



ロッキングチェアと馬の 3 次元形状を入力すると、何が得られるでしょうか?


##木製カートと馬?馬車と電動馬、バナナと帆船を手に入れましょうか?バナナヨットを手に入れましょう。卵とデッキチェアはいかがですか?エッグチェアを手に入れましょう。

UCSD、上海交通大学、クアルコムのチームの研究者らは、最新の 3 次元表現モデル OpenShape を提案しました。 3次元形状のオープンワールド。
- #論文アドレス: https://arxiv.org/pdf/2305.10764.pdf
- プロジェクトのホームページ: https://colin97.github.io/OpenShape/
- インタラクティブ デモ: https://huggingface.co/spaces/OpenShape/openshape-demo
- コード アドレス: https://github.com/Colin97/OpenShape_code
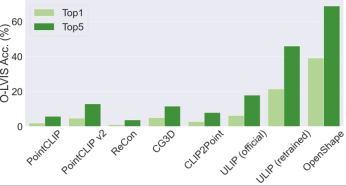
#三次元形状ゼロショット分類

OpenShape の ModelNet40 でのトップ 3 とトップ 5 の精度は、それぞれ 96.5% と 98.0% に達しました。
マルチモーダル 3D 形状検索
OpenShape のマルチモーダル表現を使用すると、ユーザーは画像、テキスト、または点群入力に対して 3D 形状検索を実行できます。入力表現と 3D 形状表現の間のコサイン類似度を計算し、kNN を見つけることにより、統合データセットからの 3D 形状の取得を研究します。

# #
上の図は、入力イメージと取得された 2 つの 3D 形状を示しています。

#テキスト入力の 3 次元形状検索
上の画像は、入力テキストと取得された 3 次元形状を示しています。 OpenShape は、幅広い視覚的および意味論的な概念を学習し、きめ細かいサブカテゴリ (最初の 2 行) と属性制御 (色、形状、スタイル、およびそれらの組み合わせなどの最後の 2 行) を可能にします。

#3D 点群入力の 3D 形状取得
上の図は、入力 3D 点群と 2 つの取得された 3D 形状を示しています。

上の図は 2 つの 3D 形状を入力として受け取り、その OpenShape 表現を使用して両方の入力に最も近い 3D 形状を同時に取得します。取得された形状は、両方の入力形状からの意味要素と幾何学的要素を巧みに組み合わせています。
3 次元形状ベースのテキストおよび画像の生成
OpenShape の 3 次元形状表現は CLIP の画像およびテキスト表現空間に合わせて配置されているため、これらを使用することができます。 CLIP からの派生モデルに基づく多くは、さまざまなクロスモーダル アプリケーションをサポートするために結合されます。
#3 次元点群の字幕生成
既製の画像字幕モデル (ClipCap) と組み合わせることで、OpenShape は 3D 点群の字幕生成を実装します。
#3 次元点群に基づく画像生成
既製のテキストから画像への拡散モデル (Stable unCLIP) と組み合わせることで、OpenShape は 3D 点群に基づく画像生成を実装します (オプションのテキスト ヒントをサポート)。
3 次元点群に基づく画像生成のその他の例

