
ホームページ >テクノロジー周辺機器 >AI >OlaGPT、人間の認知をシミュレートする初の思考フレームワーク: 6 つのモジュールが言語モデルを強化し、推論能力を最大 85% 向上させます
OlaGPT、人間の認知をシミュレートする初の思考フレームワーク: 6 つのモジュールが言語モデルを強化し、推論能力を最大 85% 向上させます

- 王林転載
- 2023-06-05 16:17:491485ブラウズ
ChatGPT が最初にリリースされたとき、私たちにあまりにも大きな衝撃を与えました。対話におけるモデルのパフォーマンスがあまりにも人間的で、言語モデルに「思考能力」があるかのような錯覚を引き起こしました。
しかし、研究者たちは、言語モデルを深く理解した後、確率の高い言語パターンに基づく再現は、期待される「一般的な人工知能」からはまだ遠いことに徐々に気づいてきました。
現在の研究のほとんどでは、大規模な言語モデルは主に、人間の認知フレームワークを考慮せずに、推論タスクを実行するための特定のプロンプトのガイダンスの下で思考連鎖を生成するため、言語モデルは複雑な推論問題を解決できません。人間とのギャップはまだまだ大きい。
人間は複雑な推論の問題に直面するとき、通常、さまざまな認知能力を使用し、ツール、知識、外部環境情報のあらゆる側面と対話する必要があります。言語モデルは人間の思考をシミュレートできますか?複雑な問題を解決するプロセスについてはどうですか? ?
答えはもちろんイエスです!人間の認知処理フレームワークをシミュレートする最初のモデル OlaGPT が登場しました。

ペーパーリンク: https://arxiv.org/abs/2305.16334
コードリンク: https://www.php.cn/link/ 73a1c863a54653d5e184b790fee14754
OlaGPT には、注意、記憶、推論、学習、対応するスケジューリングおよび意思決定メカニズムを含む複数の認知モジュールが含まれています。人間の能動学習からインスピレーションを得たこのフレームワークには、以前のエラーとエキスパートを記録する学習ユニットも含まれています。意見、および同様の問題を解決する能力を向上させるための動的な参照。
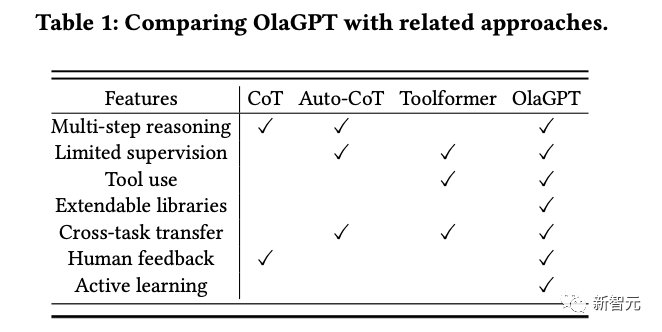
この記事では、人間が問題を解決するための一般的で効果的な推論フレームワークについても概説し、それに応じて思考連鎖 (CoT) テンプレートを設計し、包括的な意思決定も提案しています。モデルの精度を最大限に高める仕組みを作ります。
複数の推論データセットに対する厳密な評価の後に得られた実験結果は、OlaGPT が以前の最先端のベンチマークを上回り、その有効性を証明していることを示しています。
人間の認知のシミュレーション
現在の言語モデルと期待される一般的な人工知能の間には、まだ大きなギャップがあります。主な症状は次のとおりです:
1. 場合によっては、生成されたコンテンツは無意味であるか、人間の価値観の好みから逸脱しているか、または非常に危険な示唆を与えることさえあります。現在の解決策は、モデルの出力を分類するためにヒューマン フィードバックを使用した強化学習 (RLHF) を導入することです。
2. 言語モデルの知識は、トレーニング データで明示的に言及されている概念と事実に限定されます。
複雑な問題に直面したとき、言語モデルは変化する環境に適応したり、既存の知識やツールを使用したり、歴史的教訓を反映したり、問題を分解したり、人間と同じように長期的な進化の中で人間によって要約された知識を使用したりすることができません。問題を解決するための思考パターン (類推、帰納的推論、演繹的推論など)。
しかし、言語モデルが人間の脳の処理問題のプロセスをシミュレートできるようにするには、まだ多くのシステム上の問題があります:
1. 人間の認知フレームワークの主要モジュールを体系的に模倣してエンコードする方法人間の一般的な推論パターンに従ってスケジュールを設定する方法で実装できるようにしながら?
