



私たちはよく「行動する前によく考えて」、蓄積された経験を最大限に活用するように教えられますが、この言葉は AI にもインスピレーションを与えました。
従来の意思決定AIモデルは、忘却効果の存在により効果的に経験を蓄積することができませんでしたが、中国主導の研究によりAIの記憶方法が変わりました。
新しい記憶方法は人間の脳を模倣し、AI の経験蓄積効率を効果的に向上させ、それによって AI のゲーム パフォーマンスを 29.9% 向上させます。
研究チームは、ミラ ケベック AI 研究所とマイクロソフト モントリオール研究所のそれぞれ 6 名で構成されており、そのうち 4 名は中国人です。
彼らは、その結果をメモリ付き意思決定変換器 (DT-Mem) と名付けました。
従来の意思決定モデルと比較して、DT-Mem は適用範囲が広く、モデル運用の効率も高くなります。
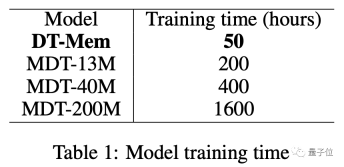
アプリケーションの効果に加えて、DT-Mem のトレーニング時間も最小 200 時間から 50 時間に短縮されました。
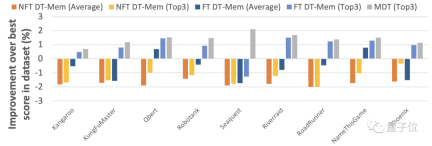
同時に、チームは、DT-Mem がトレーニングされていない新しいシナリオに適応できるようにする微調整方法も提案しました。
微調整されたモデルは、これまで学習していないゲームでも優れたパフォーマンスを発揮します。
動作メカニズムは人間からインスピレーションを得ています
従来の意思決定モデルは LLM に基づいて設計されており、暗黙的メモリを使用しており、そのパフォーマンスはデータと計算に依存します。
暗黙記憶は意図的に記憶されるのではなく無意識に生成されるため、意識的に思い出すことはできません。
もっと簡単に言うと、関連するコンテンツは明らかにそこに保存されていますが、モデルはその存在を知りません。
この暗黙記憶の特性が従来のモデルにおける忘却現象を決定づけ、作業効率の低下につながります。
忘却現象は、問題を解決するための新しい方法を学習した後、古い問題と新しい問題が同じタイプであっても、モデルが古い内容を忘れてしまう可能性があるという点で現れます。
人間の脳は 分散記憶ストレージ 方式を採用しており、記憶内容は脳の複数の異なる領域に分散して保存されます。
このアプローチは、複数のスキルを効果的に管理および整理するのに役立ち、それによって忘れる現象を軽減します。
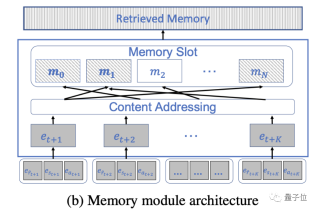
これに触発されて、研究チームは、さまざまな下流タスクのための情報を保存、混合、取得するための内部作業記憶モジュールを提案しました。
具体的には、DT-Mem は、トランスフォーマー、メモリ モジュール、および多層認識 (MLP) モジュールの 3 つの部分で構成されます。

DT-Mem の Transformer は GPT-2 のアーキテクチャを模倣していますが、アテンション メカニズムの後のフィードフォワード層を削除しています。
同時に、GPT-2 の MLP モジュールは DT-Mem の一部として独立したコンポーネントに分割されます。
この 2 つの中間として、研究チームは中間情報を保存および処理するための作業記憶モジュールを導入しました。
この構造は、メモリを使用してさまざまなアルゴリズムを推論するニューラル チューリング マシンからインスピレーションを得ています。
メモリ モジュールは、Transformer によって出力された情報を分析し、その保存場所と、それを既存の情報と統合する方法を決定します。
さらに、このモジュールでは、この情報が将来の意思決定プロセスでどのように使用されるかについても検討します。