対比学習に基づくマルチモーダル表現の調整: OpenShape は、3D 点群は次のような 3D ネイティブ エンコーダーをトレーニングします。 3D 形状の表現を抽出するための入力として使用されます。以前の研究に続いて、マルチモーダル対比学習を活用して、CLIP の画像およびテキスト表現空間と整合させます。以前の研究とは異なり、OpenShape は、より一般的でスケーラブルなジョイント表現空間を学習することを目的としています。研究の焦点は主に、オープンワールドでの 3D 形状理解を真に実現するために、3D 表現学習の規模を拡大し、対応する課題に対処することです。
複数の 3D 形状データセットの統合: 大規模な 3D 形状表現の学習にはトレーニング データの規模と多様性が重要な役割を果たすため、この研究では、現在公開されている最大のデータセットに関する 4 つのトレーニングを統合しました。 3D データセット。以下の図に示すように、調査されたトレーニング データには 876,000 のトレーニング シェイプが含まれています。 4 つのデータセットのうち、ShapeNetCore、3D-FUTURE、および ABO には人間が検証した高品質の 3D 形状が含まれていますが、限られた数の形状と数十のカテゴリのみをカバーしています。 Objaverse データセットは、最近リリースされた 3D データセットで、より多くの 3D 形状が含まれ、より多様なオブジェクト クラスをカバーしています。しかし、Objaverse の形状は主にインターネット ユーザーによってアップロードされており、手動による検証が行われていないため、品質が不均一であり、配布が非常に不均一であり、さらなる処理が必要です。 
テキスト フィルタリングとエンリッチメント: 3D 形状と 2D 画像の間でのみ検出された研究 対照学習の適用大規模なデータセットでトレーニングした場合でも、3D 形状とテキスト空間の位置合わせを推進するには不十分です。研究によると、これは CLIP の言語空間と画像表現空間に固有のドメイン ギャップが原因であると推測されています。したがって、研究では 3D 形状をテキストと明示的に位置合わせする必要があります。ただし、元の 3D データ セットからのテキスト アノテーションは、コンテンツが欠落している、間違っている、粗い、単一のコンテンツであるなどの問題に直面することがよくあります。この目的を達成するために、この文書では、テキストをフィルタリングおよび強化してテキスト注釈の品質を向上させるための 3 つの戦略を提案します。GPT-4 を使用したテキスト フィルタリング、字幕生成、および 3D モデルの 2D レンダリングの画像取得です。