2. 人間のように積極的に学習するように、つまり歴史的な間違いや困難な問題に対する専門家による解決策から学習して発展させるように言語モデルを導くにはどうすればよいでしょうか?
モデルを再トレーニングして修正された回答をエンコードすることは可能かもしれませんが、明らかにコストがかかり、柔軟性に欠けます。
3. 人間が進化させたさまざまな思考モードを柔軟に利用して推論性能を向上させる言語モデルを作成するにはどうすればよいでしょうか?
固定された普遍的な思考モデルは、さまざまな問題に適応することが困難です。人間がさまざまな種類の問題に直面するときと同じように、通常、人間は類推論や演繹的推論など、さまざまな思考方法を柔軟に選択します。
OlaGPT
OlaGPT は、人間の思考をシミュレートし、大規模な言語モデルの機能を強化できる問題解決フレームワークです。
OlaGPT は、認知アーキテクチャ理論を利用し、注意、記憶、学習、推論、アクション、アクション選択などの認知フレームワークの中核機能をモデル化します。
研究者らは、特定の実装のニーズに応じてフレームワークを微調整し、複雑な問題を解決するための言語モデルに適したプロセスを提案しました。これには、具体的には、意図強化モジュール (注意)、記憶モジュール (メモリ) の 6 つのモジュールが含まれます。 )、アクティブラーニングモジュール(学習)、推論モジュール(推論)、コントローラーモジュール(アクション選択)、および投票モジュール。
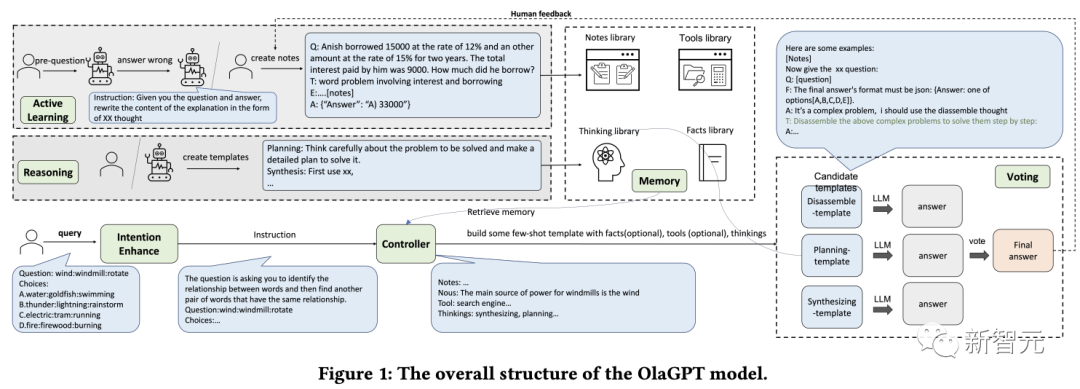
意図の強化
注意は人間の認知の重要な部分であり、関連する情報を識別し、無関係なデータを除外します。
同様に、研究者らは、言語モデルに対応する注意モジュール、つまりインテント強化を設計しました。これは、最も関連性の高い情報を抽出し、ユーザー入力とモデルの言語パターンの間のより強い相関関係を確立することを目的としています。ユーザーの表現習慣からモデルの表現習慣への最適化されたコンバーターとして。
まず、具体的なプロンプトワードを通じて LLM の質問タイプを事前に取得し、質問の方法を再構築します。

