、claude-instant の合格率は 54% です。
もちろん、Anthropic AI のもう 1 つの LLM、claude は、claude-instant ではプレイできず、合格率はわずか 51% です。
Plappert 氏は、2 つのモデルのテストに使用されたプロンプトは同じであると述べました。
これらのよく知られたモデルに加えて、Prappert は多くのオープンソースの小規模モデルもテストしました。
Plappert 氏は、これらのモデルをローカルで実行できるのは良いことだと言いました。
ただし、規模の点で、これらのモデルは明らかに OpenAI や Anthropic AI ほど大きくないため、比較するのは少々圧倒されます。

LLaMA コード生成?腰を引っ張る
# もちろん、プラパート氏は LLaMA テストの結果に満足していませんでした。
テスト結果から判断すると、LLaMA はコード生成のパフォーマンスが非常に悪かったです。おそらく、GitHub からデータを収集するときにアンダーサンプリングを使用したためです。
Codex 2.5B と比較しても、LLaMA のパフォーマンスは同じではありません。 (合格率 10% 対 22%)

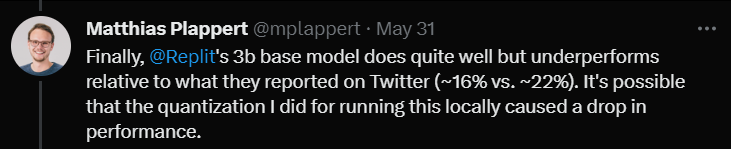
最後に、Replit の 3B サイズ モデルをテストしました。
パフォーマンスは悪くなかったが、Twitter で宣伝されたデータと比較すると (合格率 16% 対 22%)
Plappert 氏は、これはモデルをテストするときに使用した定量化手法によって合格率が数パーセント低下したためではないかと考えています。
レビューの最後で、プラパート氏は非常に興味深い点について言及しました。
あるユーザーが Twitter で、Azure プラットフォームの Completion API (Chat API ではなく) を使用すると GPT-3.5-turbo のパフォーマンスが向上することを発見しました。
Plappert 氏は、Chat API を介してプロンプトを入力するのは非常に複雑な場合があるため、この現象にはある程度の正当性があると考えています。

以上がOpenAIが上位2位を独占!大規模モデルのコード生成ランキング リストが公開され、70 億 LLaMA がそれを上回り、2 億 5,000 万の Codex に敗れました。の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。