
ホームページ >テクノロジー周辺機器 >AI >中国科学チームが大型モデルの複雑な推論能力を総合的に評価する「思考連鎖コレクション」を開始
中国科学チームが大型モデルの複雑な推論能力を総合的に評価する「思考連鎖コレクション」を開始

- 王林転載
- 2023-06-05 13:22:29905ブラウズ
大規模なモデル機能が登場していますが、パラメーターのスケールが大きいほど良いのでしょうか?
ただし、10B 未満のモデルでも GPT-3.5 と同等のパフォーマンスを達成できると主張する研究者が増えています。
#これは本当にそうなのでしょうか?
GPT-4 をリリースした OpenAI のブログで次のように言及されました:
カジュアルな会話では、GPT-3.5 と GPT-4違いは非常に微妙かもしれません。タスクの複雑さが十分なしきい値に達すると、違いが現れます。GPT-4 は GPT-3.5 よりも信頼性が高く、創造性が高く、より微妙な指示を処理できます。
Google の開発者も PaLM モデルについて同様の観察を行い、大規模モデルの思考連鎖推論能力が小規模モデルよりも大幅に強力であることを発見しました。
これらの観察結果は、複雑なタスクを実行する能力が大規模モデルの機能を具体化するための鍵であることを示しています。
古いことわざのように、モデルもプログラマーも同じです。「くだらないことを言うのはやめて、推論を見せてください。」

基本的なテキスト要約能力、大規模なモデルの実行はまさに「的外れで鶏を殺す」ようなものです。
これらの基本的な能力の評価は、将来の大型モデルの開発を検討する上ではやや専門的ではないように思えます。
#論文アドレス: https://arxiv.org/pdf/2305.17306.pdf
大規模モデルの推論が最も優れているのはどの企業ですか能力??
だからこそ、研究者たちは、困難な推論タスクにおけるモデルのパフォーマンスを測定するために、複雑な推論タスク リストである思考連鎖ハブを作成しました。
テスト項目には、数学 (GSM8K))、科学 (MATH、定理 QA)、記号 (BBH)、知識 (MMLU、C-Eval)、およびコーディング (HumanEval) が含まれます。
これらのテスト プロジェクトまたはデータ セットはすべて、大規模モデルの複雑な推論機能を目的としています。誰もが正確に回答できる単純なタスクなどというものはありません。
研究者は今でも、モデルの推論能力を評価するために思考連鎖プロンプト (COT プロンプト) 手法を使用しています。
推論能力のテストでは、研究者は最終的な解答のパフォーマンスのみを測定基準として使用し、途中の推論ステップは判断の基礎として使用されません。
下の図に示すように、さまざまな推論タスクにおける現在の主流モデルのパフォーマンスが示されています。
#テスト結果: モデルが大きいほど推論能力が強化される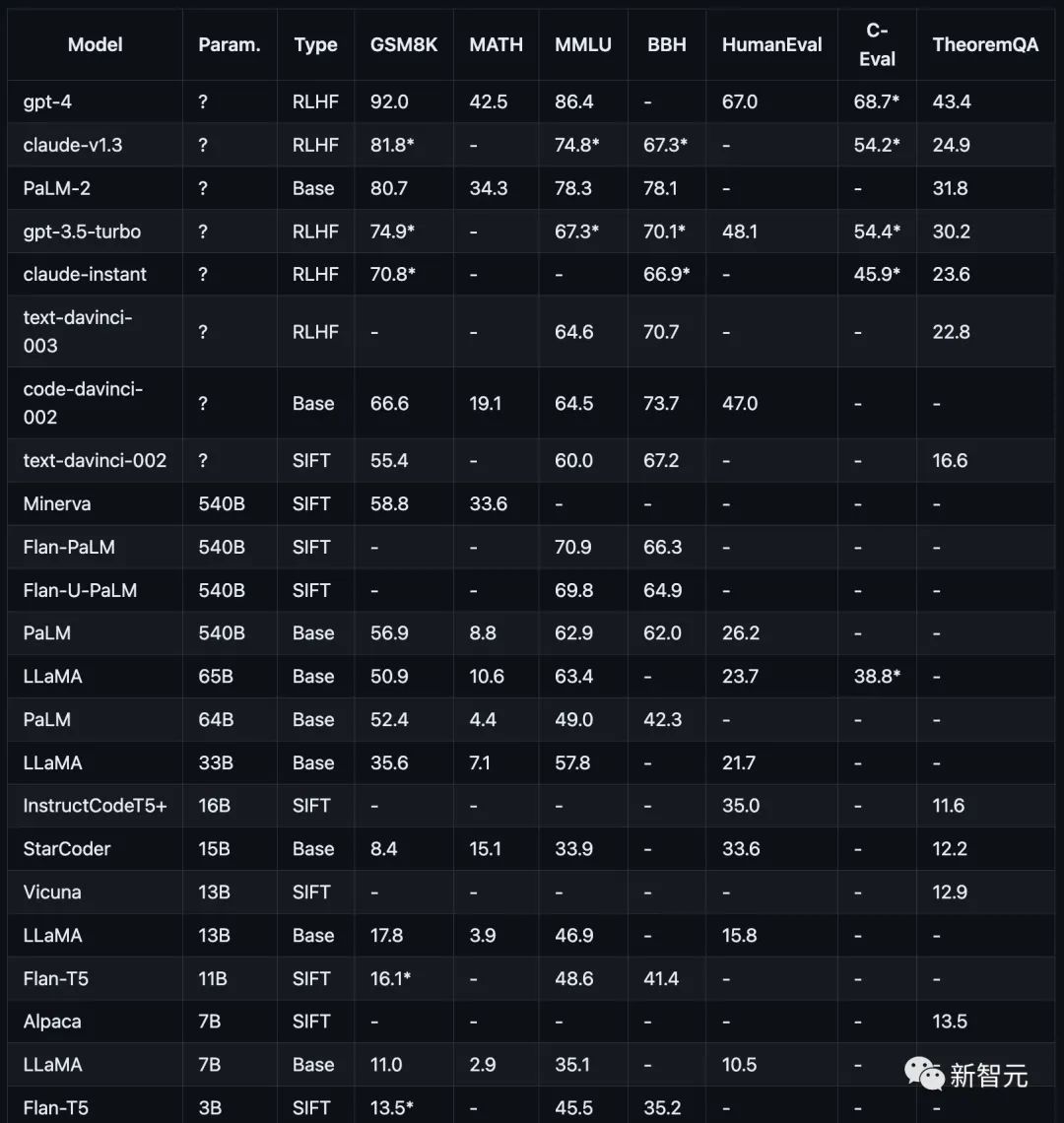
OpenAI GPT には、GPT-4 (現在最強)、GPT3.5-Turbo が含まれます(高速ですが、強力ではありません)、text-davinci-003、text-davinci-002、および code-davinci-002 (Turbo より前の重要なバージョン)。
 Anthropic Claude には、claude-v1.3 (低速ですが高機能) と claude-instant-v1.0 (より高速ですが、能力は低くなります)。
Anthropic Claude には、claude-v1.3 (低速ですが高機能) と claude-instant-v1.0 (より高速ですが、能力は低くなります)。
Google PaLM (PaLM、PaLM-2、およびそれらの命令調整バージョン (FLan-PaLM および Flan-UPaLM) を含む)、強力なベースおよび命令調整モデル。

