


AI大手がホワイトハウスに書類を提出:Google、OpenAI、オックスフォードなどを含む12のトップ機関が共同で「モデルセキュリティ評価フレームワーク」を発表

5月初旬、ホワイトハウスはGoogle、Microsoft、OpenAI、Anthropic、その他のAI企業のCEOらと会合を開き、AI生成技術の爆発的普及、技術の背後に隠れたリスク、開発方法について話し合った。責任を持って人工知能システムを開発し、効果的な規制措置を開発します。

既存のセキュリティ評価プロセスは通常、一連の評価ベンチマークに依存して、AI システムの異常な動作(誤解を招くような動作)を特定します。発言、偏った意思決定、著作権で保護されたコンテンツの輸出。
AI テクノロジーがますます強力になるにつれて、操作、欺瞞、またはその他の高リスク機能を備えた AI システムの開発を防ぐために、対応するモデル評価ツールもアップグレードする必要があります。
最近、Google DeepMind、ケンブリッジ大学、オックスフォード大学、トロント大学、モントリオール大学、OpenAI、Anthropic、その他多くのトップ大学や研究機関が共同で、評価ツールをリリースしました。モデルのセキュリティ: このフレームワークは、将来の人工知能モデルの開発と展開における重要なコンポーネントになることが期待されています。

紙のリンク: https://arxiv.org/pdf/2305.15324.pdf
# 汎用 AI システムの開発者は、トレーニング、展開、リスクの特性評価などのプロセスをより責任を持って実行できるように、モデルのハザード機能と調整を評価し、極度のリスクをできるだけ早く特定する必要があります。
AI にはリスクがあり、トレーニングには注意が必要です
一般的なモデルでは、通常、特定の能力や行動を学習するために「トレーニング」が必要ですが、既存の学習プロセスは通常不完全です。たとえば、以前の研究で、DeepMind の研究者は、トレーニング中にモデルの予期された動作が正しく報われたとしても、人工知能システムは依然としていくつかの意図しない目標を学習することを発見しました。

責任ある AI 開発者は、起こり得る将来の展開や未知のリスクを事前に予測できなければなりません。AI システムが進歩するにつれて、将来の一般的なモデルは、さまざまな危険を学習する能力をデフォルトで学習する可能性があります。
たとえば、人工知能システムは、クラウド コンピューティング上で攻撃的なサイバー操作を実行したり、会話で人間を巧妙に欺いたり、人間を操作して有害な行為を実行したり、武器を設計または入手したりする可能性があります。プラットフォームは、他の高リスク AI システムを微調整して操作したり、人間がこれらの危険なタスクを完了するのを支援したりします。
そのようなモデルに悪意のあるアクセスを持つ誰かが AI の機能を悪用したり、調整の失敗により、AI モデルが人間の指導なしに自ら有害な行動を取ることを選択したりする可能性があります。 。
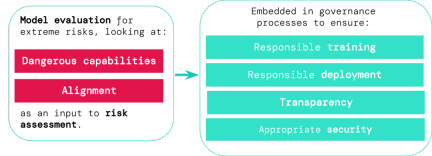
# モデル評価は、これらのリスクを事前に特定するのに役立ちます。この記事で提案されているフレームワークに従って、AI 開発者はモデル評価を使用して次のことを発見できます。 #1. モデルが、セキュリティを脅かしたり、影響力を及ぼしたり、規制を回避したりするために使用できる特定の「危険な機能」をどの程度備えているか。
2.モデルはその機能を適用する傾向があり、損傷を引き起こします (つまり、モデルの位置合わせ)。キャリブレーション評価では、モデルが非常に広範囲のシナリオ設定の下で期待どおりに動作することを確認し、可能であればモデルの内部動作を検査する必要があります。
最もリスクの高いシナリオには、危険な機能の組み合わせが含まれることが多く、評価の結果は、AI 開発者が極度のリスクを引き起こす十分な要素があるかどうかを理解するのに役立ちます。

経験的な観点から、人工知能システムの機能構成が極度のリスクを引き起こすのに十分である場合、およびシステムが悪用されるか、効果的に調整されない可能性があると想定します。 、そして人工知能 コミュニティはこれを非常に危険なシステムとして扱うべきです。
このようなシステムを現実の世界に展開するには、開発者は標準をはるかに超えるセキュリティ標準を設定する必要があります。
モデル評価は AI ガバナンスの基礎です
どのモデルがリスクにさらされているかを特定するためのより優れたツールがあれば、企業や規制当局は次のことをより確実に行うことができます。1. 責任あるトレーニング: リスクの初期兆候を示す新しいモデルをトレーニングするかどうか、またどのようにトレーニングするか。
2. 責任ある導入: 潜在的にリスクのあるモデルを導入するかどうか、いつ、どのように導入するか。
3. 透明性: 潜在的なリスクに備え、または軽減するために、有益で実用的な情報を利害関係者に報告します。
4. 適切なセキュリティ: 極度のリスクを引き起こす可能性のあるモデルには、強力な情報セキュリティ管理とシステムを適用する必要があります。
私たちは、高機能の一般モデルのトレーニングと展開に関する重要な決定に、極度のリスクのモデル評価を組み込む方法の青写真を開発しました。
開発者はプロセス全体を通じて評価を実施し、詳細な評価を実施するために外部のセキュリティ研究者やモデル監査人に構造化モデルへのアクセスを許可する必要があります。
評価結果は、モデルのトレーニングと展開の前にリスク評価を知らせることができます。
極度のリスクに対する評価の構築