たとえば、分析を容易にするために、質問の冒頭に「それでは、XX (質問の種類)、質問、選択肢を教えてください:」という文を追加します。また、「答えは JSON 形式で終わる必要があります: 答え: オプション [A、B、C、D、E] のいずれか。」

#Memory(メモリ)
メモリ モジュールは、さまざまな知識ベース情報を保存する上で重要な役割を果たします。研究により、最新の事実データを理解する際の現在の言語モデルの限界が証明されており、メモリ モジュールは、内部化されていない知識を統合することに重点を置いていますモデルごとに取得し、長期記憶として外部ライブラリに保存します。
研究者らは、短期記憶には langchain の記憶機能を使用し、次に Faiss ベースのベクトル データベースを使用して長期記憶を実現しました。
クエリ プロセス中に、その検索機能はライブラリから関連する知識を抽出できます。これは、事実、ツール、メモ、思考という 4 つのタイプのメモリ ライブラリをカバーします。事実とは、常識、常識などの実世界の情報です。など; ツールには検索エンジン、計算機、Wikipedia が含まれており、言語モデルが編集を必要としない作業を完了するのに役立ちます; メモは主にいくつかの困難なケースと問題を解決するためのステップを記録します; 思考ライブラリには主に人間が書いた問題解決法が保存されています専門家 思考テンプレート。専門家は人間またはモデルになります。
学習
人間にとって学習能力は、自己パフォーマンスを継続的に向上させるために非常に重要です。本質的に、あらゆる形式の学習は経験に依存しており、言語モデルは以前の学習から学ぶことができます。間違いを克服して推論能力をすぐに向上させます。
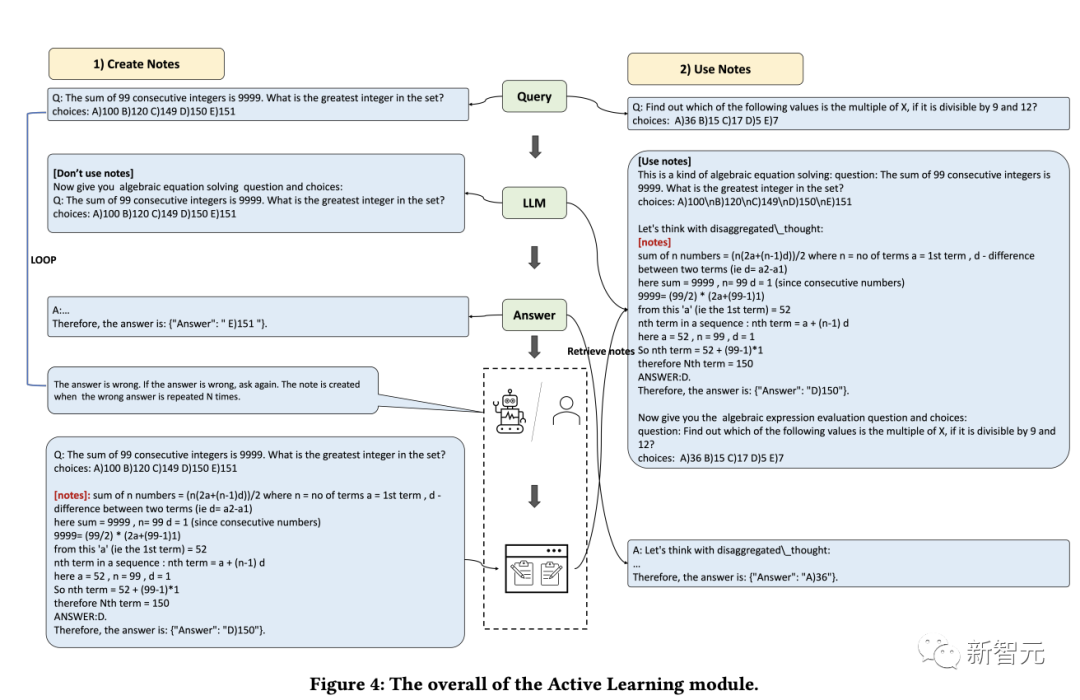
まず、研究者は言語モデルでは解決できない問題を特定し、次に専門家によって提供された洞察と説明をノート ライブラリに記録し、最後に言語を促進するために関連するノートを選択します。モデル学習により、同様の問題をより効果的に処理できるようになります。
推論