Meta LLaMA (7B、13B、33B、65B バリアントを含む) は、重要なオープンソースの基本モデルです。
GPT-4 は、GSM8K および MMLU 上の他のすべてのモデルよりも大幅に優れていますが、GPT シリーズに匹敵するのは Claude だけです。
FlanT5 11B や LLaMA 7B などの小型モデルは大幅に遅れています。
研究者らは実験を通じて、モデルのパフォーマンスは通常、スケールに関連しており、ほぼ対数線形の傾向があることを発見しました。
パラメーター スケールを開示しないモデルは、一般にスケール情報を開示するモデルよりもパフォーマンスが優れています。
LLaMA-65B 推論機能は ChatGPT に近いです
さらに研究者らは、オープンソース コミュニティは規模に関する「堀」をまだ調査する必要があるかもしれないと指摘しました。さらなる改善のためのRLHF。
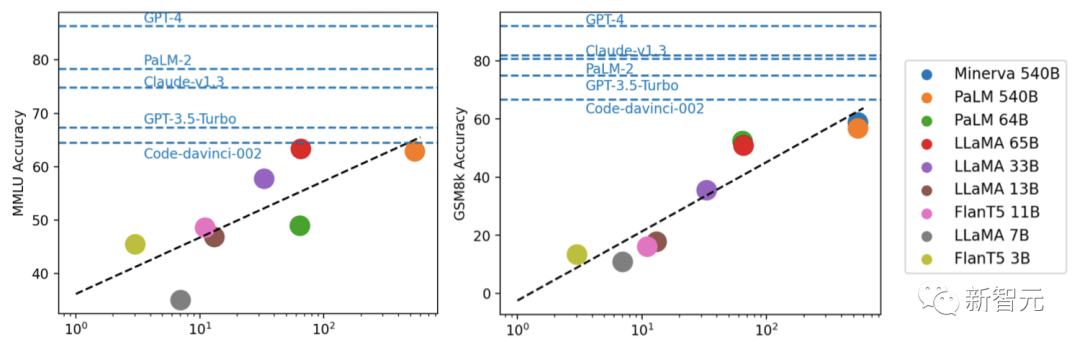
この論文の筆頭著者であるフー・ヤオ氏は次のように結論付けています:
#1.オープンソースとクローズドギャップの明らかな違い。
2. 上位の主流モデルのほとんどは RLHF
3. LLaMA-65B は code-davinci-002 に非常に近いです, GPT -3.5 基本モデル
4. 上記を踏まえると、最も有望な方向性は 「LLaMA 65B で RLHF を行う」です。

このプロジェクトについて、著者は将来のさらなる最適化について説明します:
将来的には、より厳選された推論データセット、特に常識的な推論と数学の定理を測定するデータセットが追加される予定です。
および外部 API を呼び出す機能。
さらに重要なのは、Vicuna7 やその他のオープン ソース モデルなど、LLaMA に基づく命令微調整モデルなど、より多くの言語モデルを含める必要があることです。
Cohere 8 などの API を介して、PaLM-2 などのモデルの機能にアクセスすることもできます。
つまり、著者は、このプロジェクトが、オープンソースの大規模言語モデルの開発を評価および指導するための公共の福祉施設として大きな役割を果たすことができると信じています。
以上が中国科学チームが大型モデルの複雑な推論能力を総合的に評価する「思考連鎖コレクション」を開始の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。