次の表に、モデルに必要な理想的なプロパティをいくつか示します。
 研究者らは、アライメントの包括的な評価を確立することは難しいと考えているため、現在の目標はアライメントを確立するプロセスです。モデルにリスクがあるかどうかを高い信頼度で評価するための調整。
研究者らは、アライメントの包括的な評価を確立することは難しいと考えているため、現在の目標はアライメントを確立するプロセスです。モデルにリスクがあるかどうかを高い信頼度で評価するための調整。
アライメント評価は、モデルがさまざまな環境で適切な動作を確実に示すことを確認する必要があるため、非常に困難です。そのため、モデルを幅広いテスト環境でテストする必要があります。 . より広い環境範囲を達成するために評価を実施します。具体的には:
1. 幅: できるだけ多くの環境でモデルの動作を評価する 有望な方法は、人工知能システムを使用して評価を自動的に記述することです。
2. ターゲット設定: 一部の環境は他の環境よりも失敗する可能性が高く、これはハニーポットや勾配ベースの敵対的テストの使用など、賢明な設計によって達成できる可能性があります。
3. 一般化の理解: 研究者は考えられるすべての状況を予測したりシミュレーションしたりすることはできないため、モデルの動作がさまざまな状況でどのように、そしてなぜ一般化する (または一般化できない) のかについて理解を定式化する必要があります。
もう 1 つの重要なツールは機械論的分析です。これは、モデルの機能を理解するためにモデルの重みとアクティベーションを研究します。
モデル評価の未来
プロセス全体が、複雑な社会的、政治的、経済的など、モデル開発以外の影響要因に大きく依存しているため、モデル評価は万能ではありません。部隊はいくつかのリスクを見逃す可能性がある。
モデル評価は他のリスク評価ツールと統合され、業界、政府、市民社会全体でより広範にセキュリティ意識を促進する必要があります。
Google は最近、「Responsible AI」ブログで、人工知能の開発を標準化するには、個人の実践、共有の業界標準、健全なポリシーが重要であると指摘しました。
研究者は、モデル内のリスクの出現を追跡し、関連する結果に適切に対応するプロセスが、人工知能機能の最前線で活動する責任ある開発者にとって重要な部分であると信じています。 . .
以上がAI大手がホワイトハウスに書類を提出:Google、OpenAI、オックスフォードなどを含む12のトップ機関が共同で「モデルセキュリティ評価フレームワーク」を発表の詳細内容です。詳細については、PHP 中国語 Web サイトの他の関連記事を参照してください。