推論モジュールの目的は、人間の推論プロセスに基づいて複数のエージェントを作成し、それによって言語モデルの潜在的な思考能力を刺激し、推論の問題を解決することです。
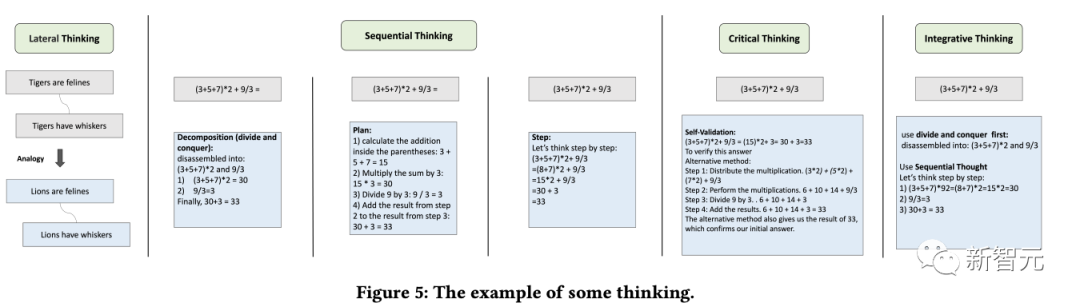
このモジュールでは、水平思考、逐次的思考、批判的思考、統合的思考などの特定の思考タイプを参照して複数の思考テンプレートを組み合わせて、推論タスクを促進します。
コントローラー
コントローラー モジュールは主に、モデルの内部計画タスク (実行する特定のモジュールの選択など) やファクトとツールの処理など、関連するアクションの選択を処理するために使用されます。 、メモ、思考バンクから選択します。
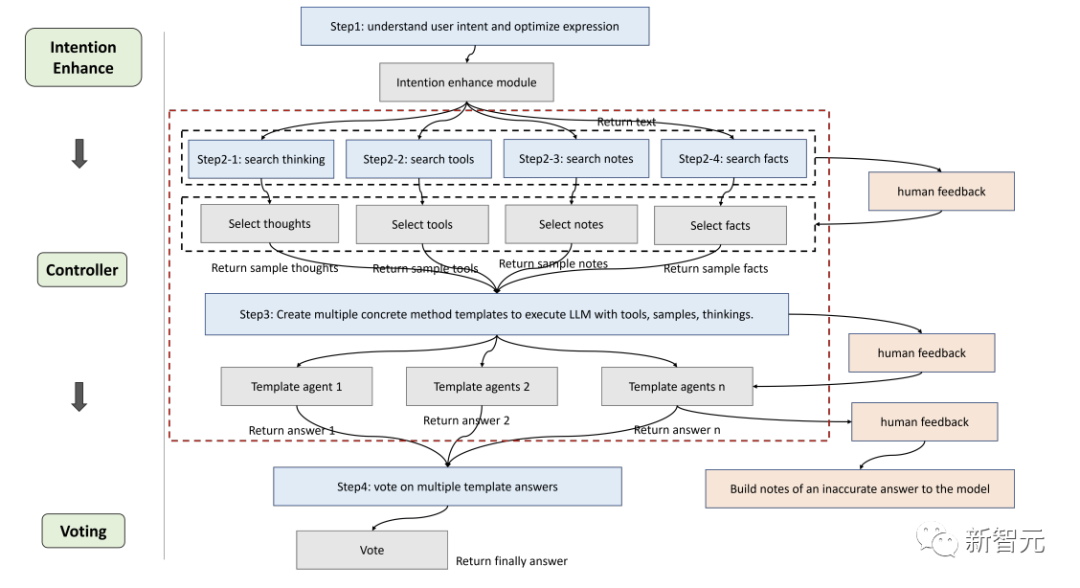
関連するライブラリが最初に取得されて照合されます。取得されたコンテンツは次にテンプレート エージェントに統合され、言語モデルがテンプレートに基づいて非同期で応答を提供する必要があります。人間が推論の開始時にすべての関連情報を特定するのが難しいのと同様に、言語モデルが最初からこれを行うことを期待することも同様に困難です。
そこで、上記 4 つのライブラリに対して、各ライブラリの検索戦略が若干異なる埋め込みインデックスを作成する Faiss 法を用いて、ユーザの質問と途中の推論の進行に基づいて動的検索を実装します。
投票
異なるタイプの問題には、異なる思考テンプレートがより適している可能性があるため、研究者は、複数の思考テンプレート間の統合調整機能を向上させ、より多くの投票戦略を作成できるように投票モジュールを設計しました。パフォーマンスを向上させるために最適な答えを生成します。
具体的な投票方法は次のとおりです:
1. 言語モデルの投票: 言語モデルをガイドして、指定された複数の選択肢の中から最も一貫した回答を選択し、その理由を説明します。
2. 正規表現投票: 正規表現の完全一致を使用して回答を抽出し、投票結果を取得します。
実験結果
推論タスクにおける強化された言語モデル フレームワークの有効性を評価するために、研究者らは 2 種類の推論データ セットに対して包括的な実験比較を実施しました。