#調査では、自動的にフィルタリングして強化するための 3 つの戦略が提案されました。生のデータセット内のノイズの多いテキスト。

テキスト フィルタリングとエンリッチメントの例
各例の左側のセクションには、サムネイル、元の形状名、GPT-4 フィルター処理された結果が表示されます。右上部分には 2 つのキャプション モデルからの画像キャプションが表示され、右下部分には取得された画像とそれに対応するテキストが表示されます。
三次元基幹ネットワークを拡充します。 3D 点群学習に関する以前の研究は主に ShapeNet のような小規模な 3D データ セットを対象としていたため、これらのバックボーン ネットワークは大規模な 3D トレーニングに直接適用できない可能性があり、それに応じてバックボーン ネットワークの規模を拡張する必要があります。 。この研究では、異なる 3D バックボーン ネットワークは、異なるサイズのデータセットでトレーニングされた場合に異なる動作とスケーラビリティを示すことがわかりました。その中でも、Transformer ベースの PointBERT と 3 次元畳み込みベースの SparseConv がより強力なパフォーマンスとスケーラビリティを示すため、3 次元バックボーン ネットワークとして選択されました。
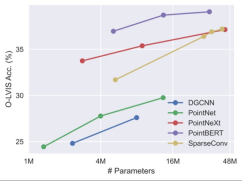
#統合データセット上の 3D バックボーン モデルのサイズをスケールアップすると、パフォーマンスが低下します。スケーラビリティの比較。
困難な負の例マイニング:この研究のアンサンブル データセットは、高度なクラスの不均衡を示しています。建築などの一部の一般的なカテゴリは数万の形状を占める場合がありますが、セイウチや財布などの他の多くのカテゴリは数十、またはさらに少ない形状しか含まれておらず、過小評価されています。したがって、対照学習用にバッチがランダムに構築される場合、混同されやすい 2 つのカテゴリ (リンゴとサクランボなど) の形状が同じバッチ内に出現して対比される可能性は低くなります。この目的を達成するために、この論文では、トレーニングの効率とパフォーマンスを向上させるための、オフラインでの困難なネガティブ サンプル マイニング戦略を提案します。 HuggingFace のインタラクティブなデモへようこそ。
以上が3D 点群、分類、検索、字幕、画像生成のオープンワールドの理解の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIゲーム開発は、激動の夢想家ポータルでエージェントの時代に入りますMay 02, 2025 am 11:17 AM
AIゲーム開発は、激動の夢想家ポータルでエージェントの時代に入りますMay 02, 2025 am 11:17 AM激動ゲーム:AIエージェントとのゲーム開発に革命をもたらします BlizzardやObsidianなどの業界の巨人の退役軍人で構成されるゲーム開発スタジオであるUpheavalは、革新的なAIを搭載したPlatforでゲームの作成に革命をもたらす態勢を整えています。
 UberはあなたのRobotaxiショップになりたいと思っています、プロバイダーはそれらを許可しますか?May 02, 2025 am 11:16 AM
UberはあなたのRobotaxiショップになりたいと思っています、プロバイダーはそれらを許可しますか?May 02, 2025 am 11:16 AMUberのRobotaxi戦略:自動運転車用の乗車エコシステム 最近のCurbivore Conferenceで、UberのRichard Willderは、Robotaxiプロバイダーの乗車プラットフォームになるための戦略を発表しました。 で支配的な位置を活用します
 ビデオゲームをプレイするAIエージェントは、将来のロボットを変革しますMay 02, 2025 am 11:15 AM
ビデオゲームをプレイするAIエージェントは、将来のロボットを変革しますMay 02, 2025 am 11:15 AMビデオゲームは、特に自律的なエージェントと現実世界のロボットの開発において、最先端のAI研究のための非常に貴重なテストの根拠であることが証明されています。 a
 スタートアップインダストリアルコンプレックス、VC 3.0、およびジェームズクーリエのマニフェストMay 02, 2025 am 11:14 AM
スタートアップインダストリアルコンプレックス、VC 3.0、およびジェームズクーリエのマニフェストMay 02, 2025 am 11:14 AM進化するベンチャーキャピタルの景観の影響は、メディア、財務報告、日常の会話で明らかです。 ただし、投資家、スタートアップ、資金に対する特定の結果はしばしば見落とされています。 ベンチャーキャピタル3.0:パラダイム
 AdobeはAdobe Max London 2025でクリエイティブクラウドとホタルを更新しますMay 02, 2025 am 11:13 AM
AdobeはAdobe Max London 2025でクリエイティブクラウドとホタルを更新しますMay 02, 2025 am 11:13 AMAdobe Max London 2025は、アクセシビリティと生成AIへの戦略的シフトを反映して、Creative Cloud and Fireflyに大幅な更新を提供しました。 この分析には、イベント以前のブリーフィングからの洞察がAdobeのリーダーシップを取り入れています。 (注:ADOB
 すべてのメタがラマコンで発表しましたMay 02, 2025 am 11:12 AM
すべてのメタがラマコンで発表しましたMay 02, 2025 am 11:12 AMMetaのLlamaconアナウンスは、Openaiのような閉じたAIシステムと直接競合するように設計された包括的なAI戦略を紹介し、同時にオープンソースモデルの新しい収益ストリームを作成します。 この多面的なアプローチはBOをターゲットにします
 AIは単なる通常のテクノロジーに過ぎないという提案に関する醸造論争May 02, 2025 am 11:10 AM
AIは単なる通常のテクノロジーに過ぎないという提案に関する醸造論争May 02, 2025 am 11:10 AMこの結論に関して、人工知能の分野には深刻な違いがあります。 「皇帝の新しい服」を暴露する時が来たと主張する人もいれば、人工知能は普通の技術であるという考えに強く反対する人もいます。 それについて議論しましょう。 この革新的なAIブレークスルーの分析は、AIの分野での最新の進歩をカバーする私の進行中のForbesコラムの一部です。 一般的な技術としての人工知能 第一に、この重要な議論の基礎を築くためには、いくつかの基本的な知識が必要です。 現在、人工知能をさらに発展させることに専念する大量の研究があります。全体的な目標は、人工的な一般情報(AGI)を達成し、さらには可能な人工スーパーインテリジェンス(AS)を達成することです
 モデル市民、なぜAI価値が次のビジネスヤードスティックであるのかMay 02, 2025 am 11:09 AM
モデル市民、なぜAI価値が次のビジネスヤードスティックであるのかMay 02, 2025 am 11:09 AM企業のAIモデルの有効性は、現在、重要なパフォーマンス指標になっています。 AIブーム以来、生成AIは、誕生日の招待状の作成からソフトウェアコードの作成まで、すべてに使用されてきました。 これにより、言語modが急増しました


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

WebStorm Mac版
便利なJavaScript開発ツール

SublimeText3 英語版
推奨: Win バージョン、コードプロンプトをサポート!

EditPlus 中国語クラック版
サイズが小さく、構文の強調表示、コード プロンプト機能はサポートされていません

ZendStudio 13.5.1 Mac
強力な PHP 統合開発環境

AtomエディタMac版ダウンロード
最も人気のあるオープンソースエディター
ホットトピック
 7907
7907 15165214141152130325124829
15165214141152130325124829