 AIゲーム開発は、激動の夢想家ポータルでエージェントの時代に入りますMay 02, 2025 am 11:17 AM
AIゲーム開発は、激動の夢想家ポータルでエージェントの時代に入りますMay 02, 2025 am 11:17 AM激動ゲーム:AIエージェントとのゲーム開発に革命をもたらします BlizzardやObsidianなどの業界の巨人の退役軍人で構成されるゲーム開発スタジオであるUpheavalは、革新的なAIを搭載したPlatforでゲームの作成に革命をもたらす態勢を整えています。
 UberはあなたのRobotaxiショップになりたいと思っています、プロバイダーはそれらを許可しますか?May 02, 2025 am 11:16 AM
UberはあなたのRobotaxiショップになりたいと思っています、プロバイダーはそれらを許可しますか?May 02, 2025 am 11:16 AMUberのRobotaxi戦略:自動運転車用の乗車エコシステム 最近のCurbivore Conferenceで、UberのRichard Willderは、Robotaxiプロバイダーの乗車プラットフォームになるための戦略を発表しました。 で支配的な位置を活用します
 ビデオゲームをプレイするAIエージェントは、将来のロボットを変革しますMay 02, 2025 am 11:15 AM
ビデオゲームをプレイするAIエージェントは、将来のロボットを変革しますMay 02, 2025 am 11:15 AMビデオゲームは、特に自律的なエージェントと現実世界のロボットの開発において、最先端のAI研究のための非常に貴重なテストの根拠であることが証明されています。 a
 スタートアップインダストリアルコンプレックス、VC 3.0、およびジェームズクーリエのマニフェストMay 02, 2025 am 11:14 AM
スタートアップインダストリアルコンプレックス、VC 3.0、およびジェームズクーリエのマニフェストMay 02, 2025 am 11:14 AM進化するベンチャーキャピタルの景観の影響は、メディア、財務報告、日常の会話で明らかです。 ただし、投資家、スタートアップ、資金に対する特定の結果はしばしば見落とされています。 ベンチャーキャピタル3.0:パラダイム
 AdobeはAdobe Max London 2025でクリエイティブクラウドとホタルを更新しますMay 02, 2025 am 11:13 AM
AdobeはAdobe Max London 2025でクリエイティブクラウドとホタルを更新しますMay 02, 2025 am 11:13 AMAdobe Max London 2025は、アクセシビリティと生成AIへの戦略的シフトを反映して、Creative Cloud and Fireflyに大幅な更新を提供しました。 この分析には、イベント以前のブリーフィングからの洞察がAdobeのリーダーシップを取り入れています。 (注:ADOB
 すべてのメタがラマコンで発表しましたMay 02, 2025 am 11:12 AM
すべてのメタがラマコンで発表しましたMay 02, 2025 am 11:12 AMMetaのLlamaconアナウンスは、Openaiのような閉じたAIシステムと直接競合するように設計された包括的なAI戦略を紹介し、同時にオープンソースモデルの新しい収益ストリームを作成します。 この多面的なアプローチはBOをターゲットにします
 AIは単なる通常のテクノロジーに過ぎないという提案に関する醸造論争May 02, 2025 am 11:10 AM
AIは単なる通常のテクノロジーに過ぎないという提案に関する醸造論争May 02, 2025 am 11:10 AMこの結論に関して、人工知能の分野には深刻な違いがあります。 「皇帝の新しい服」を暴露する時が来たと主張する人もいれば、人工知能は普通の技術であるという考えに強く反対する人もいます。 それについて議論しましょう。 この革新的なAIブレークスルーの分析は、AIの分野での最新の進歩をカバーする私の進行中のForbesコラムの一部です。 一般的な技術としての人工知能 第一に、この重要な議論の基礎を築くためには、いくつかの基本的な知識が必要です。 現在、人工知能をさらに発展させることに専念する大量の研究があります。全体的な目標は、人工的な一般情報(AGI)を達成し、さらには可能な人工スーパーインテリジェンス(AS)を達成することです
 モデル市民、なぜAI価値が次のビジネスヤードスティックであるのかMay 02, 2025 am 11:09 AM
モデル市民、なぜAI価値が次のビジネスヤードスティックであるのかMay 02, 2025 am 11:09 AM企業のAIモデルの有効性は、現在、重要なパフォーマンス指標になっています。 AIブーム以来、生成AIは、誕生日の招待状の作成からソフトウェアコードの作成まで、すべてに使用されてきました。 これにより、言語modが急増しました


ホットAIツール

Undresser.AI Undress
リアルなヌード写真を作成する AI 搭載アプリ

AI Clothes Remover
写真から衣服を削除するオンライン AI ツール。

Undress AI Tool
脱衣画像を無料で

Clothoff.io
AI衣類リムーバー

Video Face Swap
完全無料の AI 顔交換ツールを使用して、あらゆるビデオの顔を簡単に交換できます。

人気の記事
ホットツール

SecLists
SecLists は、セキュリティ テスターの究極の相棒です。これは、セキュリティ評価中に頻繁に使用されるさまざまな種類のリストを 1 か所にまとめたものです。 SecLists は、セキュリティ テスターが必要とする可能性のあるすべてのリストを便利に提供することで、セキュリティ テストをより効率的かつ生産的にするのに役立ちます。リストの種類には、ユーザー名、パスワード、URL、ファジング ペイロード、機密データ パターン、Web シェルなどが含まれます。テスターはこのリポジトリを新しいテスト マシンにプルするだけで、必要なあらゆる種類のリストにアクセスできるようになります。

メモ帳++7.3.1
使いやすく無料のコードエディター

DVWA
Damn Vulnerable Web App (DVWA) は、非常に脆弱な PHP/MySQL Web アプリケーションです。その主な目的は、セキュリティ専門家が法的環境でスキルとツールをテストするのに役立ち、Web 開発者が Web アプリケーションを保護するプロセスをより深く理解できるようにし、教師/生徒が教室環境で Web アプリケーションを教え/学習できるようにすることです。安全。 DVWA の目標は、シンプルでわかりやすいインターフェイスを通じて、さまざまな難易度で最も一般的な Web 脆弱性のいくつかを実践することです。このソフトウェアは、

ドリームウィーバー CS6
ビジュアル Web 開発ツール

MinGW - Minimalist GNU for Windows
このプロジェクトは osdn.net/projects/mingw に移行中です。引き続きそこでフォローしていただけます。 MinGW: GNU Compiler Collection (GCC) のネイティブ Windows ポートであり、ネイティブ Windows アプリケーションを構築するための自由に配布可能なインポート ライブラリとヘッダー ファイルであり、C99 機能をサポートする MSVC ランタイムの拡張機能が含まれています。すべての MinGW ソフトウェアは 64 ビット Windows プラットフォームで実行できます。
ホットトピック
 7921
7921 15165214141152130325124829
15165214141152130325124829