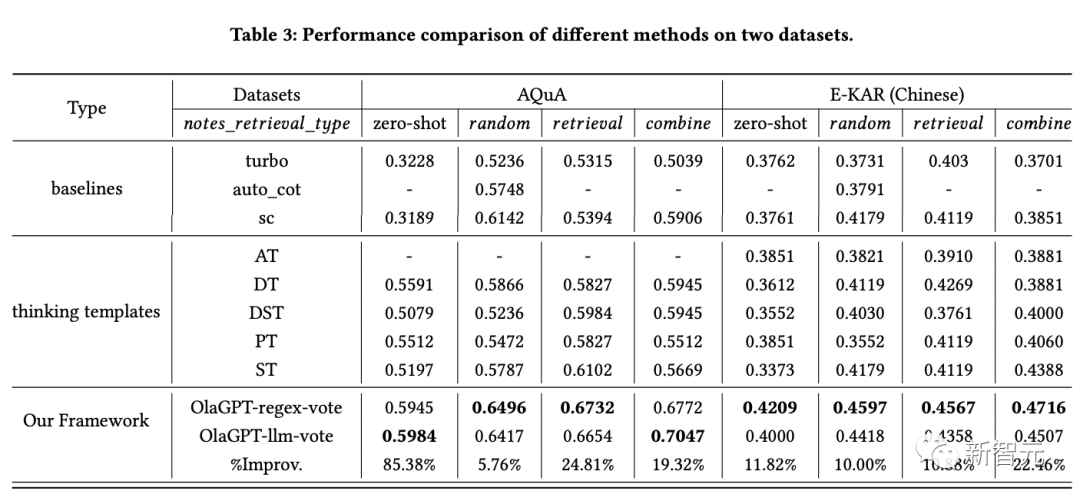
結果からわかります:
1. SC (自己一貫性) は GPT-3.5-turbo よりも優れたパフォーマンスを示し、統合がある程度の方法は、大規模モデルの有効性を向上させるのに非常に役立ちます。
2. 本記事で提案する手法の性能はSCを超えており、思考テンプレート戦略の有効性がある程度証明されています。
さまざまな思考テンプレートに対する回答には大きな違いがあり、さまざまな思考テンプレートに基づいて投票すると、単純に複数ラウンドの投票を行うよりも最終的にはより良い結果が得られます。
3. 思考テンプレートが異なれば効果も異なり、推論問題には段階的な解決策の方が適している場合があります。
4. アクティブ ラーニング モジュールのパフォーマンスは、ゼロサンプル法よりも大幅に優れています。
ノート ライブラリの一部として困難なケースを含め、ランダム、検索、および組み合わせリストを使用すると、パフォーマンスを向上させることができ、これは実現可能な戦略です。
5. 異なる取得スキームは異なるデータセットに異なる影響を及ぼします。一般に、組み合わせ戦略の方が良い結果が得られます。
6. この記事の方法は他のソリューションより明らかに優れています。これは、アクティブ ラーニング モジュールの効果的な設計を含むフレームワーク全体の合理的な設計によるものです。思考テンプレートは、さまざまなソリューションへの適応を実現します。モデルがあり、異なる思考テンプレートの下での結果は異なります。コントローラーモジュールは非常に優れた制御の役割を果たし、必要なコンテンツに一致するコンテンツを選択します。投票モジュールによって設計された異なる思考テンプレートの統合方法は効果的です。
参考資料:
https://www.php.cn/link/73a1c863a54653d5e184b790fee14754
以上がOlaGPT、人間の認知をシミュレートする初の思考フレームワーク: 6 つのモジュールが言語モデルを強化し、推論能力を最大 85% 向上させますの詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。