結果として、DT-Mem の 4 試合の最高成績はすべて MDT よりも優れていました。
具体的には、DT-Mem は MDT と比較して DQN 正規化スコアを 29.9% 改善します。
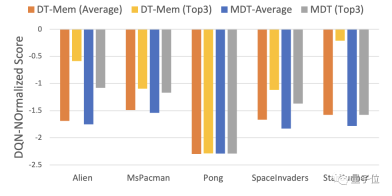
ただし、DT-Mem のパラメータ量は 20M に過ぎず、MDT (200M パラメータ) の 10% に過ぎません。
これほどのパフォーマンスは大したものと言っても過言ではありません。
DT-Mem は、優れたパフォーマンスに加えて、トレーニング効率も MDT を上回ります。
MDT の 13M パラメータ バージョンのトレーニングには 200 時間かかりますが、20M DT-Mem のトレーニングには 50 時間しかかかりません。
200M バージョンと比較すると、トレーニング時間は 32 倍短縮されますが、パフォーマンスはさらに優れています。
#チームが提案した微調整方法のテスト結果は、この微調整により DT-Mem の適応能力が向上することも示しています。未知のシナリオ。
以下の表のテストに使用されたゲームは MDT に知られているため、MDT のパフォーマンスはこのラウンドの測定の基礎として使用されないことに注意してください。
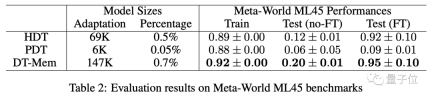
チームは、ゲームのプレイに加えて、Meta-World ML45 ベンチマークを使用して DT-Mem のテストも行いました。
今回参考にしたのはH[yper]DTとP[romot]DTです。
結果は、微調整を行わないモデルでは、DT-Mem スコアが HDT より 8 パーセント ポイント高いことを示しています。
ここでテストした HDT には 69K のパラメータしかありませんが、230 万のパラメータを持つ事前トレーニング済みモデルに依存しているため、実際のパラメータ数は DT-Mem の 10 倍以上であることに注意してください ( 147K).倍。
紙のアドレス: https://arxiv.org/ abs/2305.16338
以上がAIが人間の脳の記憶モデルを模倣し、ゲームスコアが29.9%急上昇の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 1つのプロンプトは、すべての主要なLLMのセーフガードをバイパスできますApr 25, 2025 am 11:16 AM
1つのプロンプトは、すべての主要なLLMのセーフガードをバイパスできますApr 25, 2025 am 11:16 AMHiddenLayerの画期的な研究は、主要な大規模な言語モデル(LLMS)における重大な脆弱性を明らかにしています。 彼らの発見は、ほぼすべての主要なLLMSを回避できる「政策の人形劇」と呼ばれる普遍的なバイパス技術を明らかにしています
 5つの間違いほとんどの企業が今年持続可能性を備えていますApr 25, 2025 am 11:15 AM
5つの間違いほとんどの企業が今年持続可能性を備えていますApr 25, 2025 am 11:15 AM環境責任と廃棄物の削減の推進は、企業の運営方法を根本的に変えています。 この変革は、製品開発、製造プロセス、顧客関係、パートナーの選択、および新しいものの採用に影響します
 H20チップバンジョルツチャイナ企業ですが、彼らはインパクトのために長い間支えられてきましたApr 25, 2025 am 11:12 AM
H20チップバンジョルツチャイナ企業ですが、彼らはインパクトのために長い間支えられてきましたApr 25, 2025 am 11:12 AM高度なAIハードウェアに関する最近の制限は、AI優位のためのエスカレートする地政学的競争を強調し、中国の外国半導体技術への依存を明らかにしています。 2024年、中国は3,850億ドル相当の半導体を大量に輸入しました
 OpenaiがChromeを購入すると、AIはブラウザ戦争を支配する場合がありますApr 25, 2025 am 11:11 AM
OpenaiがChromeを購入すると、AIはブラウザ戦争を支配する場合がありますApr 25, 2025 am 11:11 AMGoogleからのChromeの強制的な売却の可能性は、ハイテク業界での激しい議論に火をつけました。 Openaiが65%の世界市場シェアを誇る大手ブラウザを取得する見込みは、THの将来について重要な疑問を提起します
 AIが小売メディアの成長する痛みをどのように解決できるかApr 25, 2025 am 11:10 AM
AIが小売メディアの成長する痛みをどのように解決できるかApr 25, 2025 am 11:10 AM全体的な広告の成長を上回っているにもかかわらず、小売メディアの成長は減速しています。 この成熟段階は、生態系の断片化、コストの上昇、測定の問題、統合の複雑さなど、課題を提示します。 ただし、人工知能
 「aiは私たちであり、それは私たち以上のものです」Apr 25, 2025 am 11:09 AM
「aiは私たちであり、それは私たち以上のものです」Apr 25, 2025 am 11:09 AM古いラジオは、ちらつきと不活性なスクリーンのコレクションの中で静的なパチパチと鳴ります。簡単に不安定になっているこの不安定な電子機器の山は、没入型展示会の6つのインスタレーションの1つである「e-waste land」の核心を形成しています。
 Google Cloudは、次の2025年にインフラストラクチャについてより深刻になりますApr 25, 2025 am 11:08 AM
Google Cloudは、次の2025年にインフラストラクチャについてより深刻になりますApr 25, 2025 am 11:08 AMGoogle Cloudの次の2025年:インフラストラクチャ、接続性、およびAIに焦点を当てています Google Cloudの次の2025年の会議では、多くの進歩を紹介しました。 特定の発表の詳細な分析については、私の記事を参照してください
 Baby Ai Meme、Arcanaの550万ドルのAI映画パイプライン、IRの秘密の支援者が明らかにした話Apr 25, 2025 am 11:07 AM
Baby Ai Meme、Arcanaの550万ドルのAI映画パイプライン、IRの秘密の支援者が明らかにした話Apr 25, 2025 am 11:07 AM今週はAIとXR:AIを搭載した創造性の波が、音楽の世代から映画制作まで、メディアとエンターテイメントを席巻しています。 見出しに飛び込みましょう。 AIに生成されたコンテンツの影響力の高まり:テクノロジーコンサルタントのShelly Palme


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

Safe Exam Browser
Safe Exam Browser は、オンライン試験を安全に受験するための安全なブラウザ環境です。このソフトウェアは、あらゆるコンピュータを安全なワークステーションに変えます。あらゆるユーティリティへのアクセスを制御し、学生が無許可のリソースを使用するのを防ぎます。

SublimeText3 Mac版
神レベルのコード編集ソフト(SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

VSCode Windows 64 ビットのダウンロード
Microsoft によって発売された無料で強力な IDE エディター
ホットトピック
 7716
7716 15164114139552128925123229
15164114139552128925123229